大型語言模型對決傳統方法:多語言漏洞修復能力大比拼
論文閱讀:On the Evaluation of Large Language Models in Multilingual Vulnerability Repair
arXiv:2508.03470
On the Evaluation of Large Language Models in Multilingual Vulnerability Repair
Dong wang, Junji Yu, Honglin Shu, Michael Fu, Chakkrit Tantithamthavorn, Yasutaka Kamei, Junjie Chen
Subjects: Software Engineering (cs.SE)
一段話總結
本文通過大規模實證研究,評估了現有自動漏洞修復(AVR)方法和大型語言模型(LLMs) 在七種編程語言(C、C#、C++、Go、JavaScript、Java、Python)中的漏洞修復性能。研究發現,GPT-4o在指令微調結合少樣本提示策略下,Exact Match(EM)分數達28.71%,與最優AVR方法VulMaster(28.94%)相當;LLM方法在修復獨特漏洞和最危險漏洞上更具優勢,對未見過的編程語言(如TypeScript)泛化能力更強;所有模型在Go語言上修復效果最佳,C/C++ 最差。該研究為LLMs在多語言漏洞修復中的應用提供了關鍵 insights。
研究背景
想象一下,你手機里的APP、電腦上的軟件,就像一座座復雜的城堡,而“軟件漏洞”就是城堡墻上的裂縫——黑客可能通過這些裂縫闖入,竊取你的信息、操控設備,甚至造成巨大損失。比如2021年的Log4Shell漏洞,堪稱“十年一遇的大裂縫”,攻擊者能在任何受影響的系統上執行惡意代碼,導致無數用戶遭殃。
隨著軟件越來越復雜,漏洞數量也在飆升。2023年報告的軟件漏洞多達28961個,比2022年猛增15.57%。但修復這些漏洞可不是件容易事:一方面,需要專業知識;另一方面,手動修復平均要45天以上,遠跟不上漏洞出現的速度。
過去,研究者們開發了不少基于深度學習的“自動漏洞修復工具”,但這些工具大多只擅長修復C/C++語言的漏洞。可現在的軟件開發早已是“多國部隊”——Python、Java、Go等語言都廣泛使用,它們的漏洞同樣需要關注。這就像只給消防員配備了撲滅木房火災的工具,卻面對的是鋼筋水泥建筑的火災,顯然不夠用。
而近年來大火的大型語言模型(LLMs),比如GPT系列,號稱能理解多種語言,甚至能寫代碼。那么,它們能不能成為“多語言漏洞修復”的萬能滅火器?這正是這篇論文要探究的問題。
主要作者及單位信息
- DONG WANG,天津大學智能與計算學部
- JUNJI YU,天津大學智能與計算學部
- HONGLIN SHU,九州大學(日本)
- MICHAEL FU,墨爾本大學(澳大利亞)
- CHAKKRIT TANTITHAMTHAVORN,莫納什大學(澳大利亞)
- YASUTAKA KAMEI,九州大學(日本)
- JUNJIE CHEN(通訊作者),天津大學智能與計算學部
創新點
這篇論文的“獨特亮點”主要有三個:
-
首次全面對比:是首個系統評估“傳統自動修復方法”和“大型語言模型”在多語言漏洞修復中表現的研究,覆蓋了7種主流編程語言(C、C#、C++、Go、JavaScript、Java、Python)。
-
策略深挖:不僅測試了LLMs的基礎能力,還設計了“零樣本提示”“少樣本提示”“指令微調”等多種策略,找到讓LLMs發揮最佳效果的方式。
-
泛化能力驗證:專門測試了模型對“從未見過的編程語言”(如TypeScript)的漏洞修復能力,這對實際應用至關重要——畢竟軟件世界總有新語言出現。
研究方法和思路
研究團隊就像一場“漏洞修復大賽”的組織者,設計了一套嚴謹的“比賽規則”,步驟如下:
-
選數據集:用了目前最新的多語言漏洞數據集REEF,里面有4466個真實漏洞案例(CVE),30987個修復補丁,覆蓋7種語言。相當于給參賽者準備了豐富的“練習題”。
-
確定參賽選手:
- 傳統自動修復工具(AVR):比如VulMaster、VulRepair等5種,都是該領域的佼佼者。
- 預訓練語言模型(PLM):比如CodeBERT、CodeT5等7種,擅長處理代碼的AI模型。
- 大型語言模型(LLMs):包括DeepSeek-Coder、Code Llama、Llama 3、GPT-3.5-Turbo、GPT-4o,既有開源的,也有閉源的。
-
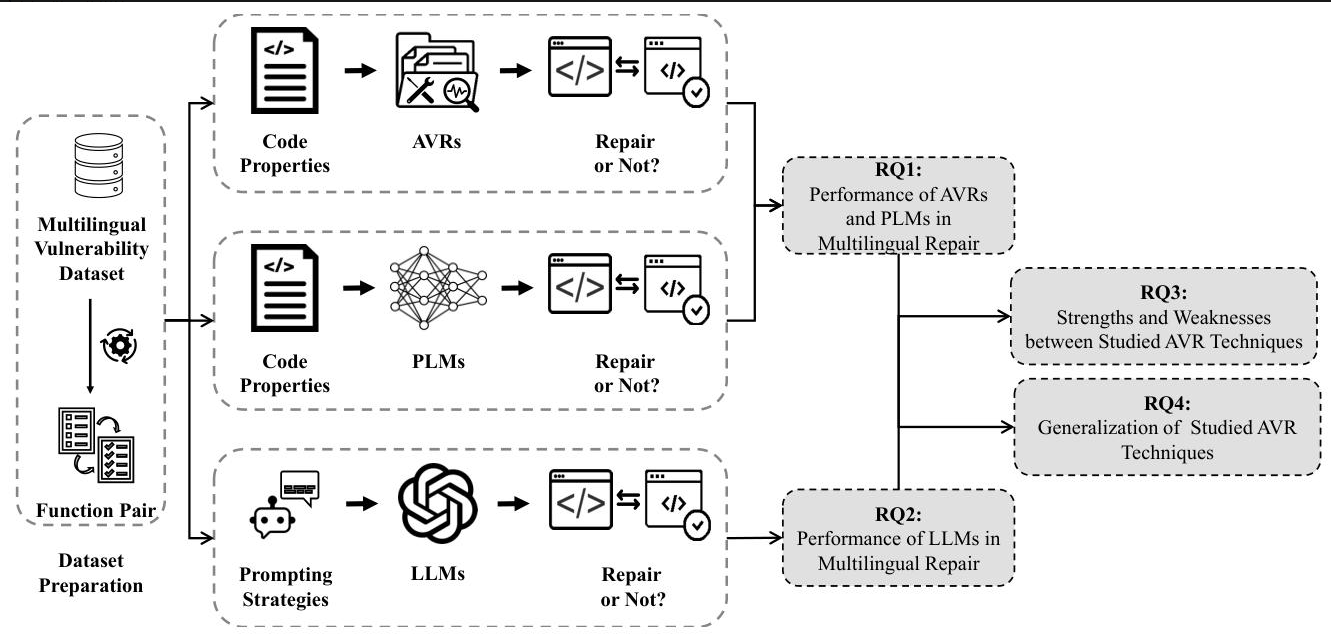
設計比賽項目:
- 基礎能力測試(RQ1):傳統工具和PLM在多語言修復中表現如何?
- LLM專項測試(RQ2):不同LLM用不同策略(零樣本、少樣本、指令微調)時,誰修復得最好?
- 優劣勢分析(RQ3):哪種方法擅長修復獨特漏洞?哪種更能處理危險漏洞?
- 泛化能力測試(RQ4):對沒學過的語言(如TypeScript),模型還能修復漏洞嗎?
-
評分標準:用三個指標打分:
- Exact Match(EM):修復結果和正確答案完全一樣的比例,相當于“全對”。
- BLEU-4:生成代碼和正確答案的相似度,看“意思對不對”。
- ROUGE:評估修復內容的覆蓋度,看“關鍵部分有沒有修到”。
主要貢獻
這篇論文的成果就像給“漏洞修復界”投下了一顆重磅炸彈,帶來了三個關鍵價值:
-
找到了當前最佳選手:GPT-4o在“指令微調+少樣本提示”策略下,EM分數達28.71%,和傳統工具中最強的VulMaster(28.94%)幾乎打平。這意味著LLMs已經具備挑戰傳統方法的實力。
-
揭示了LLMs的獨特優勢:
- 更擅長修復“獨特漏洞”:LLM能修復169個傳統工具修不了的漏洞,比VulMaster多24%。
- 更能處理危險漏洞:在2023年最危險的25種漏洞中,LLM修復成功率32.48%,高于傳統工具的31.15%。
- 泛化能力強:對沒學過的TypeScript語言,GPT-4o修復成功率28.57%,而VulMaster只有5.88%。
-
指明了語言差異:所有模型在Go語言上修復效果最好(平均EM 31.59%),在C/C++上最差(C++僅6.73%)。這可能和Go語法簡潔、C/C++復雜有關,為后續優化指明方向。
2. 思維導圖
3. 詳細總結
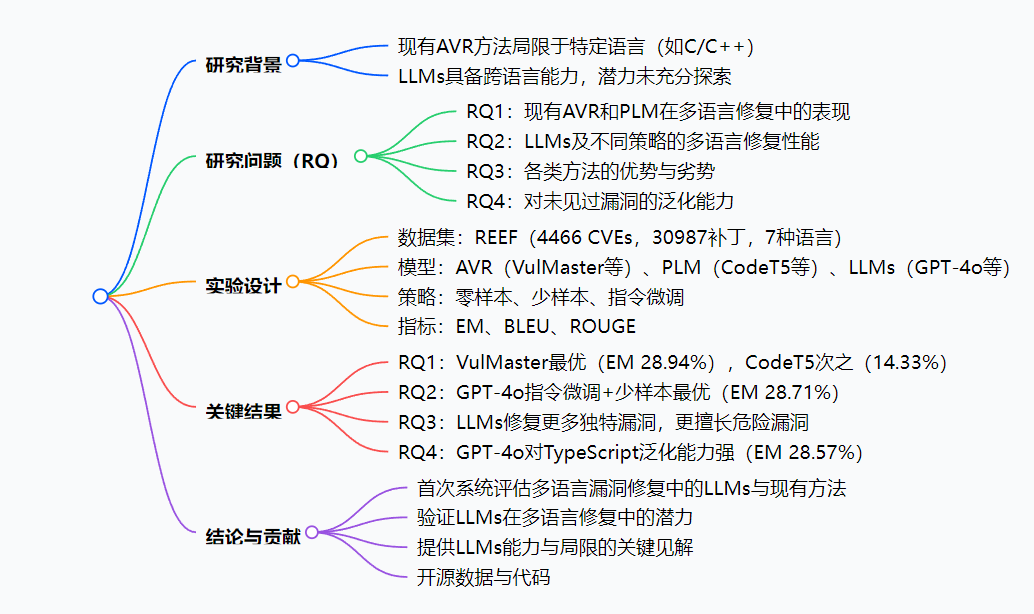
1. 研究背景與目的
- 背景:現有基于深度學習的自動漏洞修復(AVR)方法局限于特定語言(如C/C++),而大型語言模型(LLMs)具備跨語言能力,但在多語言漏洞修復中的有效性尚未明確。
- 目的:通過大規模實證研究,對比現有AVR方法、預訓練語言模型(PLMs)和LLMs在七種編程語言中的漏洞修復性能,探索LLMs的潛力與局限。
2. 實驗設計
- 數據集:采用REEF多語言漏洞數據集,包含4466個CVE、30987個補丁,覆蓋7種語言(C、C#、C++、Go、JavaScript、Java、Python),經處理后得到10649個函數對(訓練集7448、驗證集1059、測試集2142)。
- 模型:
- AVR方法:VulMaster、VulRepair等5種;
- PLMs:CodeBERT、CodeT5等7種;
- LLMs:DeepSeek-Coder、Code Llama、Llama 3、GPT-3.5-Turbo、GPT-4o共5種。
- LLM策略:零樣本提示、少樣本提示(BM25選3個示例)、指令微調(結合LoRA)。
- 評估指標:Exact Match(EM)、BLEU-4、ROUGE-1/2/L。
3. 研究結果(RQ1-RQ4)
| 研究問題 | 關鍵發現 | 關鍵數據 |
|---|---|---|
| RQ1:現有方法表現 | VulMaster最優,Encoder-decoder PLMs(如CodeT5)優于其他PLMs;Go效果最好,C/C++最差 | VulMaster的EM(beam 1)為28.94%,CodeT5為14.33% |
| RQ2:LLMs表現 | 指令微調+少樣本策略最優,GPT-4o的EM達28.71%,與VulMaster無統計差異;Go最佳,C/C++最差 | GPT-4o(指令微調+少樣本)EM 28.71%,McNemar檢驗p=0.8314 |
| RQ3:方法優劣勢 | LLM(GPT-4o)修復169個獨特漏洞,多于VulMaster(136個);在2023年Top25危險CWE中修復率32.48%,高于AVR(31.15%) | 獨特正確修復:LLM 169 > AVR 136 > PLM 8 |
| RQ4:泛化能力 | GPT-4o對未見過的TypeScript漏洞EM達28.57%,遠超VulMaster(5.88%) | TypeScript修復:GPT-4o 28.57% vs VulMaster 5.88% |
4. 結論與貢獻
- 首次系統評估多語言漏洞修復中的AVR、PLM和LLMs;
- 驗證了LLMs(尤其指令微調+少樣本策略)在多語言修復中的潛力;
- 揭示了LLMs的能力與局限,為未來研究提供指導;
- 開源數據、代碼和分析細節。
4. 關鍵問題
-
問題:在多語言漏洞修復中,LLMs與現有最優AVR方法(如VulMaster)的核心差異是什么?
答案:LLMs(如GPT-4o,指令微調+少樣本)在EM分數上與VulMaster接近(28.71% vs 28.94%),但在修復獨特漏洞(169個 vs 136個)和2023年Top25危險CWE(32.48% vs 31.15%)上表現更優,且對未見過的語言(如TypeScript)泛化能力更強(28.57% vs 5.88%)。 -
問題:哪種LLM策略對多語言漏洞修復最有效?其性能如何?
答案:指令微調結合少樣本提示策略最有效。其中,GPT-4o在該策略下EM達28.71%,BLEU-4為0.8448,ROUGE-1為0.9232,顯著優于零樣本(0.33%)和單純少樣本(26.89%)策略,且在7種語言中對Go修復效果最好(41.02%),C/C++最差(13.82%)。 -
問題:不同編程語言的漏洞修復效果有何差異?原因可能是什么?
答案:所有模型在Go語言上修復效果最佳( median EM 31.59%),C/C++ 最差(C:8.03%,C++:6.73%)。可能原因是Go語言較新、語法簡潔,而C/C++語法復雜、內存操作等漏洞類型更難修復。
總結
這篇論文通過大規模實驗,全面對比了傳統自動修復工具、預訓練模型和大型語言模型在多語言漏洞修復中的表現。結果顯示:
- 傳統工具中,VulMaster表現最佳(EM 28.94%);
- 大型語言模型中,GPT-4o在“指令微調+少樣本提示”策略下表現最優(EM 28.71%),與VulMaster不相上下;
- LLMs在修復獨特漏洞、危險漏洞和未見過的語言漏洞上更有優勢;
- 所有模型在Go語言上修復效果最好,C/C++最差。
這項研究證明了LLMs在多語言漏洞修復中的巨大潛力,為未來開發更通用、更高效的漏洞修復工具提供了重要參考。
解決的主要問題/成果
- 解決了“傳統工具語言局限”的問題,證明LLMs能跨語言修復漏洞。
- 找到了LLMs的最佳使用策略(指令微調+少樣本提示),為實際應用提供指導。
- 揭示了不同語言修復難度的差異,幫助研究者針對性優化模型。
- 開源了所有數據和代碼,方便其他研究者繼續探索。



















