背景:為什么需要Prompt緩存模塊?
在大模型問答多輪對話應用場景中,不同請求的 Prompt 往往有相同的前綴,比如:
第一次問答:
你是一名專業的電子產品客服,負責回答客戶關于手機產品的咨詢。請根據以下問題提供準確、友好的回答。
當前產品庫支持查詢的品牌包括:Apple、華為、小米、三星。用戶問題:
iPhone 16 的電池容量是多少?
模型回答:
iPhone 16 的電池容量為 3227 mAh。第二次問答:
(保留之前所有上下文)
你是一名專業的電子產品客服...(同上)用戶問題:
iPhone 16 的電池容量是多少?
模型回答:
iPhone 16 的電池容量為 3227 mAh.用戶新問題:
那它的快充功率呢?
模型回答:
iPhone 16 支持 20W 快充。兩輪問答請求中,系統預設的客服角色描述、產品庫范圍等前綴內容完全一致,這就會導致模型推理流程:
每次都從頭計算整個 Prompt 的 attention
重復計算前綴浪費算力
Prefix Cache 通過緩存這個已計算好的 Prompt 編碼結果(KV 對)直接復用,前面的結果會存儲在GPU緩存中,生成時只算后半部分。
這里說的Prompt緩存實際是vLLM中Prefix Cache的實現
vLLM 的 Prefix Cache 原理
vLLM 中的 Prefix Cache 是基于 KV Cache 的靜態共享機制,主要思路:
前綴哈希(Prefix Hashing)
將 Prompt 轉成 token 序列后計算哈希值
相同 token 序列的哈希值相同
哈希值作為緩存 key
存儲 KV 對(Key/Value Tensors)
KV 對是 attention 層計算后的結果
存在 GPU 顯存中(或部分放在 CPU 內存)
復用機制(Reuse)
當新的請求到來時,如果前綴哈希匹配,就直接加載已有的 KV 對
只需對新增的 token 做計算
分頁管理(PagedAttention 兼容)
Prefix Cache 依舊用 page(block)方式管理
可與普通 KV Cache 混用,不影響批處理
工作流程:
以一次批處理請求為例:
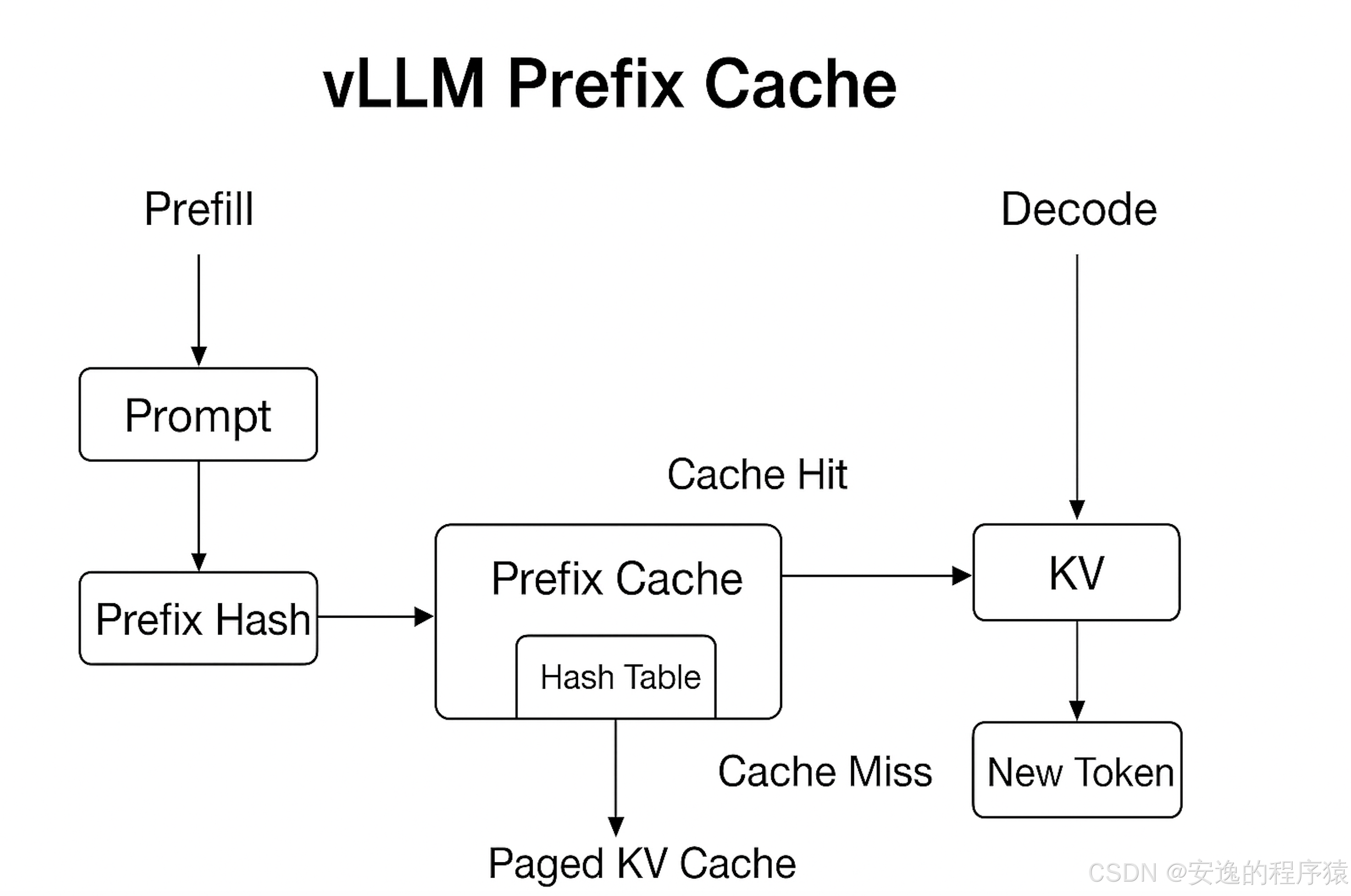
Prefill 階段
Tokenizer 將輸入文本轉成 token 序列
對序列做哈希(如 MurmurHash)
檢查哈希表:
命中:直接取 KV 對 → 進入生成階段
未命中:計算 KV 對并存入哈希表
Decode 階段
使用已緩存的 KV 對作為上下文
新 token 持續追加到 KV Cache
這樣的好處是可以減少重復計算:多個請求共享相同前綴的計算結果,同時加速批處理:常見系統提示(system prompt)復用率很高
)
)


)

(一))


-- 所有權與借用)
認證與踩坑記錄)
![[AI React Web] 包與依賴管理 | `axios`庫 | `framer-motion`庫](http://pic.xiahunao.cn/[AI React Web] 包與依賴管理 | `axios`庫 | `framer-motion`庫)




)


