摘要
本文介紹了HDFS存儲系統,包括其組件、工作機制、實戰經驗總結、使用場景以及與SpringBoot的實戰示例和優化設計。HDFS由Client、NameNode、SecondaryNameNode、DataNode等組件構成,通過特定的工作機制實現文件的讀取和寫入。它適用于多種場景,如日志采集、大數據離線分析等,但也有不適用的場景。文中還展示了如何在SpringBoot項目中使用HDFS,包括引入依賴、配置文件、配置類、操作服務類和控制器層的實現。最后探討了HDFS的優化設計。
1. HDFS分布式存儲系統簡介
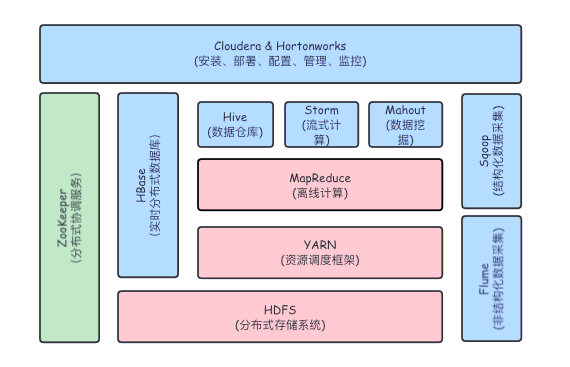
Apache Hadoop是一個開源的分布式計算框架,專門用來處理大規模數據集。Hadoop 是一套分布式系統框架,包括:分布式存儲技術 HDFS、分布式資源調度技術 YARN、分布式計算框架 MapReduce。
組件 | 全稱 | 功能 |
HDFS | Hadoop Distributed File System | 分布式存儲系統:將大文件切分成多個小塊,分布存儲在多臺機器上,具備容錯、冗余、高吞吐的特點。 |
YARN | Yet Another Resource Negotiator | 資源調度與管理系統:負責管理集群中的計算資源,并調度任務運行(如 MapReduce)。 |
MR | MapReduce | 分布式計算框架:一種基于“Map”與“Reduce”模型的數據處理方式,適合批處理大數據。 |
- HDFS: 是 Hadoop 的基礎存儲系統,Master是NameNode,Slave是DataNode。
- YARN: 是從 Hadoop 2.0 開始引入的新資源管理框架,主要包括 ResourceManager、NodeManager。
- MapReduce: 是最早期的 Hadoop 計算模型,現在很多場景已被 Spark、Flink 替代(效率更高,支持流處理)。
除了上述核心,Hadoop 還衍生出一系列生態工具:
組件 | 功能 |
Hive | 數據倉庫工具,支持 SQL 查詢(將 SQL 轉為 MapReduce 任務) |
HBase | 基于 HDFS 的分布式列式數據庫,支持實時讀寫 |
Pig | 高層數據流語言,抽象 MapReduce 操作 |
Sqoop | 用于在 Hadoop 與 RDBMS(MySQL、Oracle)間導入導出數據 |
Zookeeper | 分布式協調服務(服務發現、元數據管理) |
Oozie | 用于調度 Hadoop 作業的工作流系統 |
1.1. HDFS的組件
HDFS (Hadoop Distributed File System, 分布式文件系統) 是Google公司的GFS論文思想的實現,也作為 Hadoop 的存儲系統,它包含客戶端(Client)、元數據節點(NameNode)、備份節點(Secondary NameNode)以及數據存儲節點(DataNode)。
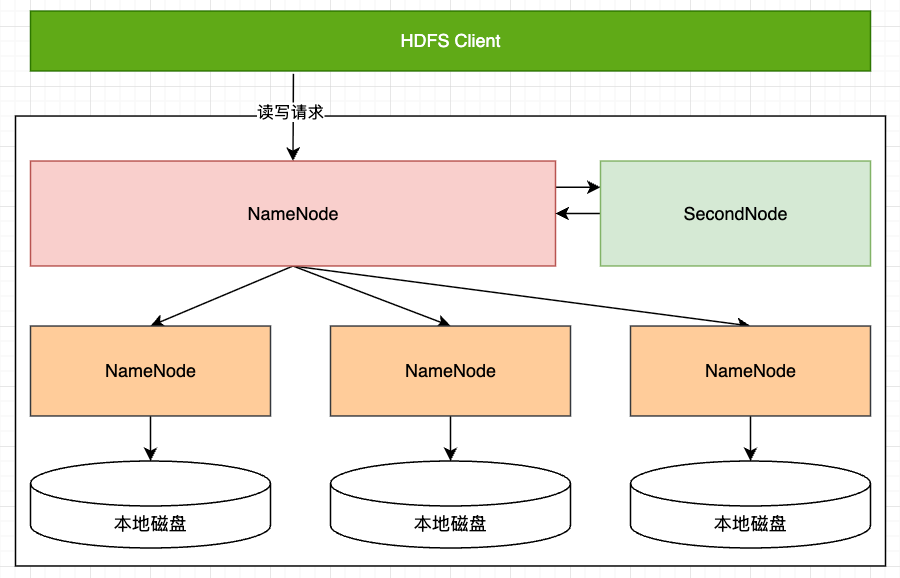
1.1.1. Client
HDFS 利用分布式集群節點來存儲數據,并提供統一的文件系統訪問接口。這樣,用戶在使用分布式文件系統時就如同在使用普通的單節點文件系統一樣,僅通過對 NameNode 進行交互訪問就可以實現操作HDFS中的文件。HDFS提供了非常多的客戶端,包括命令行接口、Java API、Thrift接口、Web界面等。
1.1.2. NameNode
NameNode 作為 HDFS 的管理節點,負責保存和管理分布式系統中所有文件的元數據信息,如果將 HDFS 比作一本書,那么 NameNode 可以理解為這本書的目錄。
其職責主要有以下三點:
- 負責接收 Client 發送過來的讀寫請求;
- 管理和維護HDFS的命名空間: 元數據是以鏡像文件(fsimage)和編輯日志(editlog)兩種形式存放在本地磁盤上的,可以記錄 Client 對 HDFS 的各種操作,比如修改時間、訪問時間、數據塊信息等。
- 監控和管理DataNode:負責監控集群中DataNode的健康狀態,一旦發現某個DataNode宕掉,則將該 DataNode 從 HDFS 集群移除并在其他 DataNode 上重新備份該 DataNode 的數據(該過程被稱為數據重平衡,即rebalance),以保障數據副本的完整性和集群的高可用性。
1.1.3. SecondaryNameNode
SecondaryNameNode 是 NameNode 元數據的備份,在NameNode宕機后,SecondaryNameNode 會接替 NameNode 的工作,負責整個集群的管理。并且出于可靠性考慮,SecondaryNameNode 節點與 NameNode 節點運行在不同的機器上,且 SecondaryNameNode 節點與 NameNode 節點的內存要一樣大。
同時,為了減小 NameNode 的壓力,NameNode 并不會自動合并 HDFS中的元數據鏡像文件(fsimage)和編輯日志(editlog),而是將該任務交由 SecondaryNameNode 來完成,在合并完成后將結果發送到NameNode, 并再將合并后的結果存儲到本地磁盤。
1.1.4. DataNode
存放在HDFS上的文件是由數據塊組成的,所有這些塊都存儲在DataNode節點上。DataNode 負責具體的數據存儲,并將數據的元信息定期匯報給 NameNode,并在 NameNode 的指導下完成數據的 I/O 操作。
實際上,在DataNode節點上,數據塊就是一個普通文件,可以在DataNode存儲塊的對應目錄下看到(默認在$(dfs.data.dir)/current的子目錄下),塊的名稱是 blk_ID,其大小可以通過dfs.blocksize設置,默認為128MB。
初始化時,集群中的每個 DataNode 會將本節點當前存儲的塊信息以塊報告的形式匯報給 NameNode。在集群正常工作時,DataNode 仍然會定期地把最新的塊信息匯報給 NameNode,同時接收 NameNode 的指令,比如創建、移動或刪除本地磁盤上的數據塊等操作。
1.1.5. HDFS數據副本
HDFS 文件系統在設計之初就充分考慮到了容錯問題,會將同一個數據塊對應的數據副本(副本個數可設置,默認為3)存放在多個不同的 DataNode 上。在某個 DataNode 節點宕機后,HDFS 會從備份的節點上讀取數據,這種容錯性機制能夠很好地實現即使節點故障而數據不會丟失。
1.2. HDFS的工作機制
1.2.1. NameNode 工作機制
NameNode簡稱NN
- NN 啟動后,會將鏡像文件(fsimage)和編輯日志(editlog)加載進內存中;
- 客戶端發來增刪改查等操作的請求;
- NN 會記錄下操作,并滾動日志,然后在內存中對操作進行處理。
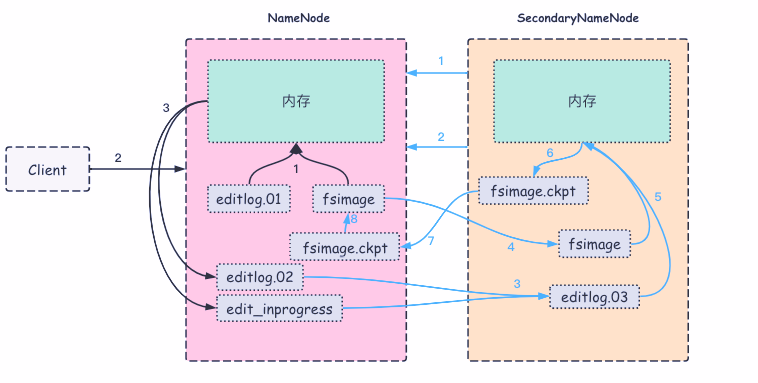
1.2.2. SecondaryNameNode工作機制
SecondaryNameNode簡稱2NN
- 當編輯日志數據達到一定量或者每隔一定時間,就會觸發 2NN 向 NN 發出 checkpoint請求;
- 如果發出的請求有回應,2NN 將會請求執行 checkpoint 請求;
- 2NN 會引導 NN 滾動更新編輯日志,并將編輯日志復制到 2NN 中;
- 同編輯日志一樣,將鏡像文件復制到 2NN 本地的 checkpoint 目錄中;
- 2NN 將鏡像文件導入內存中,回放編輯日志,將其合并到新的fsimage.ckpt;
- 將 fsimage.ckpt 壓縮后寫入到本地磁盤;
- 2NN 將 fsimage.ckpt 傳給 NN;
- NN 會將新的 fsimage.ckpt 文件替換掉原來的 fsimage,然后直接加載和啟用該文件。
1.2.3. HDFS文件的讀取流程
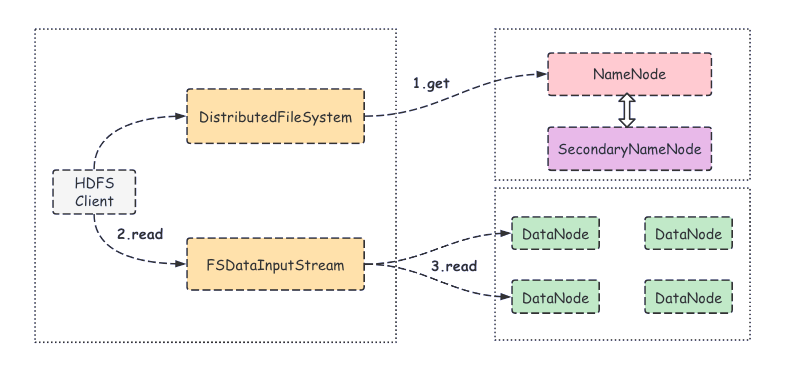
- 客戶端調用FileSystem 對象的open()方法,其實獲取的是一個分布式文件系統(DistributedFileSystem)實例;
- 將所要讀取文件的請求發送給 NameNode,然后 NameNode 返回文件數據塊所在的 DataNode 列表(是按照 Client 距離 DataNode 網絡拓撲的遠近進行排序的),同時也會返回一個文件系統數據輸入流(FSDataInputStream)對象;
- 客戶端調用 read() 方法,會找出最近的 DataNode 并連接;
- 數據從 DataNode 源源不斷地流向客戶端。
1.2.4. HDFS文件的寫入流程
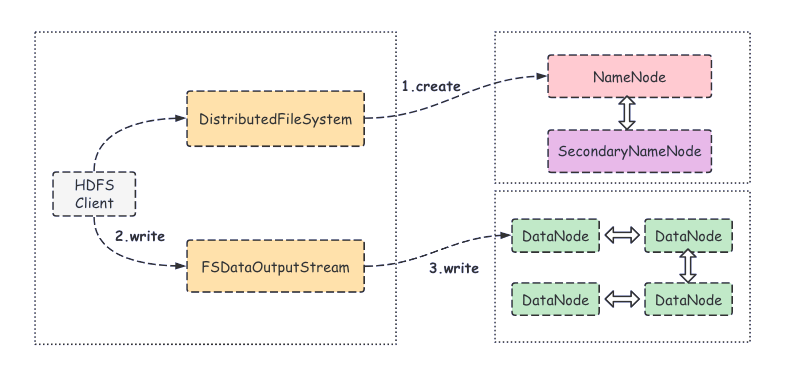
- 客戶端通過調用分布式文件系統(DistributedFileSystem)的create()方法創建新文件;
- DistributedFileSystem 將文件寫入請求發送給 NameNode,此時 NameNode 會做各種校驗,比如文件是否存在,客戶端有無權限去創建等;
- 如果校驗不通過則會拋出I/O異常。如果校驗通過,NameNode 會將該操作寫入到編輯日志中,并返回一個可寫入的 DataNode 列表,同時,也會返回文件系統數據輸出流(FSDataOutputStream)的對象;
- 客戶端在收到可寫入列表之后,會調用 write() 方法將文件切分為固定大小的數據包,并排成數據隊列;
- 數據隊列中的數據包會寫入到第一個 DataNode,然后第一個 DataNode 會將數據包發送給第二個 DataNode,依此類推。
- DataNode 收到數據后會返回確認信息,等收到所有 DataNode 的確認信息之后,寫入操作完成。
2. HDFS實戰經驗總結
2.1. HDFS存儲系統和Mysql數據庫有什么區別?
這是一個非常經典的問題,HDFS 和 MySQL 都可以“存數據”,HDFS 是為了解決“海量數據的高吞吐分布式存儲”,MySQL 是為了解決“結構化數據的實時存儲與查詢”問題。但它們的定位、設計目標、使用場景完全不同。下面我們從多個維度來對比,幫你全面理解它們的區別。
2.1.1. 🆚 HDFSvsMySQL:核心區別
維度 | HDFS(Hadoop Distributed File System) | MySQL(關系型數據庫) |
🔧 類型 | 分布式文件系統 | 關系型數據庫管理系統(RDBMS) |
📦 數據結構 | 存儲文件(文本、日志、圖片、音視頻、大數據文件等) | 存儲結構化數據表(表格、字段、行、列) |
🧱 數據組織 | 無結構,按塊切分存儲(默認128MB或更大) | 有結構,嚴格遵守表結構和約束 |
🧮 查詢能力 | 不提供查詢語言,需結合 Hive、Spark 等實現 SQL 分析 | 提供 SQL 查詢語言(SELECT、JOIN、GROUP BY 等) |
📊 適合數據類型 | 非結構化/半結構化/大規模數據 | 結構化數據 |
📁 存儲方式 | 把文件分成多個 Block 分布在不同機器上存儲 | 將數據表存儲在本地磁盤或SSD中 |
💾 讀寫模式 | 高吞吐量、寫一次讀多次,適合大批量讀寫 | 低延遲、頻繁讀寫,支持事務 |
📈 擴展性 | 高度可擴展,輕松支持 PB 級別 | 擴展能力有限(主從復制、分庫分表) |
?? 容錯機制 | 自動副本、多副本容錯(默認3份) | 依賴主從復制機制,手動或腳本化恢復 |
💻 應用場景 | 大數據存儲、日志存儲、機器學習、視頻/圖片歸檔等 | 交易系統、用戶信息、訂單管理、財務報表等傳統 OLTP 場景 |
2.1.2. 🧠 HDFS 和 MySQL比較
類比方式 | 說明 |
HDFS 像分布式硬盤 | 把大量文件分散存儲在多臺機器上,就像一個巨大的分布式網盤 |
MySQL像電子表格 | 數據結構清晰,有行有列,便于查找、過濾、分析 |
2.1.3. 📌 舉個具體例子:
假設你是風控系統的開發者:
- 你用MySQL存:用戶表、借款記錄表、規則配置表,支持事務操作和實時查詢。
- 你用HDFS存:用戶調用記錄日志、歷史交易大數據、用戶行為日志、模型訓練數據等,支持后續批量分析。
2.2. HDFS存儲系統的使用場景?
HDFS(Hadoop Distributed File System)是專門為大數據存儲與處理設計的分布式文件系統。它不是用來替代數據庫的,而是為了解決傳統存儲系統難以處理海量數據、超大文件、高吞吐量、分布式讀寫的問題。以下是 HDFS 最常見的典型使用場景,你可以根據業務系統的特點對號入座:
2.2.1. 日志采集與分析
📁 應用場景:收集海量系統日志、用戶行為日志、訪問記錄、接口調用日志等。
📌 為什么適合 HDFS:
- 數據量大(PB 級別)
- 文件多且持續產生(寫一次、讀多次)
- 不需要實時查詢,適合離線分析
? 常與 Flume + Hive/Spark 組合使用。
2.2.2. 大數據離線分析
📁 應用場景:大數據報表、風控畫像、模型訓練、批量數據清洗等。
📌 為什么適合 HDFS:
- 存儲 TB / PB 級原始數據或中間計算結果
- 結合 Hive、Spark、MapReduce 實現大規模分析任務
? 適用于風控系統中的用戶信用評分建模、交易異常批量分析等場景。
2.2.3. 機器學習/模型訓練數據存儲
📁 應用場景:用于訓練風控模型、推薦系統、CTR模型等的訓練數據。
📌 為什么適合 HDFS:
- 支持大文件、批量處理
- 與 Spark ML、TensorFlow on Hadoop 等兼容
? 可結合 Spark MLlib、TensorFlow on HDFS 使用。
2.2.4. 視頻、圖片等大文件歸檔
📁 應用場景:視頻監控數據、圖像識別數據、大量媒體內容存儲。
📌 為什么適合 HDFS:
- 文件大(幾百 MB 至 GB)
- 不需要高并發小文件隨機讀寫
- 存儲成本低,可用廉價硬盤搭建
? 適合“冷數據”存檔、后續批處理。
2.2.5. 數據中臺/湖倉一體系統的底層存儲
📁 應用場景:大數據中臺、數據湖架構中用于統一存儲各類結構化、非結構化數據。
📌 為什么適合 HDFS:
- 與 Hive、Iceberg、Hudi 等表格式存儲系統集成
- 支持數據分區、Schema 管理、演化
? 可作為 Data Lake(數據湖)中的底層文件系統。
2.2.6. ETL/數據清洗任務的中間文件存儲
📁 應用場景:在數據從業務系統導入、加工、清洗的過程中,作為中間結果文件存儲系統。
📌 為什么適合 HDFS:
- 高吞吐讀寫
- 支持批量清洗、轉換任務(如 Spark Job)
? 通常搭配 Spark、Hive、Oozie 使用。
2.2.7. 企業級風控/征信系統中的大數據底座
📁 應用場景:風控評分引擎、規則引擎的大數據支撐層。
📌 為什么適合 HDFS:
- 存儲來自多渠道的數據源(APP、WEB、第三方接口)
- 支持跨平臺、跨語言的訪問(Java、Python、Scala)
2.2.8. 🚫 不適合 HDFS 的場景(謹記)
場景 | 不推薦使用 HDFS 原因 |
頻繁更新、插入的業務系統(如 OLTP) | HDFS 不支持小文件頻繁寫入和更新 |
實時查詢、低延遲需求的系統 | HDFS 是批處理設計,不支持毫秒級響應 |
小文件非常多(數千萬個 < 1MB 的文件) | 小文件會導致 NameNode 元數據壓力過大 |
2.3. HDFS 中NameNode 是怎么管理dataNode,他們是怎么通信的?
在 HDFS(Hadoop Distributed File System)中,NameNode 與 DataNode 之間的通信機制是 HDFS 架構中最核心的部分之一。它實現了文件系統的元數據管理和數據塊的實際存儲的協作。NameNode 負責大腦調度與指揮(元數據、分配 block、恢復副本),DataNode 負責干活(存儲數據塊)。二者之間通過 心跳、Block 報告、命令下發實現協調合作。 下面詳細說明:
2.3.1. 🧠 NameNode 與 DataNode 的職責
角色 | 作用 |
NameNode | 管理元數據:如文件目錄結構、權限、文件到 block 的映射、block 到 DataNode 的映射等 |
DataNode | 存儲實際的數據塊(block),并定期向 NameNode 匯報其狀態 |
2.3.2. 🔌 通信機制詳解
HDFS 中 NameNode 和 DataNode 是通過TCP 協議進行通信的,主要有兩種類型的通信:
2.3.2.1. 1?? 心跳(Heartbeat)
- 目的:讓 NameNode 知道哪些 DataNode 還活著;
- 頻率:每 3 秒一次(默認
dfs.heartbeat.interval=3); - 通道:DataNode 主動向 NameNode 發送;
- 攜帶內容:
- DataNode 的 ID;
- 當前使用量、剩余空間;
- 是否處于運行狀態;
- NameNode 響應:
- 是否需要發送 block 報告(Block Report);
- 是否需要復制、刪除某些 block;
- 啟動 block 的復制或刪除命令;
2.3.2.2. 2?? Block 報告(Block Report)
- 目的:告訴 NameNode:這個 DataNode 存儲了哪些 block;
- 頻率:每 6 小時(默認
dfs.blockreport.intervalMsec=21600000); - 內容:所有 block 的 ID、長度、版本等;
- 作用:維護 NameNode 的 block-to-DataNode 映射;
2.3.2.3. 3?? 增量 block 報告(Incremental Block Report)
- 觸發時機:當 DataNode 有新的 block 寫入、刪除或復制;
- 作用:比 Block 報告更及時,減少元數據滯后;
2.3.2.4. 4?? 客戶端讀寫時的協調(NameNode 作為調度者)
- 寫操作:
- 客戶端向 NameNode 請求寫入;
- NameNode 返回可用的若干 DataNode 地址(用于副本);
- 客戶端直接與這些 DataNode 通信寫入 block;
- 讀操作:
- 客戶端向 NameNode 請求讀取文件;
- NameNode 返回 block 所在的 DataNode 列表;
- 客戶端直接從 DataNode 拉取數據;
2.3.3. 🔄 容錯與故障檢測機制
- 超時判定失效節點:
- 如果某個 DataNode 在 10.5 分鐘內(默認 3 秒 × 210 次)沒有心跳,NameNode 會判定它掛掉(
dfs.namenode.heartbeat.recheck-interval);
- 如果某個 DataNode 在 10.5 分鐘內(默認 3 秒 × 210 次)沒有心跳,NameNode 會判定它掛掉(
- 副本恢復:
- NameNode 會自動觸發 block 復制以確保副本數量(
dfs.replication); - 可通過其他 DataNode 重新恢復副本到健康節點;
- NameNode 會自動觸發 block 復制以確保副本數量(
2.4. 🧪 可視化示意圖
[Client]| 寫/讀請求v
[NameNode] <--------- 心跳、Block報告 --------- [DataNode 1]| [DataNode 2]| [DataNode 3]|響應 block 位置信息|
[Client 與 DataNode 通信完成真正的 I/O]2.5. HDFS中NameNode和DataNode是通過TCP協議進行通信的是通過發送http請求嗎?
HDFS中NameNode和DataNode 是通過 TCP 協議通信的,但不是通過 HTTP 請求通信,主要通過以下兩種機制:
2.5.1. ? 通信協議:HDFS自定義的RPC(遠程過程調用)協議
- NameNode 與 DataNode、Client 之間的通信使用的是 Hadoop 自定義的 RPC 協議,底層是基于 TCP。
- 它不是 HTTP 協議,而是 通過Java 的 Netty/NIO 框架 自定義的高性能傳輸機制。
2.5.2. ? NameNode與DataNode通信流程
2.5.2.1. 📌 啟動時注冊
- DataNode 啟動后,會向 NameNode 發起注冊請求(RPC 形式),發送自己的 IP、端口、存儲容量等信息。
2.5.2.2. 📌 定期心跳(默認3秒)
- DataNode 每隔一段時間(默認 3 秒)向 NameNode 發送心跳包,報告存活狀態。
- 如果 NameNode 超過 10.5 秒(默認值)沒收到心跳,就認為該節點掛了。
2.5.2.3. 📌 Block 匯報
- 每隔一小時或在 Block 變更時,DataNode 會向 NameNode 發送 block 匯報,說明自己當前有哪些 block。
2.5.3. ? Client與DataNode的通信
- 當客戶端(Client)讀寫數據時,會先通過 RPC 向 NameNode 獲取數據塊位置(block 和 DataNode 的映射信息)。
- 然后客戶端通過 TCP 直接和 DataNode 通信來讀寫數據,這時候 使用的是 HTTP 協議的子集(叫做 DataTransferProtocol),仍然是基于 TCP。
2.5.4. 🔁 NameNode和DataNode總結
通信雙方 | 協議類型 | 是否基于 TCP | 是否 HTTP |
NameNode ? DataNode | Hadoop RPC | ? 是 | ? 否 |
NameNode ? Client | Hadoop RPC | ? 是 | ? 否 |
Client ? DataNode | DataTransfer 協議 | ? 是 | ? 是(部分) |
2.6. DataNode 每隔一段時間(默認 3 秒)向 NameNode 發送心跳包,報告存活狀態。 是通過定時任務觸發嗎?
是的,DataNode 向 NameNode 發送心跳包是通過定時任務觸發的,具體實現是在 DataNode 的內部線程機制中完成的。
2.6.1. 🔧 DataNode 心跳機制的執行原理
2.6.1.1. ? 背景線程:BPServiceActor
DataNode 啟動時,會為每一個 Block Pool 啟動一個 BPServiceActor(Block Pool Service Actor)線程,這個線程的主要任務包括:
- 定期向 NameNode 發送心跳(Heartbeat)
- 匯報 block 列表(Block Report)
- 發送增量的 block 通知(Incremental Block Report)
這些任務都通過定時機制觸發。
2.6.1.2. ? 心跳定時任務調度邏輯
在源碼中,心跳邏輯大致如下(Hadoop 3.x):
// 每個 BPServiceActor 都維護一個線程,周期性執行:
while (shouldRun) {long startTime = Time.monotonicNow();// 心跳間隔檢查if (shouldSendHeartbeat()) {sendHeartBeat(); // 發送心跳}// 處理 Block Report、Command 等等processCommandFromNameNode();long sleepTime = computeNextWaitTime(startTime);Thread.sleep(sleepTime);
}默認心跳間隔配置項:dfs.heartbeat.interval,默認值是 3 秒。
2.7. 🔍 NameNode如何處理心跳
NameNode 接收到心跳包后,會:
- 更新對應 DataNode 的“最后心跳時間”
- 檢查 DataNode 的狀態(健康、存儲、負載等)
- 向 DataNode 返回指令(如:刪除某些 block、副本遷移等)
如果 NameNode 超過 dfs.heartbeat.timeout(默認 10.5 秒 = 3.0 × 3 × 1.5)沒有收到心跳,就認為該 DataNode 已失聯,觸發副本重分配。
2.8. ? NameNode心跳總結
項目 | 內容 |
心跳機制 | 是由 DataNode 內部定時線程完成的 |
實現方式 | 使用后臺線程 + 間隔輪詢機制(非 Timer) |
默認心跳間隔 |
|
心跳處理 | NameNode 更新狀態 + 返回操作指令 |
2.9. NameNode心跳采用sleep 是不是效率不高? 為啥cronjob 來實現?
下面我從底層線程調度原理、性能考慮以及為什么 HDFS 不用 cronjob 來逐步回答你的問題。
2.9.1. ? Thread.sleep() 是否效率不高?
2.9.1.1. ? 它的本質是什么?
Thread.sleep(ms) 的本質是:
- 當前線程主動讓出 CPU,進入 TIMED_WAITING 狀態。
- 在指定時間后由系統調度器喚醒,繼續運行。
2.9.1.2. ? 優點:
- 低 CPU 占用:線程在 sleep 時不消耗 CPU。
- 實現簡單:只需 sleep 循環即可實現定時行為。
2.9.1.3. ?? 缺點:
- 不是精準的定時器(受限于系統調度粒度);
- 無法處理復雜的定時調度(如:每小時整點、每日0點等);
- 對于大量線程 sleep-wake,系統調度器壓力會增加。
但在 HDFS 的這種周期性任務中,這種方式其實是足夠輕量且高效的。
2.9.2. ? 為什么不用 cron job?
你指的是系統級的 cron(Linux 中的定時任務)嗎?HDFS 不用 cron 的原因如下:
2.9.2.1. 🚫 cron job 是系統級進程,不能高頻運行
cron最小精度是 分鐘級,不適合每 3 秒運行一次;- 調用外部命令的方式也會引入啟動開銷。
2.9.2.2. 🚫 Hadoop 是多線程服務進程,不是腳本系統
DataNode是一個長時間運行的 Java 后臺服務;- 使用 cron 等外部定時器調度 Java 內部邏輯是不合適的。
2.9.3. ? 為什么不用Java的ScheduledExecutorService?
其實 Hadoop 也有一些地方使用了類似 ScheduledExecutorService,但在 DataNode 這種核心、頻繁的心跳邏輯中:
- 為了最大控制權和性能,Hadoop 更傾向使用自己控制的循環 + sleep;
- 它也能更方便地處理異常、網絡延遲、自適應重試等高級邏輯。
2.9.4. ? NameNode心跳sleep/cron總結
對比點 | Thread.sleep | cron job |
調度精度 | 毫秒級(但不準) | 分鐘級 |
CPU 占用 | 低 | 無(但需啟動子進程) |
適合頻率 | 高頻調度(如每秒/3秒) | 低頻調度(如每小時/每天) |
適用場景 | 后臺服務內部定時邏輯 | 系統腳本、任務調度器 |
Hadoop 是否使用? | ? 使用 | ? 不使用 |
在 HDFS 中使用 Thread.sleep() 控制心跳周期,是一種 高效、可控、適合服務進程的方式。相比之下,cron job 不適合這種場景。
3. HDFS+SpringBoot實戰示例
下面是一個完整的 Spring Boot + HDFS 實戰示例,涵蓋以下核心操作:
功能點包括:
- 上傳文件到 HDFS
- 從 HDFS 下載文件
- 刪除 HDFS 文件
- 列出目錄下文件
3.1. 🧱 引入依賴(pom.xml)
<dependencies><!-- Spring Boot 核心依賴 --><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter</artifactId></dependency><!-- Hadoop HDFS 依賴 --><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-common</artifactId><version>3.3.6</version></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-hdfs</artifactId><version>3.3.6</version></dependency><!-- Spring Web --><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency>
</dependencies>🔧 Hadoop 版本請與你的 HDFS 集群保持一致。
3.2. ?? 配置文件 application.yml
hdfs:uri: hdfs://localhost:9000 # 替換為你集群的地址3.3. 🧩 HDFS 配置類
@Configuration
public class HdfsConfig {@Value("${hdfs.uri}")private String hdfsUri;@Beanpublic FileSystem fileSystem() throws IOException {Configuration config = new Configuration();config.set("fs.defaultFS", hdfsUri);// 如果你使用的是 HA 或 Kerberos,需額外配置return FileSystem.get(URI.create(hdfsUri), config);}
}3.4. 💼 四、HDFS 操作服務類
@Service
public class HdfsService {@Autowiredprivate FileSystem fileSystem;public void uploadFile(MultipartFile file, String hdfsPath) throws IOException {try (FSDataOutputStream output = fileSystem.create(new Path(hdfsPath));InputStream input = file.getInputStream()) {IOUtils.copyBytes(input, output, 4096, true);}}public byte[] downloadFile(String hdfsPath) throws IOException {try (FSDataInputStream input = fileSystem.open(new Path(hdfsPath));ByteArrayOutputStream output = new ByteArrayOutputStream()) {IOUtils.copyBytes(input, output, 4096, false);return output.toByteArray();}}public boolean deleteFile(String hdfsPath) throws IOException {return fileSystem.delete(new Path(hdfsPath), true);}public List<String> listFiles(String hdfsDir) throws IOException {FileStatus[] statuses = fileSystem.listStatus(new Path(hdfsDir));List<String> files = new ArrayList<>();for (FileStatus status : statuses) {files.add(status.getPath().toString());}return files;}
}3.5. 📦 控制器層HdfsController
@RestController
@RequestMapping("/hdfs")
public class HdfsController {@Autowiredprivate HdfsService hdfsService;@PostMapping("/upload")public ResponseEntity<String> upload(@RequestParam MultipartFile file,@RequestParam String path) {try {hdfsService.uploadFile(file, path);return ResponseEntity.ok("上傳成功: " + path);} catch (IOException e) {return ResponseEntity.status(500).body("上傳失敗: " + e.getMessage());}}@GetMapping("/download")public ResponseEntity<byte[]> download(@RequestParam String path) {try {byte[] content = hdfsService.downloadFile(path);return ResponseEntity.ok().header(HttpHeaders.CONTENT_DISPOSITION, "attachment; filename=" + Paths.get(path).getFileName()).body(content);} catch (IOException e) {return ResponseEntity.status(500).body(null);}}@DeleteMapping("/delete")public ResponseEntity<String> delete(@RequestParam String path) {try {boolean deleted = hdfsService.deleteFile(path);return ResponseEntity.ok(deleted ? "刪除成功" : "刪除失敗");} catch (IOException e) {return ResponseEntity.status(500).body("刪除失敗: " + e.getMessage());}}@GetMapping("/list")public ResponseEntity<List<String>> list(@RequestParam String dir) {try {return ResponseEntity.ok(hdfsService.listFiles(dir));} catch (IOException e) {return ResponseEntity.status(500).body(Collections.emptyList());}}
}4. HDFS優化設計
博文參考
《Hadoop原理》







)





NDK基礎)
的docker拉取倉庫失敗的加速方法)




