文章目錄
- ==有需要本項目的代碼或文檔以及全部資源,或者部署調試可以私信博主==
- 一、項目背景
- 二、項目目標
- 三、系統架構與技術選型
- 四、系統功能模塊
- 五、應用場景與價值
- 六、項目特色與創新點
- 七、總結
- 每文一語
有需要本項目的代碼或文檔以及全部資源,或者部署調試可以私信博主
一、項目背景
隨著信息技術的不斷發展和互聯網的廣泛普及,計算機相關資源如軟件教程、開源項目、技術文檔、硬件參數等在網絡上日益豐富。面對海量數據,如何高效、精準地收集、整理并呈現這些資源,成為提升學習效率與技術積累的關鍵。傳統的人工收集方式費時費力,且不具備實時更新能力。因此,開發一套能夠自動化爬取計算機資源并可視化展示的系統,對于提升資源利用率和信息獲取效率具有重要意義。
二、項目目標
本項目旨在開發一個基于Django框架的計算機資源爬蟲及可視化系統。系統將包括三個核心模塊:
- 資源爬蟲模塊:基于Python編寫的定向網絡爬蟲,可自動抓取指定網站上的計算機類資源,如開源項目信息、教程文章、硬件評測等。
- 數據管理模塊:通過Django后臺管理系統,實現對爬取數據的分類、存儲、檢索與管理功能。
- 可視化展示模塊:利用圖表與交互界面,直觀展示數據分布、趨勢、熱門話題等信息,幫助用戶高效獲取所需內容。
三、系統架構與技術選型
-
后端框架:Django
- Django作為一個高效、可擴展的Web框架,提供了完備的MVC結構,適合快速開發和部署;
- 利用其ORM(對象關系映射)功能,實現對數據庫中爬取資源的高效管理;
- 自帶的Admin管理后臺便于開發者進行數據審核和內容控制。
-
**爬蟲技術:Scrapy **
- 使用Scrapy框架構建高性能爬蟲;
- 配合Requests和BeautifulSoup庫,提高頁面解析和數據提取的靈活性;
- 支持定時爬取和反爬機制處理(如User-Agent偽裝、IP代理、請求限速等)。
-
數據庫:MySQL 或 PostgreSQL
- 存儲結構化的計算機資源數據;
- 配合Django ORM進行高效的數據操作。
-
前端技術:Vue+ Echarts/D3.js
- 前端頁面通過Bootstrap或Tailwind進行響應式設計;
- 使用Echarts或D3.js實現數據圖表的動態可視化,提供圖形界面如詞云、折線圖、柱狀圖等;
- 支持關鍵詞搜索、分類篩選等交互功能。
四、系統功能模塊
-
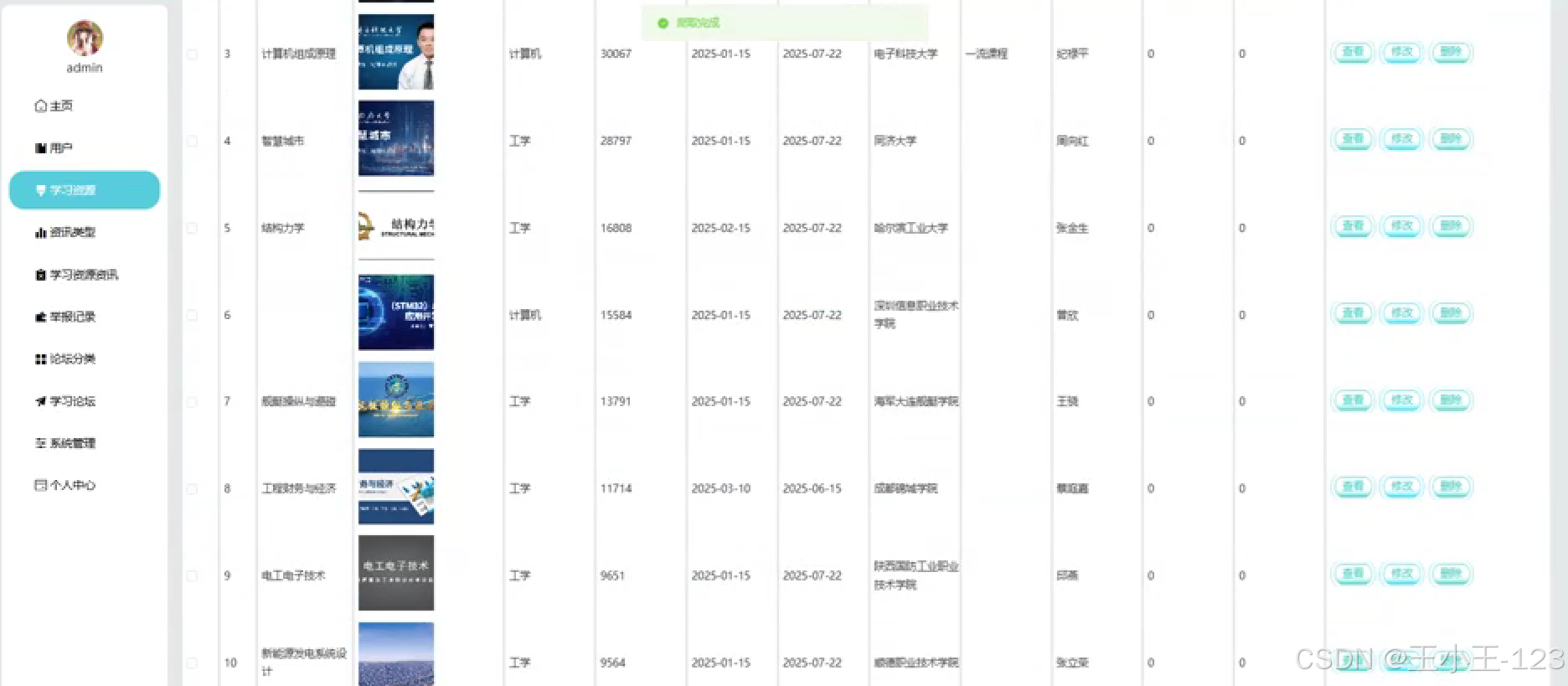
資源爬取
- 用戶可設定關鍵詞或選擇來源網站;
- 系統自動抓取頁面內容,并提取標題、內容摘要、URL、發布時間等信息;
- 定期自動更新數據,確保資源的時效性。
-
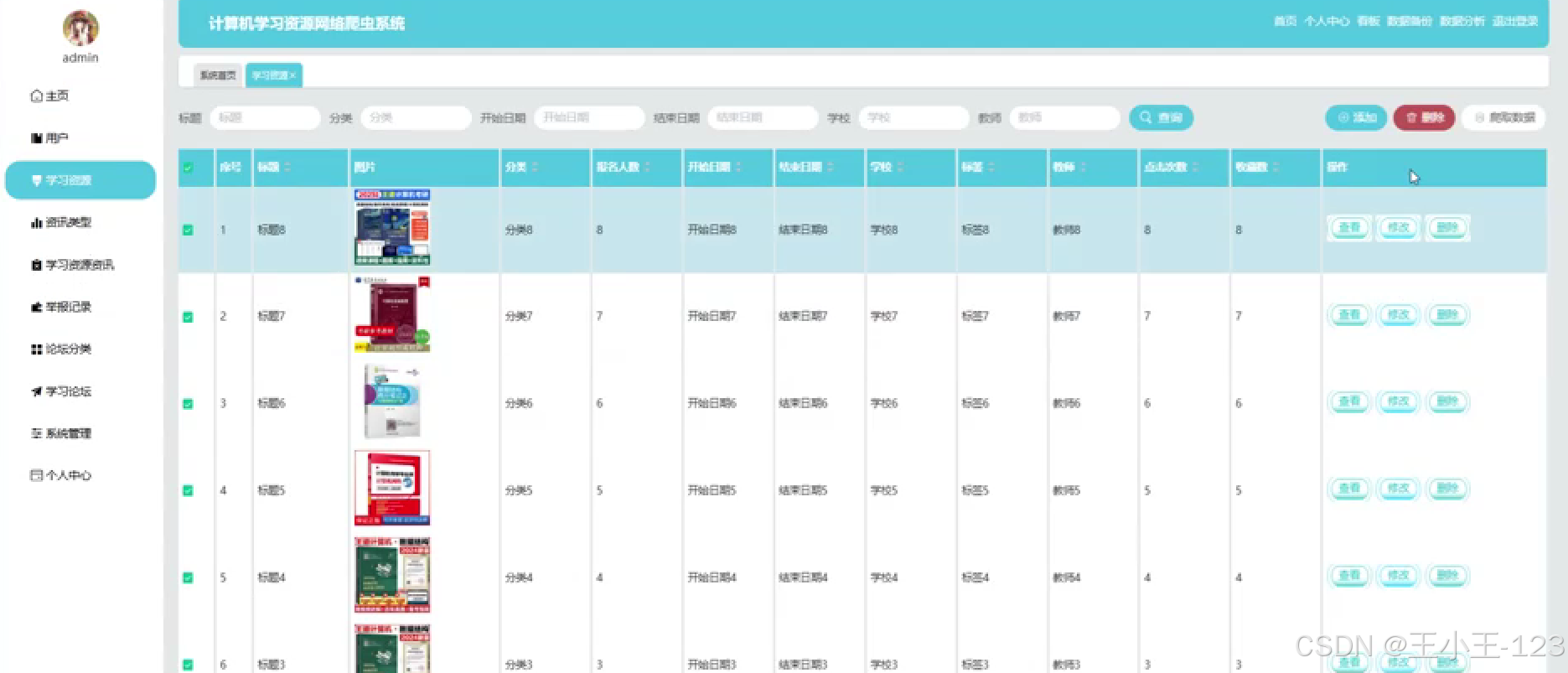
數據管理
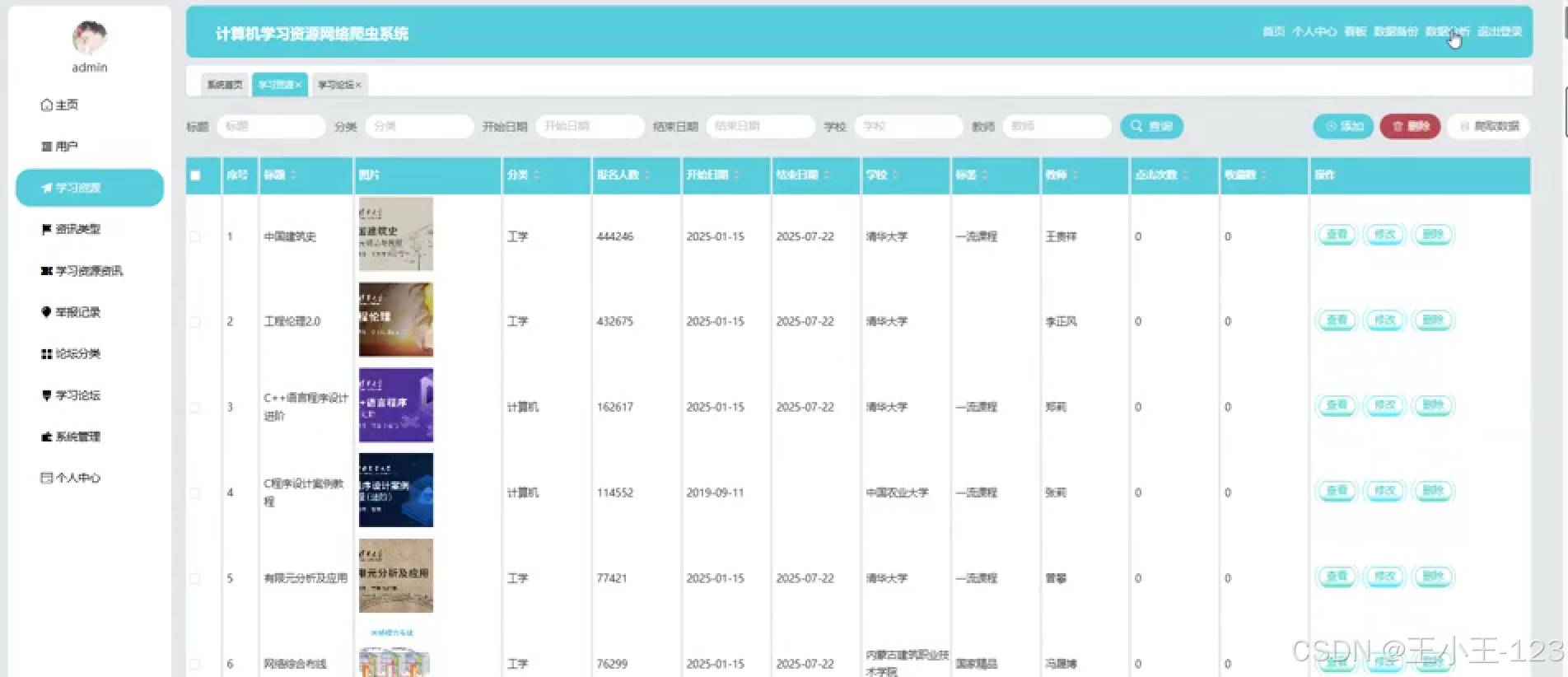
- 后臺管理系統用于審核、編輯、刪除或歸類資源;
- 提供分頁檢索、關鍵詞過濾、標簽管理等功能;
- 支持用戶評價或收藏功能;
-
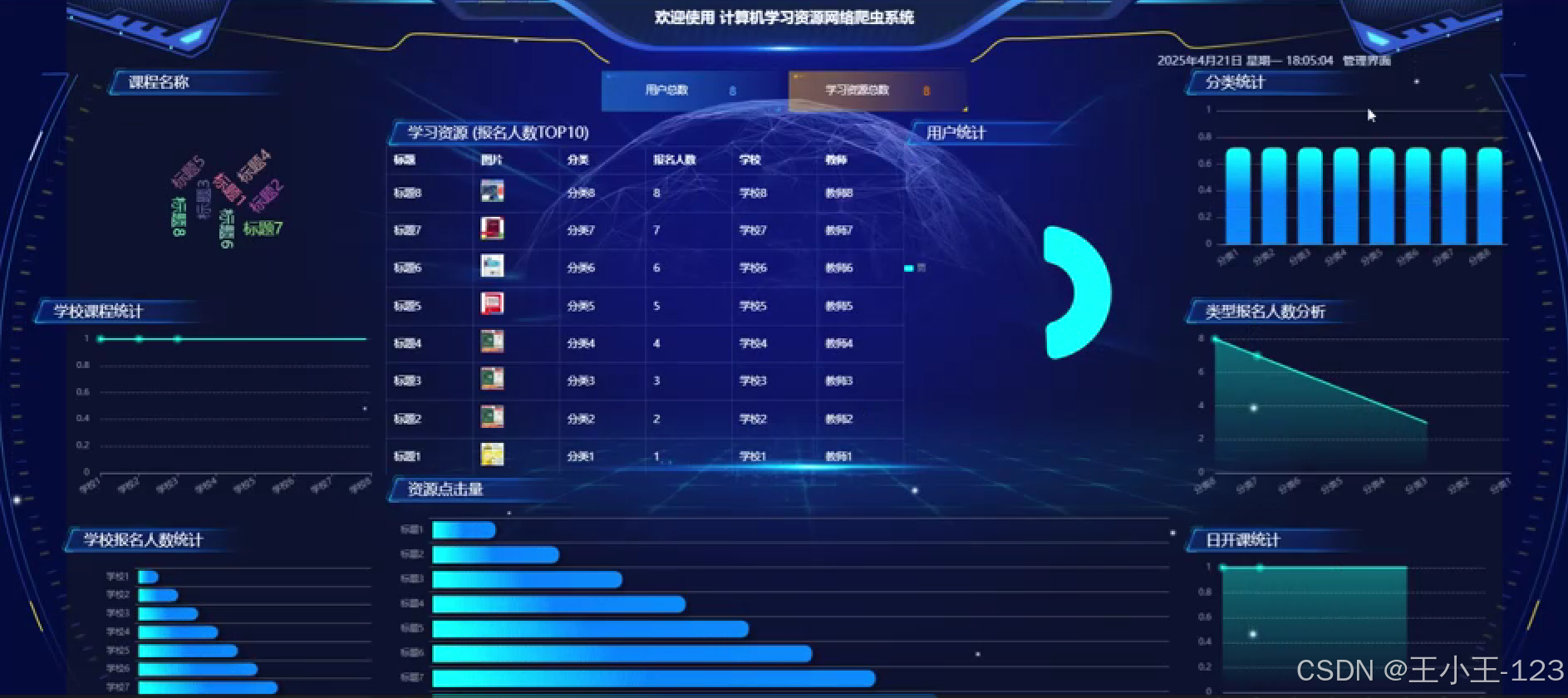
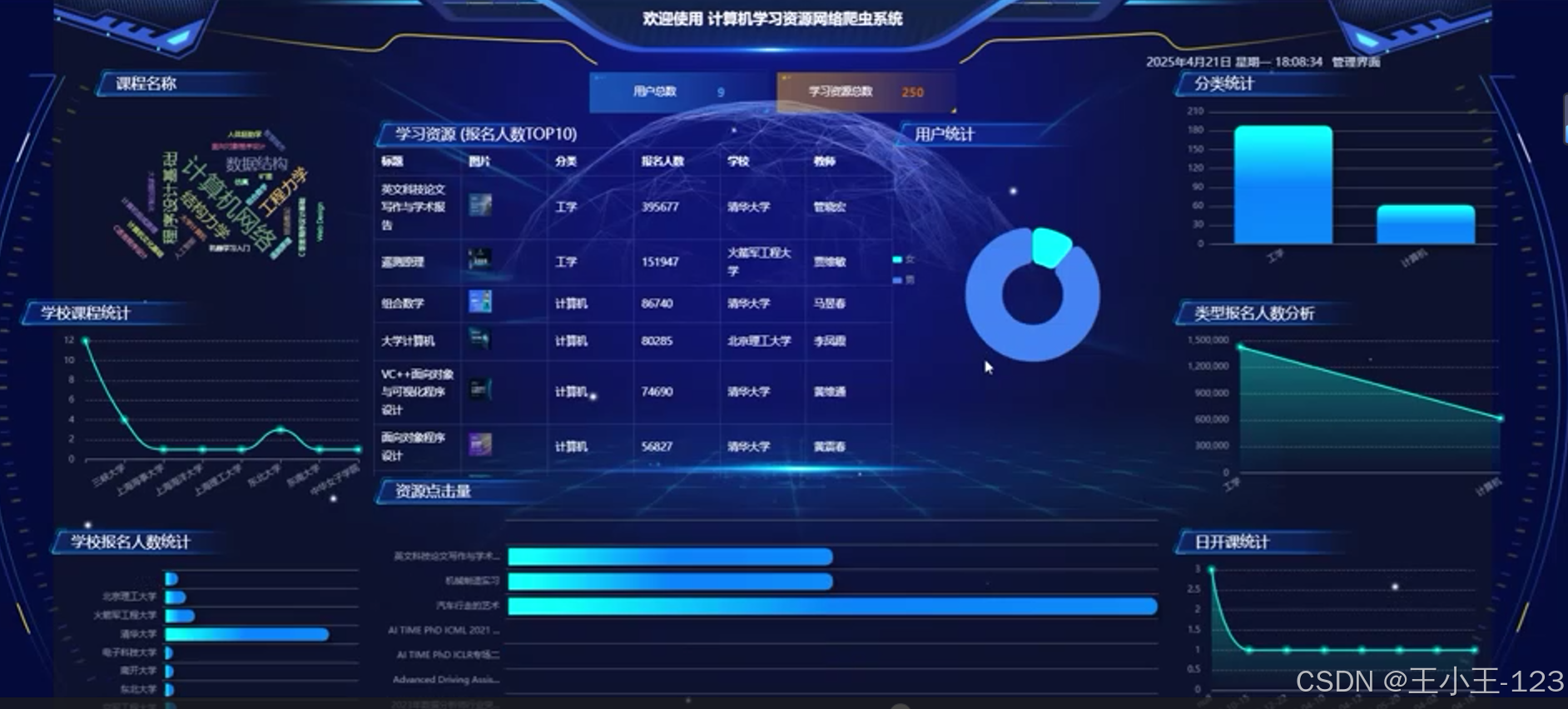
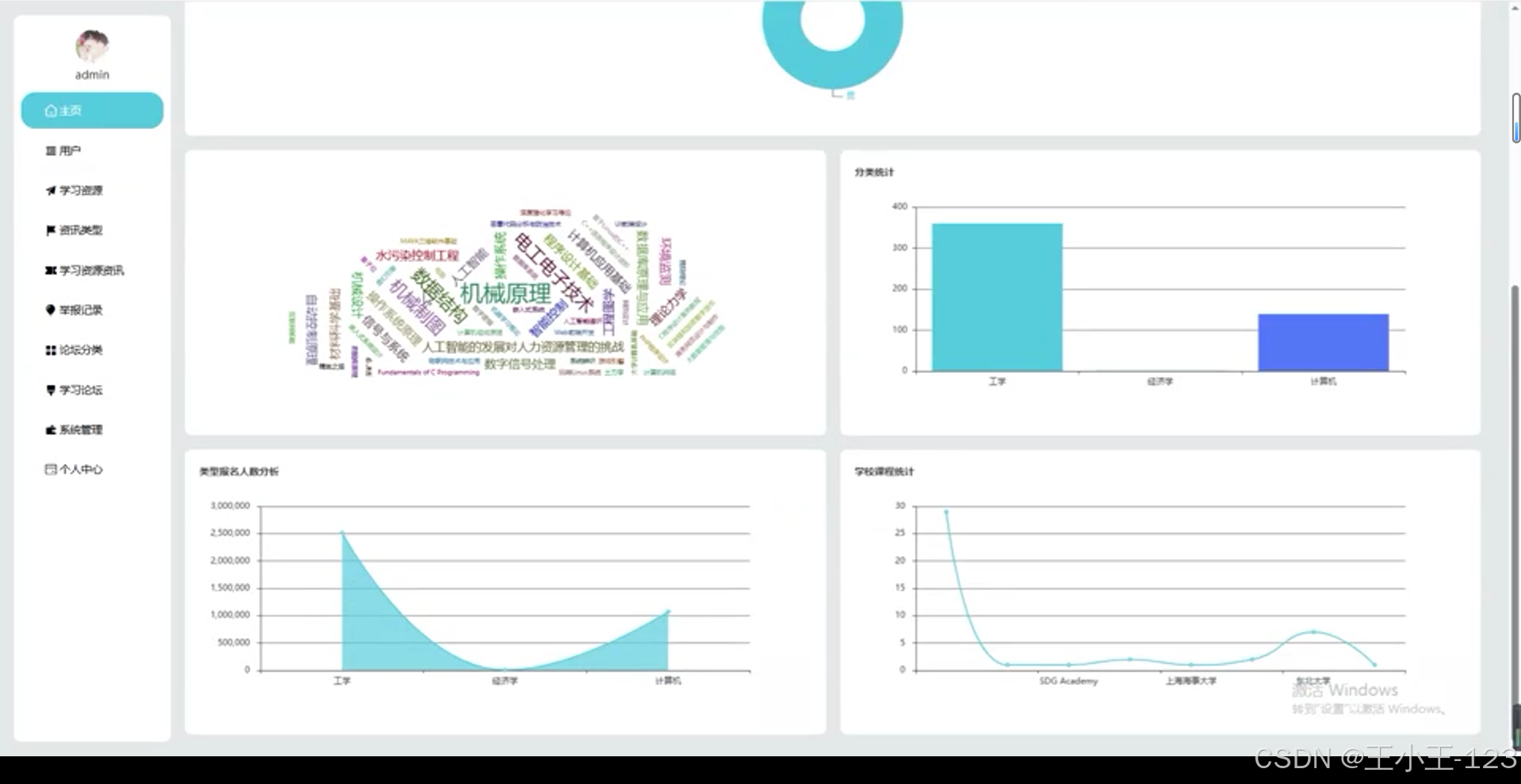
可視化展示
- 首頁展示資源總覽圖,如資源數量趨勢圖、熱門關鍵詞詞云;
- 提供各類圖表展示資源的類型分布、來源占比、發布時間曲線等;
- 可根據用戶偏好生成個性化推薦圖譜。
五、應用場景與價值
- 技術學習平臺:為學習者提供最新、最全的技術教程與工具;
- 信息聚合工具:整合多源資源,避免用戶在多個網站反復查找;
- 數據分析與決策支持:通過可視化圖表,快速洞察技術發展趨勢與用戶興趣變化;
- 輔助教學與研究:為高校教師或科研人員提供技術資料收集與展示平臺。
六、項目特色與創新點
- 基于Django實現后端一體化管理,開發效率高、可維護性強;
- 爬蟲模塊靈活可擴展,支持多站點、多類型資源采集;
- 可視化圖表增強用戶交互體驗,提高數據利用效率;
- 支持自定義爬取規則,具備良好的適應性和擴展性。
七、總結
“基于Django的計算機資源爬蟲及可視化系統”是一個集數據抓取、分類管理與可視化展示為一體的信息平臺。該系統不僅提高了計算機資源的獲取效率,也通過可視化手段降低了用戶獲取信息的門檻。隨著數據規模擴大和算法優化的加入,未來該系統可進一步拓展到更多領域,如人工智能、網絡安全、區塊鏈等,成為信息時代中高效的數據聚合與知識服務工具。


每文一語
本文無語
(IIC驅動開發))




GameMode之PlayerController)
與客戶端渲染(CSR)的區別及解決方案)


NDK進階及性能優化)







)

)