目錄
一、學科的產生與發展
1、什么是自然語言?
2、自然語言處理技術的誕生
二、技術挑戰
三、基本方法
1、方法概述
理性主義方法
經驗主義方法
2、傳統的統計學習方法
3、深度學習方法
詞向量表示
詞向量學習
開源工具
四、應用舉例
1、漢語分詞
(1)最大匹配法
(2)基于n-gram的分詞方法
(3)由字構詞的分詞方法
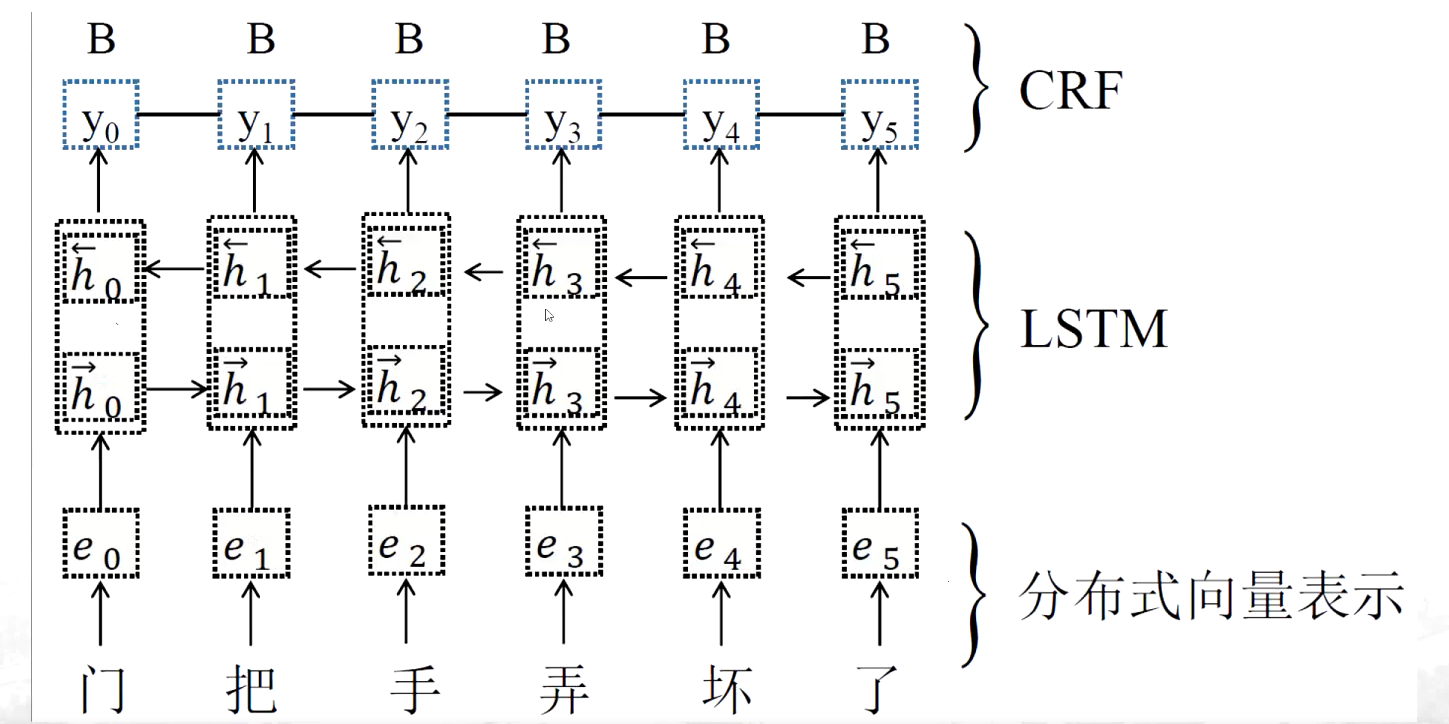
(4)基于神經網絡的分詞方法
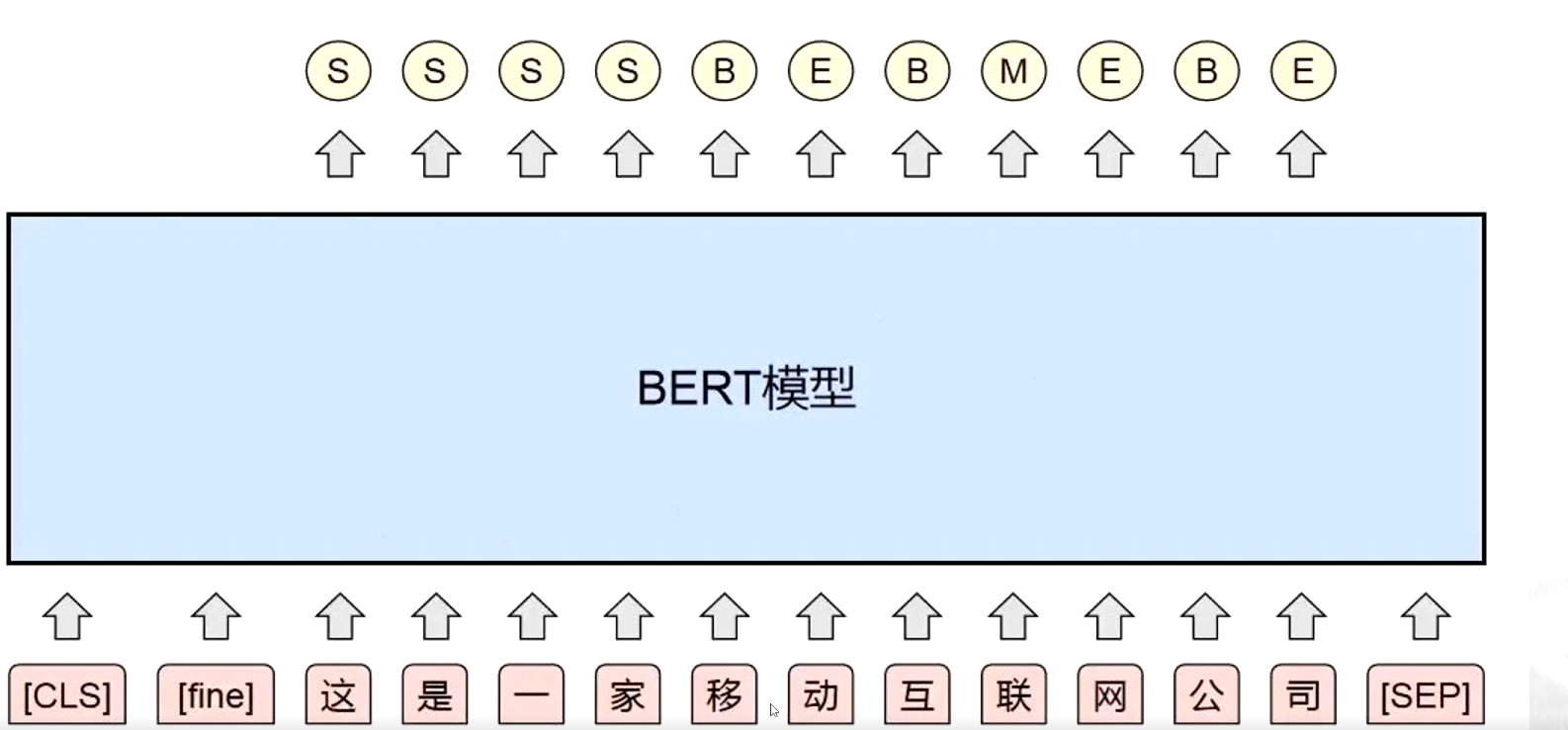
(5)基于預訓練模型的分詞方法
2、機器翻譯【MT】
(1)基于模版的直接轉換法
(2)基于規則的翻譯方法
(3)基于中間語言的翻譯方法
(4)基于語料庫的翻譯方法
統計機器翻譯(SMT)
神經機器翻譯方法
3、語音翻譯/同聲傳譯
五、技術現狀
1、漢語自動分詞技術現狀
2、機器翻譯譯文的質量
3、做不到語言的深度理解,缺乏推理能力
書籍推薦
一、學科的產生與發展
1、什么是自然語言?
? ? ? ?自然語言是人類社會發展過程中自然產生的語言,是最能體現人類智慧和文明的產物。
? ? ? ?語言是思維的載體,是人類交流思想、表達感情最自然、最直接、最方便的工具;人類
歷史上以語言文字形式記載和流傳的知識站比達八成以上。
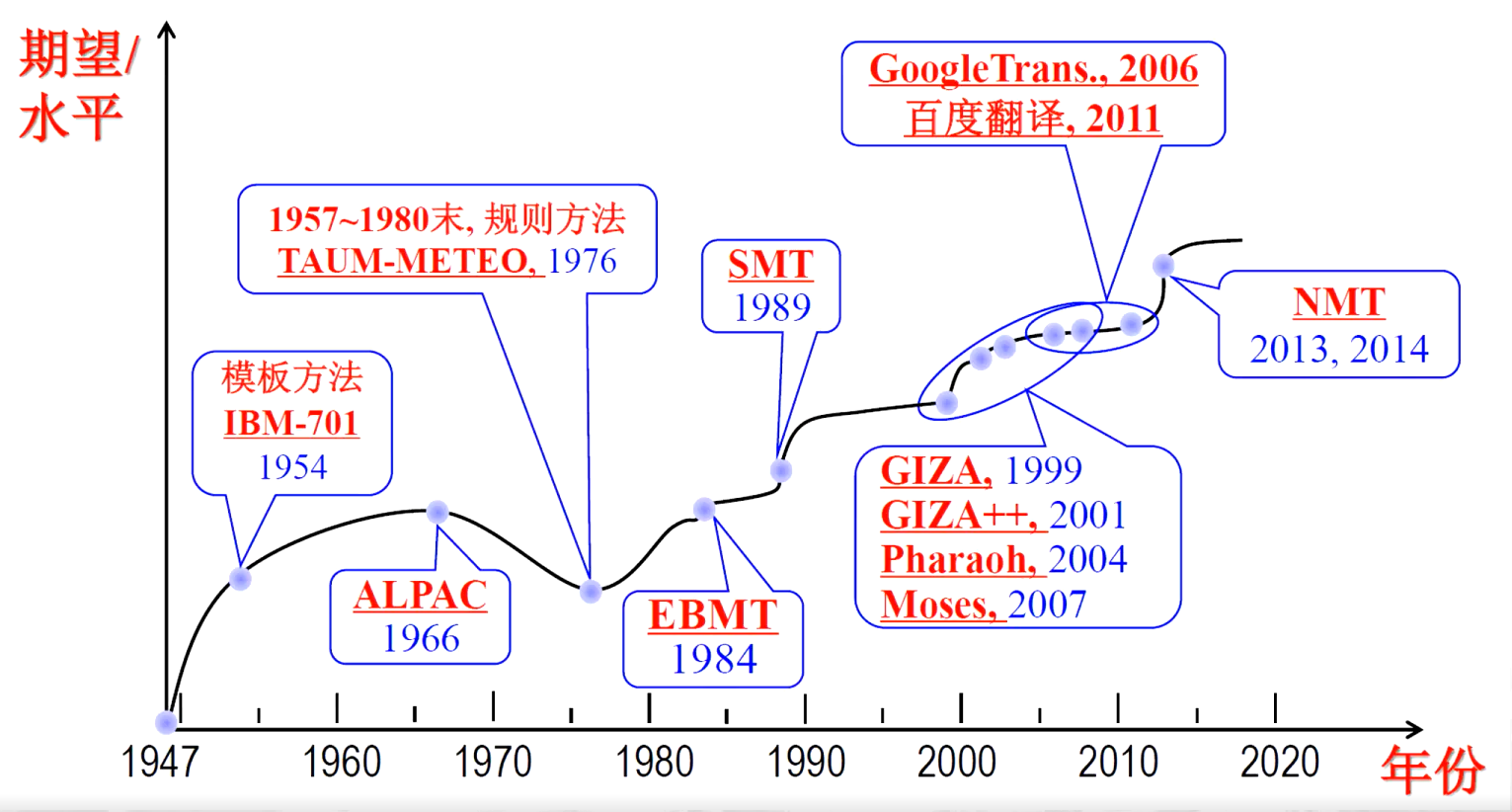
2、自然語言處理技術的誕生
- 自W. Weaver 和A.D.Booth 提出機器翻譯概念后,美國和英國的學術界對機器翻譯(machine translation,MT)產生了濃厚的興趣,并得到了實業界的支持。

- 1954年Georgetown大學在IBM協助下,用IBM-701計算機實現了世界上第一個MI系統,實現俄譯英翻譯,1954年1月該系統在紐約公開演示。系統只有250條俄語詞匯,6 條語法規則,可以翻譯簡單的俄語句子。
- 隨后10 多年里,MT研究在國際上出現熱潮。
- 1962年國際計算語言學學會(Association for Computational Linguistics,ACL)成立;
- 1965年國際計算語言學委員會(International Committee on Computational Linguistics,ICCL)成立。
- 1964年,美國科學院成立語言自動處理咨詢委員會(AutomaticLanguage Processing Advisory
Committee,ALPAC),調查機器翻譯的研究情況,于1966年11月公布了一個題為“語言與機器”的調查報告,簡稱ALPAC 報告,宣稱:“在目前給機器翻譯以大力支持還沒有多少理由”
“機器翻譯遇到了難以克服的語義障礙(semantic barrier)”。從此機器翻譯研究在世界范圍內進入低迷狀態。計算語言學(computational linguistic)術語首次以正式身份出現在這個報告里。 - 1980S,隨著計算機網絡的快速發展和普及,以開發實用自然語言處理系統為目標的語言工程技術應運而生,自然語言處理(natural? language? ?processing,NLP)術語由此誕生
二、技術挑戰
- 大量存在的未知語言現象如:高山、高升;吉林、武夷山、桂林、溫泉、溫馨、時光;虎蠅,埃博拉,奧特曼、悶騷 ;BoW,word2vec
- 無處不在的歧義詞如:蘋果、粉絲:bank,interest……;那輛白色的車是黑車/臭豆腐真香啊!
- 復雜或歧義結構比比皆是:喜歡鄉下的孩子;上大學子燭光追思錢偉長;’“動物保護警察”明年上崗。。。。
- 普遍存在的隱喻表達:在微信圈里潛水;打鐵還要自身硬;你簡直是個木頭腦袋;
- 對翻譯而言,不同語言之間的概念不對等: 饅頭 steamed bread
三、基本方法
1、方法概述

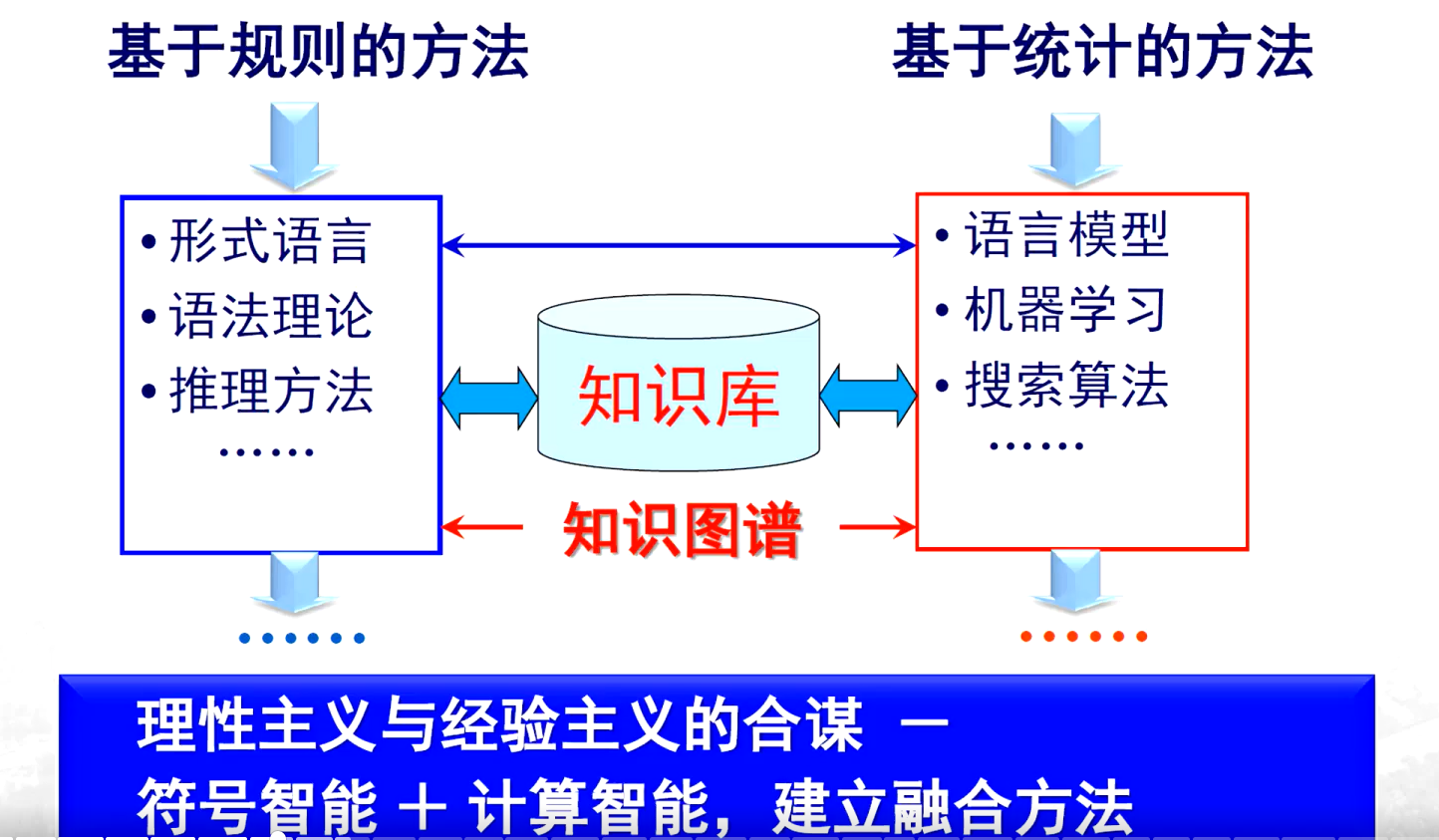
理性主義方法
- 核心思路:將分析對象轉化為 “數據 + 算法”。其中,數據即語言符號,算法則是根據分析目的設計的方法、原則和過程。
- 分析層面:
- 詞法分析:研究詞與詞、字與字之間的搭配規律及計算方式。
- 句法分析:探討詞匯組成句子時,詞與詞之間、句子與句子之間的關系。
- 語義分析:試圖解析語言文字所包含的意義(包括淺層和深層意義)。
- 輔助手段:
- 構建詞典:存儲能組成詞的字或詞。
- 總結規則:將詞與詞、字與字之間的搭配及連接關系總結為規則,以此說明符號間的邏輯關系。
- 特點:依賴語言學理論,建立形式化的規則體系,進行基于符號的推理。
經驗主義方法
- 核心思路:關注詞與詞之間的搭配情況,包括前后、并列等各種結構關系,其關注的結構相對寬泛,涉及共現關系(如哪些詞更容易同時出現在同一文本、上下文或存在前后關系等)。
- 經驗來源:從大量以往的書寫文本(語料庫)中獲取,認為文本中如此使用,便可以這樣運用。
- 方法特點:
- 基于統計:通過統計學方法從大規模語料庫中統計出規律,屬于數據驅動型。
- 概率計算:計算符號(詞)前后出現的概率大小。
? ? ? ? ? 兩者都關注語言的結構,但理性主義方法側重人工構建詞典和規則,依賴語言學理論與符號推理;經驗主義方法則依賴大規模語料庫的統計數據,注重從實際使用經驗中挖掘規律。
也就是深度學習、大語言模型
2、傳統的統計學習方法


3、深度學習方法
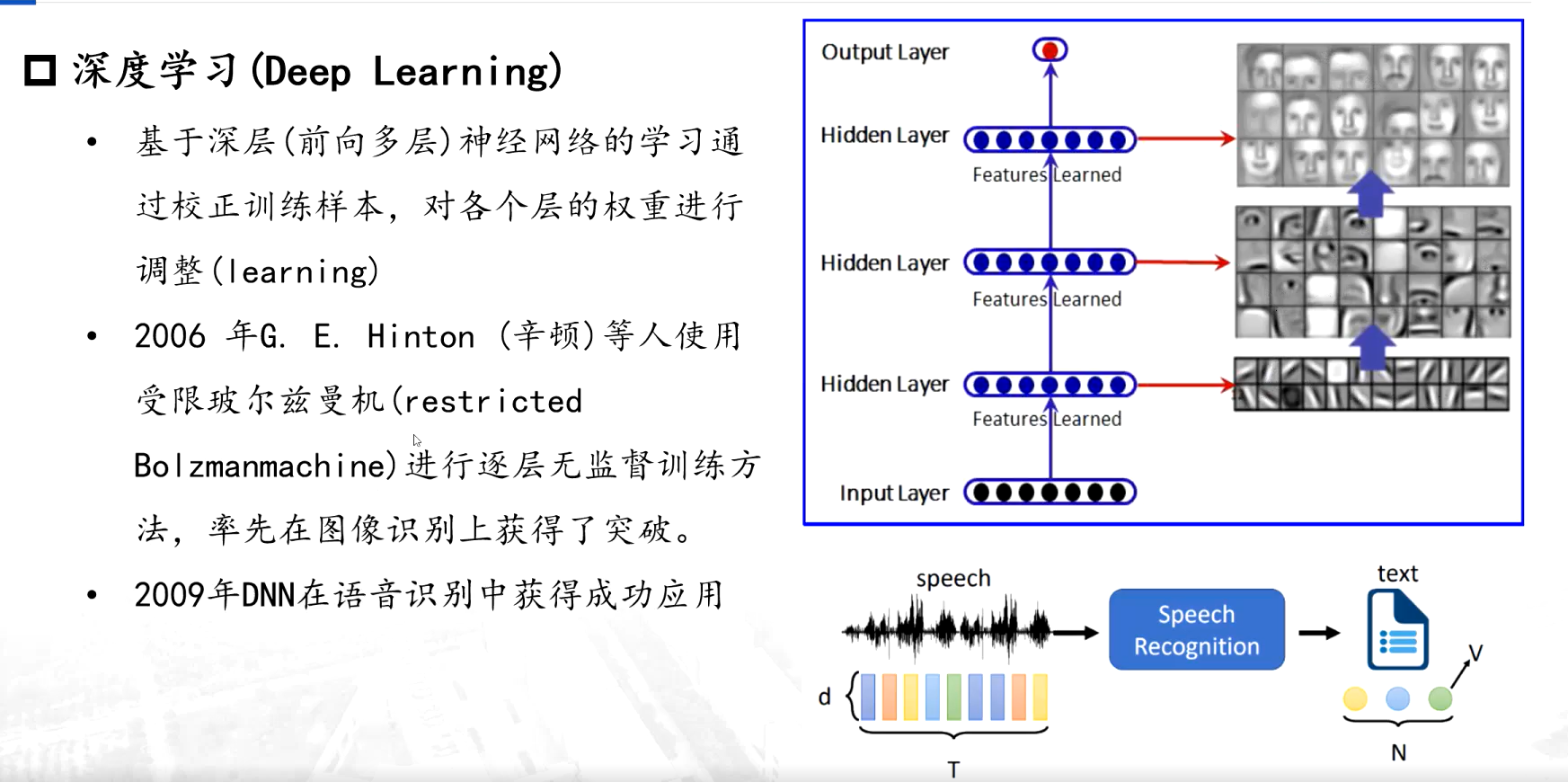
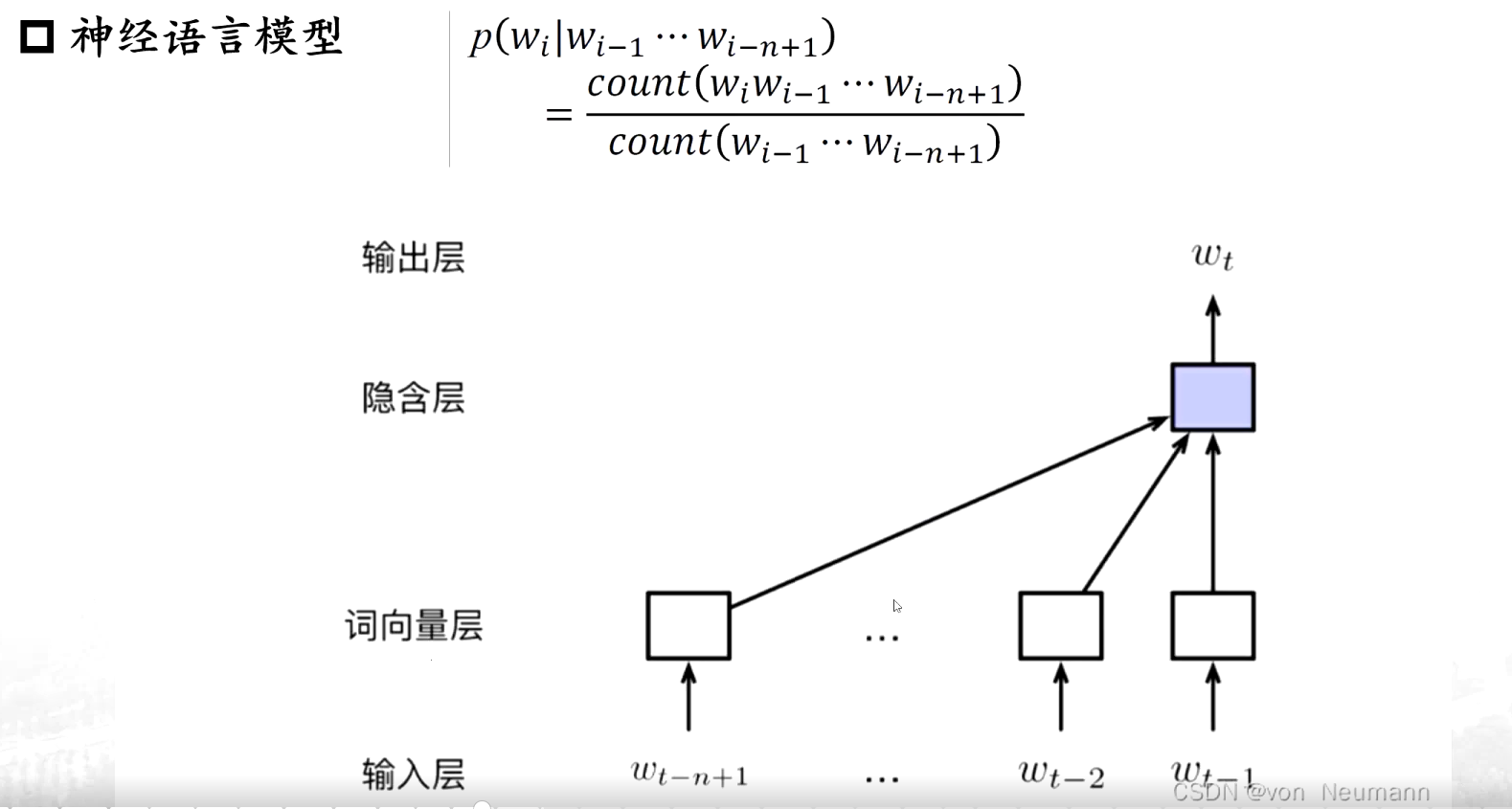
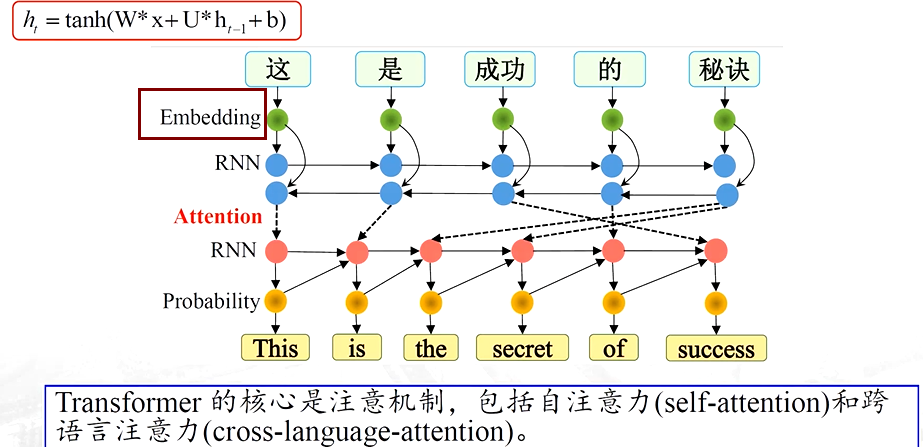
? ? 對這個特征的描述等等發生了變化,變成一個序列的形式,也就是第一個詞、第二、第三個詞,直到第七個詞的時候,我們能夠通過前幾個字判斷一下第七個詞大最大的可能是哪一個詞....
詞向量表示
相近的詞之間距離小
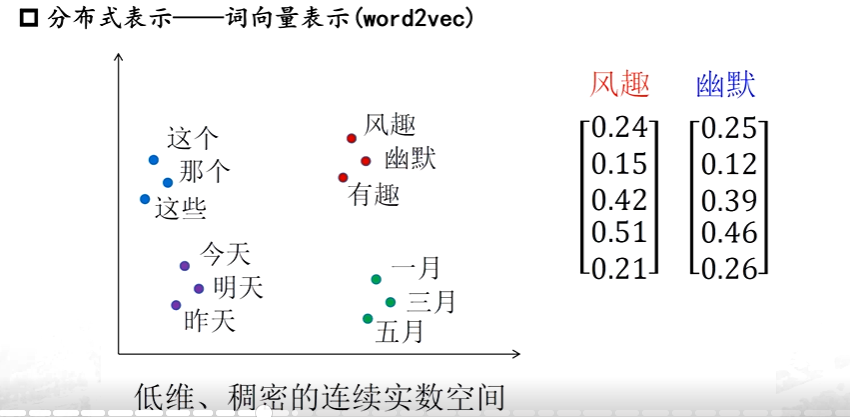
? ? ? ? 而之前都是符號化的,變為詞向量后就可計算了【計算風趣和幽默兩個之間的向量的歐式距離,它的距離一定比風趣和這個之間的距離近】
不同詞語之間距離差異
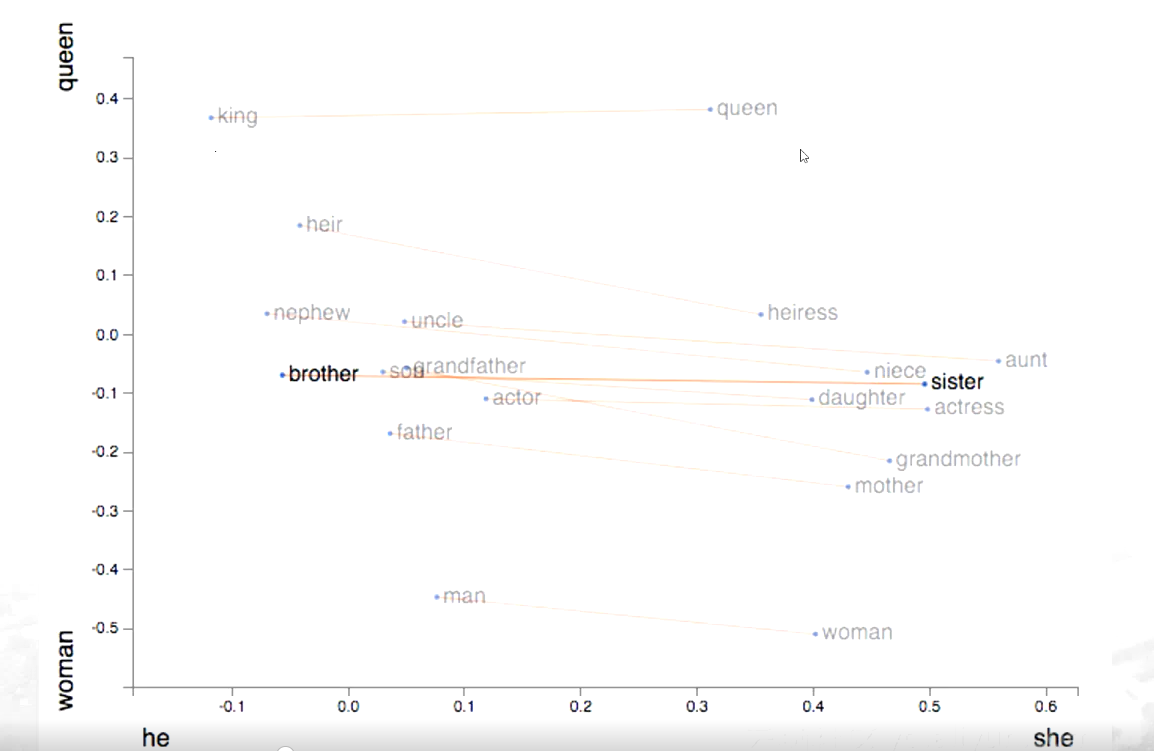
不同的詞和詞之間的距離也會有差異,像表示親屬關系、血緣關系的這些詞會近一些,而表示身份地位【king\queen】這個詞,要遠離這些親屬這種特質的這個詞; 以男女不同性別之間區分時,發現他們之間的距離的=差不多一樣【如brother與sister的距離約等于 king和queen的距離】
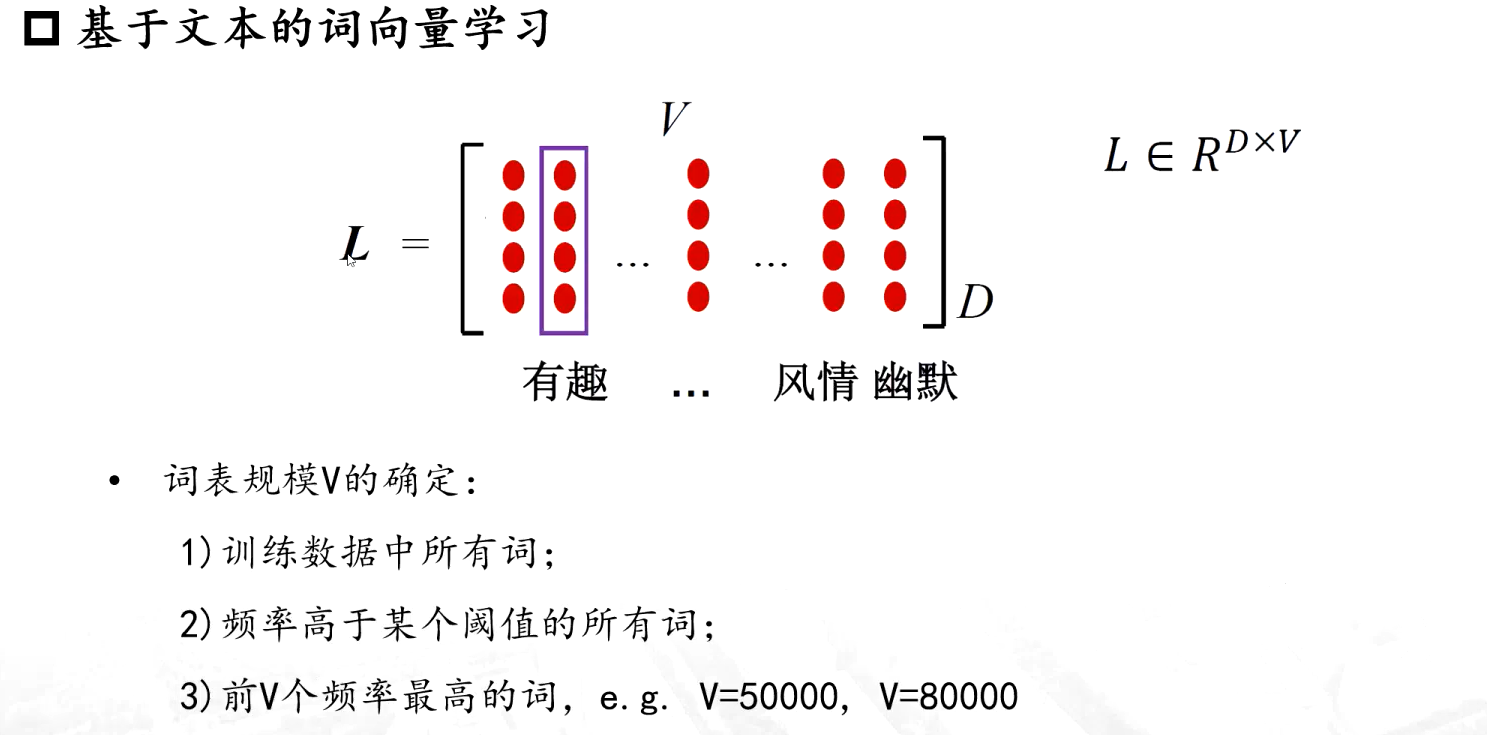
詞向量學習
????????基于文本的詞向量學習就是要學這樣的一個語義空間 L ,認為每一個詞只要是包含在這個空間中了,它要對應的他的詞向量【詞表的規模V的確定是很重要的,不一定需要訓練數據中的所有詞,一般會采用頻率高于某閾值的詞,甚至也會在訓練前設置一些停用詞】
開源工具

四、應用舉例
1、漢語分詞

已有的方法:全切分方法/最短路徑切分方法/基于n-gram的統計方法/基于HMM的分詞與詞性標注一體化方法.....
(1)最大匹配法
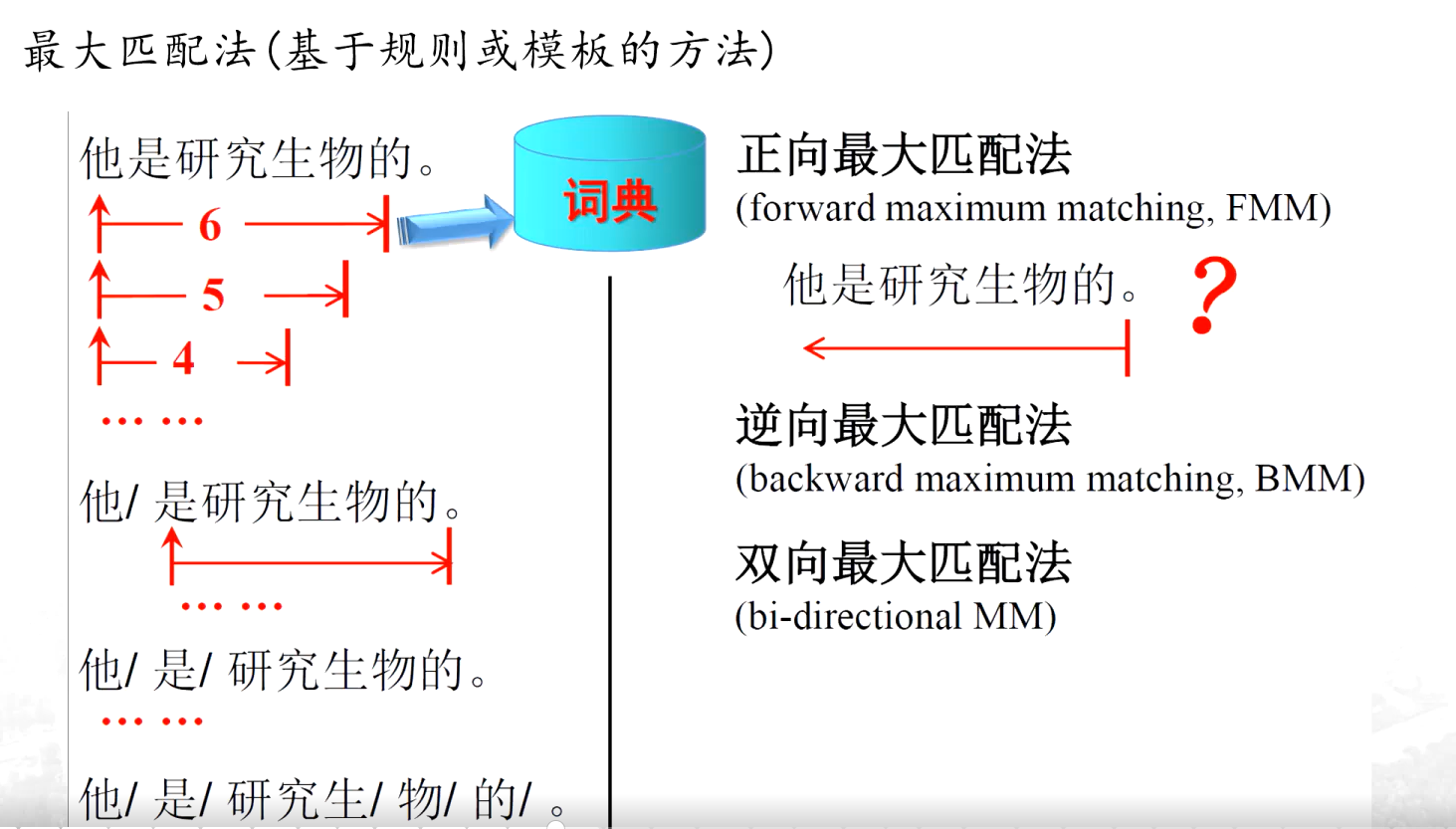
?????????“他是研究生物的。”,先從最左邊開始,看看最長能組成詞典里有的詞語是幾個字。一開始找 6 個字 “他是研究生物”,發現詞典里沒有這個詞;然后減少一個字,找 5 個字 “他是研究生”,詞典里還是沒有;再減少一個字,找 4 個字 “他是研究” ,詞典里依然沒有;直到找到 “他”,詞典里有這個詞,就把 “他” 切出來,接著從剩下的部分 “是研究生物的。” 繼續用同樣的方法找,依次拆分出 “是”“研究”“生物”“的” 。簡單來說,就是從句子左邊起,每次盡可能找最長的、能在詞典里匹配上的詞語。
? ??逆向最大匹配法是從句子的最右邊開始 “切” 。
????雙向最大匹配法就是把正向最大匹配法和逆向最大匹配法結合起來用。先分別用正向和逆向最大匹配法對句子進行分詞,然后對比兩種方法得到的結果。如看哪種分詞方式得到的詞語數量更合理
(2)基于n-gram的分詞方法

(3)由字構詞的分詞方法

? ? ?B M E S相當于是標簽,這樣有樣本就可以訓練處一個分類器,之后針對一個新樣本的每一個字就可以預測出一個標簽,然后再進行分詞,但是這樣對字和字之間出現的前后距離會比較窄
(4)基于神經網絡的分詞方法
(5)基于預訓練模型的分詞方法
2、機器翻譯【MT】
(1)基于模版的直接轉換法
????????從源語言句子的表層出發,將單詞、短語或句子直接置換成目標語言譯文,必要時進行簡單的詞序調整。直接將源語言句子按照固定的模版或句型結構轉換為目標語言,不經過復雜的語法分析,屬于早期機器翻譯的基礎方法。為常見的短語、句子結構預先設定一一對應的翻譯模版(如 “Hello” 對應 “你好”,“I am...” 對應 “我是...”)

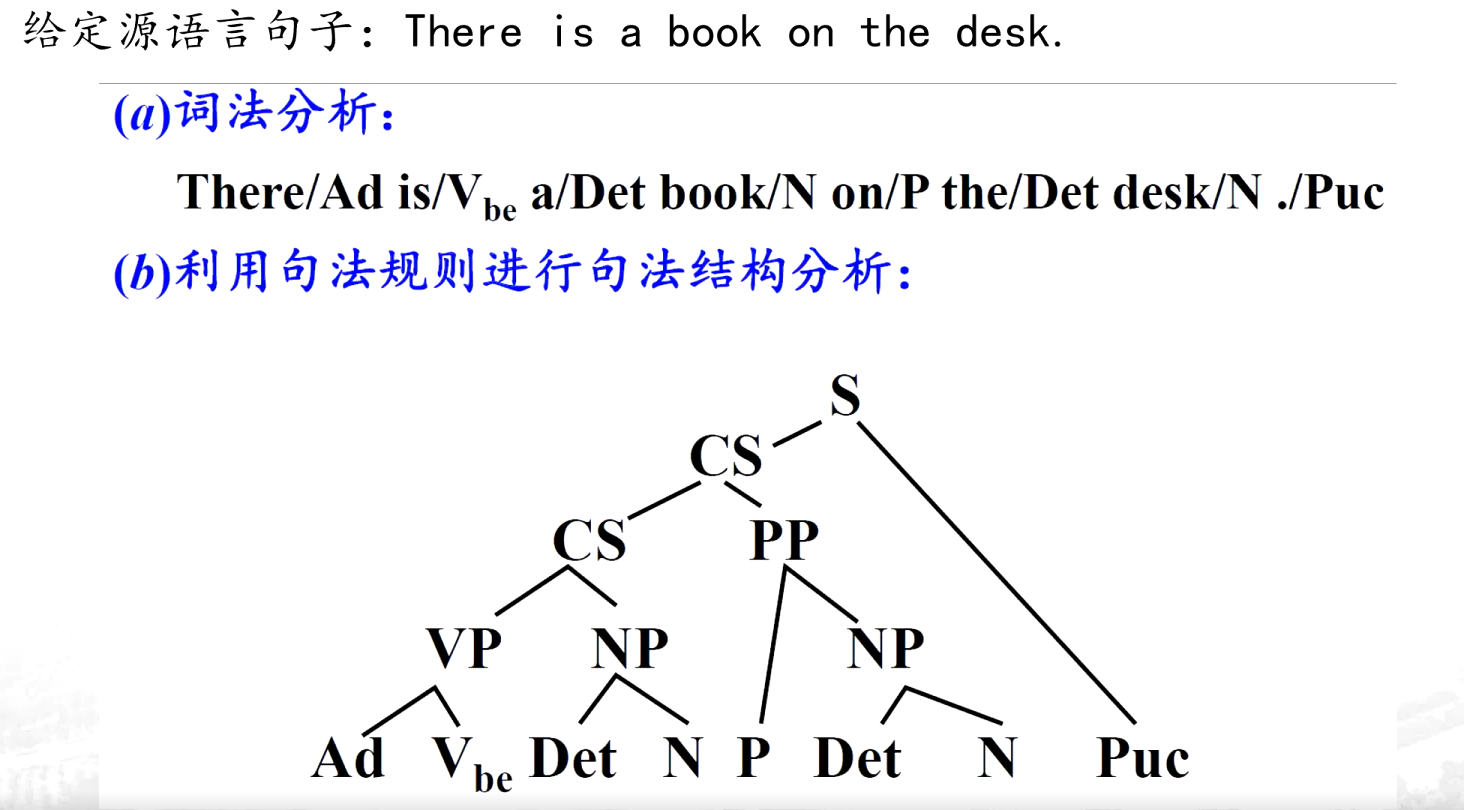
(2)基于規則的翻譯方法
?????通過人工定義源語言和目標語言的語法規則、詞匯規則及轉換規則,利用計算機對句子進行語法分析,再根據規則生成目標語言。
基于規則的翻譯過程分成6個步驟:
(a)對源語言句子進行詞法分析
(b)對源語言句子進行句法/語義分析
(c)源語言句子結構到譯文結構的轉換
(d)譯文句法結構生成
e)源語言詞匯到譯文詞匯的轉換
(f)譯文詞法選擇與生成
(3)基于中間語言的翻譯方法
????????引入一種獨立于源語言和目標語言的 “中間語言”(Interlingua),作為翻譯的中介。先將源語言轉換為中間語言,再將中間語言轉換為目標語言,避免直接處理雙語對應關系。
(4)基于語料庫的翻譯方法
????????依賴大規模雙語平行語料庫(即源語言文本及其對應的目標語言翻譯),通過統計或機器學習方法從語料中學習雙語對應規律,實現翻譯。是目前主流的機器翻譯方法。
統計機器翻譯(SMT)

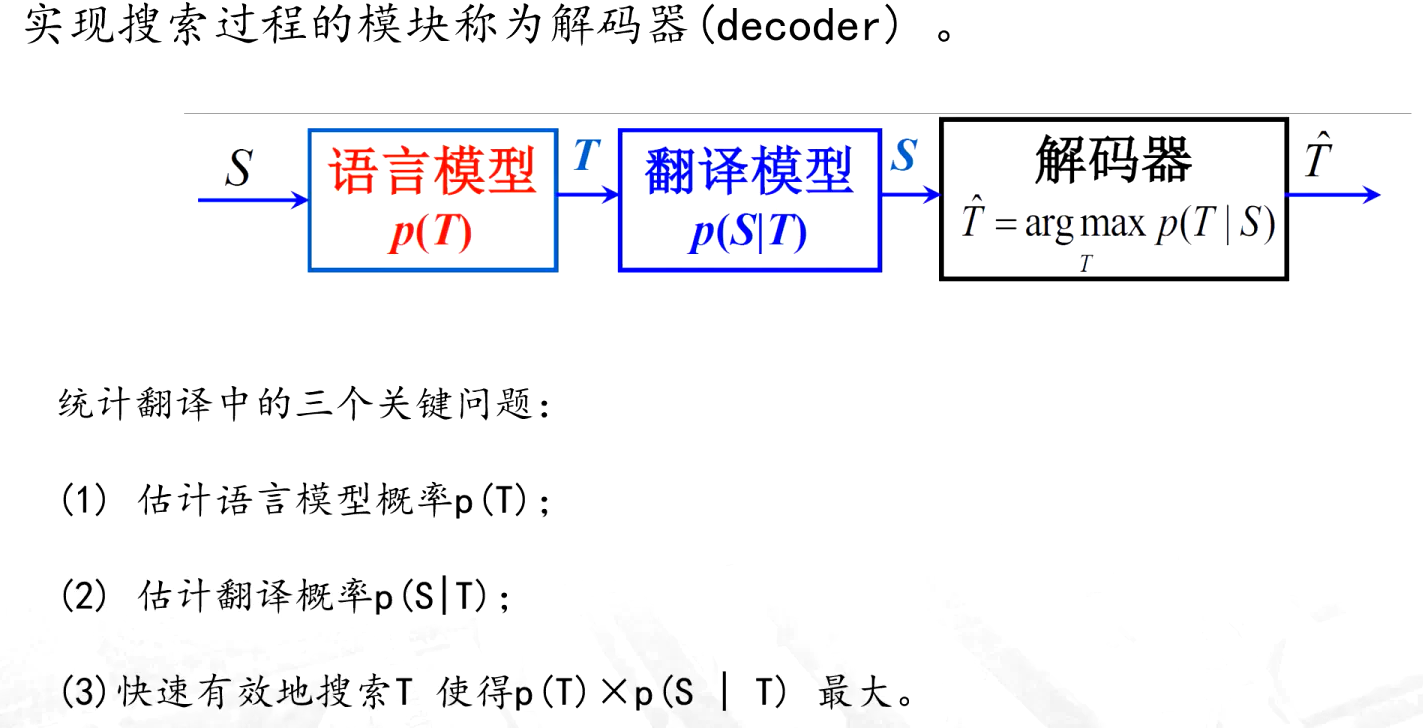
神經機器翻譯方法

如:
| 方法 | 核心依賴 | 優勢 | 主要局限 | 適用場景 |
|---|---|---|---|---|
| 基于模版的直接轉換 | 固定模版 | 簡單易實現 | 靈活性極差 | 簡單短句、固定場景 |
| 基于規則 | 人工語法規則 | 可以較好的保持原文的結構 | 規則覆蓋有限、人工量大,主觀性強 | 語法嚴謹的小范圍翻譯 |
| 基于中間語言 | 通用中間語言 | 多語言擴展方便 | 中間語言設計難、語義解析復雜 | 理論上適合多語言互譯 |
| 基于語料庫 | 大規模平行語料 | 數據驅動、性能優、不需要對源語言進行深層次分析 | 依賴語料、可解釋性弱 | 通用場景、現代主流翻譯方法 |
3、語音翻譯/同聲傳譯
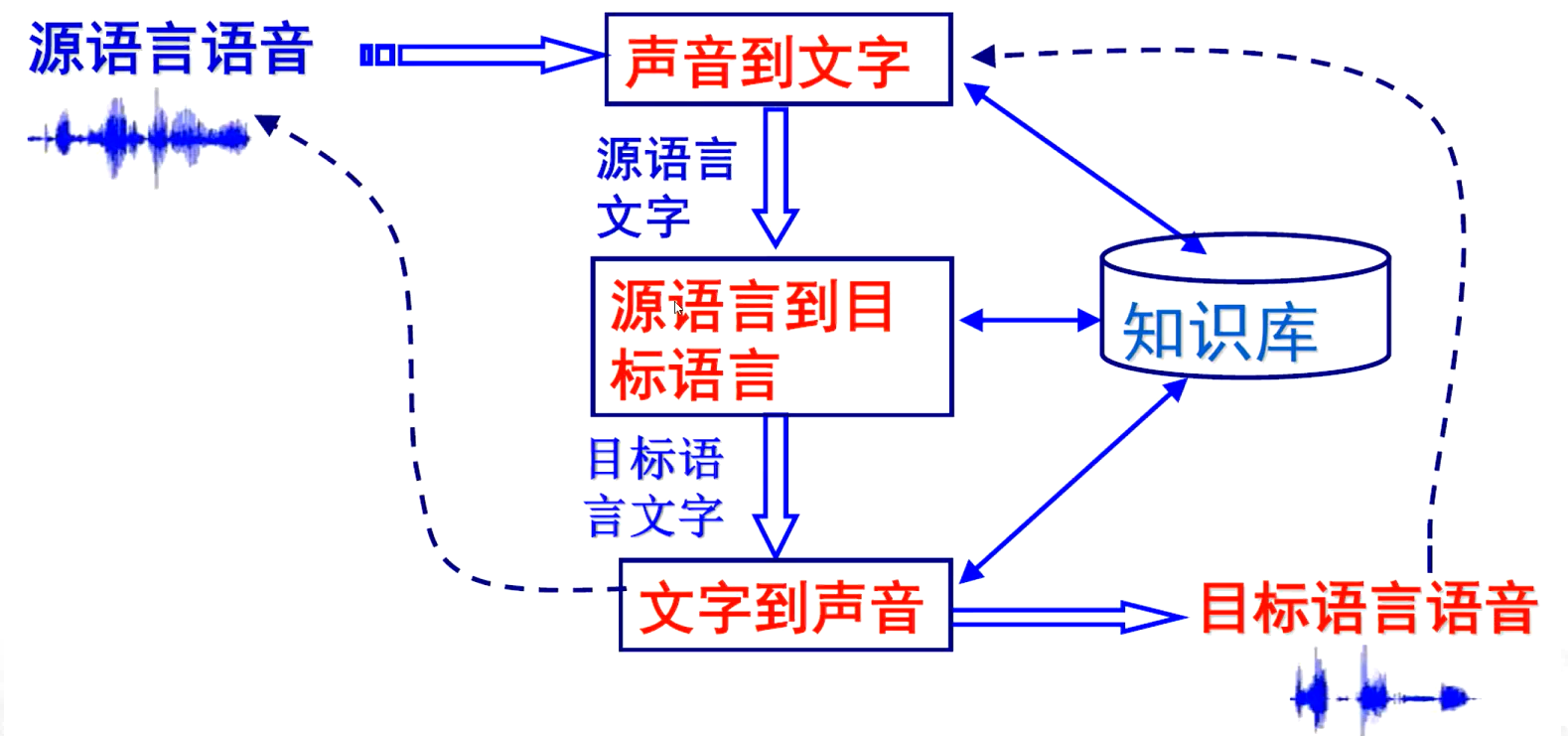
三個關鍵技術:語音識別、口語理解和翻譯、語音合成
五、技術現狀
1、漢語自動分詞技術現狀
2、機器翻譯譯文的質量

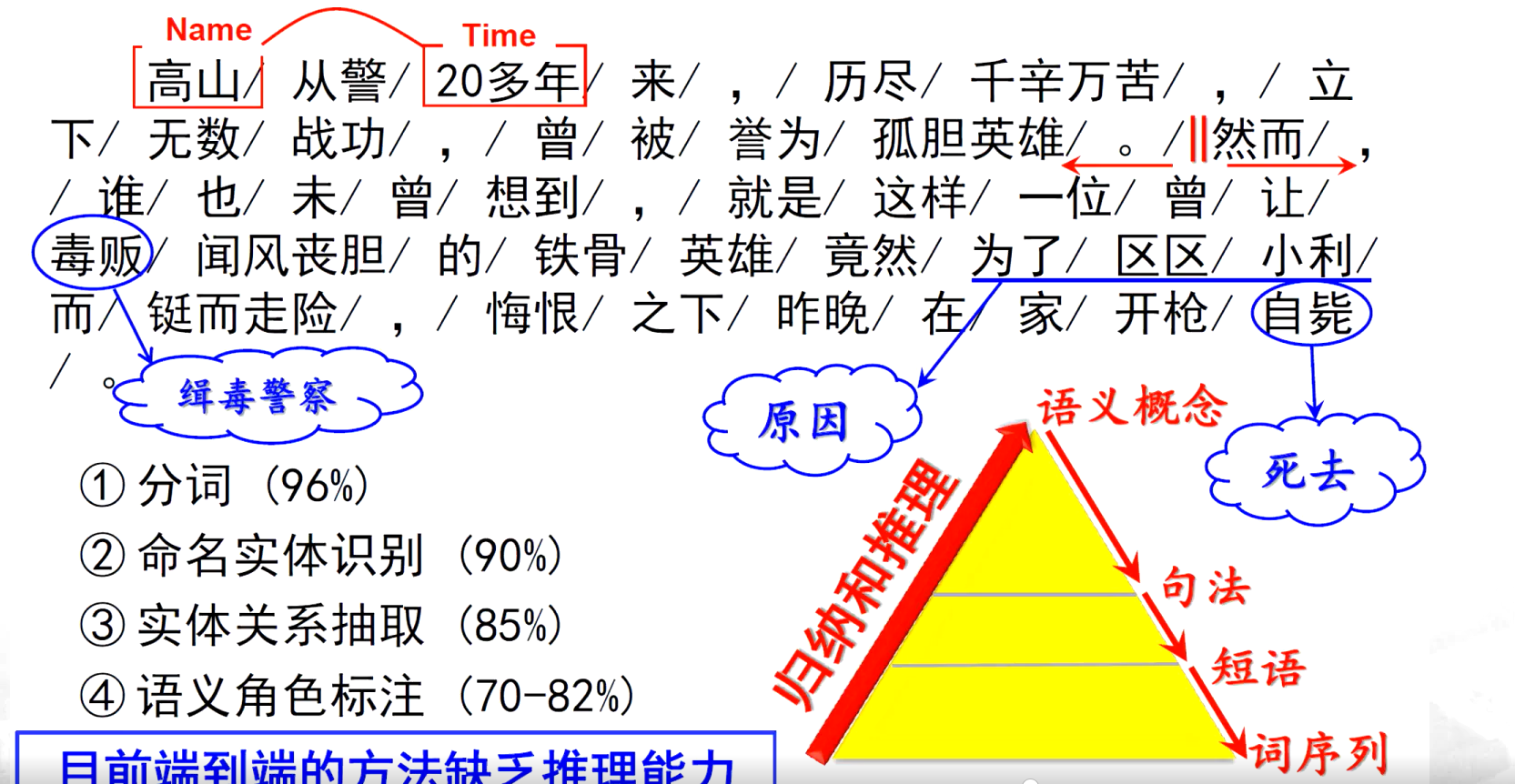
3、做不到語言的深度理解,缺乏推理能力
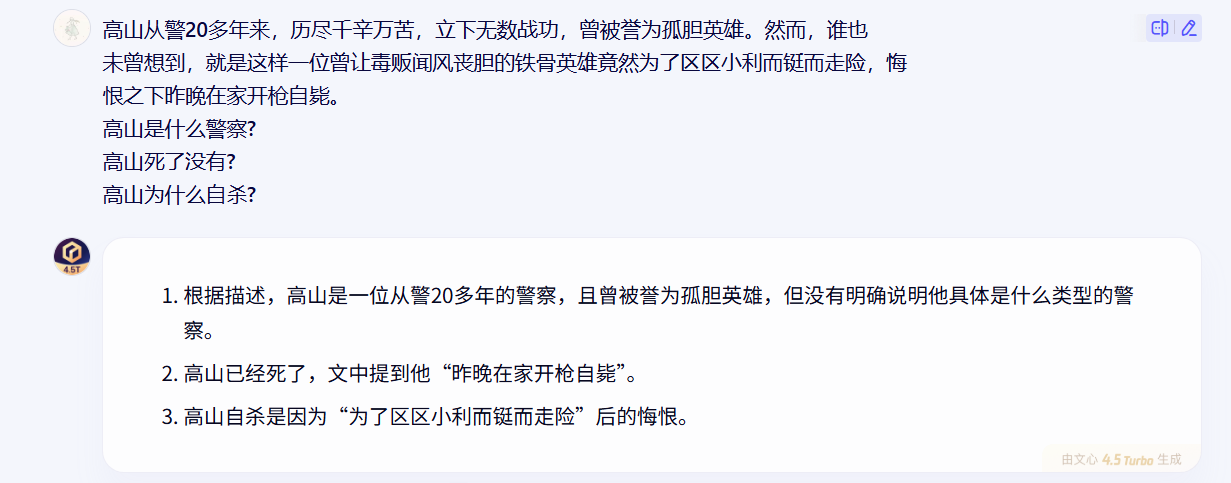
- ? ??生詞識別和切分是漢語自動分詞技術面臨的最大問題
- ? ? 跨領域和非規范是導致生詞大量出現的主要原因
- ? ? 研究半監督學習、遷移學習等方法,解決領域的自適應問題,提高系統的魯棒性和準確率,盡量減少系統對標注樣本的依賴性,是未來漢語自動分詞技術研究的主要方向

書籍推薦






)





NDK基礎)
的docker拉取倉庫失敗的加速方法)





)
