1. 必須實現拷貝構造函數的場景
核心問題:默認拷貝構造的缺陷
C++ 默認的拷貝構造函數(淺拷貝),會直接拷貝指針 / 引用成員的地址。若類包含引用成員或指向堆內存的指針,淺拷貝會導致 “多個對象共享同一份資源”,引發 double free、數據混亂等問題。此時必須手動實現深拷貝的拷貝構造函數。
場景 1:類包含引用成員(int&)
引用成員必須綁定有效對象,默認拷貝構造會讓新對象的引用綁定到原對象的引用成員(共享同一塊內存)。若原對象的引用成員失效(如局部變量銷毀),新對象的引用會變成 “野引用”。
示例:默認拷貝構造的危險
class Test {
public:int& ref;// 構造函數:綁定引用到外部變量Test(int& r) : ref(r) {} // 默認拷貝構造(編譯器生成,危險!)// Test(const Test& other) : ref(other.ref) {}
};int main() {int x = 10;Test t1(x); // 用默認拷貝構造,t2.ref 也綁定到 xTest t2 = t1; x = 20;// t1.ref 和 t2.ref 都變成20(共享x)cout << t1.ref << " " << t2.ref << endl; // 若 x 是局部變量,t2 的引用可能失效// int y = 30;// Test t3(y);// Test t4 = t3;// y 銷毀后,t4.ref 變成野引用return 0;
}
解決方案:手動實現拷貝構造
需讓新對象的引用綁定到新的有效變量(或確保原引用的生命周期足夠長)。若引用需綁定到獨立變量,需重新構造引用關系(如示例中讓新對象的引用綁定到原引用的值,而非原引用本身)。
class Test {
public:int& ref;Test(int& r) : ref(r) {} // 手動實現拷貝構造:讓新對象的引用綁定到原引用的值Test(const Test& other) // 用原引用的值,構造新的 int 變量,再綁定引用: ref(*new int(other.ref)) {} // 注意:需手動管理內存,否則內存泄漏~Test() { // 釋放 new 出來的 int(否則內存泄漏)delete &ref; }
};
場景 2:類包含指針成員(指向堆內存)
默認拷貝構造會拷貝指針地址(淺拷貝),導致多個對象共享堆內存。若一個對象釋放內存,其他對象的指針會變成 “野指針”。
示例:淺拷貝導致 double free
class Test {
public:int* ptr;Test(int val) : ptr(new int(val)) {} // 默認拷貝構造(淺拷貝,危險!)// Test(const Test& other) : ptr(other.ptr) {} ~Test() { delete ptr; }
};int main() {Test t1(10);// 淺拷貝,t2.ptr 和 t1.ptr 指向同一塊內存Test t2 = t1; // t1 析構時釋放 ptr,t2.ptr 變成野指針// t2 析構時再次釋放,引發 double freereturn 0;
}
解決方案:深拷貝的拷貝構造
class Test {
public:int* ptr;Test(int val) : ptr(new int(val)) {} // 深拷貝:新對象重新分配堆內存Test(const Test& other) : ptr(new int(*other.ptr)) {} ~Test() { delete ptr; }
};
總結:必須實現拷貝構造的時機
當類包含 ** 引用成員(需重新綁定)或指針成員(需深拷貝)** 時,默認淺拷貝會引發未定義行為,必須手動實現拷貝構造函數,確保:
- 引用成員綁定到新的有效對象(或值)。
- 指針成員重新分配堆內存(深拷貝)。
2. 對?explicit?關鍵字的理解
核心作用:禁止單參數構造函數的隱式類型轉換
C++ 中,單參數構造函數(或多參數但其余參數有默認值的構造函數)會被編譯器用作隱式類型轉換:用一個類型的值(如int)直接構造另一個類型的對象(如MyInt)。explicit?關鍵字禁止這種隱式轉換,強制要求顯式構造對象。
場景 1:單參數構造函數的隱式轉換(危險!)
class MyInt {
public:int value;// 單參數構造函數:int → MyIntMyInt(int num) : value(num) {}
};void print(MyInt mi) {cout << mi.value << endl;
}int main() {// 隱式轉換:10 → MyInt(10)print(10); return 0;
}
這種隱式轉換可能讓代碼邏輯晦澀(讀者難以發現類型轉換),甚至引發錯誤(如意外觸發構造函數的副作用)。
場景 2:explicit?禁止隱式轉換
給構造函數加?explicit?后,編譯器不再允許隱式轉換,必須顯式構造對象。
class MyInt {
public:int value;// 禁止隱式轉換explicit MyInt(int num) : value(num) {}
};void print(MyInt mi) {cout << mi.value << endl;
}int main() {// 編譯報錯:無法隱式轉換 int→MyInt// print(10); // 必須顯式構造print(MyInt(10)); return 0;
}
擴展:C++11 后支持多參數的?explicit(配合列表初始化)
C++11 允許?explicit?修飾多參數構造函數(需配合{}列表初始化),禁止用括號初始化的隱式轉換。
class Point {
public:int x, y;// 多參數構造函數,explicit 禁止隱式轉換explicit Point(int a, int b) : x(a), y(b) {}
};void draw(Point p) { /*...*/ }int main() {// 編譯報錯:無法隱式轉換 (1,2)→Point// draw((1,2)); // 必須顯式構造draw(Point(1,2)); // 或用列表初始化(C++11)draw({1,2}); return 0;
}
最佳實踐
- 所有單參數構造函數(或可能被隱式轉換的構造函數)都應加?
explicit,避免意外的隱式轉換。 - 僅在需要隱式轉換的場景(如智能指針
std::shared_ptr的構造),才不用?explicit。
3. 無法被繼承的函數
核心規則:構造函數、析構函數、賦值運算符、final?修飾的函數無法被繼承
| 函數類型 | 無法繼承的原因 |
|---|---|
| 構造函數 | 構造函數與類的初始化邏輯強綁定,子類需獨立構造 |
| 析構函數 | 析構函數與類的資源釋放邏輯強綁定,子類需獨立析構 |
賦值運算符(operator=) | 賦值需處理子類新增成員,繼承父類的賦值邏輯會遺漏子類成員 |
被?final?修飾的虛函數 | final?顯式禁止子類重寫該虛函數 |
詳細解析
(1)構造函數與析構函數
- 構造函數:子類對象包含父類成員和子類成員,父類構造函數負責初始化父類成員,子類構造函數需調用父類構造函數(通過初始化列表),無法直接繼承父類構造邏輯(否則無法初始化子類新增成員)。
- 析構函數:子類析構函數需先釋放子類資源,再調用父類析構函數。若繼承父類析構函數,無法保證子類資源優先釋放,可能導致內存泄漏。
(2)賦值運算符(operator=)
父類的?operator=?僅處理父類成員,子類的?operator=?需處理子類新增成員。若繼承父類的?operator=,會導致子類成員未被賦值(遺漏),引發數據不完整。
示例:繼承賦值運算符的危險
class Father {
public:int x;Father& operator=(const Father& other) {x = other.x;return *this;}
};class Son : public Father {
public:int y;// 若繼承父類 operator=,會遺漏 y 的賦值Son& operator=(const Son& other) {// 必須手動調用父類的 operator=Father::operator=(other); y = other.y;return *this;}
};
(3)被?final?修飾的虛函數
final?是 C++11 引入的關鍵字,用于禁止虛函數被重寫。若父類虛函數被?final?修飾,子類無法繼承(重寫)該函數,否則編譯報錯。
class Father {
public:// 禁止子類重寫virtual void func() final { /*...*/ }
};class Son : public Father {
public:// 編譯報錯:無法重寫 final 函數// void func() override { /*...*/ }
};
4. 繼承中同名成員的處理
核心規則:子類同名成員會隱藏父類同名成員(而非覆蓋),需用作用域運算符?::?顯式訪問父類成員。
場景 1:子類定義與父類同名的成員變量
父類的同名成員變量仍被繼承到子類,但子類的同名成員會 “隱藏” 父類成員(默認訪問子類成員)。
class Father {
public:int money = 100;
};class Son : public Father {
public:// 子類同名成員,隱藏父類的 moneyint money = 50;
};int main() {Son son;// 訪問子類的 money(輸出50)cout << son.money << endl; // 顯式訪問父類的 money(輸出100)cout << son.Father::money << endl; return 0;
}
場景 2:子類定義與父類同名的成員函數
若子類函數與父類函數同名但參數不同(非虛函數),會隱藏父類的所有同名函數(無論參數是否相同)。若子類函數與父類函數同名且參數相同(虛函數),則重寫父類函數(多態)。
示例:同名非虛函數的隱藏
class Father {
public:void func(int x) { cout << "Father: " << x << endl; }
};class Son : public Father {
public:// 同名但參數不同,隱藏父類的 func(int)void func(double x) { cout << "Son: " << x << endl; }
};int main() {Son son;// 調用子類的 func(double)son.func(3.14); // 編譯報錯:父類的 func(int) 被隱藏// son.func(10); // 顯式訪問父類的 func(int)son.Father::func(10); return 0;
}
最佳實踐
- 避免同名成員:設計類時,盡量讓子類成員與父類成員名稱不同,減少混淆。
- 顯式訪問父類成員:若必須同名,用?
Father::money、Father::func()?明確訪問父類成員,增強代碼可讀性。
5. 繼承中構造與析構的順序
構造順序:父類 → 成員對象 → 子類
對象構造時,需先確保父類和成員對象的構造完成(為子類提供初始化的基礎),因此順序為:
- 調用父類的構造函數(按繼承順序,從最頂層父類到直接父類)。
- 調用成員對象的構造函數(按成員在子類中的聲明順序)。
- 調用子類的構造函數體。
示例:多層繼承 + 成員對象的構造順序
class GrandFather {
public:GrandFather() { cout << "GrandFather 構造" << endl; }
};class Father : public GrandFather {
public:Father() { cout << "Father 構造" << endl; }
};class Member {
public:Member() { cout << "Member 構造" << endl; }
};class Son : public Father {
public:Member m;Son() { cout << "Son 構造" << endl; }
};int main() {Son son;// 輸出順序:// GrandFather 構造 → Father 構造 → Member 構造 → Son 構造return 0;
}
析構順序:子類 → 成員對象 → 父類
對象析構時,需先釋放子類資源,再釋放成員對象和父類資源(避免父類資源先釋放,子類資源訪問無效內存),因此順序與構造相反:
- 調用子類的析構函數體。
- 調用成員對象的析構函數(按構造順序的逆序)。
- 調用父類的析構函數(按繼承順序的逆序,從直接父類到最頂層父類)。
示例:析構順序驗證
class GrandFather {
public:~GrandFather() { cout << "GrandFather 析構" << endl; }
};class Father : public GrandFather {
public:~Father() { cout << "Father 析構" << endl; }
};class Member {
public:~Member() { cout << "Member 析構" << endl; }
};class Son : public Father {
public:Member m;~Son() { cout << "Son 析構" << endl; }
};int main() {Son son;// 構造順序:GrandFather → Father → Member → Son// 析構順序:Son → Member → Father → GrandFatherreturn 0;
}6. 繼承中的構造與析構順序
繼承體系中,構造函數和析構函數的調用順序嚴格遵循?“先構造父類,再構造子類;先析構子類,再析構父類”?的規則,這是由 C++ 對象的內存布局和生命周期決定的。
一、構造函數的調用順序
1. 子類對象創建時,先調用父類構造函數
原理:
子類繼承了父類的成員變量,這些成員的初始化依賴父類的構造邏輯。如果先構造子類,父類成員可能因未初始化而出現訪問非法內存、數據未定義等問題。因此,C++ 強制規定:創建子類對象時,必須先確保父類構造完成,為繼承的成員打好初始化基礎。
示例驗證:
class Father {
public:Father() {cout << "Father 構造函數調用" << endl;}
};class Son : public Father {
public:Son() {cout << "Son 構造函數調用" << endl;}
};int main() {Son son; // 輸出順序:// Father 構造函數調用 → Son 構造函數調用return 0;
}
內存視角:
子類對象的內存布局中,父類成員在前、子類成員在后。構造時必須先初始化父類部分(確保父類成員有效),再初始化子類獨有的成員。
2. 父類有參數時,子類必須用初始化列表顯式調用
場景:
如果父類沒有默認構造函數(即構造函數需要傳入參數,無法無參調用),子類構造函數必須在初始化列表中顯式調用父類的有參構造函數,否則編譯器報錯(因為父類無法自動用默認構造初始化)。
示例驗證:
class Father {
public:int money;// 父類沒有默認構造,必須傳參初始化Father(int m) : money(m) {cout << "Father 帶參構造:" << money << endl;}
};class Son : public Father {
public:int toyNum;// 子類構造函數初始化列表,顯式調用父類帶參構造Son(int m, int toy) // 調用父類有參構造,初始化父類成員 money: Father(m), // 初始化子類成員 toyNumtoyNum(toy) {cout << "Son 帶參構造:" << toyNum << endl;}
};int main() {Son son(100, 5); // 輸出順序:// Father 帶參構造:100 → Son 帶參構造:5return 0;
}
關鍵細節:
- 初始化列表的調用順序不受書寫順序影響,而是嚴格按照成員變量在類中聲明的順序執行。
- 若父類無默認構造,子類構造函數的初始化列表必須顯式調用父類有參構造,否則編譯報錯(編譯器無法自動推斷父類的構造方式)。
二、析構函數的調用順序
原理:
對象銷毀時,要保證?“先構造的后銷毀,后構造的先銷毀”。子類對象依賴父類的資源(如父類成員變量、父類申請的堆內存),若父類先銷毀,子類在析構時可能訪問已銷毀的父類成員,引發未定義行為。因此,析構順序嚴格與構造順序相反:先調子類析構函數,再調父類析構函數。
示例驗證:
class Father {
public:~Father() {cout << "Father 析構函數調用" << endl;}
};class Son : public Father {
public:~Son() {cout << "Son 析構函數調用" << endl;}
};int main() {Son son; // 構造順序:Father → Son// 析構順序:Son → Father// 輸出:// Son 析構函數調用 → Father 析構函數調用return 0;
}
內存視角:
子類析構時,需先釋放子類獨有的資源(避免父類析構后,子類資源釋放邏輯依賴父類成員但父類已銷毀),再通知父類釋放其資源。
7. 子類調用成員對象、父類有參構造的注意點
子類構造函數不僅要處理父類的構造,還要處理 ** 成員對象(子類中包含的其他類對象)** 的構造。成員對象的構造順序與父類構造緊密相關,需特別注意默認構造和有參構造的調用規則。
一、默認構造的自動調用
規則:
當父類和成員對象存在默認構造函數(無參構造函數,或所有參數都有默認值的構造函數)時,子類構造時會自動調用它們的默認構造,無需手動在初始化列表中處理。
示例驗證:
class Father {
public:// 父類默認構造(無參)Father() { cout << "Father 默認構造" << endl; }
};class Member {
public:// 成員對象默認構造(無參)Member() { cout << "Member 默認構造" << endl; }
};class Son : public Father {
private:// 子類包含的成員對象Member m;
public:Son() { cout << "Son 構造" << endl; }
};int main() {Son son; // 輸出順序:// Father 默認構造 → Member 默認構造 → Son 構造return 0;
}
原理:
編譯器會自動在子類構造函數的初始化列表中,插入對父類默認構造和成員對象默認構造的調用,確保所有基類和成員對象都被正確初始化。
二、有參構造的強制調用(初始化列表)
規則:
若父類或成員對象沒有默認構造函數(只有帶參數的構造函數),子類構造函數必須在初始化列表中顯式調用它們的有參構造函數,否則編譯器報錯(因為無法默認初始化)。
調用規則細節:
- 父類:用?
父類名(參數)?調用,指定父類構造函數及參數。 - 成員對象:用?
成員對象名(參數)?調用,指定成員對象構造函數及參數。
示例驗證(父類、成員對象均為有參構造):
class Father {
public:int money;// 父類有參構造(無默認構造)Father(int m) : money(m) { cout << "Father 有參構造:" << money << endl; }
};class Member {
public:int toy;// 成員對象有參構造(無默認構造)Member(int t) : toy(t) { cout << "Member 有參構造:" << toy << endl; }
};class Son : public Father {
private:// 子類包含的成員對象Member m;
public:// 初始化列表:調用父類、成員對象的有參構造Son(int m_money, int m_toy) // 調用父類有參構造,初始化父類成員 money: Father(m_money), // 調用成員對象有參構造,初始化成員對象 m 的 toym(m_toy) { cout << "Son 構造" << endl; }
};int main() {Son son(100, 5); // 輸出順序:// Father 有參構造:100 → Member 有參構造:5 → Son 構造return 0;
}
避坑點:
初始化列表的調用順序由成員變量在類中的聲明順序決定,而非初始化列表的書寫順序。若順序錯誤,可能導致未定義行為(如用未初始化的成員給其他成員賦值)。
8. 虛繼承的原理
虛繼承是 C++ 為解決多繼承中的菱形繼承問題(多個子類繼承同一父類,導致父類成員在子類中重復存儲)而設計的機制。其核心是通過虛基類指針和虛基類表,讓多個子類共享同一父類的成員,避免數據冗余和訪問沖突。
一、菱形繼承問題(不使用虛繼承)
場景:
類?A?是類?B?和?C?的父類,類?D?同時繼承?B?和?C。此時,D?中會包含兩份?A?的成員(一份來自?B,一份來自?C),導致數據冗余和二義性。
示例(問題代碼):
class A {
public:int data;A(int d) : data(d) {}
};class B : public A {
public:B(int d) : A(d) {}
};class C : public A {
public:C(int d) : A(d) {}
};class D : public B, public C {
public:D(int d1, int d2) : B(d1), C(d2) {}
};int main() {D d(10, 20);// 編譯報錯:data 二義性(B::data 和 C::data 沖突)// cout << d.data << endl; return 0;
}
問題:
D?中存儲了兩份?A?的?data(B::data?和?C::data),訪問?d.data?時編譯器無法確定訪問哪一份,引發二義性錯誤。
二、虛繼承的解決方案
原理:
虛繼承通過在子類中添加虛基類指針(vbptr),指向虛基類表(vbtable)。虛基類表中記錄了從該指針到公共祖先(如?A)成員的偏移量,確保多個子類(如?B?和?C)共享同一?A?的成員,避免數據冗余。
使用虛繼承的代碼:
class A {
public:int data;A(int d) : data(d) {}
};// 虛繼承 A
class B : virtual public A {
public:B(int d) : A(d) {}
};// 虛繼承 A
class C : virtual public A {
public:C(int d) : A(d) {}
};class D : public B, public C {
public:// 必須顯式調用 A 的構造(虛繼承后,B 和 C 無法直接初始化 A)D(int d) : A(d), B(d), C(d) {}
};int main() {D d(10);// 輸出10(B 和 C 共享 A::data)cout << d.data << endl; return 0;
}
內存布局變化:
B?和?C?中各有一個虛基類指針(vbptr),指向虛基類表。- 虛基類表中存儲了?
B/C?到?A?成員的偏移量,確保?B::data?和?C::data?實際指向同一?A::data。
三、虛繼承的優缺點
優點:
- 解決菱形繼承的二義性和數據冗余問題,讓公共基類成員只存儲一份。
缺點:
- 增加內存開銷(每個虛繼承的子類需存儲虛基類指針和虛基類表)。
- 構造函數復雜(虛繼承后,最終子類需顯式調用公共基類的構造函數,無法依賴中間子類)。
最佳實踐:
虛繼承是 “無奈之舉”,實際開發中應盡量避免多繼承(用組合、接口繼承替代),因為多繼承的復雜性(如虛繼承的理解成本、構造順序問題)遠大于其帶來的便利。
9. 純虛函數與抽象類
純虛函數是 C++ 實現抽象類和接口的核心機制。它強制子類必須實現某些函數,確保繼承體系的行為統一。
一、普通純虛函數的定義與特性
定義:
純虛函數是在基類中聲明的虛函數,格式為?virtual 返回值類型 函數名(參數列表) = 0;。純虛函數不需要(也不能強制要求)在基類中實現函數體,但子類必須以?override?關鍵字重寫該函數(否則子類也會成為抽象類,無法實例化)。
示例:
class Base {
public:// 純虛函數:基類只聲明,不實現virtual void func() = 0;
};class Derived : public Base {
public:// 子類必須重寫純虛函數void func() override { cout << "Derived::func 調用" << endl; }
};int main() {// 錯誤:抽象類不能實例化// Base b; Derived d;d.func(); // 輸出:Derived::func 調用return 0;
}
二、純虛函數的特殊用法(基類實現函數體)
規則:
純虛函數可以在基類中實現函數體,但這不是強制的。子類可以選擇調用基類的實現(通過?Base::func()),但即便基類實現了函數體,子類仍需顯式重寫純虛函數(否則子類是抽象類)。
示例驗證:
class Base {
public:// 純虛函數聲明virtual void func() = 0;
};// 基類中實現純虛函數的函數體(非強制,僅為示例)
void Base::func() { cout << "Base::func 調用" << endl;
}class Derived : public Base {
public:// 子類必須重寫純虛函數void func() override { // 調用基類的實現(可選)Base::func(); cout << "Derived::func 調用" << endl; }
};int main() {Derived d;d.func(); // 輸出:// Base::func 調用 → Derived::func 調用return 0;
}
注意:
基類純虛函數的實現體通常用于提供 “默認邏輯”,子類可選擇復用或完全重寫,但子類必須顯式重寫(否則無法實例化)。
三、純虛函數對析構函數的影響
純虛析構函數是特殊場景:基類若聲明純虛析構函數,必須提供函數體(否則鏈接報錯,因為析構函數需要釋放資源)。子類析構函數會自動調用基類析構函數,確保資源正確釋放。
示例(純虛析構函數):
class Base {
public:// 純虛析構函數,必須實現函數體virtual ~Base() = 0;
};// 基類純虛析構函數的實現體
Base::~Base() { cout << "Base 析構函數調用" << endl;
}class Derived : public Base {
public:~Derived() {cout << "Derived 析構函數調用" << endl;}
};int main() {Base* ptr = new Derived();// 銷毀時:先 Derived 析構,再 Base 析構delete ptr; // 輸出:// Derived 析構函數調用 → Base 析構函數調用return 0;
}
關鍵:
純虛析構函數的函數體必須定義(否則鏈接階段報錯),子類析構函數會隱式調用基類析構函數,保證繼承體系的資源釋放順序。
10. 多態成立的條件
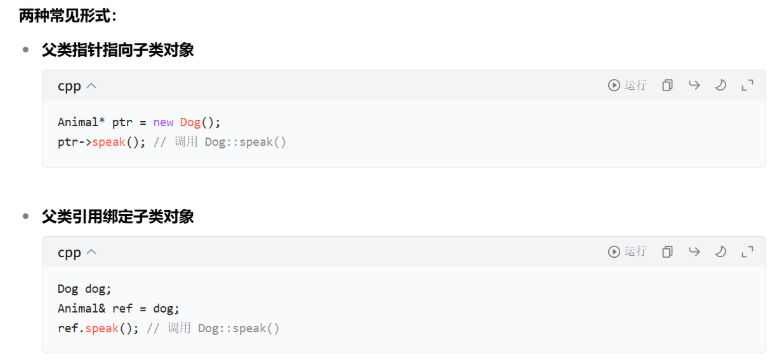
多態是 C++ 面向對象設計的核心特性,允許程序根據對象的實際類型(而非聲明類型)調用對應的函數。其成立需滿足以下三個條件:
https://github.com/0voice





NDK基礎)
的docker拉取倉庫失敗的加速方法)





)





)
