伯努利模型的參數估計方法
1. 統計學習方法三要素對比
| 方法 | 模型 | 策略 | 算法 |
|---|---|---|---|
| 極大似然估計 | 概率模型 | 經驗風險最小化 | 數值解 |
| 貝葉斯估計 | 概率模型 | 結構風險最小化 | 解析解 |
2. 極大似然估計
2.1 模型設定
設P(x=1)=θP(x=1)=\thetaP(x=1)=θ,則P(x=0)=1?θP(x=0)=1-\thetaP(x=0)=1?θ
2.2 似然函數
對于n次獨立實驗,k次結果為1:
L(x1,x2,...,xn;θ)=θk(1?θ)n?kL(x_1,x_2,...,x_n;\theta) = \theta^k(1-\theta)^{n-k}L(x1?,x2?,...,xn?;θ)=θk(1?θ)n?k
2.3 對數似然函數
ln?L=kln?θ+(n?k)ln?(1?θ)\ln L = k\ln\theta + (n-k)\ln(1-\theta)lnL=klnθ+(n?k)ln(1?θ)
2.4 求導得估計值
θ^MLE=kn\hat{\theta}_{MLE} = \frac{k}{n}θ^MLE?=nk?
Python實現
import numpy as np
from scipy.stats import bernoulli# 生成伯努利數據
np.random.seed(42)
theta_true = 0.7
n = 1000
data = bernoulli.rvs(theta_true, size=n)
k = sum(data)# 極大似然估計
theta_mle = k / n
print(f"MLE估計值: {theta_mle:.4f}")
LE估計值: 0.7120
3. 貝葉斯估計
3.1 先驗分布選擇
使用Beta分布作為共軛先驗:
f(θ;α,β)=Γ(α+β)Γ(α)Γ(β)θα?1(1?θ)β?1 f(\theta;\alpha,\beta) = \frac{\Gamma(\alpha+\beta)}{\Gamma(\alpha)\Gamma(\beta)}\theta^{\alpha-1}(1-\theta)^{\beta-1} f(θ;α,β)=Γ(α)Γ(β)Γ(α+β)?θα?1(1?θ)β?1
3.2 后驗分布
后驗分布也是Beta分布:
f(θ∣D)∝θk+α?1(1?θ)n?k+β?1 f(\theta|D) \propto \theta^{k+\alpha-1}(1-\theta)^{n-k+\beta-1} f(θ∣D)∝θk+α?1(1?θ)n?k+β?1
3.3 MAP估計
θ^MAP=k+α?1n+α+β?2 \hat{\theta}_{MAP} = \frac{k+\alpha-1}{n+\alpha+\beta-2} θ^MAP?=n+α+β?2k+α?1?
from scipy.stats import beta# 設置先驗參數 (α=2, β=2 相當于均勻分布)
alpha, beta_ = 2, 2# MAP估計
theta_map = (k + alpha - 1) / (n + alpha + beta_ - 2)
print(f"MAP估計值: {theta_map:.4f}")# 設置支持中文的字體
plt.rcParams['font.sans-serif'] = ['Microsoft YaHei'] # 使用微軟雅黑字體
plt.rcParams['axes.unicode_minus'] = False # 解決負號'-'顯示為方塊的問題
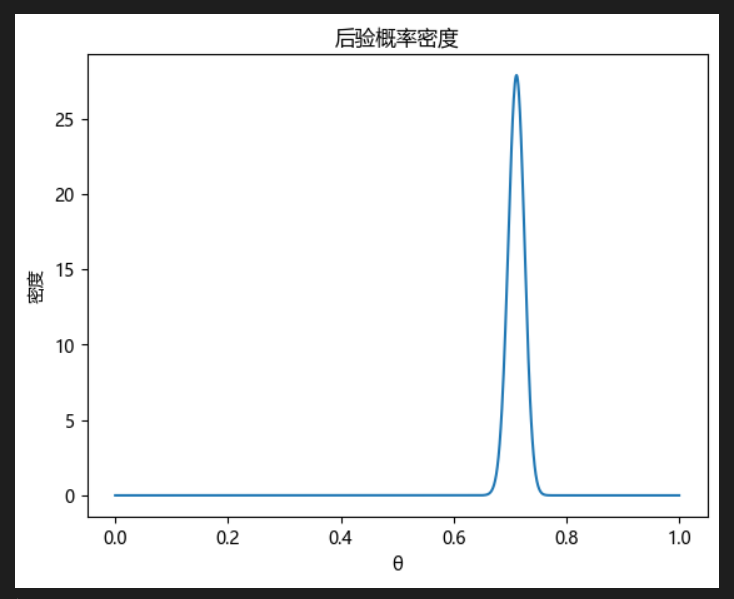
# 后驗分布可視化
import matplotlib.pyplot as plt
theta_range = np.linspace(0, 1, 1000)
posterior = beta.pdf(theta_range, k+alpha, n-k+beta_)
plt.plot(theta_range, posterior)
plt.title('后驗概率密度')
plt.xlabel('θ')
plt.ylabel('密度')
plt.show()
4. 經驗風險最小化與極大似然估計的關系
當滿足以下條件時,經驗風險最小化等價于極大似然估計:
- 模型是條件概率分布
- 損失函數是對數損失函數
4.1 經驗風險最小化形式
min?1N∑i=1N?ln?P(Yi∣Xi,θ) \min \frac{1}{N}\sum_{i=1}^N -\ln P(Y_i|X_i,\theta) minN1?i=1∑N??lnP(Yi?∣Xi?,θ)
4.2 等價于極大似然
max?∏i=1NP(Yi∣Xi,θ) \max \prod_{i=1}^N P(Y_i|X_i,\theta) maxi=1∏N?P(Yi?∣Xi?,θ)
注意事項
- 選擇先驗分布時需注意定義域匹配
- Beta分布是伯努利分布的共軛先驗
- 當先驗為均勻分布時,MAP估計退化為MLE估計
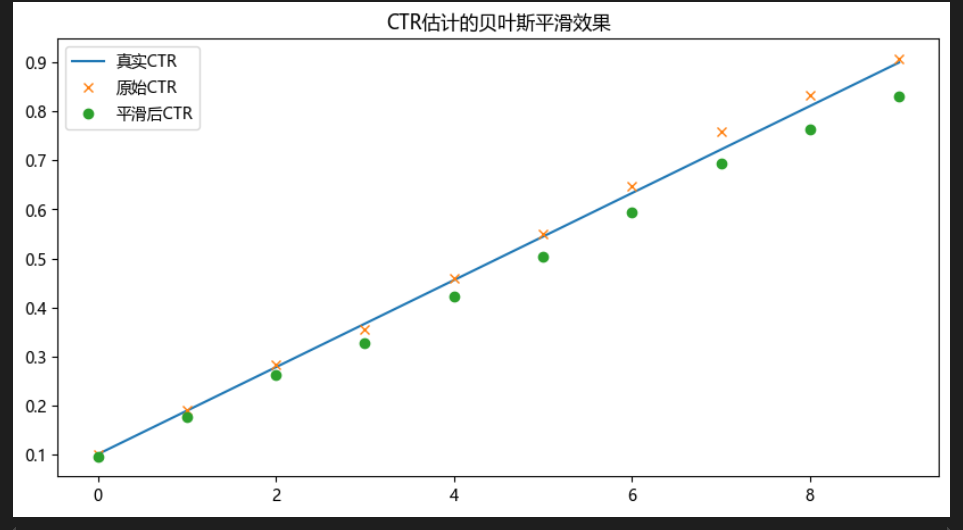
# 模擬廣告點擊數據 (10個廣告,每個展示1000次)
np.random.seed(42)
ctr_true = np.linspace(0.1, 0.9, 10)
clicks = [np.sum(bernoulli.rvs(p, size=1000)) for p in ctr_true]# 使用貝葉斯估計平滑小CTR
alpha, beta_ = 5, 95 # 先驗認為點擊率約5%
smoothed_ctr = [(c + alpha)/(1000 + alpha + beta_) for c in clicks]# 可視化對比
plt.figure(figsize=(10,5))
plt.plot(ctr_true, label='真實CTR')
plt.plot([c/1000 for c in clicks], 'x', label='原始CTR')
plt.plot(smoothed_ctr, 'o', label='平滑后CTR')
plt.legend()
plt.title('CTR估計的貝葉斯平滑效果')
plt.show()

![[自動化Adapt] 錄制引擎 | iframe 穿透 | NTP | AIOSQLite | 數據分片](http://pic.xiahunao.cn/[自動化Adapt] 錄制引擎 | iframe 穿透 | NTP | AIOSQLite | 數據分片)






)










