摘要:擴散變換器目前所取得的成功在很大程度上依賴于預訓練變分自編碼器(VAE)所塑造的壓縮潛在空間。然而,這種兩階段訓練模式不可避免地會引入累積誤差和解碼偽影。為解決上述問題,研究人員選擇回歸像素空間,但這需要付出構建復雜級聯流水線和增加令牌復雜度的代價。與他們的努力不同,我們提出利用神經場對分塊解碼進行建模,并給出了一種單尺度、單階段、高效且端到端的解決方案,稱之為像素神經場擴散(PixelNerd)。得益于PixNerd中高效的神經場表示,我們在無需任何復雜級聯流水線或VAE的情況下,直接在256×256分辨率的ImageNet數據集上實現了2.15的FID分數,在512×512分辨率的ImageNet數據集上實現了2.84的FID分數。此外,我們還將PixNerd框架拓展到了文本生成圖像的應用領域。我們的PixNerd-XXL/16在GenEval基準測試中取得了0.73的綜合得分,在DPG基準測試中取得了80.9的綜合得分,表現極具競爭力。Huggingface鏈接:Paper page,論文鏈接:2507.23268
研究背景和目的
研究背景:
近年來,擴散模型(Diffusion Models)在圖像生成領域取得了顯著進展,尤其是基于潛在空間的擴散變換器(Diffusion Transformers)展現出了強大的生成能力。這些模型通常依賴于預訓練的變分自編碼器(VAE)來壓縮圖像空間,從而在低維潛在空間上進行學習和生成。VAE通過顯著減少原始像素的空間維度,提供了一個緊湊且幾乎無損的潛在表示,極大地簡化了擴散變換器的學習難度。然而,這種兩階段訓練方法(先訓練VAE,再訓練擴散模型)不可避免地引入了累積誤差和解碼偽影,限制了生成圖像的質量和多樣性。
與此同時,直接在像素空間上進行擴散學習的模型進展較為緩慢。由于像素空間的龐大維度,直接學習擴散過程面臨巨大的計算挑戰,且生成的圖像細節和結構往往不如基于潛在空間的模型。為了解決這些問題,一些研究嘗試了級聯解決方案,通過在不同分辨率尺度上分割擴散過程來降低計算成本,但這些方法通常導致訓練和推理過程的復雜化。
研究目的:
針對上述背景,本研究旨在提出一種新穎、優雅且高效的單尺度、單階段端到端解決方案——像素神經場擴散(PixelNerd),以消除對VAE的依賴,并直接在像素空間上實現高質量的圖像生成。具體目標包括:
- 消除累積誤差和解碼偽影:通過直接在像素空間上學習擴散過程,避免兩階段訓練帶來的累積誤差和解碼偽影。
- 簡化模型架構:提出一種單尺度、單階段的端到端模型,避免復雜的級聯流水線和增加的令牌復雜度。
- 實現高質量圖像生成:在ImageNet等大型數據集上實現與基于潛在空間的模型相當甚至更優的生成性能。
- 拓展應用場景:將模型框架拓展到文本生成圖像等應用領域,驗證其泛化能力。
研究方法
1. 模型架構設計:
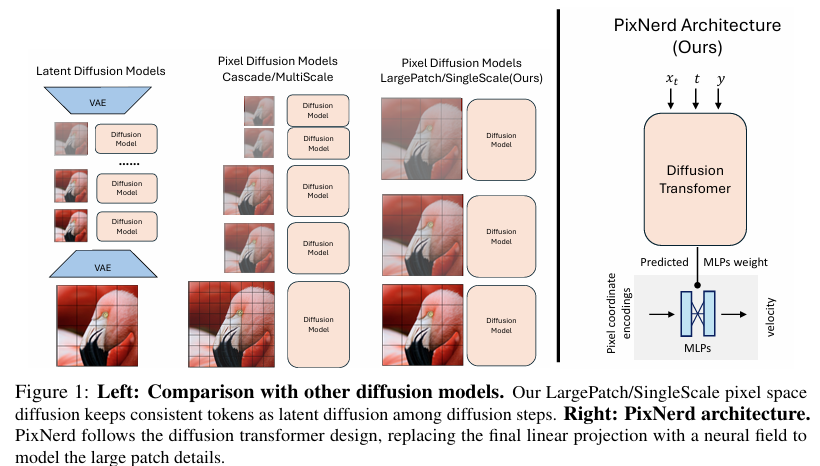
PixNerd遵循擴散變換器的設計原則,但用神經場(Neural Field)替換了最終的線性投影層,以建模大塊區域的細節。具體來說,PixNerd使用擴散變換器的最后隱藏狀態來預測神經場的參數(MLP權重),這些參數隨后用于解碼每個像素塊內的像素級擴散速度。
2. 神經場表示:
神經場通常采用多層感知機(MLP)將坐標編碼映射到信號(如RGB值)。在PixNerd中,每個像素塊內的局部坐標首先被轉換為坐標編碼,然后與對應的噪聲像素值一起輸入到神經場MLP中,以預測擴散速度。這種方法顯著減輕了在大塊配置下學習細節的挑戰。
3. 擴散過程建模:
PixNerd采用與標準擴散模型相似的擴散過程,但通過神經場來預測每個像素塊的擴散速度。在訓練過程中,模型通過最小化預測擴散速度與真實擴散速度之間的差異來優化神經場參數。
4. 優化與訓練策略:
為了提高模型的訓練穩定性和生成質量,PixNerd采用了多種優化策略,包括:
- SwIGLU激活函數:增強模型的非線性表達能力。
- RMSNorm歸一化:穩定訓練過程,加速收斂。
- 對數域采樣:提高采樣效率,減少計算成本。
- 表示對齊:通過與DINOv2等預訓練模型的中間特征進行對齊,增強模型的生成能力。
研究結果
1. 圖像生成質量:
在ImageNet 256×256和512×512分辨率上,PixNerd-XL/16分別實現了2.15和2.84的FID分數,與基于潛在空間的模型相當甚至更優。特別是在空間結構方面(sFID),PixNerd-XL/16在ImageNet 256×256上實現了4.55的sFID分數,顯著優于其他像素空間生成模型。
2. 文本生成圖像應用:
將PixNerd框架拓展到文本生成圖像領域后,PixNerd-XXL/16在GenEval基準測試中取得了0.73的綜合得分,在DPG基準測試中取得了80.9的綜合得分,表現極具競爭力。這表明PixNerd不僅限于圖像生成任務,還能有效處理更復雜的文本到圖像生成場景。
3. 計算效率與資源消耗:
與基于潛在空間的模型相比,PixNerd在訓練和推理過程中消耗更少的內存和計算資源。特別是在推理階段,PixNerd-L/16實現了近8倍于其他像素空間擴散模型的加速效果。
研究局限
盡管PixNerd在圖像生成質量和計算效率方面取得了顯著進展,但仍存在以下局限:
1. 細節表現不足:
在某些情況下,PixNerd生成的圖像細節仍不夠清晰,尤其是在處理復雜場景或精細結構時。這可能是由于神經場在建模極端細節方面的能力有限。
2. 多語言支持有限:
雖然PixNerd在英語提示下表現良好,但在處理其他語言(如中文、日語)時,生成圖像的質量和多樣性可能受到影響。這主要是由于訓練數據中非英語提示的覆蓋不足。
3. 分辨率適應性:
盡管PixNerd通過坐標插值實現了任意分辨率的圖像生成,但在處理極高分辨率(如超過1024×1024)時,生成圖像的質量和細節可能有所下降。這需要進一步優化神經場的表示能力和擴散過程的建模方法。
未來研究方向
針對上述局限,未來研究可以從以下幾個方面展開:
1. 增強細節建模能力:
通過改進神經場的架構設計(如增加MLP層數或通道數)或引入更復雜的坐標編碼方式,提升模型在建模極端細節方面的能力。此外,可以考慮結合超分辨率技術來進一步提升生成圖像的細節表現。
2. 拓展多語言支持:
通過收集和標注更多非英語提示的圖像數據,增強模型在處理多語言提示時的生成能力和多樣性。同時,可以探索跨語言提示生成技術,實現不同語言提示下的高質量圖像生成。
3. 提升高分辨率生成能力:
針對極高分辨率圖像生成的需求,可以研究更高效的神經場表示方法和擴散過程建模技術。例如,可以嘗試將神經場與多尺度建模方法相結合,或者引入分塊生成和融合策略來提升高分辨率圖像的生成質量和效率。
4. 探索更多應用場景:
除了文本生成圖像外,還可以探索PixNerd在其他生成任務(如視頻生成、3D物體生成)中的應用潛力。通過調整模型架構和訓練策略,使其能夠適應不同類型的數據和生成需求。
5. 優化訓練和推理過程:
進一步優化模型的訓練和推理過程,減少計算成本和內存消耗。例如,可以研究更高效的采樣算法和參數優化策略,或者利用硬件加速技術(如GPU并行計算)來提升模型的訓練和推理速度。













創建第一個Shader項目)

的組成詳解)
)


