Transformer:顛覆NLP的自注意力革命
Transformer是自然語言處理領域中極具影響力的深度學習模型架構,以下是對其的詳細介紹:
- 提出背景與應用:2017年,Vaswani等人在《Attention Is All You Need》論文中首次提出Transformer架構,它主要用于處理序列到序列的任務,如機器翻譯、文本生成等。
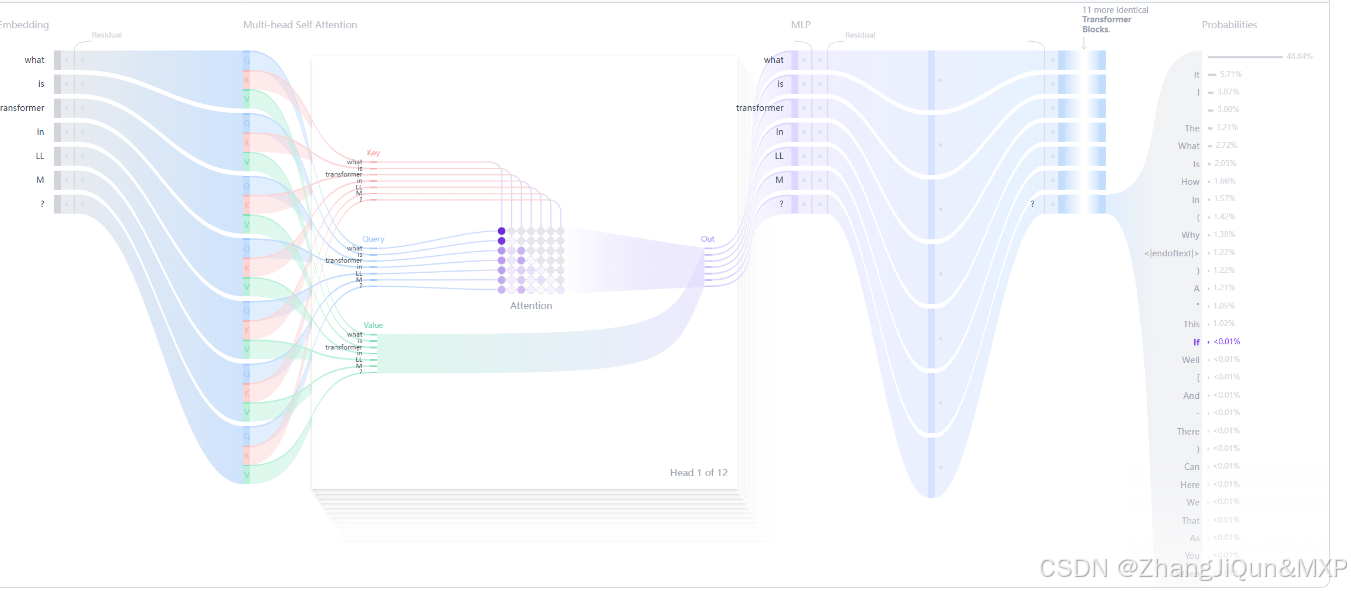
- 核心原理:文本生成的Transformer模型原理是“預測下一個詞”。模型通過自注意力機制處理用戶給定的文本(prompt),從而預測下一個最有可能出現的詞。自注意力機制是Transformer的核心創新,它能讓模型處理整個序列,更有效地捕捉長距離依賴關系,這是相較于之前的RNN架構的重大優勢。
- 模型結構
- 嵌入層(Embedding):將文本輸入分割成詞元(token),可以是單詞或子詞,然后將這些詞元轉換成能夠捕捉詞語語義含義的數值向量,即嵌入(embeddings)。
- Transformer塊:是模型處理和轉換輸入數據的基本構建單元,每個塊包含注意力機制和多層感知器(MLP)層。注意







和Pycharm)

)



)

)



