目錄
一.機器學習概述
二.人工智能的兩大方向
三.KNN算法介紹
1.核心思想:“物以類聚,人以群分”
2.算法步驟
四.KNN算法實現
1.安裝scikit-learn庫
2.導入knn用于分類的類KNeighborsClassifier
3.設置KNeighborsClassifier的相關參數
4.訓練模型
5.進行預測
6.計算準確率
五.鳶尾花案例實現
1.準備訓練集和測試集數據
2.讀取數據
3.劃分訓練集
4.調用KNN,完成訓練過程
5.用訓練集中的數據預測,并計算結果的正確率
6.劃分測試集
7.將測試集中的數據進行預測,計算準確率
8.完整代碼呈現
一.機器學習概述
- 機器學習是人工智能的核心技術之一,涉及利用數學公式從數據中總結規律。
- 經典算法(如KNN、線性回歸、決策樹等)是學習重點,掌握后可輕松擴展至衍生算法。
- 機器學習流程分為三個階段:
- 數據收集:需大量高質量數據(如GPT訓練數據達45TB)。
- 模型訓練:通過數學公式求解未知參數(如拋物線公式中的ABC)。
- 預測:將新數據代入訓練好的模型得出結果。
二.人工智能的兩大方向
- 回歸:預測連續型數值(如房價、股票價格、溫度)。
- 分類:劃分離散類別(如人臉識別、指紋識別、動物分類)。
三.KNN算法介紹
1.核心思想:“物以類聚,人以群分”
KNN 分類的核心邏輯是:一個樣本的類別,由它周圍距離最近的 K 個鄰居的類別決定。
- 如果一個樣本周圍的多數鄰居屬于某一類,則該樣本也被判定為該類。
- 這是一種 “懶惰學習”(Lazy Learning)算法,訓練階段不進行模型擬合,僅存儲所有訓練數據;直到預測時,才通過計算新樣本與訓練樣本的距離來確定類別。
2.算法步驟
-
確定參數 K:選擇一個正整數 K(例如 K=3、5、7),表示要參考的 “鄰居數量”。
- K 值過小:容易受噪聲影響,模型過擬合(泛化能力差)。
- K 值過大:可能包含過多其他類別的樣本,模型欠擬合(分類模糊)。
-
計算距離:對于待預測的新樣本,計算它與所有訓練樣本之間的距離(衡量樣本間的 “相似性”)。 常用距離度量方式:
- 歐氏距離(最常用,適用于連續特征):
- 二維空間公式:√[(x?-x?)2 + (y?-y?)2]。
- 三維空間公式:√[(x?-x?)2 + (y?-y?)2 + (z?-z?)2]。
- N維空間擴展:對每個維度差值平方求和后開根號。
- 曼哈頓距離(適用于高維數據,抗噪聲):\(\text{距離} = |x_1-y_1| + |x_2-y_2| + ... + |x_d-y_d|\)
- 余弦相似度(適用于文本、向量等,衡量方向相似性)。
-
篩選 K 個最近鄰:根據距離從小到大排序,選取與新樣本距離最近的 K 個訓練樣本(即 “K 個鄰居”)。
-
投票決定類別:統計 K 個鄰居的類別,出現次數最多的類別即為新樣本的預測類別(“少數服從多數”)。
四.KNN算法實現
1.安裝scikit-learn庫
KNN算法已封裝于Scikit-learn(SKL)庫中,無需手動實現距離公式和訓練過程,所以我們要先安裝好scikit-learn庫(可以自己指定版本號),命令如下:
pip install scikit-learn==1.0.2 -i Https://pypi.tuna.tsinghua.edu.cn/simple
2.導入knn用于分類的類KNeighborsClassifier
from sklearn.neighbors import KNeighborsClassifier
3.設置KNeighborsClassifier的相關參數
源碼如下:
class KNeighborsClassifier(KNeighborsMixin, ClassifierMixin, NeighborsBase):"""Classifier implementing the k-nearest neighbors vote.def __init__(self,n_neighbors=5,*,weights="uniform",algorithm="auto",leaf_size=30,p=2,metric="minkowski",metric_params=None,n_jobs=None,):super().__init__(n_neighbors=n_neighbors,algorithm=algorithm,leaf_size=leaf_size,metric=metric,p=p,metric_params=metric_params,n_jobs=n_jobs,)self.weights = weights
- 關鍵參數:
n_neighbors(K值,默認5):控制鄰居數量。weights(權重):可調整不同類別的優先級(如偏好紅色數據)。algorithm(計算算法):優化排序速度(如暴力搜索、KD樹、球樹或自動選擇)。
4.訓練模型
KNeighborsClassifier中已經封裝過fit()方法,所以我們只用調用方法即可完成訓練過程
knn = KNeighborsClassifier(n_neighbors=5)
knn.fit(train_x,train_y)train_x為訓練集中的特征數據
train_y為根據特征而得到的分類類別數據
5.進行預測
可以直接通過KNeighborsClassifier中的predict()方法完成對數據的預測
train_predicted = knn.predict(要預測的數據)
6.計算準確率
可以直接通過KNeighborsClassifier中的score()方法完成對預測數據結果的準確率的計算
train_score = knn.score(train_x,train_y)
五.鳶尾花案例實現
1.準備訓練集和測試集數據
鳶尾花訓練數據.xlsx 如下:
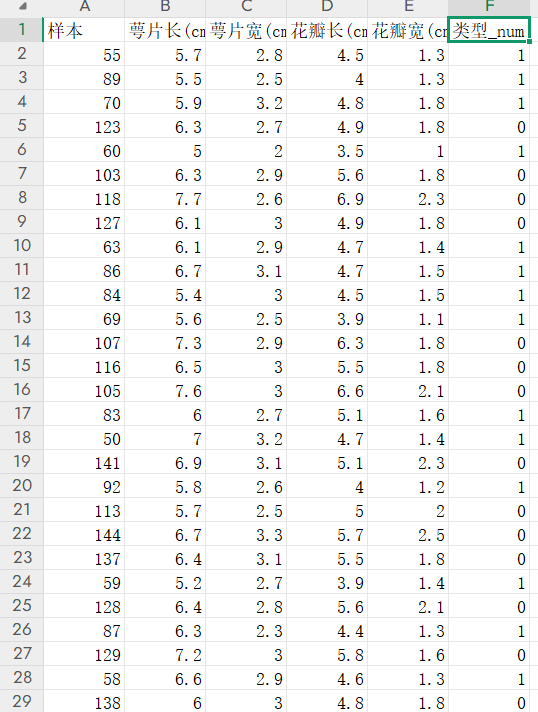
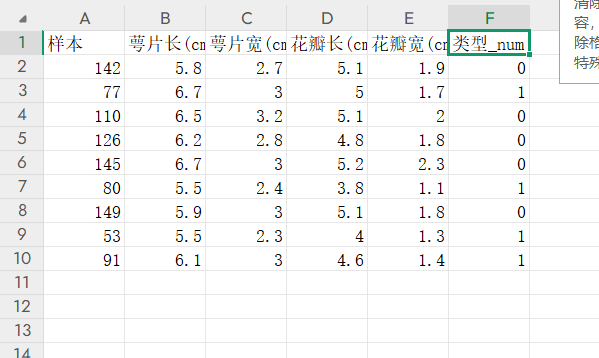
鳶尾花測試數據.xlsx 如下:
2.讀取數據
train_data=pd.read_excel('鳶尾花訓練數據.xlsx')
test_data=pd.read_excel('鳶尾花測試數據.xlsx')3.劃分訓練集
將訓練集的特征列劃分到train_x數據,分類類型則劃分到train_y中
train_x=train_data[['萼片長(cm)','萼片寬(cm)','花瓣長(cm)','花瓣寬(cm)']]
train_y=train_data['類型_num']4.調用KNN,完成訓練過程
knn=KNeighborsClassifier(n_neighbors=5)
knn.fit(train_x,train_y)5.用訓練集中的數據預測,并計算結果的正確率
train_predicted = knn.predict(train_x)
train_score = knn.score(train_x,train_y)
print('train_score={}'.format(train_score))train_score=0.9696969696969697
可以看到,即使使用訓練集中的數據進行預測,也達不到百分百的正確率
6.劃分測試集
test_x=test_data[['萼片長(cm)','萼片寬(cm)','花瓣長(cm)','花瓣寬(cm)']]
test_y=test_data['類型_num']7.將測試集中的數據進行預測,計算準確率
test_predicted=knn.predict(test_x)
test_score = knn.score(test_x,test_y)
print('test_score={}'.format(test_score))test_score=1.0由于測試集中數據比較少,所以正確率達到了百分百
8.完整代碼呈現
from sklearn.neighbors import KNeighborsClassifier
import pandas as pd
train_data=pd.read_excel('鳶尾花訓練數據.xlsx')
test_data=pd.read_excel('鳶尾花測試數據.xlsx')train_x=train_data[['萼片長(cm)','萼片寬(cm)','花瓣長(cm)','花瓣寬(cm)']]
train_y=train_data['類型_num']knn=KNeighborsClassifier(n_neighbors=5)
knn.fit(train_x,train_y)
train_predicted = knn.predict(train_x)
train_score = knn.score(train_x,train_y)
print('train_score={}'.format(train_score))test_x=test_data[['萼片長(cm)','萼片寬(cm)','花瓣長(cm)','花瓣寬(cm)']]
test_y=test_data['類型_num']
test_predicted=knn.predict(test_x)
test_score = knn.score(test_x,test_y)
print('test_score={}'.format(test_score))
)









---層序遍歷二叉樹)
)

對北半球光伏數據進行時間序列預測)





