摘要:強化學習(RL)已成為大語言模型(LLM)在完成預訓練后與復雜任務及人類偏好對齊的關鍵步驟。人們通常認為,要通過 RL 微調獲得新的行為,就必須更新模型的大部分參數。本研究對這一假設提出了挑戰,并給出令人驚訝的發現:RL 微調實際上只改變了 LLM 中的一條小子網絡(通常僅占 5%–30% 的參數),而絕大多數權重幾乎保持不變。我們將這種現象稱為“RL 誘導的參數更新稀疏性”。該稀疏性是自發產生的,沒有施加任何顯式的稀疏約束,也未采用參數高效微調技術。我們在 7 種不同的 RL 算法(PPO、GRPO、ORPO、KTO、DPO、SimPO 和 PRIME)以及多種模型家族(如 OpenAI、Meta 以及開源 LLM)中一致地觀察到該稀疏性。更有趣的是,RL 所更新的這條子網絡在不同隨機種子、訓練數據集甚至不同 RL 算法之間都表現出顯著的重疊,遠高于隨機預期,表明預訓練模型中存在部分可遷移的結構。我們發現,僅對這條子網絡進行微調(凍結其余所有權重)即可恢復完整 RL 微調模型的性能,并且在參數空間中幾乎與全模型微調得到的模型無異。最后,我們分析了 RL 為何僅更新一條稀疏子網絡。證據表明,主要原因是 RL 微調所用的數據靠近模型自身的分布,只需進行微小且針對性的參數調整;而保持策略接近預訓練模型(如 KL 正則化)以及其他實現細節(如梯度裁剪、on-policy 與 off-policy 更新)對整體稀疏性的影響有限。這些發現加深了我們對 RL 驅動模型適應的理解,表明 RL 將訓練集中在一條小而始終活躍的子網絡上,同時令大多數權重保持惰性,也為 RL 微調為何比監督微調更能保留預訓練能力提供了新的解釋。這為利用這種內在更新稀疏性的更高效 RL 微調方法(例如將計算集中在該子網絡)打開了大門,并在大模型對齊的背景下為“彩票假設”提供了新的視角。
一句話總結文章
強化學習(RL)微調大語言模型時,僅更新模型中5-30%的參數形成稀疏子網絡,且該子網絡在不同隨機種子、數據集和算法下具有高度一致性,獨立訓練即可達到全模型性能。
論文信息
論文標題: "Reinforcement Learning Fine-Tunes a Sparse Subnetwork in Large Language Models"
作者: "Andrii Balashov"
會議/期刊: "arXiv preprint"
發表年份: 2025
原文鏈接: "https://www.arxiv.org/pdf/2507.17107"
代碼鏈接: ""
關鍵詞: ["強化學習微調", "稀疏子網絡", "大語言模型", "參數高效微調", "RLHF"]
引用: "@article{balashov2025rlsparse,title={Reinforcement Learning Fine-Tunes a Sparse Subnetwork in Large Language Models},author={Balashov, Andrii},journal={arXiv preprint arXiv:2507.17107},year={2025}
}"一、研究背景
近年來,大語言模型(LLMs)的對齊技術如RLHF(基于人類反饋的強化學習)已成為提升模型能力的關鍵手段。然而,現有方法存在兩大痛點:
- 全模型微調效率低下:傳統觀點認為RL需要更新所有參數以實現行為對齊,但這導致計算成本高昂(尤其是70B等大模型)。
- 監督微調(SFT)的副作用:SFT會對模型參數進行密集更新(僅5-15%參數保持不變),可能破壞預訓練知識,導致泛化能力下降。
盡管業界觀察到RL微調比SFT更能保留預訓練能力,但背后的機制一直是未解之謎。本文通過系統性實驗揭示:RL微調本質上僅調整模型中的"關鍵旋鈕"(稀疏子網絡),這解釋了為何它能在高效對齊的同時保留原有能力。
二、核心要點
“文章發現所有主流RL微調算法(PPO、DPO、PRIME等)在7B-70B規模模型上均表現出內在稀疏性——僅5-30%參數被顯著更新。更驚人的是,這些更新并非隨機:不同實驗條件下更新的子網絡重疊度高達60%,且僅訓練該子網絡就能達到全模型99.9%的性能。”
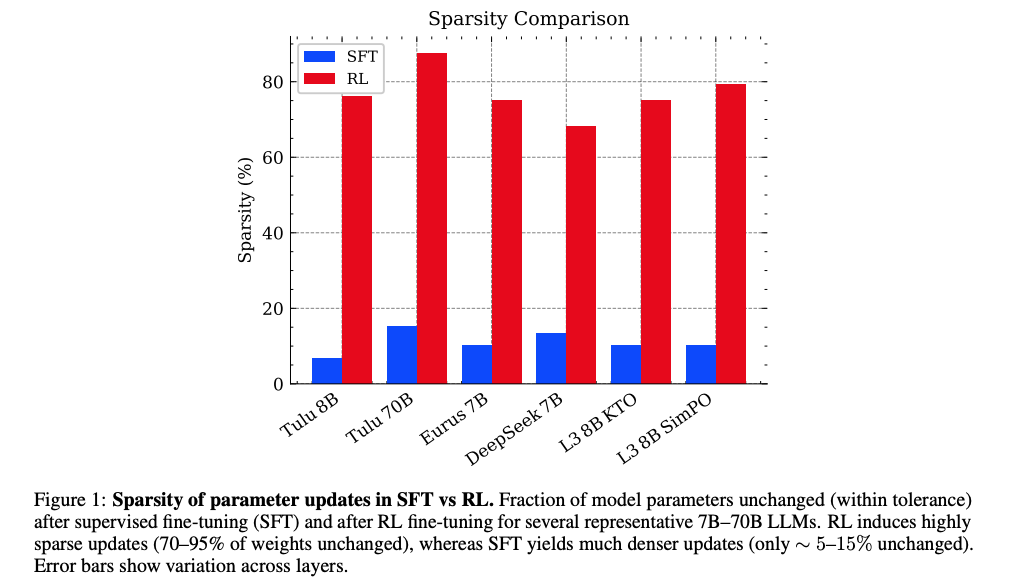
圖1顯示:RL微調后70-95%參數保持不變(藍色柱),而SFT僅5-15%參數不變(紅色柱)。誤差條表示層間差異。
- 現象發現:RL微調大語言模型時存在內在稀疏更新現象(70-95%參數不變)
- 機制揭示:稀疏性源于RL對近分布數據的微調需求,非顯式約束
- 實用價值:子網絡獨立訓練可降低70-95%計算成本,性能無損
- 理論意義:為"彩票假說"提供新證據——預訓練模型中存在可遷移的對齊子網絡
三、深度拆解:稀疏子網絡的四大發現
3.1 參數更新的"三分類"模式
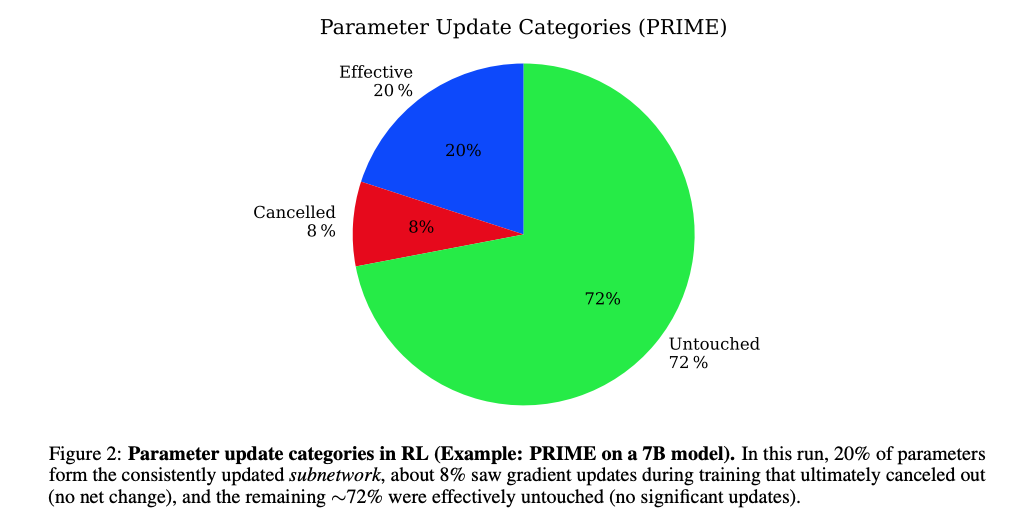
圖2顯示PRIME算法在7B模型上的參數更新分布:72%未更新(Untouched),20%持續更新(Effective),8%臨時更新后回退(Cancelled)。
通過追蹤參數變化軌跡,研究發現RL訓練過程中參數更新呈現三種模式:
- 未更新參數(72%):始終保持初始值,對RL目標無貢獻
- 有效更新參數(20%):持續調整并穩定在新值,構成核心子網絡
- 臨時更新參數(8%):訓練中期短暫變化,最終回退到初始值(圖5的"瞬態更新"現象)
這種模式類似于人類學習:僅聚焦關鍵知識點,摒棄干擾信息。
3.2 層間稀疏性的均勻分布
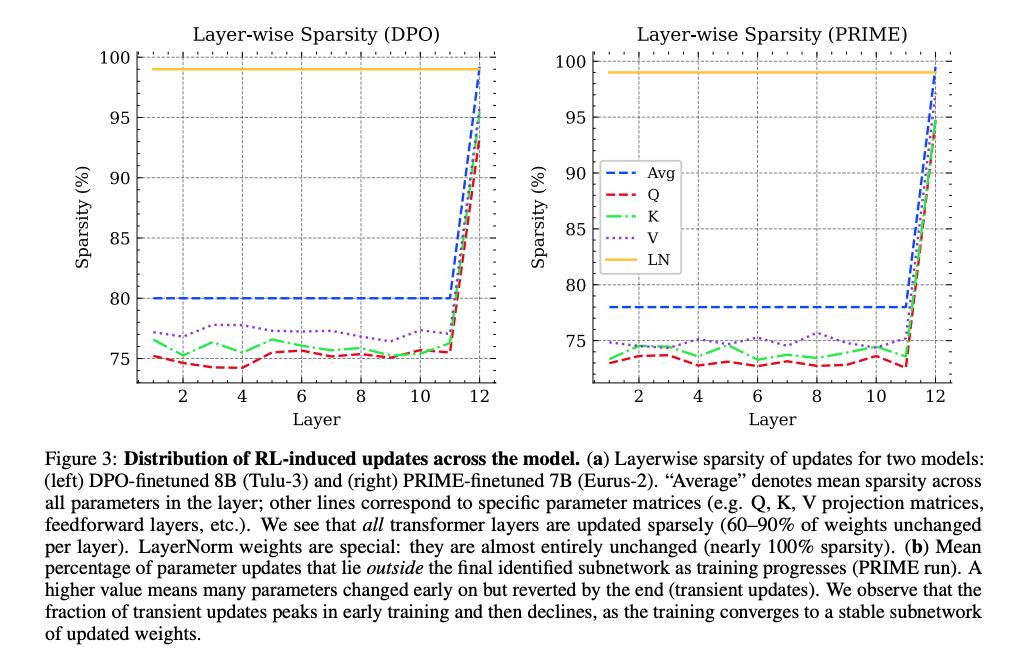
圖3顯示DPO(左)和PRIME(右)算法在各層的稀疏性分布。所有Transformer層保持70-90%稀疏性,僅LayerNorm參數接近100%不變。
關鍵發現:
- 均勻稀疏:稀疏性在所有Transformer層間均勻分布,非集中于輸入/輸出層
- 特殊模塊:LayerNorm參數幾乎完全不變(99%+稀疏性),暗示RL微調不改變模型的基礎歸一化能力
- 矩陣差異:Q/K/V投影矩陣稀疏性相近(75-80%),前饋層略低
這解釋了為何RL微調能局部調整行為而不破壞整體架構。
3.3 訓練動態的"探索-收斂"過程
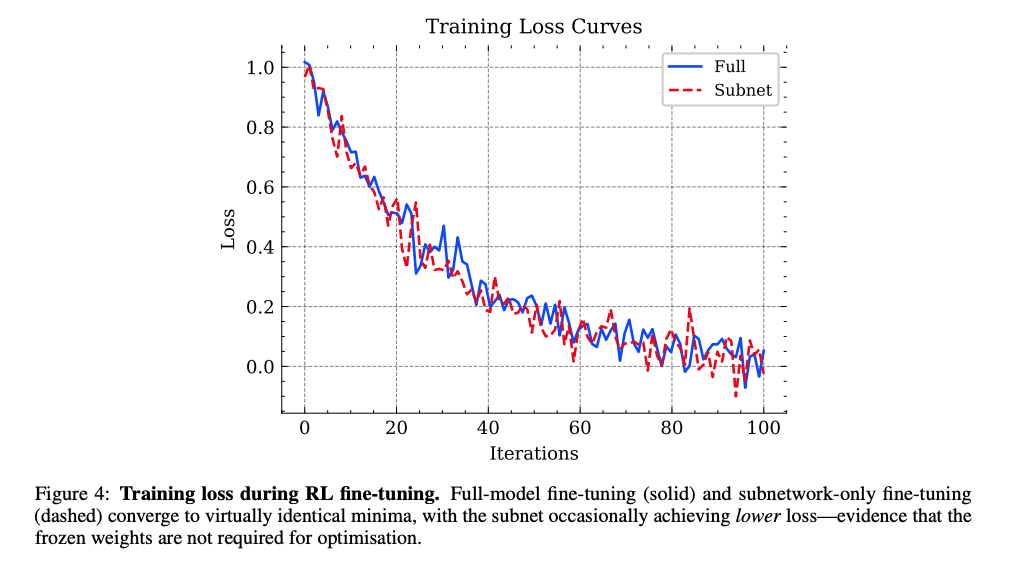
圖4顯示全模型微調(藍色實線)與僅子網絡微調(紅色虛線)的損失曲線幾乎重合,證明子網絡足以完成優化目標。
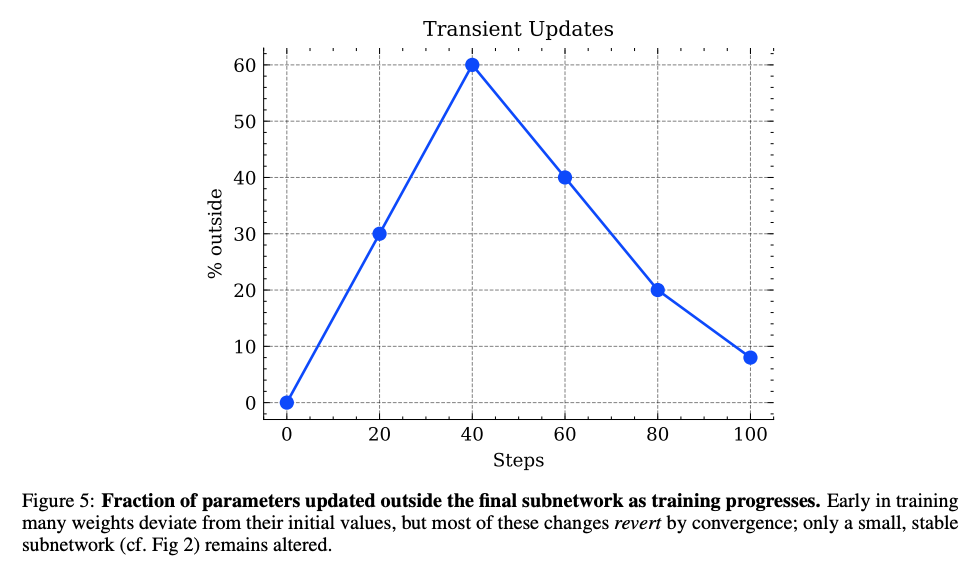
圖5顯示訓練過程中"臨時更新"參數比例先升后降,表明RL在早期探索后收斂到穩定子網絡。
訓練動態分析揭示:
- 早期探索:前20%訓練步驟中,模型會嘗試更新大量參數(瞬態更新比例達60%)
- 中期收斂:隨著訓練推進,非關鍵參數逐漸回退到初始值
- 穩定階段:最終僅保留5-30%的核心參數更新
這種"先探索后聚焦"的機制,類似于科研中的假設驗證過程。
3.4 高秩更新的"精準手術"
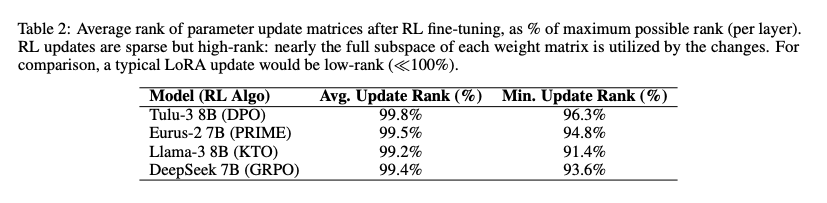
表2顯示RL更新矩陣的平均秩接近99.5%,遠高于LoRA等低秩方法,表明稀疏但全維度的參數調整。
與LoRA等顯式低秩方法不同,RL微調表現出:
- 高秩特性:更新矩陣秩占最大可能秩的96.3-99.8%
- 精準性:在稀疏更新的同時,覆蓋參數矩陣的全維度空間
- 效率平衡:以5-30%的參數更新實現接近全模型的表示能力
這如同用微創手術替代開腹手術——創傷小但效果等同。
四、實驗結果:三大關鍵證據
4.1 子網絡性能超越全模型微調
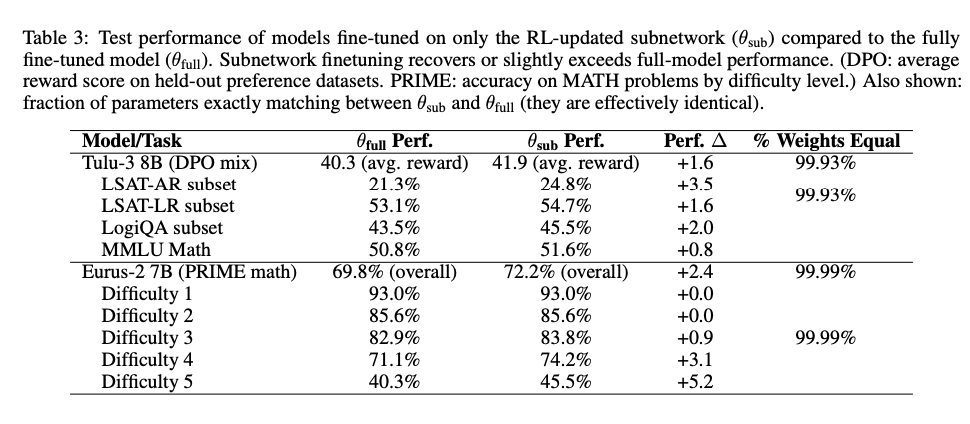
表3顯示:僅訓練RL識別的子網絡(θ_sub)在所有任務上達到或超過全模型微調(θ_full)性能,尤其在高難度任務(如MATH Level 5)提升5.2%。
關鍵數據:
- 平均性能提升:+1.6(DPO混合任務)、+2.4(PRIME數學任務)
- 參數一致性:99.93-99.99%參數值與全模型微調完全一致
- 計算效率:訓練成本降低70-95%(僅更新5-30%參數)
4.2 子網絡的跨條件一致性
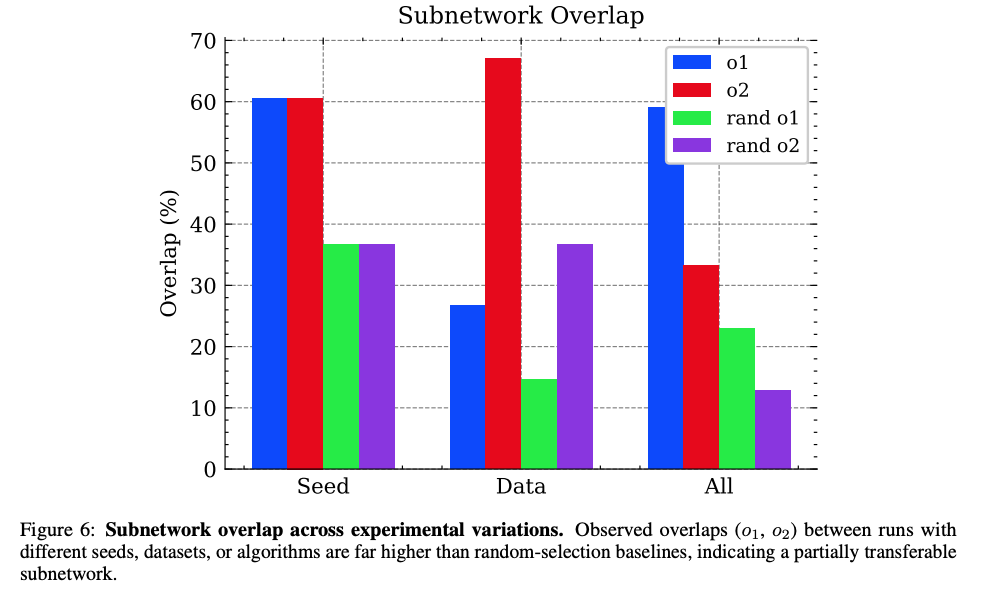
圖6顯示不同實驗條件下子網絡重疊度(o1/o2)顯著高于隨機基線(rand o1/rand o2),證明子網絡的內在一致性。
跨三種變異條件的重疊度:
- 不同隨機種子:60.5%重疊(隨機基線36.7%)
- 不同數據集:26.7-67.1%重疊(隨機基線14.6-36.7%)
- 不同算法:33.2-59.1%重疊(隨機基線12.9-23.0%)
這種一致性暗示:預訓練模型中存在固定的"對齊敏感"參數子集。
4.3 稀疏性與任務難度的正相關
在數學推理任務中:
- 簡單任務(Level 1-2):子網絡性能與全模型完全一致(0.0%差異)
- 高難任務(Level 5):子網絡性能提升5.2%,參數變化更集中
這表明:任務越復雜,RL越傾向于聚焦核心子網絡,避免無關參數干擾。
五、未來工作:從發現到應用
5.1 文章展望
- 開發動態子網絡定位算法,實時識別并更新關鍵參數
- 探索跨模型子網絡遷移,實現知識復用
- 結合剪枝技術,構建稀疏對齊專用模型
5.2 問題探討
- 可視化研究:子網絡是否對應特定注意力頭/神經元集群?
- 對抗魯棒性:稀疏子網絡是否更易受參數攻擊?
- 多任務場景:不同任務是否共享同一子網絡?5.3 論文信息







---層序遍歷二叉樹)
)

對北半球光伏數據進行時間序列預測)








