KNN原理及應用
機器學習方法的分類
基于概率統計的方法
- K-近鄰(KNN)
- 貝葉斯模型
- 最小均值距離
- 最大熵模型
- 條件隨機場(CRF)
- 隱馬爾可夫模型(HMM)
基于判別式的方法
- 決策樹(DT)
- 感知機
- 支持向量機(SVM)
- 人工神經網絡(NN)
- 深度學習(DL)
聚類算法
- 基于劃分的聚類
- K-Means、K-MEDOIDS、CLARANS
- 層次聚類
- BIRCH、CURE、CHAMELEON
- 密度聚類
- DBSCAN、OPTICS、DENCLUE
增強學習方法
- 隨機森林
- 增強算法(Boosting)
- 極端梯度提升(Xgboost)
- 梯度增強決策樹(GBDT)
回歸分析方法
- 回歸分析方法
- 非線性回歸(邏輯回歸)
概率密度及累積分布函數
概率密度函數
-
隨機變量x出現的可能性,在某個確定的取值點附近的輸出值,記作 p ( x ) p(x) p(x)。
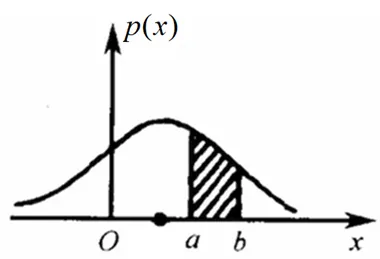
累計分布函數
-
隨機變量 x 的取值落在某個區域之內的概率則為概率密度函數在這個區域上的積分。
也稱為概率分布函數,記作 P X ( x ) P_X(x) PX?(x)。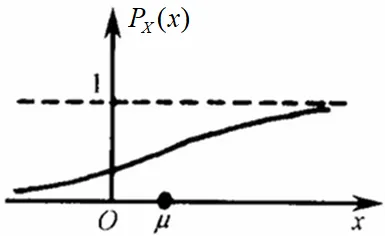
高斯分布
最常見的概率分布模型,也稱為正態分布
二維:
p ( x ) = 1 2 π e x p ( ? ( x ? μ ) 2 2 σ 2 ) p(x)=\frac{1}{\sqrt{2\pi}exp(-\frac{(x-\mu)^2}{2\sigma^2})} p(x)=2π?exp(?2σ2(x?μ)2?)1?
多維數據:
p X ( x 1 , ? , x d ) = 1 ( 2 π ) d ∣ ∑ ∣ e ( x ? μ ) T ∑ ? 1 ( x ? μ ) p_X(x_1,\cdots,x_d)=\frac{1}{\sqrt{(2\pi)^d|\sum|e^{(x-\mu)^T\sum^{-1}(x-\mu)}}} pX?(x1?,?,xd?)=(2π)d∣∑∣e(x?μ)T∑?1(x?μ)?1?
貝葉斯決策
以分類為例
對于數據樣本x,有M個類別,記作 C 1 , C 2 , ? , C m C_1,C_2,\cdots,C_m C1?,C2?,?,Cm?
- x屬于各個類別的概率(后驗概率):
- p ( C 1 ∣ x ) , p ( C 2 ∣ x ) , ? , p ( C m ∣ x ) p(C_1|x),p(C_2|x),\cdots,p(C_m|x) p(C1?∣x),p(C2?∣x),?,p(Cm?∣x)
- 判斷樣本x屬于類別 C i C_i Ci?:
- i = a r g M a x ( p ( C m ∣ x ) ) i=argMax(p(C_m|x)) i=argMax(p(Cm?∣x))
后驗概率的計算
- 經典的貝葉斯概率公式:
- P ( C i ∣ x ) = P ( x ∣ C i ) P ( C i ) P ( x ) = P ( x ∣ C i ) P ( C i ) ∑ P ( x ∣ C m ) P ( C m ) P(C_i|x)=\frac{P(x|C_i)P(C_i)}{P(x)}=\frac{P(x|C_i)P(C_i)}{\sum P(x|C_m)P(C_m)} P(Ci?∣x)=P(x)P(x∣Ci?)P(Ci?)?=∑P(x∣Cm?)P(Cm?)P(x∣Ci?)P(Ci?)?
- P ( C i ) = N i N P(C_i)=\frac{N_i}{N} P(Ci?)=NNi??
- P ( x ∣ C i ) P(x|C_i) P(x∣Ci?)可以叫做先驗概率、先驗密度、似然。
基于KNN的概率密度估計方法
后驗密度 p ( C i ∣ x ) p(C_i|x) p(Ci?∣x)的估算
-
基于假設:
-
相似的輸入應該有相似的輸出。
-
局部的分布模型只受到鄰近實例樣本的影響。
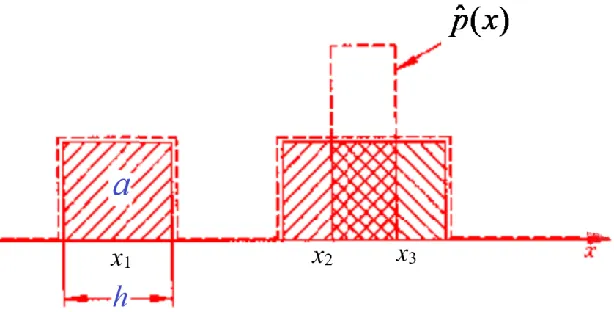
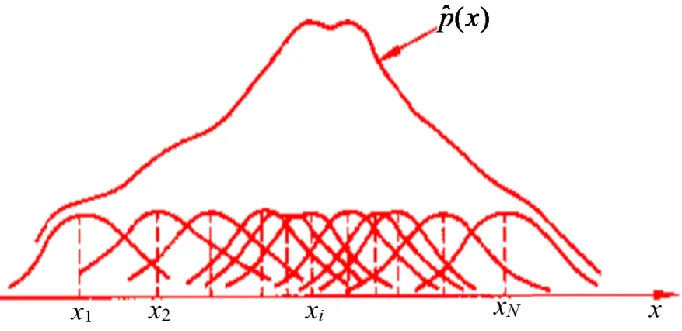
-
-
隨機變量x落入區域R的概率:
P = ∫ R p ( x ) d x P=\int_Rp(x)dx P=∫R?p(x)dx
-
從規模為N 的樣本集中抽取 k 個樣本落入區域 R 的概率 符合隨機變量的二項分布,可以寫成:
P k = C N k P k ( 1 ? P ) N ? k , C N k = N ! k ! ( N ? k ) ! P_k=C_N^kP^k(1-P)^{N-k},\quad C_N^k=\frac{N!}{k!(N-k)!} Pk?=CNk?Pk(1?P)N?k,CNk?=k!(N?k)!N!?
-
具體操作方法
- 從隨機變量 x 出發,向四周擴展,逐漸擴大區域 R。
- 直至區域里面包進來 k 個樣本( x 最近鄰的樣本)
- 此時,周邊區域的大小為 V R V_R VR?,分布有( k +1 )個樣本。
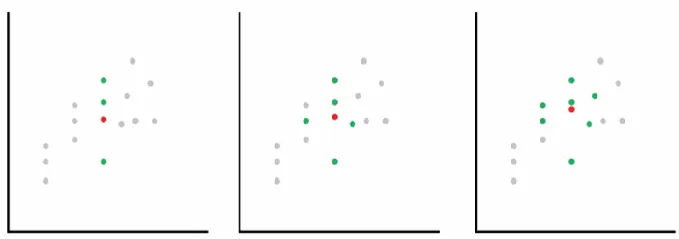
-
具體操作方法的理論:
目標是估計給定數據點x的后驗密度 p ( C ∣ x ) p(C|x) p(C∣x)。
E [ k ] = N P k ≈ N P ^ \begin{align} E[k]=NP\\ k\approx N{\hat{P}} \end{align} E[k]=NPk≈NP^??
式 ( 1 ) (1) (1)說明,在區域R內,期望的最近鄰點數k等于總樣本數N乘以概率P。
式 ( 2 ) (2) (2)說明,實際觀測到的最近鄰點數k近似等于NP。
由 ( 2 ) (2) (2)可得:
P ^ ≈ k N \begin{align} \hat{P}\approx\frac{k}{N} \end{align} P^≈Nk???
概率P可理解為密度函數 p ( x ) p(x) p(x)在區域R內的積分,近似為 p ( x ) p(x) p(x)乘以區域體積 V V V:
P = ∫ R p ( x ) d x = p ( x ) V \begin{align} P=\int_{R}p(x)dx=p(x)V \end{align} P=∫R?p(x)dx=p(x)V??
由式 ( 3 ) ( 4 ) (3)(4) (3)(4)可得:
k N ≈ P ^ = ∫ R p ^ ( x ) d x ≈ p ^ ( x ) V \begin{align} \frac{k}{N}\approx\hat{P}=\int_R\hat{p}(x)dx\approx\hat{p}(x)V \end{align} Nk?≈P^=∫R?p^?(x)dx≈p^?(x)V??
得:
p ^ ( x ) = k / N V \begin{align} \hat{p}(x)=\frac{k/N}{V} \end{align} p^?(x)=Vk/N???
在計算后驗概率的時候,沒有必要計算體積V:
( 6 ) (6) (6)等價于 ( 7 ) (7) (7):
p ^ ( x ) = k N V k ( x ) \begin{align} \hat{p}(x)=&\frac{k}{NV_k(x)}\\ \end{align} p^?(x)=?NVk?(x)k???
其中, k k k是 x x x的鄰域內所有樣本的數量, N N N為總樣本數, V k ( x ) V_k(x) Vk?(x)是鄰域的體積。
當我們關注某個特別的類 C i C_i Ci?時,公式 ( 7 ) (7) (7)中的換位特別的類 C i C_i Ci?的樣本數 k i k_i ki?,總樣本數 N i N_i Ni?。
于是得到公式 ( 8 ) (8) (8),即類別條件概率密度估計:
p ^ ( x ∣ C i ) = k i N i V k ( x ) \begin{align} \hat{p}(x|C_i)=&\frac{k_i}{N_iV_k(x)} \end{align} p^?(x∣Ci?)=?Ni?Vk?(x)ki????
基于頻率,易得表示類別 C i C_i Ci?的先驗概率估計:
p ( C i ) = N i N \begin{align} p(C_i)=\frac{N_i}{N} \end{align} p(Ci?)=NNi????
由 ( 7 ) ( 8 ) ( 9 ) (7)(8)(9) (7)(8)(9)可得:
P ^ ( C i ∣ x ) = k i k \begin{align} \hat{P}(C_i|x)=\frac{k_i}{k} \end{align} P^(Ci?∣x)=kki????
后驗概率 P ( C i ∣ x ) P(C_i|x) P(Ci?∣x)簡化為x的最近鄰中屬于 C i C_i Ci?的比例 k i k \frac{k_i}{k} kki??。
KNN分類方法
由上推理可知:
k = k 1 + k 2 + k 3 P ^ ( C 1 ∣ x ) = k 1 k P ^ ( C 2 ∣ x ) = k 2 k P ^ ( C 3 ∣ x ) = k 3 k \begin{align} k=k_1+k_2+k_3\\ \hat{P}(C_1|x)=\frac{k_1}{k}\\ \hat{P}(C_2|x)=\frac{k_2}{k}\\ \hat{P}(C_3|x)=\frac{k_3}{k}\\ \end{align} k=k1?+k2?+k3?P^(C1?∣x)=kk1??P^(C2?∣x)=kk2??P^(C3?∣x)=kk3????
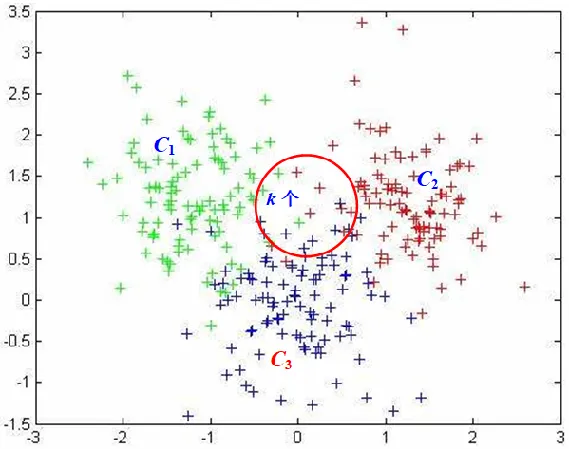
算法描述
如果一個樣本在特征空間中的 k 個最鄰近 (即最相似)的樣本中的大多數屬于某一個類別,則該樣本也屬于這個類別。
- 特點:
- KNN算法的預測風險基本與貝葉斯模型一樣,理論上非常低的錯誤風險。
- 沒有明顯的訓練過程。
- 算法的復雜度很高。
- 需要記錄所有的訓練樣本。
- 需要計算與所有訓練樣本的距離。
時間復雜度
- KNN的時間復雜度為 O ( n 2 ) O(n^2) O(n2)。
- 設:訓練樣本規模M,測試樣本規模N,選擇k個最近鄰。
- 時間復雜度為: O ( k × M × N ) O(k\times M\times N) O(k×M×N)
- 若 M > = N M>=N M>=N: O ( n 2 ) O(n^2) O(n2)
訓練樣本的有效性
不是所有樣本都有用
→KNN的決策邊界僅由靠近類別邊界的樣本決定,而遠離邊界的樣本(如類別內部的點)對分類結果無影響
優化思路:相容子集
定義:相容子集是訓練集的一個最小子集,能夠保持與原訓練集完全相同的分類決策邊界。
目標:僅保留邊界附近的樣本(相容子集),減少計算量,同時保持模型準確性。
實現:貪心算法。
KNN的距離計算方法
通常采用歐氏距離公式:
d a b = ∑ k = 1 n ( x 1 k ? x 2 k ) 2 \begin{align} d_{ab}=\sqrt{\sum_{k=1}^{n}(x_{1k}-x_{2k})^2} \end{align} dab?=k=1∑n?(x1k??x2k?)2???
如果要考慮量綱影響,可以進行歸一化:
d = ∑ k = 1 n ( x 1 k ? x 2 k s k ) \begin{align} d=\sqrt{\sum_{k=1}^{n}(\frac{x_{1k}-x_{2k}}{s_k})} \end{align} d=k=1∑n?(sk?x1k??x2k??)???
式 ( 15 ) (15) (15)中, s k s_k sk?稱為歸一化因子
采用馬氏距離:
-
某一樣本集的樣本 Xi與Xj,樣本集的協方差矩陣 S, 這兩個多維向量Xi與Xj之間的馬氏距離:
D ( X i , X j ) = ( X i ? X j ) T S ? 1 ( X i ? X j ) \begin{align} D(X_i,X_j)=\sqrt{(X_i-X_j)^TS^{-1}(X_i-X_j)} \end{align} D(Xi?,Xj?)=(Xi??Xj?)TS?1(Xi??Xj?)???
——當S為單位陣,式 ( 16 ) (16) (16)等價于 ( 14 ) (14) (14),為對角陣,式 ( 16 ) (16) (16)等價于 ( 15 ) (15) (15)。

、嵌入(Embeddings)及潛空間(Latent space))







導致服務器面臨 RCE 風險)









