文章目錄
- 1. 表征 (Representations)
- 2. 嵌入 (Embeddings)
- 3. 潛空間 (Latent Space)
- 4. 關系總結
- 5. 學習思考
1. 表征 (Representations)
- 定義: 表征是指數據的一種編碼或描述形式。在機器學習和深度學習中,它特指模型在處理數據時,將原始輸入數據轉換成的某種(通常是數值)形式,以便于模型理解和執行任務。
- 目的: 找到一種能夠捕捉數據關鍵特征、模式或結構的表征,這種表征對于模型完成特定任務(如分類、回歸、生成等)是有用的。
- 廣泛性: 這是一個非常廣泛的概念。
- 輸入本身就是一種表征(例如,圖像的像素值、文本的原始字符序列)。
- 模型每一層的輸出都可以看作是該層對輸入數據的一種新的、通常更抽象的表征。
- 最終的輸出(如分類概率)也是一種表征。
- 好壞: 一個好的表征應該能夠簡化后續任務。例如,對于圖像分類,一個好的表征可能使得不同類別的圖像在表征空間中是線性可分的或易于區分的。神經網絡通過逐層學習,試圖將原始輸入轉換為越來越好的、對任務更有用的表征。
- 例子:
- 圖像的原始像素值。
- 卷積神經網絡(CNN)中某一卷積層的激活圖(activation map),它可能表征了圖像的邊緣、紋理等低級特征。
- 循環神經網絡(RNN)在處理完一個句子后的隱藏狀態(hidden state),它可能表征了該句子的語義概要。
- 詞袋模型(Bag-of-Words)向量是文本的一種稀疏表征。
2. 嵌入 (Embeddings)
- 定義: 嵌入是一種特定類型的表征。它特指將離散的、高維稀疏的類別型變量(如單詞、用戶ID、商品ID、圖節點)映射到一個連續的、低維稠密的向量空間中的過程或結果。這個低維稠密向量就是該類別變量的嵌入向量。
- 目的:
- 降維: 將通常非常高維(如 one-hot 編碼后的詞匯表大小)的稀疏表示轉換為低維表示,提高計算效率和存儲效率。
- 捕捉語義/關系: 嵌入向量是學習得到的,目標是讓相似或相關的離散項在嵌入空間中具有相近的向量表示(例如,通過向量的余弦相似度或歐氏距離來衡量)。這使得模型能夠利用項與項之間的潛在關系。
- 適配神經網絡: 神經網絡更擅長處理連續、稠密的數值輸入。
- 關鍵特征:
- 稠密 (Dense): 向量中的大部分元素都是非零的,與 one-hot 編碼(只有一個 1,其余都是 0)形成對比。
- 低維 (Lower-dimensional): 嵌入向量的維度通常遠小于原始離散空間的基數(例如,詞匯表大小可能有幾萬,但詞嵌入維度通常是幾十到幾百)。
- 學習得到 (Learned): 嵌入向量的值是在模型訓練過程中,根據任務目標(如預測下一個詞、進行分類、推薦等)自動學習和調整的。
- 例子:
- 詞嵌入 (Word Embeddings): 如
Word2Vec,GloVe,FastText,或在神經網絡(如Transformer,RNN)的Embedding層學習到的向量,將每個單詞映射到一個向量,使得語義相近的詞(如 “king” 和 “queen”)在向量空間中距離較近。 - 用戶/物品嵌入 (User/Item Embeddings): 在推薦系統中,將每個用戶和物品映射到一個向量,用于預測用戶對物品的偏好。
- 節點嵌入 (Node Embeddings): 在圖神經網絡中,將圖的每個節點映射到一個向量,捕捉節點的結構和屬性信息。
- 詞嵌入 (Word Embeddings): 如
3. 潛空間 (Latent Space)
- 定義: 潛空間是一個抽象的、多維的向量空間,數據的表征(尤其是嵌入向量或經過壓縮的表征)就“存在”于這個空間中。它通常是低維的,并且其維度(坐標軸)可能不具有直接、明確的物理或現實意義,但這些維度共同捕捉了數據的潛在結構、變異性或核心特征。
- 目的:
- 理解數據結構: 通過將數據點映射到潛空間,可以可視化數據(如果維度降到2或3維),觀察聚類、流形結構、相似性關系等。
- 特征提取/降維: 潛空間通常是通過降維技術(如
PCA、t-SNE)或模型(如自動編碼器Autoencoder的瓶頸層、嵌入層)學習得到的,它代表了數據的壓縮或核心信息。 - 數據生成: 在生成模型(如
VAE,GAN)中,可以從潛空間中采樣一個點(向量),然后通過模型的解碼器將其映射回原始數據空間,從而生成新的、與訓練數據類似的數據。潛空間的結構(如平滑性)對生成質量至關重要。
- 關鍵特征:
- 抽象: 空間的維度不一定對應于可直接解釋的特征。
- 低維 (Often): 相對于原始數據空間,潛空間通常維度較低。
- 結構化 (Ideally): 一個好的潛空間應該是有意義的結構,例如相似的數據點聚集在一起,或者沿著某個方向移動會對應數據某種屬性的平滑變化。
- 例子:
- 詞嵌入向量所在的 N 維空間就是一個潛空間。
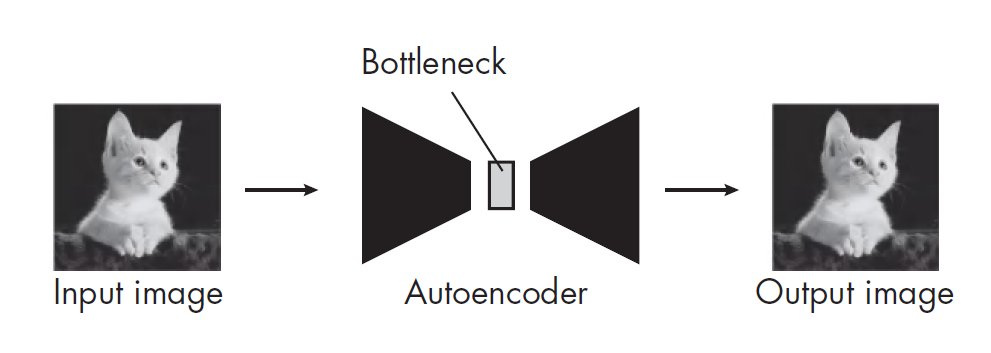
- 自動編碼器(
Autoencoder)的瓶頸層(bottleneck layer)輸出的向量所在的那個低維空間。 - 變分自編碼器(
VAE)中,編碼器輸出的均值和方差定義的那個概率分布所在的參數空間,以及從中采樣得到的z向量所在的那個空間。 PCA降維后,主成分定義的那個低維空間。
自動編碼器可以對輸入圖像進行重建,從而學習這些特征:
4. 關系總結
- 表征 是最廣泛的概念,指數據的任何編碼形式。
- 嵌入 是一種特定類型的表征,用于將離散高維數據映射為連續低維稠密向量,并捕捉其潛在關系。所有嵌入都是表征,但并非所有表征都是嵌入。
- 潛空間 是這些表征(尤其是嵌入或壓縮表征)所處的抽象向量空間。表征向量是潛空間中的點。
5. 學習思考
有哪些不屬于嵌入表征的輸入形式?
以下是一些常見的不屬于典型“嵌入表征”定義的輸入形式(盡管它們也是一種表征):
- 原始像素值 (Raw Pixel Values): 圖像的像素值是連續的(或離散的整數),并且是高維、結構化的,但它們不是通過學習將離散項映射到低維稠密空間得到的。它們是數據的原始、直接表征。
- 直方圖: 直方圖提供了數字圖像中色調分布的圖形表示,捕獲了像素的強度分布。
- One-Hot 編碼向量 (One-Hot Encoded Vectors): 這是將離散類別變量轉換為向量的一種方式,但它是高維、極其稀疏的,并且是固定映射而非學習得到的。它通常是輸入給嵌入層以獲取嵌入向量的原始形式。
- 詞袋模型 (Bag-of-Words, BoW) 向量: 計算文檔中每個詞出現的次數(或頻率)。這也是一種表征,但通常是高維、稀疏的,并且是基于簡單計數規則生成的,而非通過神經網絡端到端學習得到的稠密語義向量。
- TF-IDF 向量: 詞頻-逆文檔頻率向量,是對 BoW 的改進,考慮了詞的重要性。它仍然是高維、稀疏的,并且是基于統計規則計算的。
- 原始數值特征 (Raw Numerical Features): 例如,一個人的年齡、身高、體重,或者傳感器的溫度、濕度讀數。這些已經是連續(或離散)的數值,可以直接(或經過標準化后)輸入模型。它們不是從離散類別映射來的低維稠密向量。
- 時間序列數據 (Raw Time Series Data): 例如,股票價格隨時間的變化、音頻信號的波形。這些是連續的序列數據,是原始輸入,而非學習到的低維稠密嵌入。
關鍵區別在于嵌入通常是從離散/類別型數據出發,通過學習得到的一個低維、稠密、連續的向量表示,目的是捕捉項與項之間的潛在關系或語義。上述例子要么是原始數據,要么是稀疏表示,要么是基于規則生成的,或者本身就是連續數值,不符合嵌入的核心定義。







導致服務器面臨 RCE 風險)











