索引分類
按數據結構分類?
B-Tree索引(B+Tree)
描述??:默認的索引類型,大多數存儲引擎(如InnoDB、MyISAM)支持。實際使用B+Tree結構,數據存儲在葉子節點,葉子節點通過指針連接,支持高效的范圍查詢和排序。
??適用場景??:全值匹配、范圍查詢(如>、<、BETWEEN)、前綴匹配(最左前綴原則)等。
??限制??:無法跳過聯合索引的左前列進行查詢。
??哈希索引
描述??:基于哈希表實現,僅支持精確匹配查詢(如=、IN)。Memory引擎顯式支持,InnoDB通過自適應哈希索引(內部自動管理)優化等值查詢。
??適用場景??:等值查詢,如鍵值對存儲。
??限制??:不支持范圍查詢、排序,哈希沖突可能影響性能。
全文索引
描述??:倒排索引結構,用于文本內容的全文搜索(MATCH AGAINST)。MyISAM和InnoDB(5.6+)支持。
??適用場景??:文本字段的關鍵詞搜索(如文章內容檢索)。
??限制??:需顯式創建,且對中文支持需借助插件(如ngram)。
空間索引(R-Tree)
??描述??:用于地理空間數據(如GEOMETRY、POINT類型),支持空間操作(如ST_Contains)。MyISAM和InnoDB(5.7+)支持。
??適用場景??:地理數據查詢(如“查找某區域內的所有坐標”)。
按存儲方式分類?
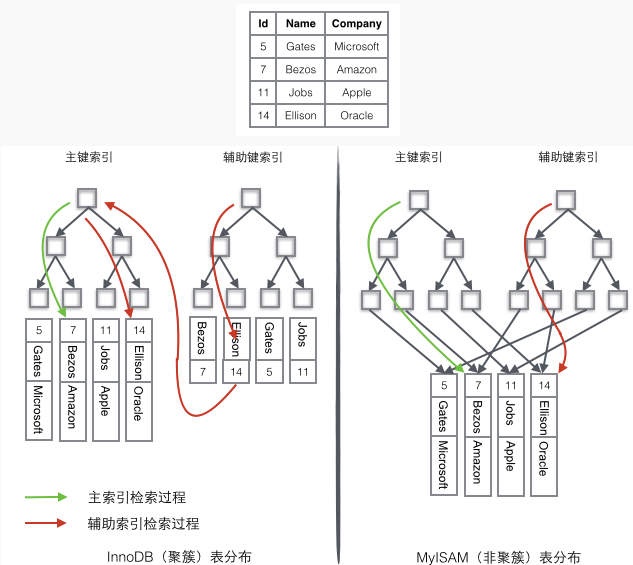
??聚簇索引(Clustered Index)
實現原理??
??數據結構??:
B+Tree,葉子節點存儲完整的數據行(數據頁)。
??存儲方式??:
數據按主鍵順序物理存儲,主鍵索引即數據本身。
默認行為??:
InnoDB中,若未顯式定義主鍵,會自動選擇唯一非空列作為聚簇索引;若無則隱式創建ROWID。
優點??
??高效查詢??:范圍查詢或排序時,因數據物理連續,減少磁盤I/O。
??避免回表??:直接通過索引獲取數據,無需二次查找。
??缺點??
??插入性能依賴主鍵順序??:若主鍵非自增,可能導致頁分裂和碎片化。
??更新代價高??:主鍵變更時,需調整數據物理位置,影響所有二級索引。
適用場景??
頻繁范圍查詢(如BETWEEN、ORDER BY)。
主鍵查詢(如WHERE id = 1)。
??二級索引(Secondary Index,非聚簇索引)
??實現原理??
??數據結構??:B+Tree,葉子節點存儲主鍵值(InnoDB)或數據物理地址(MyISAM)。
??存儲方式??:索引與數據分離,索引僅存儲定位數據的必要信息。
??分類??
??InnoDB二級索引??:
葉子節點存儲主鍵值,查詢時需回表(通過主鍵到聚簇索引獲取數據)。
??覆蓋索引優化??:若查詢字段均在索引中,無需回表(如SELECT a FROM t WHERE b=1,索引為(b, a))。
??MyISAM索引??:
葉子節點存儲數據文件物理地址,直接定位數據。
??優點??
??靈活創建??:支持多列聯合索引,適應復雜查詢條件。
??更新代價低??:數據物理位置變化時,僅MyISAM需更新索引地址,InnoDB二級索引不受影響(因存儲主鍵值)。
????缺點??
??回表開銷??:InnoDB中若未覆蓋索引,需二次查詢聚簇索引,增加I/O。
??范圍查詢效率低??:非連續數據需多次磁盤尋址。
??適用場景??
高頻等值查詢(如WHERE email = ‘user@example.com’)。
覆蓋索引優化查詢(避免回表)。
聚簇索引與非聚簇索引核心區別
| ??特性? | 聚簇索引? | 非聚簇索引? |
|---|---|---|
| ??數據存儲方式?? | 索引的葉子節點直接存儲數據行(數據即索引) | 索引的葉子節點存儲主鍵值或數據行的物理地址 |
| ??索引與數據關系?? | 索引和數據物理上連續存儲 | 索引和數據物理上分離,索引指向數據位置 |
| ??數量限制?? | 每表僅一個聚簇索引 | 每表可創建多個非聚簇索引 |
| ??回表查詢? | 無需回表 | 需通過主鍵回表查詢(InnoDB)或直接訪問數據(MyISAM) |
| ??適用引擎?? | InnoDB | InnoDB的二級索引、MyISAM的所有索引 |
聚簇索引與非聚簇索引不同存儲引擎的對比?
| 引擎? | 索引類型? | ??數據存儲? | 二級索引葉子節點內容? |
|---|---|---|---|
| ?InnoDB | 聚簇索引(主鍵) | 數據按主鍵順序存儲 | 主鍵值(用于回表查詢) |
| 非聚簇索引(二級) | 獨立于數據存儲 | ||
| MyISAM? | 非聚簇索引(所有) | 數據按插入順序存儲,索引與數據分離 | 數據文件物理地址(直接定位數據) |
按邏輯功能分類?
主鍵索引(Primary Key)
??描述??:
唯一標識數據行,不允許NULL值。InnoDB中作為聚簇索引。
??特點??:
一個表僅一個主鍵,通常與AUTO_INCREMENT聯用。
核心規則?:
唯一性??:主鍵列的值必須唯一,不能重復。
??非空約束??:主鍵列不允許 NULL 值。
??數量限制??:每個表只能有一個主鍵(但主鍵可以是多列聯合)。
??存儲引擎差異??:
??InnoDB??:主鍵索引是聚簇索引,數據按主鍵順序存儲。
??MyISAM??:主鍵索引是非聚簇索引,數據按插入順序存儲。
-- 新建表時定義主鍵索引?
-- 基本語法
CREATE TABLE 表名 (列名 數據類型 PRIMARY KEY, -- 單列主鍵...
);
-- 示例:單列主鍵(自增)
CREATE TABLE user (id INT AUTO_INCREMENT PRIMARY KEY, -- 主鍵自增name VARCHAR(50),email VARCHAR(100)
);
-- 示例:聯合主鍵(多列組合)
CREATE TABLE order_item (order_id INT,product_id INT,quantity INT,PRIMARY KEY (order_id, product_id) -- 聯合主鍵
);-- 為已有表添加主鍵索引?
-- 基本語法
ALTER TABLE 表名
ADD PRIMARY KEY (列名); -- 單列主鍵
ALTER TABLE 表名
ADD PRIMARY KEY (列1, 列2); -- 聯合主鍵--主鍵索引的刪除?
-- 刪除主鍵索引(不會刪除列)
ALTER TABLE 表名 DROP PRIMARY KEY;
??唯一索引(Unique Index)
描述??:確保列值唯一,允許單個NULL值。可作用于單列或多列(聯合唯一索引)。
??特點??:用于避免數據重復(如用戶郵箱)。
-- 新建表時定義唯一索引?
-- 單列唯一索引
CREATE TABLE 表名 (列名 數據類型,...UNIQUE [索引名] (列名) -- 索引名可選,默認與列名相同
);
-- 示例:用戶表(郵箱唯一)
CREATE TABLE user (id INT AUTO_INCREMENT PRIMARY KEY,email VARCHAR(100) UNIQUE, -- 直接定義唯一索引name VARCHAR(50)
);
-- 多列聯合唯一索引
CREATE TABLE order_item (order_id INT,product_id INT,quantity INT,UNIQUE idx_order_product (order_id, product_id) -- 自定義索引名
);-- 為已有表添加唯一索引?
-- 基本語法
ALTER TABLE 表名
ADD UNIQUE [索引名] (列名); -- 單列唯一索引
ALTER TABLE 表名
ADD UNIQUE [索引名] (列1, 列2); -- 聯合唯一索引-- 刪除唯一索引?
-- 語法
ALTER TABLE 表名 DROP INDEX 索引名;
??普通索引(Secondary Index)
??描述??:基本的非唯一索引,無數據唯一性約束。
??特點??:僅加速查詢,允許重復值和NULL。
-- 新建表時定義普通索引?
-- 基本語法
CREATE TABLE 表名 (列名 數據類型,...INDEX [索引名] (列名) -- 單列普通索引-- 或INDEX [索引名] (列1, 列2) -- 聯合索引
);-- 為已有表添加普通索引??
-- 語法1:ALTER TABLE
ALTER TABLE 表名
ADD INDEX [索引名] (列名); -- 單列索引
ALTER TABLE 表名
ADD INDEX [索引名] (列1, 列2); -- 聯合索引
-- 語法2:CREATE INDEX(效果與 ALTER TABLE 相同)
CREATE INDEX 索引名 ON 表名 (列名);-- 刪除普通索引?
-- 語法1:ALTER TABLE
ALTER TABLE 表名
DROP INDEX 索引名;
-- 語法2:DROP INDEX(效果相同)
DROP INDEX 索引名 ON 表名;
??全文索引(Full-Text Index)
全文索引概述?
全文索引(Full-Text Index)?? 是一種專為文本字段設計的索引類型,支持自然語言搜索和布爾搜索,能夠快速定位文本中的關鍵詞或短語。與普通索引(B-Tree)不同,全文索引通過分詞技術將文本拆解為單詞或詞組,建立倒排索引結構,適用于模糊查詢和語義匹配。
全文索引概核心特性?
??支持數據類型??:CHAR、VARCHAR、TEXT。
??存儲引擎支持??:
??MyISAM??:全版本支持。
??InnoDB??:MySQL 5.6+ 支持。
??分詞機制??:默認按空格和標點分詞(適用于英文),中文需借助插件(如ngram)。
??搜索模式??:
??自然語言模式(NATURAL LANGUAGE MODE)??:按相關性排序結果。
??布爾模式(BOOLEAN MODE)??:支持邏輯操作符(+, -, *)。
全文索引操作?
創建全文索引?
-- ??建表時定義
CREATE TABLE articles (id INT AUTO_INCREMENT PRIMARY KEY,title VARCHAR(200),content TEXT,FULLTEXT INDEX ft_idx_content (content) -- 單列全文索引-- FULLTEXT INDEX ft_idx_title_content (title, content) -- 多列聯合全文索引
) ENGINE=InnoDB;-- 為已有表添加?
ALTER TABLE articles
ADD FULLTEXT INDEX ft_idx_content (content);
-- 或使用 CREATE INDEX
CREATE FULLTEXT INDEX ft_idx_title_content
ON articles (title, content);
刪除全文索引?
ALTER TABLE articles
DROP INDEX ft_idx_content;
-- 或使用 DROP INDEX
DROP INDEX ft_idx_title_content ON articles;
全文索引查詢語法?
-- 自然語言模式(默認)
SELECT * FROM articles
WHERE MATCH(content) AGAINST('database optimization');
-- 布爾模式(支持操作符)
SELECT * FROM articles
WHERE MATCH(content) AGAINST('+MySQL -Oracle' IN BOOLEAN MODE);
??空間索引(Spatial Index)
空間索引概述?
空間索引(Spatial Index)?? 是專為地理空間數據(如點、線、面)設計的索引類型,支持高效的空間關系查詢(如相交、包含、距離計算)。MySQL 使用 ??R-Tree??(R樹)數據結構實現空間索引,適用于地理信息系統(GIS)、地圖服務等場景。
空間索引核心特性?
??支持數據類型??:
GEOMETRY、POINT、LINESTRING、POLYGON、MULTIPOINT 等。
??存儲引擎支持??:
??MyISAM??:全版本支持。
??InnoDB??:MySQL 5.7.5+ 支持。
??索引結構??:R-Tree(平衡樹結構,優化范圍查詢)。
??空間函數支持??:
ST_Contains(g1, g2):判斷幾何對象是否包含另一個。
ST_Distance(g1, g2):計算兩個幾何對象的最小距離。
ST_Intersects(g1, g2):判斷幾何對象是否相交。
空間索引核心操作?
創建空間索引?
-- 建表時定義??
CREATE TABLE locations (id INT AUTO_INCREMENT PRIMARY KEY,name VARCHAR(100),position POINT NOT NULL SRID 4326, -- 指定坐標系(WGS84)SPATIAL INDEX idx_position (position) -- 創建空間索引
) ENGINE=InnoDB;-- 為已有表添加??
ALTER TABLE locations
ADD SPATIAL INDEX idx_position (position);
-- 或使用 CREATE INDEX
CREATE SPATIAL INDEX idx_position
ON locations (position);
刪除空間索引?
ALTER TABLE locations
DROP INDEX idx_position;
-- 或使用 DROP INDEX
DROP INDEX idx_position ON locations;
空間索引查詢示例?
插入空間數據?
-- 插入一個點(經度 116.4, 緯度 39.9)
INSERT INTO locations (name, position)
VALUES ('Beijing', ST_GeomFromText('POINT(116.4 39.9)', 4326));
查詢示例?
-- 范圍查詢(查找某矩形區域內的點)
SELECT * FROM locations
WHERE ST_Contains(ST_GeomFromText('POLYGON((116.3 39.8, 116.5 39.8, 116.5 40.0, 116.3 40.0, 116.3 39.8))', 4326),position
);-- 距離查詢(查找距離某點 10 公里內的點)
SET @center = ST_GeomFromText('POINT(116.4 39.9)', 4326);
SELECT name,ST_Distance(@center, position) * 111195 AS distance_meters -- 轉換為米(假設為WGS84)
FROM locations
WHERE ST_Distance(@center, position) <= 10 / 111195; -- 10公里
按應用場景分類?
??聯合索引(Composite Index)??
聯合索引定義
聯合索引(Composite Index)?? 是將多個列組合在一起創建的索引。例如,在用戶表中,若經常需要根據城市和年齡進行查詢,可以創建一個聯合索引(城市, 年齡)。與單列索引不同,聯合索引的鍵值是多個列值的組合,并按順序存儲在索引結構中(如B+樹)。
聯合索引核心原理
??存儲結構??:
聯合索引的鍵值由多個列的值按順序拼接而成。例如,索引(A, B)的鍵值為(A1, B1)、(A1, B2)、(A2, B1)等。
在B+樹中,鍵值按字典序排序:先按第一個列排序,第一個列相同再按第二個列排序,依此類推。
??最左前綴原則(Leftmost Prefix Rule)??:
查詢條件必須包含聯合索引的最左側列,才能有效使用索引。
??有效場景??:
WHERE A = 1
WHERE A = 1 AND B = 2
WHERE A = 1 AND B = 2 AND C = 3
??無效場景??:
WHERE B = 2(缺少最左列A)
WHERE B = 2 AND C = 3
聯合索引的設計策略?
??高頻查詢優先??:
將最常用的查詢條件列放在索引左側。
??示例??:若查詢多為WHERE city = ‘X’ AND age > Y,則索引應為(city, age)而非(age, city)。
??選擇性高的列在前??:
高選擇性(唯一值多)的列應放在左側,能更快縮小查詢范圍。
??示例??:性別(低選擇性)和城市(高選擇性)中,優先將城市放在左側。
??避免冗余索引??:
若已存在索引(A, B),則索引(A)是冗余的,可刪除。
??控制索引數量??:
每個索引會增加插入、更新、刪除的開銷,需權衡讀寫性能。
聯合索引的局限性?
無法跳過最左列??:
若無最左列的查詢條件,索引無法生效。
??優化方案??:單獨為右側列創建索引。
??索引大小增加??:
聯合索引的存儲空間隨列數和列類型增長,尤其是文本類型列。
??寫入性能影響??:
維護索引需要額外的I/O和計算資源,影響寫入速度。
????覆蓋索引(Covering Index)??
覆蓋索引定義
覆蓋索引(Covering Index)?? 是指某個索引包含了查詢所需的所有字段,使得數據庫無需訪問數據行(無需回表)即可完成查詢。覆蓋索引的本質是??利用索引結構本身存儲查詢所需的字段值??,從而顯著減少磁盤 I/O 和 CPU 計算開銷。
覆蓋索引的核心原理?
索引結構存儲數據??:
在 B+Tree 索引中,葉子節點存儲索引列的值。若查詢的字段全部在索引中,直接讀取索引即可返回結果。
??示例(查詢字段 city 和 age 均包含在索引 idx_city_age 中,無需回表查詢數據行)??:
-- 表結構:id(主鍵),name,age,city
-- 索引:idx_city_age (city, age)
SELECT city, age FROM users WHERE city = 'Beijing';
避免回表(Key Lookup)??:
??回表??:普通索引的葉子節點存儲主鍵值,需通過主鍵回表查詢數據行。
??覆蓋索引??:直接返回索引中的字段值,跳過回表步驟。
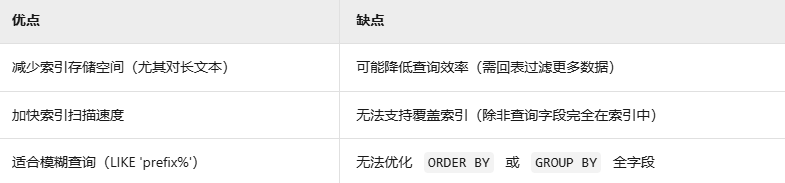
????前綴索引(Prefix Index)??
前綴索引的定義?
?前綴索引(Prefix Index)?? 是一種針對文本類型列(如 CHAR、VARCHAR、TEXT)的優化索引方法,通過僅對列值的前 ??N 個字符?? 建立索引,減少索引存儲空間,同時平衡查詢效率。
??核心思想??:用部分字符代替完整內容作為索引鍵值,犧牲一定區分度以換取更小的索引體積。
前綴索引的適用場景
?超長文本字段??:
例如 VARCHAR(255) 的郵箱地址、URL 等。
??前綴區分度高??:
字段的前幾個字符已足夠區分不同數據(如訂單號前綴)。
??存儲空間敏感??:
需減少索引占用空間(尤其對大數據表)。
如何創建前綴索引?
-- 對單列的前 N 個字符創建索引
CREATE INDEX 索引名 ON 表名 (列名(N));-- 示例:對 name 列的前 10 個字符創建索引
CREATE INDEX idx_name_prefix ON users (name(10));-- 聯合索引中可指定不同列的前綴長度
CREATE INDEX idx_name_email ON users (name(5), email(20));
前綴長度的選擇?
選擇合適的前綴長度是核心優化點,需滿足 ??高選擇性??(不同值占比高)且 ??長度最小化??
計算選擇性?
-- 計算不同前綴長度的選擇性
SELECT COUNT(DISTINCT LEFT(列名, 10)) / COUNT(*) AS sel10,COUNT(DISTINCT LEFT(列名, 20)) / COUNT(*) AS sel20,COUNT(DISTINCT LEFT(列名, 30)) / COUNT(*) AS sel30
FROM 表名;
結果解讀??
sel10=0.85:前 10 字符能區分 85% 的數據。
若 sel20=0.86,則長度 10 到 20 的提升不大,選擇 10 即可。
經驗法則?
確保前綴長度的選擇性接近完整列的選擇性。
例如:若完整列選擇性為 95%,則前綴長度應使選擇性 ≥ 90%。
前綴索引的優缺點?
其他索引類型?
????自適應哈希索引(Adaptive Hash Index)??
InnoDB自動為頻繁訪問的索引頁創建哈希索引,加速等值查詢,無需用戶干預。
??????降序索引(Descending Index)??
MySQL 8.0+支持,針對ORDER BY column DESC優化,提升排序性能。
是否對字段建立索引
適合建立索引的字段
- 高頻查詢條件(WHERE 子句中的字段)?
- 主鍵(Primary Key)?(主鍵默認創建聚簇索引(InnoDB)或唯一索引(MyISAM))
- 外鍵(Foreign Key)?(外鍵字段常用于表連接(JOIN),索引可加速連接性能)
- 排序和分組字段(ORDER BY / GROUP BY)?(頻繁用于排序或分組的列)
- 高選擇性字段(區分度高的列)?
列中不同值的比例高(接近唯一):身份證號(唯一)比性別(只有2-3種值)更適合索引 - 聯合查詢字段(聯合索引)?
- 覆蓋索引(Covering Index)?
不適合建立索引的字段?
- 低選擇性字段?
??示例??:
性別(只有 “男/女”)、布爾狀態(0/1)。
索引可能比全表掃描更慢(優化器可能忽略索引)。 - 頻繁更新的字段?
??代價??:索引維護成本高,影響寫入性能。
??示例??:
實時更新的計數器字段(如 view_count)。 - 大文本或二進制字段(TEXT/BLOB)
問題??:索引體積大,效率低。
??替代方案??:
使用前綴索引(VARCHAR(255) 前20字符)。
計算哈希值并索引哈希列。 - 小表的字段?
規則??:數據量小的表(如配置表)無需索引。
??原因??:全表掃描可能更快。
索引失效的場景
違反最左前綴原則(聯合索引)?
?場景??:
聯合索引 (A, B, C),但查詢條件中未包含最左列 A。
??示例??:
SELECT * FROM table WHERE B = 2; -- 無法使用索引
SELECT * FROM table WHERE B = 2 AND C = 3; -- 無法使用索引
??原因??:B+Tree 索引按 A → B → C 順序構建,缺失最左列無法定位索引范圍。
??優化方案??:
查詢條件需包含最左列。
單獨為 B 或 C 建立索引。
對索引列進行運算或函數操作?
場景??:對索引字段進行運算或函數處理后作為查詢條件。
??示例??:
SELECT * FROM users WHERE YEAR(create_time) = 2023; -- 索引失效
SELECT * FROM users WHERE id + 1 = 100; -- 索引失效
??原因??:運算后的值無法匹配索引中存儲的原始值。
??優化方案??:
– 避免函數,改為范圍查詢
SELECT * FROM users
WHERE create_time BETWEEN '2023-01-01' AND '2023-12-31';-- 直接使用原始值計算
SELECT * FROM users WHERE id = 100 - 1;
使用模糊查詢 LIKE 以通配符開頭?
場景??:LIKE 查詢以 % 開頭。
??示例??:
SELECT * FROM users WHERE name LIKE '%Alice%'; -- 無法使用索引
SELECT * FROM users WHERE name LIKE 'Alice%'; -- 可使用索引
??原因??:前綴模糊匹配破壞了索引值的順序結構。
??優化方案??:
盡可能使用右側模糊(如 ‘Alice%’)。
使用全文索引(FULLTEXT)替代 LIKE。
隱式類型轉換?(字段類型不同)
場景??:字段類型與查詢值類型不一致。
??示例??:
– 假設 phone 字段為 VARCHAR,但查詢時使用數字
SELECT * FROM users WHERE phone = 13812345678; -- 索引失效
??原因??:數據庫需將字段隱式轉換為數值類型,導致無法匹配索引。
??優化方案??:嚴格匹配字段類型:
SELECT * FROM users WHERE phone = '13812345678';
使用 OR 連接非索引字段?
場景??:OR 連接的多個條件中存在未索引字段。
??示例??:
-- name 有索引,age 無索引
SELECT * FROM users WHERE name = 'Alice' OR age = 25; -- 全表掃描
原因??:優化器無法通過單一的索引覆蓋所有條件。
??優化方案??:
為 age 字段添加索引。
拆分成兩個查詢后用 UNION 合并。
聯合索引范圍查詢后的列失效?
場景??:聯合索引 (A, B, C),查詢條件中存在 A 的范圍查詢,后續條件無法使用索引。
??示例??
SELECT * FROM table
WHERE A > 100 AND B = 2; -- B 無法使用索引過濾
原因??:B+Tree 的索引結構在范圍查詢后,后續字段無序,無法快速定位。
??優化方案??:
調整索引順序:將等值查詢的字段放在范圍字段前。
單獨為 B 建立索引。
數據區分度過低(低選擇性)?
場景??:字段值重復率過高(如性別、狀態碼)。
??示例??:
-- gender 字段僅有 'M'/'F' 兩個值
SELECT * FROM users WHERE gender = 'M'; -- 索引可能被優化器忽略
??原因??:索引掃描可能比全表掃描更慢(需回表多次)。
??優化方案??:
避免為此類字段單獨建索引。
與其他高選擇性字段組成聯合索引。
使用 != 或 NOT IN?或NOT EXISTS
場景??:查詢條件中包含否定操作符。
??示例??:
SELECT * FROM users WHERE status != 1; -- 索引失效
SELECT * FROM users WHERE id NOT IN (1, 2, 3); -- 索引失效
??原因??:否定操作符需要掃描大部分數據,優化器傾向于全表掃描。
??優化方案??:重寫查詢邏輯或限制查詢范圍。
列比對、表達式比對
當查詢條件中對兩列進行直接比較(如 col1 = col2、col1 > col2、col1 + col2 > 100)時,??優化器無法直接利用單列索引??,通常會導致全表掃描或低效的索引使用。其根本原因是索引結構的設計針對單列值的存儲和查找,而非列之間的動態關系。
排查索引是否失效的工具?
使用 EXPLAIN 分析查詢執行計劃:
EXPLAIN SELECT * FROM users WHERE name = 'Alice';
關鍵字段解讀:
??type??:
ref:使用索引查詢。
index:全索引掃描(需檢查是否覆蓋索引)。
ALL:全表掃描(可能索引失效)。
??key??:實際使用的索引。
??Extra??:
Using index:覆蓋索引有效。
Using filesort:未使用索引排序。





-- P2P文件分發視頻流和內容分發網)



:概率論)

![vue+django農產品價格預測和推薦可視化系統[帶知識圖譜]](http://pic.xiahunao.cn/vue+django農產品價格預測和推薦可視化系統[帶知識圖譜])

從原理到實戰)


)


