MessageQueue --- RabbitMQ WorkQueue and Prefetch
- 什么是WorkQueue
- 分發機制 --- RoundRobin
- 分發機制 --- Prefetch
- Spring example use prefetch --- Fair Dispatch
什么是WorkQueue
- Work queues,任務模型。簡單來說就是讓多個消費者綁定到一個隊列,共同消費隊列中的消息。
- 當消息處理比較耗時的時候,可能生產消息的速度會遠遠大于消息的消費速度。長此以往,消息就會堆積越來越多,無法及時處理。此時就可以使用workqueu模型,多個消費者共同處理消息處理,消息處理的速度就能大大提高了。

分發機制 — RoundRobin
工作機制:
- 默認模式:當多個消費者訂閱同一個隊列時,RabbitMQ 會依次將消息分發給每個消費者,按順序循環分配。
- 示例:
隊列中有消息 M1, M2, M3, M4,消費者 C1 和 C2 同時訂閱。
分發順序為:M1 → C1,M2 → C2,M3 → C1,M4 → C2。
特點:
- 簡單高效:無需額外配置,適合消費者處理速度相近的場景。
潛在問題:
- 若消費者處理速度差異較大,可能導致某些消費者空閑,而其他消費者積壓消息。
- 例如:C1 處理速度慢,C2 處理速度快,但 C1 仍會分配到一半的消息,造成負載不均衡。
Example
//消息發送
//循環發送,模擬大量消息堆積現象。
@Test
public void testWorkQueue() throws InterruptedException {// 隊列名稱String queueName = "simple.queue";// 消息String message = "hello, message_";for (int i = 0; i < 50; i++) {// 發送消息,每20毫秒發送一次,相當于每秒發送50條消息rabbitTemplate.convertAndSend(queueName, message + i);Thread.sleep(20);}
}
//消息接收
//模擬多個消費者綁定同一個隊列,我們添加2個方法,
//并且設置不同睡眠時間模擬不同性能讀取
@RabbitListener(queues = "work.queue")
public void listenWorkQueue1(String msg) throws InterruptedException {System.out.println("消費者1接收到消息:【" + msg + "】" + LocalTime.now());Thread.sleep(20);
}
@RabbitListener(queues = "work.queue")
public void listenWorkQueue2(String msg) throws InterruptedException {System.err.println("消費者2........接收到消息:【" + msg + "】" + LocalTime.now());Thread.sleep(200);
}
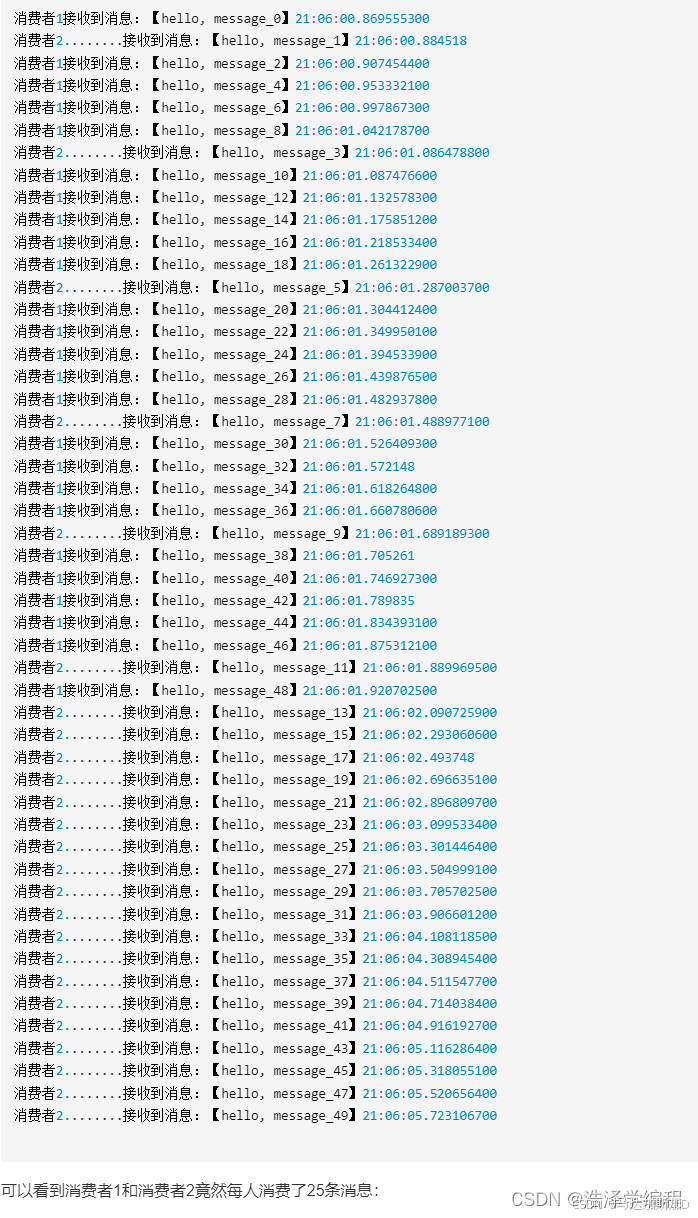
- 消費者1很快完成了自己的25條消息
- 消費者2卻在緩慢的處理自己的25條消息。
- 也就是說消息是平均分配給每個消費者,并沒有考慮到消費者的處理能力。導致1個消費者空閑,另一個消費者忙的不可開交。沒有充分利用每一個消費者的能力,最終消息處理的耗時遠遠超過了1秒。這樣顯然是有問題的。
下面我們介紹prefetch機制,可以做到fair dispatch
分發機制 — Prefetch
工作機制:
- 配置預取計數(Prefetch Count):通過設置 basicQos 參數,限制每個消費者未確認(unacknowledged)的消息數量。
- 進入prefetch的消息仍會被保留在隊列中,但是同時也會發給消費者等待處理
在 RabbitMQ 的原始隊列(Queue)中,會被標記為 “Unacked”(未確認)狀態。
這些消息不會被其他消費者獲取(即使設置了 prefetch 的消費者崩潰)。
只有消費者顯式發送 ack 或 nack 后,消息才會從隊列中移除(或重新排隊)。
消息狀態變化流程
- 消息推送給消費者:
RabbitMQ 將消息標記為 “Unacked”,但仍在隊列中(占用內存或磁盤,取決于隊列持久化配置)。
此時消息對其他消費者不可見。- 消費者處理消息:
若成功處理并發送 ack → 消息從隊列中物理刪除。
若發送 nack(requeue=true) → 消息重新變為 “Ready” 狀態,可被其他消費者獲取。
若發送 nack(requeue=false) 或者超時→ 消息被放入死信隊列,如果沒有配置死信隊列則被丟棄
示例:
Channel channel = ...;
Consumer consumer = ...;
channel.basicQos(10); // Per consumer limit
channel.basicConsume("my-queue", false, consumer);
Channel channel = ...;
Consumer consumer = ...;
channel.basicQos(0); // No limit for this consumer,allowing any number of unacknowledged messages.
channel.basicConsume("my-queue", false, consumer);
Channel channel = ...;
Consumer consumer1 = ...;
Consumer consumer2 = ...;
channel.basicQos(10); // Per consumer limit
channel.basicConsume("my-queue1", false, consumer1);
channel.basicConsume("my-queue2", false, consumer2);
Channel channel = ...;
Consumer consumer1 = ...;
Consumer consumer2 = ...;
channel.basicQos(10, false); // Per consumer limit
channel.basicQos(15, true); // Per channel limit
channel.basicConsume("my-queue1", false, consumer1);
channel.basicConsume("my-queue2", false, consumer2);
//這兩個消費者之間總共最多只能有 15 條未確認消息,且每個消費者最多處理 10 條消息。
//由于需要在 Channel 和隊列之間協調全局限制,該模式的性能會低于前述示例(存在額外開銷)
特點:
- 負載均衡:處理速度快的消費者會獲取更多消息,避免空閑
- 可以一次性發送多個消息給消費者處理,減少網絡開銷
- 可靠性:需配合手動確認(ack)機制,確保消息處理成功后才從隊列移除。
- 適用場景:消費者處理速度差異較大時(如耗時任務),能顯著提升整體吞吐量。
Automatic acknowledgement mode or manual acknowledgement mode with unlimited prefetch should be used with care. 通常設為 100~300,平衡吞吐與內存占用。
Note:
- AMQP 0-9-1 協議是
channel level prefetch,通過 basic.qos 方法限制channel上的未確認消息數- channel level有很大缺陷,由于單個channel可能從多個queue消費消息,channel與queue之間需要為每條消息進行協調,以確保不超出限制。這種機制在單機環境下效率較低,而在集群消費場景中性能會顯著下降,大多數使用場景也需要consumer level prefetch
- 所以RabbitMQ支持
consumer level prefetch(也就是以上的例子)

Spring example use prefetch — Fair Dispatch
- 在spring中有一個prefetch的配置,我們修改consumer服務的application.yml文件,添加配置:
spring:rabbitmq:listener:simple:acknowledge-mode: manual # 設置確認方式為手動確認prefetch: 1 # 每次只能獲取一條消息,處理完成才能獲取下一個消息

- 可以發現,由于消費者1處理速度較快,所以處理了更多的消息;消費者2處理速度較慢,只處理了6條消息。而最終總的執行耗時也在1秒左右,大大提升
- 還可根據實際情況自定義prefetch count,達到限流的目的
spring:rabbitmq:listener:simple:acknowledge-mode: manual # 設置確認方式為手動確認prefetch: 5 # 限制消費者只能接收5條消息
Self-Attention(自注意力機制))




MySQL主從同步原理深度剖析)

![[MySQL初階]MySQL(9)事務機制](http://pic.xiahunao.cn/[MySQL初階]MySQL(9)事務機制)



)
)

:ADC LTC系列模數轉換器的輸出范圍+滿量程和偏移調整)


)

)