代碼來源
Learning Transferable Visual Models From Natural Language Supervision![]() https://arxiv.org/pdf/2103.00020
https://arxiv.org/pdf/2103.00020
模塊作用
當前最先進的計算機視覺系統被訓練用于預測一組固定的、預先定義的目標類別。這種受限的監督方式限制了它們的通用性和可用性,因為要識別其他視覺概念時,仍然需要額外的標注數據。直接從關于圖像的原始文本中學習是一種更具潛力的替代方案,它可以利用更廣泛的監督信息。
模塊結構
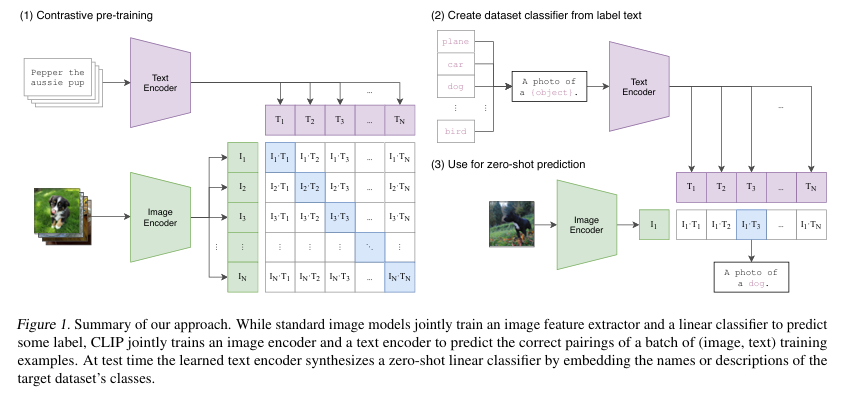
- 圖像編碼器:
- 支持多種架構,包括ResNet(如ResNet-50、ResNet-101、RN50x4、RN50x16、RN50x64)和Vision Transformer(ViT,如ViT-B/32、ViT-B/16、ViT-L/14)。
- ResNet版本包括ResNet-D改進、抗混疊rect-2模糊池化和注意力池化(多頭QKV注意力)。
- ViT版本在Transformer前增加層歸一化,訓練模型包括ViT-B/32、ViT-B/16和ViT-L/14,其中ViT-L/14@336px(在336像素分辨率下預訓練額外一輪)表現最佳。
- 文本編碼器:
- 使用63M參數的12層Transformer,寬度512,8個注意力頭,處理小寫字節對編碼(BPE),詞匯表大小49,152,最大序列長度76,用[SOS]和[EOS]標記括住,使用屏蔽自注意力。
代碼
class CLIP(nn.Module):def __init__(self,embed_dim: int,# visionimage_resolution: int,vision_layers: Union[Tuple[int, int, int, int], int],vision_width: int,vision_patch_size: int,# textcontext_length: int,vocab_size: int,transformer_width: int,transformer_heads: int,transformer_layers: int):super().__init__()self.context_length = context_lengthif isinstance(vision_layers, (tuple, list)):vision_heads = vision_width * 32 // 64self.visual = ModifiedResNet(layers=vision_layers,output_dim=embed_dim,heads=vision_heads,input_resolution=image_resolution,width=vision_width)else:vision_heads = vision_width // 64self.visual = VisionTransformer(input_resolution=image_resolution,patch_size=vision_patch_size,width=vision_width,layers=vision_layers,heads=vision_heads,output_dim=embed_dim)self.transformer = Transformer(width=transformer_width,layers=transformer_layers,heads=transformer_heads,attn_mask=self.build_attention_mask())self.vocab_size = vocab_sizeself.token_embedding = nn.Embedding(vocab_size, transformer_width)self.positional_embedding = nn.Parameter(torch.empty(self.context_length, transformer_width))self.ln_final = LayerNorm(transformer_width)self.text_projection = nn.Parameter(torch.empty(transformer_width, embed_dim))self.logit_scale = nn.Parameter(torch.ones([]) * np.log(1 / 0.07))self.initialize_parameters()def initialize_parameters(self):nn.init.normal_(self.token_embedding.weight, std=0.02)nn.init.normal_(self.positional_embedding, std=0.01)if isinstance(self.visual, ModifiedResNet):if self.visual.attnpool is not None:std = self.visual.attnpool.c_proj.in_features ** -0.5nn.init.normal_(self.visual.attnpool.q_proj.weight, std=std)nn.init.normal_(self.visual.attnpool.k_proj.weight, std=std)nn.init.normal_(self.visual.attnpool.v_proj.weight, std=std)nn.init.normal_(self.visual.attnpool.c_proj.weight, std=std)for resnet_block in [self.visual.layer1, self.visual.layer2, self.visual.layer3, self.visual.layer4]:for name, param in resnet_block.named_parameters():if name.endswith("bn3.weight"):nn.init.zeros_(param)proj_std = (self.transformer.width ** -0.5) * ((2 * self.transformer.layers) ** -0.5)attn_std = self.transformer.width ** -0.5fc_std = (2 * self.transformer.width) ** -0.5for block in self.transformer.resblocks:nn.init.normal_(block.attn.in_proj_weight, std=attn_std)nn.init.normal_(block.attn.out_proj.weight, std=proj_std)nn.init.normal_(block.mlp.c_fc.weight, std=fc_std)nn.init.normal_(block.mlp.c_proj.weight, std=proj_std)if self.text_projection is not None:nn.init.normal_(self.text_projection, std=self.transformer.width ** -0.5)def build_attention_mask(self):# lazily create causal attention mask, with full attention between the vision tokens# pytorch uses additive attention mask; fill with -infmask = torch.empty(self.context_length, self.context_length)mask.fill_(float("-inf"))mask.triu_(1) # zero out the lower diagonalreturn mask@propertydef dtype(self):return self.visual.conv1.weight.dtypedef encode_image(self, image):return self.visual(image.type(self.dtype))def encode_text(self, text):x = self.token_embedding(text).type(self.dtype) # [batch_size, n_ctx, d_model]x = x + self.positional_embedding.type(self.dtype)x = x.permute(1, 0, 2) # NLD -> LNDx = self.transformer(x)x = x.permute(1, 0, 2) # LND -> NLDx = self.ln_final(x).type(self.dtype)# x.shape = [batch_size, n_ctx, transformer.width]# take features from the eot embedding (eot_token is the highest number in each sequence)x = x[torch.arange(x.shape[0]), text.argmax(dim=-1)] @ self.text_projectionreturn xdef forward(self, image, text):image_features = self.encode_image(image)text_features = self.encode_text(text)# normalized featuresimage_features = image_features / image_features.norm(dim=1, keepdim=True)text_features = text_features / text_features.norm(dim=1, keepdim=True)# cosine similarity as logitslogit_scale = self.logit_scale.exp()logits_per_image = logit_scale * image_features @ text_features.t()logits_per_text = logits_per_image.t()# shape = [global_batch_size, global_batch_size]return logits_per_image, logits_per_text總結
本文研究了在自然語言處理(NLP)領域取得成功的、與具體任務無關的大規模網絡預訓練方法,是否可以遷移到另一個領域。研究表明,采用這一方法后,在計算機視覺領域會出現類似的行為,我們也探討了這一研究方向的社會影響。為了優化訓練目標,CLIP 模型在預訓練過程中學習執行多種不同的任務。這種任務學習可以通過自然語言提示(prompting)加以利用,從而實現對許多現有數據集的零樣本(zero-shot)遷移。在足夠大的規模下,這種方法的性能可以與特定任務的監督學習模型相競爭,盡管仍有很大的改進空間。
![[MySQL初階]MySQL(9)事務機制](http://pic.xiahunao.cn/[MySQL初階]MySQL(9)事務機制)



)
)

:ADC LTC系列模數轉換器的輸出范圍+滿量程和偏移調整)


)

)






