聲明:
? ? ? ?本文基于嗶站博主【Shusenwang】的視頻課程【RNN模型及NLP應用】,結合自身的理解所作,旨在幫助大家了解學習NLP自然語言處理基礎知識。配合著視頻課程學習效果更佳。
材料來源:【Shusenwang】的視頻課程【RNN模型及NLP應用】
視頻鏈接:RNN模型與NLP應用(9/9):Self-Attention (自注意力機制)_嗶哩嗶哩_bilibili
一、學習目標
1.簡單了解什么是自注意力機制
2.理解自注意力機制的底層邏輯
二、Self-Attention——自注意力機制
? ? ? ?我們上節課學習到使用Attention改進Sequence to Sequence模型,Sequence to Sequence模型有兩個RNN神經網絡(一個Encoder,一個Decoder)。我們今天要學習的是將Attention運用到一個RNN網絡 上。
前言:
原論文講的是將Attention與還能用在一個LSTM上,為了簡單方便大家理解,本博客將Attention用在Simple RNN上。

Simple RNN與Attention的結合:
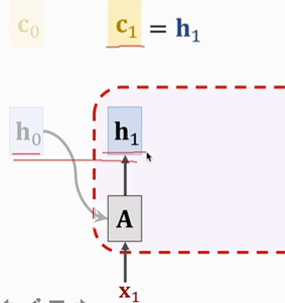
1.初始狀態下,h0和C0都是全零向量。
標準的SimpleRNN是這樣更新h狀態向量的:

Self-Attention+Simple RNN是這樣的更新h狀態向量的:

? ? ? ?有了新的狀態向量h后,我們就該計算新的C1(contect vector),?新的C1是已有狀態向量的加權平均。
因為初始狀態的h0是全零向量,因此第一個C1=h1
接下來我們更新狀態向量h:
然后要計算下一個C,計算下一個C之前我們首先需要計算權重α。α公式如下:
h2將會拿h1做對比,拿h2自己做對比,計算出兩個權重α1和α2。C2就是h1和h2的加權平均
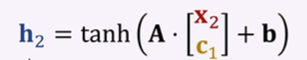


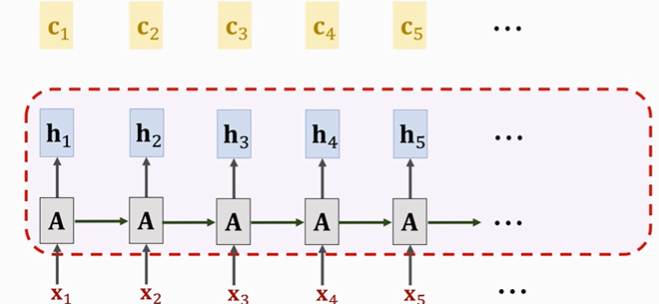
按照此過程不斷循環計算,計算出新的狀態h和C
三、總結
1.self-attention就能解決遺忘的問題
? ? ? ? RNN都有遺忘的問題,比如分析電影評論是正面的還是負面的,如果評論太長,最后一個狀態就記不住整句話,不能有效利用整句話的信息。
self-attention每一輪更新狀態之前,都會用C看一遍之前所有狀態,這樣就不會遺忘之前的信息了
? ? ? ?self-attention和Attention的道理是一樣的但是self-attention不局限于Sequence to Sequence模型,他可以作用于任何RNN模型
2.除了避免遺忘,Self-Attention還可以幫助RNN關注相關的信息
如下圖所示:

紅色部分是輸入信息,而高亮標出的是權重很大的位置,這些α說明前面最相關的是哪一個。




MySQL主從同步原理深度剖析)

![[MySQL初階]MySQL(9)事務機制](http://pic.xiahunao.cn/[MySQL初階]MySQL(9)事務機制)



)
)

:ADC LTC系列模數轉換器的輸出范圍+滿量程和偏移調整)


)

)
