大家好,Crawl4AI作為開源Python庫,專門用來簡化網頁爬取和數據提取的工作。它不僅功能強大、靈活,而且全異步的設計讓處理速度更快,穩定性更好。無論是構建AI項目還是提升語言模型的性能,Crawl4AI都能幫您簡化工作流程。它可以直接在Python項目中使用,或者將其集成到REST API中,實現快速、穩定的數據爬取和處理。這樣,無論是數據的實時獲取還是后續的分析處理,都能更加得心應手。
1.快速使用
以下是個簡單的例子,展示了Crawl4AI強大的異步能力:
import?asyncio
from?crawl4ai?import?AsyncWebCrawlerasyncdef?main():# 初始化異步網頁爬蟲asyncwith?AsyncWebCrawler(verbose=True)?as?crawler:# 爬取指定的 URLresult =?await?crawler.arun(url="https://www.nbcnews.com/business")# 以 Markdown 格式顯示提取的內容print(result.markdown)# 執行異步主函數
if?__name__ ==?"__main__":asyncio.run(main())
解釋:
-
導入庫:從
crawl4ai庫中導入AsyncWebCrawler和asyncio模塊。 -
創建異步上下文:使用異步上下文管理器實例化
AsyncWebCrawler。 -
運行爬蟲:使用
arun()?法異步爬取指定的 URL 并提取有意義的內容。 -
打印結果:輸出提取的內容,格式化為 Markdown。
-
執行異步函數:使用
asyncio.run()執行異步的main函數。
2.特性亮點
Crawl4AI具備以下核心特性,讓網頁爬取和數據提取工作更加高效:
-
開源免費:無額外費用,開源可信賴。
-
快速性能:速度超越許多付費工具。
-
多樣輸出:支持JSON、清潔HTML、Markdown格式。
-
多URL并發:一次性處理多個網頁,提升效率。
-
媒體提取:全面抓取圖片、音頻、視頻等。
-
鏈接全收集:不遺漏任何內外鏈接。
-
元數據抽取:深入提取網頁信息。
-
自定義操作:自定義請求頭、認證,修改頁面后再爬取。
-
用戶代理模擬:模擬不同設備訪問。
-
頁面截圖:快速獲取網頁視覺快照。
-
JavaScript支持:執行JS獲取動態內容。
-
數據結構化:精確提取結構化數據。
-
智能提取技術:使用余弦聚類和LLM技術。
-
CSS選擇器:精準定位數據。
-
指令優化:通過指令提升提取效果。
-
代理配置:增強訪問權限和隱私保護。
-
會話管理:輕松處理多頁爬取。
-
異步架構:提升性能和可擴展性。
3.安裝指南
Crawl4AI提供了多種安裝方式,以適應不同的使用場景。以下是幾種常用的安裝方法:
3.1 基本安裝(推薦)
對于大多數網頁爬取和數據抓取任務,可以直接使用pip進行安裝:
pip install crawl4ai
這樣,默認安裝的是Crawl4AI的異步版本,使用Playwright進行網頁爬取。
如果安裝時遇到Playwright相關錯誤,可以通過以下命令手動安裝Playwright:
playwright install
或者,安裝特定版本的Chromium:
python -m playwright install chromium
3.2 同步版本安裝
如果需要使用Selenium的同步版本,可以使用以下命令:
pip install crawl4ai[sync]
3.3 開發者安裝
對于想要參與項目開發,修改源代碼的貢獻者,可以通過以下步驟進行安裝:
git clone https://github.com/unclecode/crawl4ai.git
cd crawl4ai
pip install -e .
4.高級應用
要想充分發揮Crawl4AI的能力,可以看看這些高級功能和應用案例:
4.1 執行JavaScript和使用CSS選擇器
可以利用Crawl4AI執行自定義JavaScript代碼,以及通過CSS選擇器精準定位頁面元素,從而提升爬取任務的效率和精確度。這讓你能夠更靈活地處理復雜的網頁數據抓取需求。
import?asyncio
from?crawl4ai?import?AsyncWebCrawlerasyncdef?main():asyncwith?AsyncWebCrawler(verbose=True)?as?crawler:js_code = ["const loadMoreButton = Array.from(document.querySelectorAll('button')).find(button => button.textContent.includes('Load More')); loadMoreButton && loadMoreButton.click();"]result =?await?crawler.arun(url="https://www.nbcnews.com/business",js_code=js_code,css_selector="article.tease-card",bypass_cache=True)print(result.extracted_content)if?__name__ ==?"__main__":asyncio.run(main())
4.2 使用代理
通過將爬取任務路由到代理,增強隱私和訪問權限。
import?asyncio
from?crawl4ai?import?AsyncWebCrawlerasync?def?main():async?with?AsyncWebCrawler(verbose=True, proxy="http://127.0.0.1:7890")?as?crawler:result =?await?crawler.arun(url="https://www.nbcnews.com/business",bypass_cache=True)print(result.markdown)if?__name__ ==?"__main__":asyncio.run(main())
4.3 不使用 LLM 提取結構化數據
使用JsonCssExtractionStrategy精確提取使用 CSS 選擇器的結構化數據。
import?asyncio
import?json
from?crawl4ai?import?AsyncWebCrawler
from?crawl4ai.extraction_strategy?import?JsonCssExtractionStrategyasyncdef?extract_news_teasers():schema = {"name":?"News Teaser Extractor","baseSelector":?".wide-tease-item__wrapper","fields": [{"name":?"category",?"selector":?".unibrow span[data-testid='unibrow-text']",?"type":?"text"},{"name":?"headline",?"selector":?".wide-tease-item__headline",?"type":?"text"},{"name":?"summary",?"selector":?".wide-tease-item__description",?"type":?"text"},{"name":?"time",?"selector":?"[data-testid='wide-tease-date']",?"type":?"text"},{"name":?"image","type":?"nested","selector":?"picture.teasePicture img","fields": [{"name":?"src",?"type":?"attribute",?"attribute":?"src"},{"name":?"alt",?"type":?"attribute",?"attribute":?"alt"},],},{"name":?"link",?"selector":?"a[href]",?"type":?"attribute",?"attribute":?"href"},],}extraction_strategy = JsonCssExtractionStrategy(schema, verbose=True)asyncwith?AsyncWebCrawler(verbose=True)?as?crawler:result =?await?crawler.arun(url="https://www.nbcnews.com/business",extraction_strategy=extraction_strategy,bypass_cache=True,)assert?result.success,?"Failed to crawl the page"news_teasers = json.loads(result.extracted_content)print(f"Successfully extracted?{len(news_teasers)}?news teasers")print(json.dumps(news_teasers[0], indent=2))if?__name__ ==?"__main__":asyncio.run(extract_news_teasers())
4.4 使用 OpenAI 提取結構化數據
利用 OpenAI 的能力動態提取和結構化數據:
import?os
import?asyncio
from?crawl4ai?import?AsyncWebCrawler
from?crawl4ai.extraction_strategy?import?LLMExtractionStrategy
from?pydantic?import?BaseModel, Fieldclass?OpenAIModelFee(BaseModel):model_name: str = Field(..., description="Name of the OpenAI model.")input_fee: str = Field(..., description="Fee for input token for the OpenAI model.")output_fee: str = Field(..., description="Fee for output token for the OpenAI model.")asyncdef?main():asyncwith?AsyncWebCrawler(verbose=True)?as?crawler:result =?await?crawler.arun(url='https://openai.com/api/pricing/',word_count_threshold=1,extraction_strategy=LLMExtractionStrategy(provider="openai/gpt-4
o",api_token=os.getenv('OPENAI_API_KEY'),?schema=OpenAIModelFee.schema(),extraction_type="schema",instruction="""From the crawled content, extract all mentioned model names along with their fees for input and output tokens.?Do not miss any models in the entire content. One extracted model JSON format should look like this:?{"model_name": "GPT-4", "input_fee": "US$10.00 / 1M tokens", "output_fee": "US$30.00 / 1M tokens"}."""), ? ? ? ? ? ?bypass_cache=True,)print(result.extracted_content)if?__name__ ==?"__main__":asyncio.run(main())
4.5 會話管理 & 動態內容爬取
處理復雜的場景,如爬取通過 JavaScript 加載動態內容的多個頁面:
import?asyncio
import?re
from?bs4?import?BeautifulSoup
from?crawl4ai?import?AsyncWebCrawlerasyncdef?crawl_typescript_commits():first_commit =?""asyncdef?on_execution_started(page):nonlocal?first_commit?try:whileTrue:await?page.wait_for_selector('li.Box-sc-g0xbh4-0 h4')commit =?await?page.query_selector('li.Box-sc-g0xbh4-0 h4')commit =?await?commit.evaluate('(element) => element.textContent')commit = re.sub(r'\s+',?'', commit)if?commit?and?commit != first_commit:first_commit = commitbreakawait?asyncio.sleep(0.5)except?Exception?as?e:print(f"Warning: New content didn't appear after JavaScript execution:?{e}")asyncwith?AsyncWebCrawler(verbose=True)?as?crawler:crawler.crawler_strategy.set_hook('on_execution_started', on_execution_started)url =?"https://github.com/microsoft/TypeScript/commits/main"session_id =?"typescript_commits_session"all_commits = []js_next_page =?"""const button = document.querySelector('a[data-testid="pagination-next-button"]');if (button) button.click();"""for?page?in?range(3): ?# Crawl 3 pagesresult =?await?crawler.arun(url=url,session_id=session_id,css_selector="li.Box-sc-g0xbh4-0",js=js_next_page?if?page >?0elseNone,bypass_cache=True,js_only=page >?0)assert?result.success,?f"Failed to crawl page?{page +?1}"soup = BeautifulSoup(result.cleaned_html,?'html.parser')commits = soup.select("li.Box-sc-g0xbh4-0")all_commits.extend(commits)print(f"Page?{page +?1}: Found?{len(commits)}?commits")await?crawler.crawler_strategy.kill_session(session_id)print(f"Successfully crawled?{len(all_commits)}?commits across 3 pages")if?__name__ ==?"__main__":asyncio.run(crawl_typescript_commits())
5.性能對比
Crawl4AI在設計上注重速度和效率,性能持續超越許多付費服務。以下是性能測試結果:
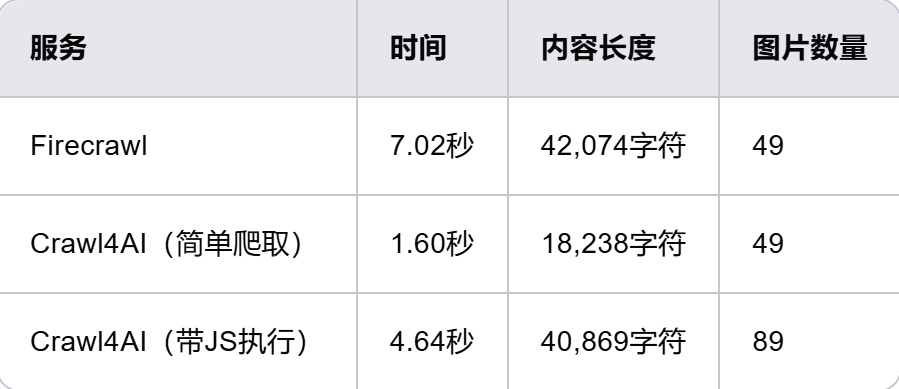
要點總結:
-
簡單爬取:Crawl4AI的速度是Firecrawl的4倍以上。
-
帶JavaScript執行:即使在執行JavaScript加載更多內容的情況下(圖片數量增加一倍),Crawl4AI的速度依然遠超Firecrawl的簡單爬取。



MySQL主從同步原理深度剖析)

![[MySQL初階]MySQL(9)事務機制](http://pic.xiahunao.cn/[MySQL初階]MySQL(9)事務機制)



)
)

:ADC LTC系列模數轉換器的輸出范圍+滿量程和偏移調整)


)

)

