目錄
緩存
緩存更新策略
定期生成
實時生成
緩存問題
緩存預熱(Cache preheating)
緩存穿透(Cache penetration)
緩存雪崩(Cache avalanche)
緩存擊穿(Cache breakdown)
分布式鎖
分布式鎖基礎實現
引入過期時間
引入校驗id
引入lua腳本
引入watch dog(看門狗)
引入Redlock算法
緩存
緩存的核心思路就是把常用的數據放入訪問速度更快的地方,方便隨時讀取。使用Redis作為緩存,數據是直接存儲在內存上的,對于關系型數據庫例如MySql來說速度更快。
為什么說關系型數據庫性能不高?
1.數據庫將數據存儲在硬盤上,硬盤的IO速度沒有內存快。
2.如果查詢不能命中索引,就需要進行表的遍歷,這就會大大增加硬盤IO次數。
3.關系型數據庫會對SQL的執行做一系列的解析,校驗,優化工作。
4.復雜查詢更加消耗效率。(笛卡爾積)
?如果全部請求直接訪問數據庫,對于數據庫壓力很大,很容易使數據庫服務器宕機。使用Redis緩存可以加快讀操作,寫操作還是得寫在數據庫中。
緩存更新策略
定期生成
每隔一定時間,對訪問數據頻次較高的數據進行統計,挑選出訪問頻次最高的前N%的數據,導入到Redis中。實時性比較低,面對突發情況不友好。如春節期間,“春節”的搜索頻率變高,在平時搜索頻率比較低。
實時生成
用戶查詢數據,如果沒有在Redis中命中,就在數據庫中查詢,然后將結果更新到Redis中。如果Redis緩存滿了,就可以使用內存淘汰策略進行刪除:
FIFO(First In First Out)先進先出
將緩存中存在時間最久的數據淘汰。
LRU(Least Recently Used)淘汰最久未使用的
記錄每個key的最近訪問時間,把最近訪問時間最老的key淘汰。
LFU(淘汰訪問次數最少的)
記錄每個key最近一段時間的訪問次數,淘汰訪問次數最少得到。
Random隨機淘汰
隨機淘汰緩存中的key。
緩存問題
緩存預熱(Cache preheating)
剛剛啟動Redis作為MySQL緩存時,Redis自身為空,所有請求都會直接直接訪問數據庫,從而對數據庫造成很大的壓力。
提前準備熱點數據導入Redis中,使Redis更快提供服務,解決緩存預熱問題。
緩存穿透(Cache penetration)
訪問的key在Redis和MySQL中都不存在,此時key不會放入緩存中,后續如果接著訪問這個key,依然會訪問到數據庫。這樣會給數據庫造成壓力。
針對查詢的key進行校驗,如要查詢的key為手機號,首先對key的格式進行校驗。
針對數據庫不存在的key也放入redis中。
使用布隆過濾器,判定key是否存在。
緩存雪崩(Cache avalanche)
短時間內,大量的key失效(Redis掛了/大量key同時過期),導致數據庫壓力增大。
部署高可用的Redis系統,完善監控報警體系。
不給key設置過期時間,或者設置過期時間時加入隨機因子。
緩存擊穿(Cache breakdown)
熱點key突然過期,大量請求直接訪問MySQL數據庫。
將這些熱點key設置為永不過期。
分布式鎖
分布式系統中,當不同節點訪問統一資源時,就需要通過鎖進行互斥控制,避免出現類似“線程 安全”問題。在分布式這種多進程,多主機的的場景中,就需要有一臺服務器進行記錄加鎖操作。
分布式鎖基礎實現
使用Redis實現分布式鎖,本質上就是通過設置一個鍵值對,然后通過鍵值對來判定是否已有其他進程加鎖。
例如在網上買票的時候,車站提供了多個服務器處理買票的請求,客戶端每次買票需要查詢車票數量,判斷車票數量是否大于1,滿足條件車票數量減一。在高并發情況下,可能會導致超賣情況,此時引入分布式鎖。
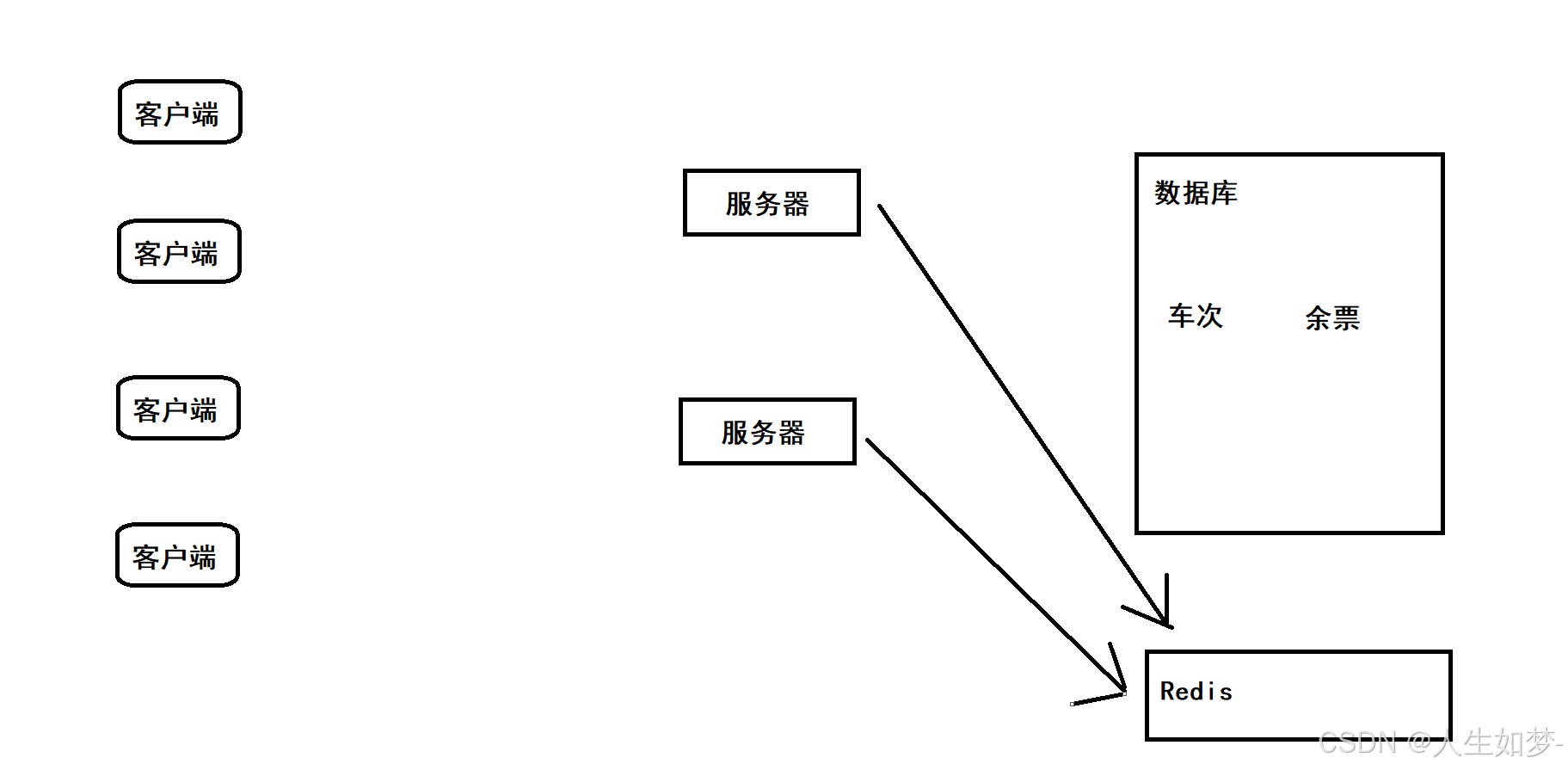
此時服務器對數據庫進行操作時,就會先判斷Redis中是否有加鎖的鍵值對,Redis中的key就可以代表車次,表示該車次的票正在其他進程中進行操作。Redis中提供了setnx操作,當key設置成功,則代表加鎖成功,反之就代表已經有其他進程進行加鎖了。設置成功后,就可以對數據庫進行讀寫操作了,操作完成之后再把Redis上剛剛的key進行刪除。
但是這個方案并不完整,當加鎖的進程在執行刪除key操作之前遇到問題(如宕機),此時刪除操作不能進行,其他進程也不能獲取鎖。
引入過期時間
為解決加鎖后加鎖進程意外宕機的情況,在設置key時順便設置過期時間,表示進程持有鎖的最大時間,達到時間后就會自動刪除key,使用set ex nx命令進行設置,不能分開設置,由于Redis事務不能保證兩個操作都能成功執行,可能就會出現set nx操作成功,但是expire失敗的情況。此時任然會出現無法正確釋放鎖的問題。
但是仍然存在問題,其他進程也可以操作Redis刪除key,此時加鎖就失去了意義。
引入校驗id
為解決其他進程刪除key,引入校驗機制,在設置鍵值對時,value設置為可以識別加鎖服務器的身份。在執行解鎖操作時,先根據value判斷是否為加鎖的服務器。該邏輯用偽代碼表示:
String key = "要加鎖的資源id"; String serverId = "服務器的編號"; //加鎖,設置過期時間為10s redis.set(key,serverId,"NX","EX","10s"); //執行各種邏輯,如數據庫的增刪查改 select(); update(); delete(); insert(); //解鎖,先判斷是否為加鎖進程 if(redis.get(key) == serverId) {redis.del(key); }
在執行解鎖操作時,解鎖的邏輯是分為兩步的,不是原子操作。一個服務器內部,可能是多線程的,同一個服務器內部,兩個線程都在執行解鎖操作,就可能導致del操作被重復執行,然后將其他加鎖線程的鎖給刪除了。
引入lua腳本
?為了使解鎖操作變為原子的,使用Redis支持的lua腳本,將查詢和刪除操作打包為原子操作,可以將上述代碼編寫成一個.lua后綴的文件,一個lua腳本會被Redis服務器以原子的方式進行執行。
引入watch dog(看門狗)
設置key過期時間后,任然存在當前任務沒有執行完,key就過期了的情況,導致鎖提前失效。引入watch dog,本質上是加鎖的服務器上一個單獨的線程,通過這個線程來對鎖的過期時間進行“續約”。這個線程并不是Redis提供,而是業務服務器上的線程。
假設設置一個key,過期時間為10s,設定看門狗線程沒3s檢測一次。
當3s時間到的時候,看門狗就會判定當前任務是否完成。
如果完成,可通過lua腳本直接釋放鎖。
未完成,則將過期時間重新設置為10s(續約)。
這樣就不用擔心鎖提前失效的問題。如果該服務器掛了,那么看門狗線程也隨之掛了,沒人給鎖續約,到達過期時間后key就會過期,讓其他服務器能夠獲取鎖。
引入Redlock算法
?實踐中Redis一般是以集群的方式部署的(至少是主從結構),Redis成為分布式鎖可能會遇到一些極端情況:負責加鎖的master節點剛剛進行加鎖操作,然后就掛了,此時slave節點成了新的master節點,由于此時的key并沒有同步給slave節點,導致加鎖操作形同虛設。
解決辦法:引入一組Redis節點,每一組Redis節點都包含master節點和slave節點,組與組之間的數據都是一致的,相互之間為“備份”關系。在進行加鎖操作時,設置加鎖操作的超時時間,比如設置為30ms,超過30ms沒有加鎖,則視為加鎖失敗。如果當前節點加鎖失敗。就立即嘗試下一個節點,當加鎖成功的節點超過總結點的一半,則視為加鎖成功。即使某些節點掛了也不會影響鎖的正確性。
文章結束,感謝觀看!?
)








)





:實現 stdio 通信的Client與Server)


)
 打開文件操作)