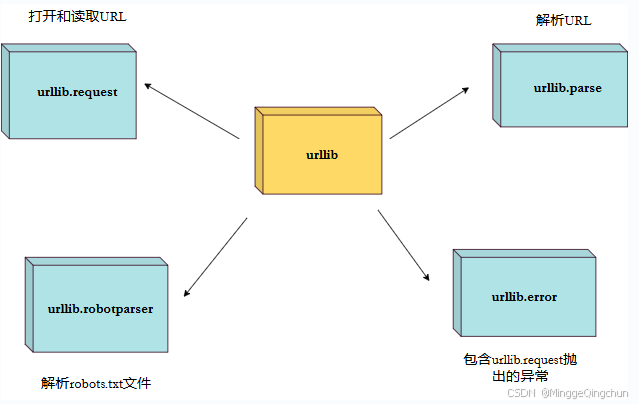
urllib庫是Python內置的HTTP請求庫。無需額外安裝,可以直接使用。urllib庫包含以下四個模塊。
- urllib.request?- 打開和讀取 URL。
- urllib.error?- 包含 urllib.request 拋出的異常。
- urllib.parse?- 解析 URL。
- urllib.robotparser?- 解析 robots.txt 文件。
1、request:最基本的HTTP請求模塊,可以模擬請求的發送。只需給該庫方法傳入URL以及對應的參數,就可以模擬瀏覽器發送請求了
2、error:異常處理模塊。如果出現請求異常,我們可以捕獲這些異常,然后進行重試或其他操作保證程序運行不會意外終止
3、parse:一個工具模塊。提供了許多URL的處理方法,如拆分、解析、合并等
4、robotparser:主要用來識別網站的robot.txt文件,判斷哪些網站可以爬,哪些網站不可以,一般使用較少
一、urllib.request
urllib.request 定義了一些打開 URL 的函數和類,包含授權驗證、重定向、瀏覽器 cookies等。
urllib.request 可以模擬瀏覽器的一個請求發起過程。
使用 urllib.request 的 urlopen 方法來打開一個 URL,語法格式如下:
urllib.request.urlopen(url, data=None, [timeout, ]*, cafile=None, capath=None, cadefault=False, context=None)- url:url 地址。
- data:發送到服務器的其他數據對象,默認為 None。
- timeout:設置訪問超時時間。
- cafile 和 capath:cafile 為 CA 證書, capath 為 CA 證書的路徑,使用 HTTPS 需要用到。
- cadefault:已經被棄用。
- context:ssl.SSLContext類型,用來指定 SSL 設置。
推薦一個測試網站,用于提交各種請求:http://httpbin.org/,該網站的更多的用法自行搜索
r = urllib.request.urlopen('http://httpbin.org/get')
# 讀取response內容
text = r.read()
# http返回狀態碼和msg
print("http返回狀態碼:%s;返回msg:%s"%(r.status,r.msg)) # http返回狀態碼:200;返回msg:OK
r.close()read() 是讀取整個網頁內容?
除了 read() 函數外,還包含以下兩個讀取網頁內容的函數:
-
readline()?- 讀取文件的一行內容
from urllib.request import urlopenmyURL = urlopen("https://www.baidu.com/")
print(myURL.readline()) #讀取一行內容-
readlines()?- 讀取文件的全部內容,它會把讀取的內容賦值給一個列表變量。
from urllib.request import urlopenurl= urlopen("https://www.baidu.com/")
lines = url.readlines()
for line in lines:print(line) import urllib
import json
from urllib import robotparser'''
urllib使用
Python urllib 庫用于操作網頁 URL,并對網頁的內容進行抓取處理
'''print('--------返回狀態碼和msg---------')
r = urllib.request.urlopen('http://httpbin.org/get')
# 讀取response內容
text = r.read()
# http返回狀態碼和msg
print("http返回狀態碼:%s;返回msg:%s"%(r.status,r.msg)) # http返回狀態碼:200;返回msg:OK
r.close()print('--------error---------')
url = urllib.request.urlopen("https://www.baidu.com/")
print(url.getcode()) # 200try:url = urllib.request.urlopen("https://www.baidu.com/index11.html")
except urllib.error.HTTPError as e:if e.code == 404:print(404) # 404print('--------load函數加載的Json內容---------')
# load函數加載json格式內容
obj = json.loads(text)
print(f"load函數加載的Json內容: {obj}") # load函數加載的Json內容: {'args': {}, 'headers': {'Accept-Encoding': 'identity', 'Host': 'httpbin.org', 'User-Agent': 'Python-urllib/3.13', 'X-Amzn-Trace-Id': 'Root=1-67a6c6a7-273842674fbc43b01cdc3fba'}, 'origin': '58.241.18.10', 'url': 'http://httpbin.org/get'}print('--------headers參數---------')
# r.headers是一個HTTPMessage對象
print(r.headers)
# Date: Sat, 08 Feb 2025 02:51:19 GMT
# Content-Type: application/json
# Content-Length: 274
# Connection: close
# Server: gunicorn/19.9.0
# Access-Control-Allow-Origin: *
# Access-Control-Allow-Credentials: true
for key,value in r.headers._headers:print('header每行參數-%s:%s' %(key,value))# header每行參數-Date:Sat, 08 Feb 2025 02:51:19 GMT# header每行參數 - Content - Type: application / json# header每行參數 - Content - Length: 274# header每行參數 - Connection: close# header每行參數 - Server: gunicorn / 19.9.0# header每行參數 - Access - Control - Allow - Origin: *# header每行參數 - Access - Control - Allow - Credentials: trueprint('--------headers參數---------')
ua = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3'
# 添加自定義的頭信息
req = urllib.request.Request('http://httpbin.org/user-agent')
req.add_header('User-Agent', ua)
# 接受一個urllib.request.Request對象
r = urllib.request.urlopen(req)
resp = json.loads(r.read())
# 打印httpbin網站返回信息里的user-agent
print('網站返回的user-agent:', resp["user-agent"]) # 網站返回的user-agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3print('--------auth驗證登錄---------')
auth_handler = urllib.request.HTTPBasicAuthHandler()
auth_handler.add_password(realm='httpbin auth',uri='/basic-auth/admin/admin123',user='admin',passwd='admin123')
opener = urllib.request.build_opener(auth_handler)
urllib.request.install_opener(opener)
r = urllib.request.urlopen('http://httpbin.org')
print(r.read().decode('utf-8'))print('--------GET參數---------')
params = urllib.parse.urlencode({'name': 'admin', 'password': 'admin123'})
url = 'http://httpbin.org/get?%s'%params
with urllib.request.urlopen(url) as r:print(json.load(r)) # {'args': {'name': 'admin', 'password': 'admin123'}, 'headers': {'Accept-Encoding': 'identity', 'Host': 'httpbin.org', 'User-Agent': 'Python-urllib/3.13', 'X-Amzn-Trace-Id': 'Root=1-67a6c6a9-78e0111069464ef205e85476'}, 'origin': '58.241.18.10', 'url': 'http://httpbin.org/get?name=admin&password=admin123'}print('--------POST參數---------')
data = urllib.parse.urlencode({'name': 'admin', 'password': 'admin123'})
data = data.encode()
with urllib.request.urlopen('http://httpbin.org/post', data) as r:print(json.load(r)) # {'args': {}, 'data': '', 'files': {}, 'form': {'name': 'admin', 'password': 'admin123'}, 'headers': {'Accept-Encoding': 'identity', 'Content-Length': '28', 'Content-Type': 'application/x-www-form-urlencoded', 'Host': 'httpbin.org', 'User-Agent': 'Python-urllib/3.13', 'X-Amzn-Trace-Id': 'Root=1-67a6c6aa-3d49564d145ee67e2d47dd95'}, 'json': None, 'origin': '58.241.18.10', 'url': 'http://httpbin.org/post'}print('--------代理IP請求遠程URL---------')
proxy_handler = urllib.request.ProxyHandler({'http': 'http://127.0.0.1:8080'})
# proxy_auth_handler = urllib.request.ProxyBasicAuthHandler()
opener = urllib.request.build_opener(proxy_handler)
# r = opener.open('http://httpbin.org/ip')
# print(r.read())print('--------urlparse模塊---------')
o = urllib.parse.urlparse('http://httpbin.org/get')
print(o) # ParseResult(scheme='http', netloc='httpbin.org', path='/get', params='', query='', fragment='')print('--------robotparser模塊---------')
# 在 Python 3 中,robotparser 是一個獨立的模塊,而不是 urllib 的一個屬性
# 使用 import robotparser 來直接導入 robotparser 模塊。
# 或者使用 from urllib import robotparser 來從 urllib 包中導入 robotparser
rp = robotparser.RobotFileParser()
rp.set_url("http://httpbin.org/robots.txt")
print(rp.read())二、urllib.error
urllib.error 模塊為 urllib.request 所引發的異常定義了異常類,基礎異常類是 URLError。
urllib.error 包含了兩個方法,URLError 和 HTTPError。
URLError 是 OSError 的一個子類,用于處理程序在遇到問題時會引發此異常(或其派生的異常),包含的屬性 reason 為引發異常的原因。
HTTPError 是 URLError 的一個子類,用于處理特殊 HTTP 錯誤例如作為認證請求的時候,包含的屬性?code?為 HTTP 的狀態碼,?reason?為引發異常的原因,headers?為導致 HTTPError 的特定 HTTP 請求的 HTTP 響應頭。
url = urllib.request.urlopen("https://www.baidu.com/")
print(url.getcode()) # 200try:url = urllib.request.urlopen("https://www.baidu.com/index11.html")
except urllib.error.HTTPError as e:if e.code == 404:print(404) # 404三、urllib.parse
urllib.parse 用于解析 URL,格式如下:
urllib.parse.urlparse(urlstring, scheme='', allow_fragments=True)urlstring 為 字符串的 url 地址,scheme 為協議類型
o = urllib.parse.urlparse('http://httpbin.org/get')
print(o) # ParseResult(scheme='http', netloc='httpbin.org', path='/get', params='', query='', fragment='')
完整內容如下:
| 屬性 | 索引 | 值 | 值(如果不存在) |
|---|---|---|---|
|
| 0 | URL協議 | scheme?參數 |
|
| 1 | 網絡位置部分 | 空字符串 |
|
| 2 | 分層路徑 | 空字符串 |
|
| 3 | 最后路徑元素的參數 | 空字符串 |
|
| 4 | 查詢組件 | 空字符串 |
|
| 5 | 片段識別 | 空字符串 |
|
| 用戶名 |
| |
|
| 密碼 |
| |
|
| 主機名(小寫) |
| |
|
| 端口號為整數(如果存在) |
|
四、urllib.robotparser
urllib.robotparser 用于解析 robots.txt 文件。
robots.txt(統一小寫)是一種存放于網站根目錄下的 robots 協議,它通常用于告訴搜索引擎對網站的抓取規則。
urllib.robotparser 提供了 RobotFileParser 類,語法如下:
class urllib.robotparser.RobotFileParser(url='')這個類提供了一些可以讀取、解析 robots.txt 文件的方法:
-
set_url(url) - 設置 robots.txt 文件的 URL。
-
read() - 讀取 robots.txt URL 并將其輸入解析器。
-
parse(lines) - 解析行參數。
-
can_fetch(useragent, url) - 如果允許 useragent 按照被解析 robots.txt 文件中的規則來獲取 url 則返回 True。
-
mtime() -返回最近一次獲取 robots.txt 文件的時間。 這適用于需要定期檢查 robots.txt 文件更新情況的長時間運行的網頁爬蟲。
-
modified() - 將最近一次獲取 robots.txt 文件的時間設置為當前時間。
-
crawl_delay(useragent) -為指定的 useragent 從 robots.txt 返回 Crawl-delay 形參。 如果此形參不存在或不適用于指定的 useragent 或者此形參的 robots.txt 條目存在語法錯誤,則返回 None。
-
request_rate(useragent) -以 named tuple RequestRate(requests, seconds) 的形式從 robots.txt 返回 Request-rate 形參的內容。 如果此形參不存在或不適用于指定的 useragent 或者此形參的 robots.txt 條目存在語法錯誤,則返回 None。
-
site_maps() - 以 list() 的形式從 robots.txt 返回 Sitemap 形參的內容。 如果此形參不存在或者此形參的 robots.txt 條目存在語法錯誤,則返回 None
在 Python 3 中,robotparser 是一個獨立的模塊,而不是 urllib 的一個屬性;
使用 import robotparser 來直接導入 robotparser 模塊;
或者使用 from urllib import robotparser 來從 urllib 包中導入 robotparser
# 在 Python 3 中,robotparser 是一個獨立的模塊,而不是 urllib 的一個屬性
# 使用 import robotparser 來直接導入 robotparser 模塊。
# 或者使用 from urllib import robotparser 來從 urllib 包中導入 robotparser
rp = robotparser.RobotFileParser()
rp.set_url("http://httpbin.org/robots.txt")
print(rp.read())


(1))


)





-2-戰略規劃及管理過程-1-概述)






linux內核)