目錄
一、位圖
1.1 位圖的概念
1.2 位圖的實現
1.3 位圖的應用
二、布隆過濾器
2.1 布隆過濾器的提出
2.2 布隆過濾器的概念
2.3 布隆過濾器的插入和查找
2.4?布隆過濾器的刪除
2.5?布隆過濾器的優點
2.6?布隆過濾器的缺點
一、位圖
1.1 位圖的概念
1. 面試題
給40億個不重復的無符號整數,沒排過序。給一個無符號整數,如何快速判斷一個數是否在這40億個數中。【騰訊】
- 遍歷,時間復雜度(O(N))
- 排序(O(N*logN)),利用二分查找(O(logN))
- 位圖解決:數據是否在給定的整形數據中,結果是在或者不在,剛好是兩種狀態,那么可以使用一個二進制比特位來代表數據是否存在的信息,如果二進制比特位為1,代表存在,為0代表不存在。比如:
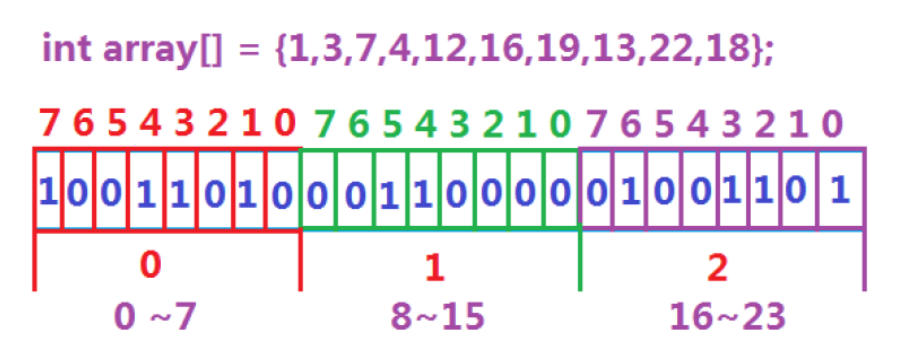
2. 位圖概念
所謂位圖,就是用每一位來存儲某種狀態,適用于海量數據,數據無重復的場景。通常是用來判斷某個數據存不存在。
1.2 位圖的實現
template<size_t N>
class Bitset
{
public:Bitset(){_bs.resize(N / 32 + 1);}void set(size_t x) // 將該位置置為1{size_t i = x / 32;size_t j = x % 32;_bs[i] |= (1 << j);}void reset(size_t x) // 將該位置置為0{size_t i = x / 32;size_t j = x % 32;_bs[i] &= (~(1 << j));}bool test(size_t x) // 判斷該數是否存在{size_t i = x / 32;size_t j = x % 32;return _bs[i] & (1 << j);}
private:vector<int> _bs;
};測試代碼:
void test_bitset1()
{int a1[] = { 5,7,9,2,5,99,5,5,7,5,3,9,2,55,1,5,6 };int a2[] = { 5,3,5,99,6,99,33,66 };Bitset<100> bs1;Bitset<100> bs2;for (auto e : a1){bs1.set(e);}for (auto e : a2){bs2.set(e);}for (size_t i = 0; i < 100; i++){if (bs1.test(i) && bs2.test(i)){cout << i << endl;}}
}
1.3 位圖的應用
- 快速查找某個數據是否在一個集合中
- 排序 + 去重
- 求兩個集合的交集,并集等
- 操作系統中磁盤塊標記
位圖應用變形:1個文件有100億個int,1G內存,設計算法找到出現次數不超過2次的所有整數
template<size_t N>class TwoBiteset{public:void set(size_t x){bool b1 = _bs1.test(x);bool b2 = _bs2.test(x);if (!b1 && !b2) // 第一次出現 00 -> 01_bs2.set(x);else if (b1 && !b2) // 第二次出現 01 -> 10{_bs2.reset(x);_bs1.set(x);}else if (!b1 && b2) // 第三次即以上 10 -> 11{_bs2.set(x);}}size_t count(size_t x){bool b1 = _bs1.test(x);bool b2 = _bs2.test(x);if (!b1 && !b2) // 出現次數0return 0;else if (!b1 && b2) // 出現次數1return 1;else if (b1 && !b2) // 出現次數2return 2;else // 出現次數大于2return 3;}private:Bitset<N> _bs1;Bitset<N> _bs2;};測試代碼:
void test_twobitset()
{TwoBiteset<100> tbs;int a[] = { 5,7,9,2,5,99,5,5,7,5,3,9,2,55,1,5,6,6,6,6,7,9 };for (auto e : a){tbs.set(e);}for (size_t i = 0; i < 100; ++i){//cout << i << "->" << tbs.get_count(i) << endl;if (tbs.count(i) == 1 || tbs.count(i) == 2){cout << i << endl;}}
}
二、布隆過濾器
2.1 布隆過濾器的提出
我們在使用新聞客戶端看新聞時,它會給我們不停地推薦新的內容,它每次推薦時要去重,去掉那些已經看過的內容。問題來了,新聞客戶端推薦系統如何實現推送去重的? 用服務器記錄了用戶看過的所有歷史記錄,當推薦系統推薦新聞時會從每個用戶的歷史記錄里進行篩選,過濾掉那些已經存在的記錄。 如何快速查找呢?
- 用哈希表存儲用戶記錄,缺點:浪費空間。
- 用位圖存儲用戶記錄,缺點:位圖一般只能處理整形,如果內容編號是字符串,就無法處理了。
- 將哈希與位圖結合,即布隆過濾器。
2.2 布隆過濾器的概念
布隆過濾器是由布隆(Burton Howard Bloom)在1970年提出的 一種緊湊型的、比較巧妙的概率型數據結構,特點是高效地插入和查詢,可以用來告訴你 “某樣東西一定不存在或者可能存在”,它是用多個哈希函數,將一個數據映射到位圖結構中。此種方式不僅可以提升查詢效率,也可以節省大量的內存空間。
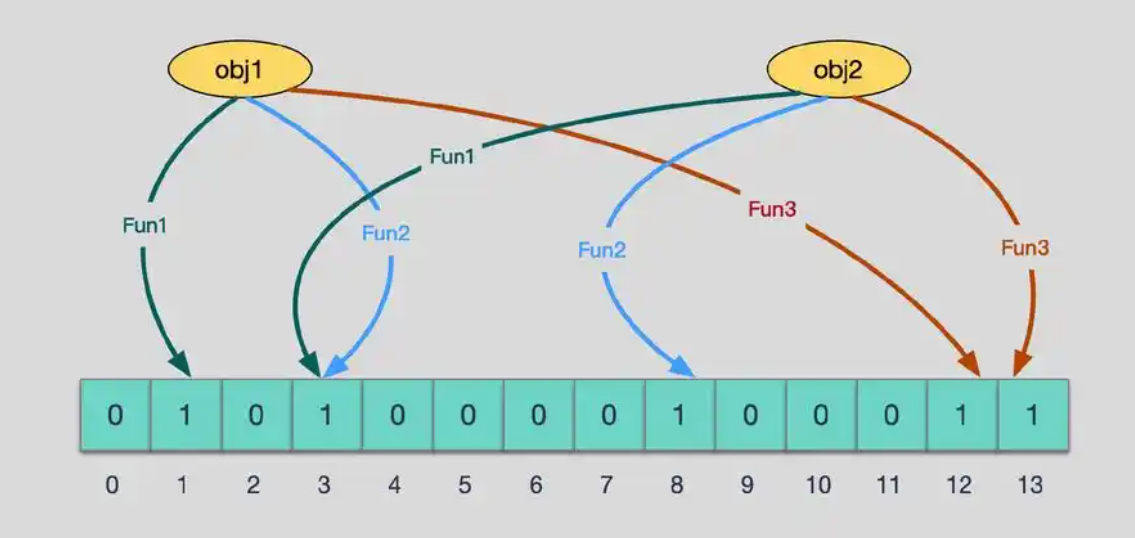
2.3 布隆過濾器的插入和查找
1. 插入
向布隆過濾器中插入:world
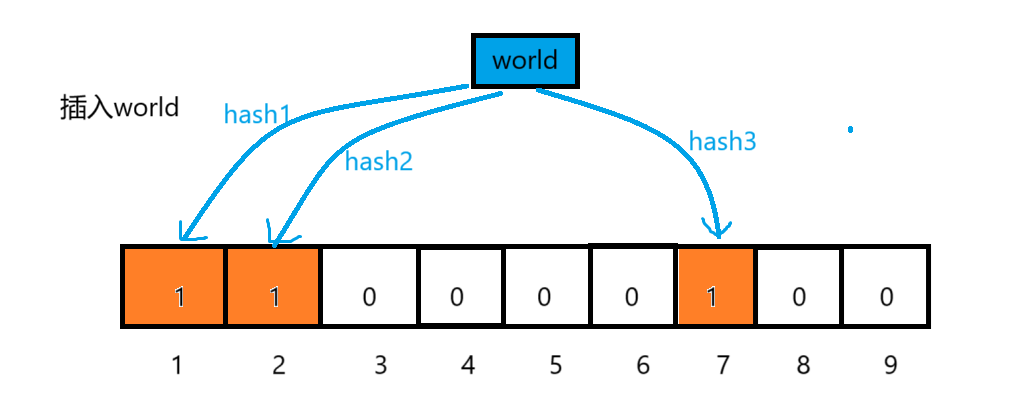
向布隆過濾器中插入:hello
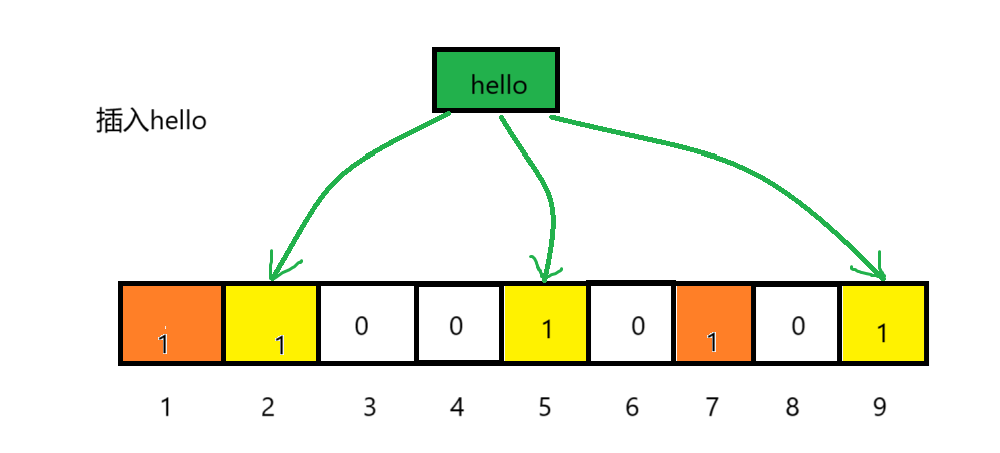
2. 查找
布隆過濾器的思想是將一個元素用多個哈希函數映射到一個位圖中,因此被映射到的位置的比特位一定為1。所以可以按照以下方式進行查找:分別計算每個哈希值對應的比特位置存儲的是否為零,只要有一個為零,代表該元素一定不在哈希表中,否則可能在哈希表中。
注意:布隆過濾器如果說某個元素不存在時,該元素一定不存在,如果該元素存在時,該元素可能存在,因為有些哈希函數存在一定的誤判。
#include <string>
#include "Bitset.h"struct HashFuncBKDR
{// 本算法由于在Brian Kernighan與Dennis Ritchie的《The CProgramming Language》// 一書被展示而得 名,是一種簡單快捷的hash算法,也是Java目前采用的字符串的Hash算法累乘因子為31。size_t operator()(const std::string& s){size_t hash = 0;for (auto ch : s){hash *= 31;hash += ch;}return hash;}
};struct HashFuncAP
{// 由Arash Partow發明的一種hash算法。 size_t operator()(const std::string& s){size_t hash = 0;for (size_t i = 0; i < s.size(); i++){if ((i & 1) == 0) // 偶數位字符{hash ^= ((hash << 7) ^ (s[i]) ^ (hash >> 3));}else // 奇數位字符{hash ^= (~((hash << 11) ^ (s[i]) ^ (hash >> 5)));}}return hash;}
};struct HashFuncDJB
{// 由Daniel J. Bernstein教授發明的一種hash算法。 size_t operator()(const std::string& s){size_t hash = 5381;for (auto ch : s){hash = hash * 33 ^ ch;}return hash;}
};template<size_t N, size_t X = 5, class K = string, // X跟誤判率有關class Hash1 = HashFuncBKDR, class Hash2 = HashFuncAP,class Hash3 = HashFuncDJB>
class Bloomfilter
{
public:void set(const K& key){size_t hash1 = Hash1()(key) % M;size_t hash2 = Hash2()(key) % M;size_t hash3 = Hash3()(key) % M;_bf.set(hash1);_bf.set(hash2);_bf.set(hash3);}bool test(const K& key){size_t hash1 = Hash1()(key) % M;size_t hash2 = Hash2()(key) % M;size_t hash3 = Hash3()(key) % M;if (_bf.test(hash1) == false)return false;else if (_bf.test(hash2) == false)return false;else if (_bf.test(hash3) == false)return false;elsereturn true; // 可能存在誤判}// 獲取公式計算出的誤判率double getFalseProbability(){double p = pow((1.0 - pow(2.71, -3.0 / X)), 3.0);return p;}
private:static const size_t M = N * X;my::Bitset<M> _bf;
};測試代碼:
void TestBloomFilter1()
{Bloomfilter<10> bf;bf.set("豬八戒");bf.set("孫悟空");bf.set("唐僧");cout << bf.test("豬八戒") << endl;cout << bf.test("孫悟空") << endl;cout << bf.test("唐僧") << endl;cout << bf.test("沙僧") << endl;cout << bf.test("豬八戒1") << endl;cout << bf.test("豬戒八") << endl;
}
2.4?布隆過濾器的刪除
布隆過濾器不能直接支持刪除工作,因為在刪除一個元素時,可能會影響其他元素。
比如:刪除上圖中"hello"元素,如果直接將該元素所對應的二進制比特位置0,“world”元素也被刪除了,因為這兩個元素在多個哈希函數計算出的比特位上剛好有重疊.
一種支持刪除的方法:將布隆過濾器中的每個比特位擴展成一個小的計數器,插入元素時給k個計數器(k個哈希函數計算出的哈希地址)加一,刪除元素時,給k個計數器減一,通過多占用幾倍存儲空間的代價來增加刪除操作。
缺陷:
- 無法確定元素是否真正在布隆過濾器中
- 存在計數回繞
2.5?布隆過濾器的優點
- 增加和查詢元素的時間復雜度為:O(K), (K為哈希函數的個數,一般比較小),與數據量大小無關
- 哈希函數相互之間沒有關系,方便硬件并行運算
- 布隆過濾器不需要存儲元素本身,在某些對保密要求比較嚴格的場合有很大優勢
- 在能夠承受一定的誤判時,布隆過濾器比其他數據結構有這很大的空間優勢
- 數據量很大時,布隆過濾器可以表示全集,其他數據結構不能
- 使用同一組散列函數的布隆過濾器可以進行交、并、差運算
2.6?布隆過濾器的缺點
- 有誤判率,即存在假陽性(False Position),即不能準確判斷元素是否在集合中(補救方法:再建立一個白名單,存儲可能會誤判的數據)
- 不能獲取元素本身
- 一般情況下不能從布隆過濾器中刪除元素
- 如果采用計數方式刪除,可能會存在計數回繞問題
)

(一))


-- 所有權與借用)
認證與踩坑記錄)
![[AI React Web] 包與依賴管理 | `axios`庫 | `framer-motion`庫](http://pic.xiahunao.cn/[AI React Web] 包與依賴管理 | `axios`庫 | `framer-motion`庫)




)




排序算法—插入排序(插入、希爾)(動圖演示))

