利用bbbrisk一步一步實現評分卡
- 一、什么是評分卡
- 1.1.什么是評分卡
- 1.2.評分卡有哪些
- 二、評分卡怎么弄出來的
- 2.1.如何制作評分卡
- 2.2.制作評分卡的流程
- 三、變量的分箱
- 3.1.數據介紹
- 3.2.變量自動分箱
- 3.3.變量的篩選
- 四、構建評分卡
- 4.1.評分卡實現代碼
- 4.2.評分卡表
- 4.3.閾值表與分數分布圖
一、什么是評分卡
1.1.什么是評分卡
評分卡,一般是指用于小貸客戶質量評分的評分卡表。
評分卡樣式如下:
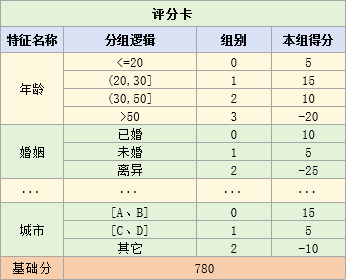
來了一個新客戶,先根據客戶的數據,判斷客戶在各個特征上屬于哪一組
然后在評分卡表中找到對應的分數,對所有特征得分求和,并加上基本分,就是客戶的總評分
假設客戶在rev、due30、due90、city上的組別為【0、3、1、1】
那么客戶在rev、due30、due90、city上的得分為【28、-30、-20、5】
則客戶的總得分為28-30-20+5+780=763
1.2.評分卡有哪些
針對評分的使用不同場景,一般分為A、B、C、F卡
- A卡:Application scorecard,申請評分卡
A卡用申請數據,建立模型,評估用戶是否會壞賬
作用:用于審批放款 - B卡:Behavior scorecard,行為評分卡
C卡作用于借貸中的客戶。加入貸后還款等行為數據
多種作用:可用于老客戶提額 - C卡:Collection scorecard,催收評分卡
作用于借貸中的客戶
作用:預測用戶是否會逾期,提前催收 - F卡:(Fraud scorecard):欺詐評級評分卡
作用于申請階段,針對欺詐客戶的判斷
二、評分卡怎么弄出來的
2.1.如何制作評分卡
評分卡建模的思路與流程如下: 先在原始數據中,衍生并選擇出建模的變量, 然后用建模變量與好壞客戶標簽建立邏輯回歸模型。這樣就能通過建模變量預測樣本是壞客戶的概率,最后,把邏輯回歸模型的線性部分抽取出來,生成評分卡。
最后的最后,還需要分析當前業務應以哪個分數作為拒絕客戶的臨界值,以臨界值作為評分閾值。
2.2.制作評分卡的流程
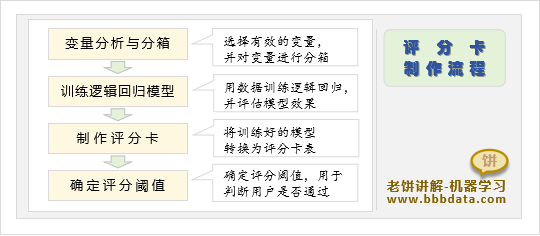
- 建模數據準備
數據準備主要是建模之前,對原始數據進行分箱與變量分析
篩選出與客戶質量相關的變量,作為建模的輸入特征 - 建模
(1)數據預處理:歸一化,并預留測試數據
(2)用逐步回歸選出盡量少的特征(同時保持建模效果)
(3)訓練邏輯回歸模型
(4)檢驗AUC是否達標,并檢查系數是否都為正 - 制作評分卡
制作評分卡也俗稱“模型轉評分”
將3中得到的邏輯回歸模型,制作成評分卡表 - 確定評分閾值
確定生產上判定為壞客戶的分數閾值
當分數低于該閾值時,就拒絕客戶
三、變量的分箱
在構建評分卡之前,需要先對變量進行分析與分箱,并選擇出有效的變量作為建模變量。
3.1.數據介紹
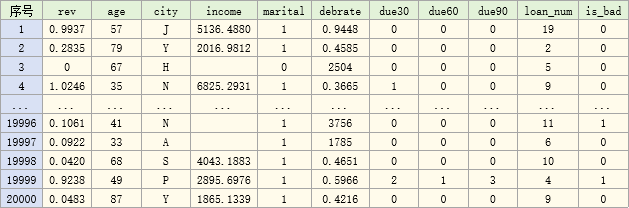
bbbrisk自帶的小貸數據共包含10個變量與客戶好壞標簽,數據包含的10變量和標簽如下:

數據共2萬條,示例如下:
3.2.變量自動分箱
變量的分箱可以使用算法進行自動分箱,常用的分箱算法有:等頻分箱、等距分箱、決策樹分箱、KS分箱和卡方分箱等等。
bbbrisk包提供了bins.autoBin函數來對多個變量進行自動分箱,具體代碼如下:
import bbbrisk as br# 加載數據
data = br.datasets.load_bloan() # 加載數據
x = data.iloc[:,:-1] # 變量數據
y = data['is_bad'] # 標簽數據# 自動分箱
bin_sets = br.bins.batch.autoBins(x, y,enum_var=['city','marital']) # 自動分箱,如果有枚舉變量,必須指出哪些是枚舉變量
bin_stats = br.bins.batch.bin_stats(x,y,bin_sets) # 統計各個變量的分箱情況
br.display.pd.set(width=300,max_colwidth=30,max_rows=30) # 美化pandas的顯示方式
for var in bin_stats: # 逐個變量打印分箱結果print('\n變量'+var+'的分箱結果:\n',bin_stats[var]) # 打印當前變量的分箱統計結果# 選擇iv足夠大的變量
select_bin_set = {} # 初始化選擇的變量的分箱
for var,stat in bin_stats.items(): # 逐個變量循環if (stat['iv'].iloc[-1]>0.1): # 當前變量的iv值是否滿足要求select_bin_set[var] = bin_sets[var] # 如果滿足,則添加到選擇池
print('\n iv > 0.1 的變量與分箱結果:\n',select_bin_set) # 最終選擇的變量的分箱
通過以上的代碼,就對變量進行分箱了,它的結果如下:
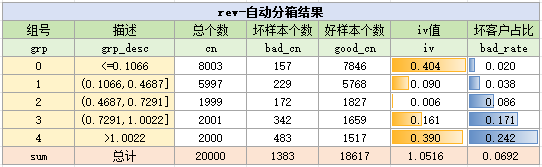
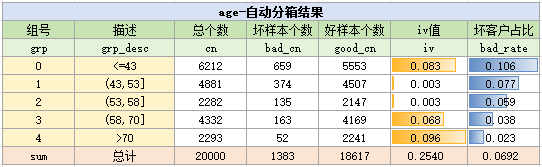
…
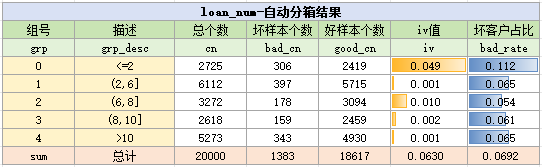
3.3.變量的篩選
一般來說,需要通過iv值來篩選出有效的變量。
IV全稱為信息價值(Information Value),它常在評分卡中用于篩選變量。IV的原理是通過評估好、壞樣本在變量分布上的差異,從而評估變量對y的信息價值。
IV值越高,變量的價值越高,一般來說,IV值與變量對好壞客戶的區分度的關系如下:
IV < 0.02 :幾乎沒有區分度,
0.02 <= IV < 0.1 :有微弱的區分度;
0.1 <= IV < 0.3 :有明顯的區分度;
0.3 <= IV :較強的區分度
通考上述的值,來篩選出有效的變量。在本例中,所有變量都是有效的。
四、構建評分卡
在完成變量分箱后,就可以直接使用bbbrisk的評分卡包來構建評分卡,以及打印相關報告
如果沒有bbbrisk的包,需要先通過pip安裝
pip install bbbrisk
4.1.評分卡實現代碼
用bbbrisk構建評分卡的具體代碼如下:
import bbbrisk as br#加載數據
data = br.datasets.load_bloan() # 加載數據
x = data.iloc[:,:-1] # 變量數據
y = data['is_bad'] # 標簽數據# 構建評分卡
bin_sets = br.bins.batch.autoBins(x, y,enum_var=['city','marital']) # 自動分箱,必須指出哪些是枚舉變量
model,card = br.model.scoreCard(x,y,bin_sets) # 構建評分卡
score = card.predict(x[card.var]) # 用評分卡進行評分
# 打印結果
print('\n-----【 模型性能評估 】----')
print('* 模型訓練AUC:',model.train_auc) # 打印模型訓練數據集的AUC
print('* 模型測試AUC:',model.test_auc) # 打印模型測試數據集的AUC
print('* 模型訓練KS:',model.train_ks) # 打印模型訓練數據集的KS
print('* 模型測試KS:',model.test_ks) # 打印模型測試數據集的KSprint('\n--------【 模型 】---------')
print('* 模型使用的變量:',model.var) # 模型最終使用的變量
print('* 模型權重:',model.w) # 模型的變量權重
print('* 模型閾值:',model.b) # 模型的閾值print('\n--------【 評分卡 】---------')
print('\n* 特征得分featureScore: \n' ,card.featureScore ) # 特征得分
print('\n* 基礎得分baseScore: ' ,card.baseScore ) # 基礎分
運行結果如下:
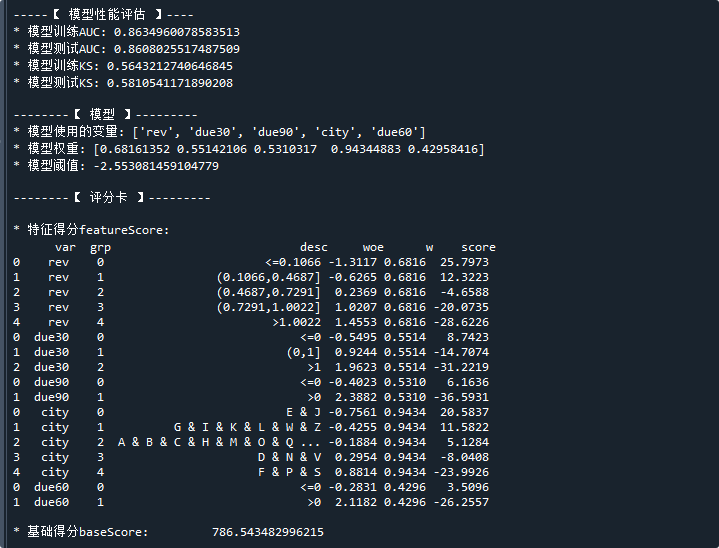
可以看到,通過簡單的代碼,就可以得到評分卡模型的AUC/KS,以及模型的參數、評分卡表。
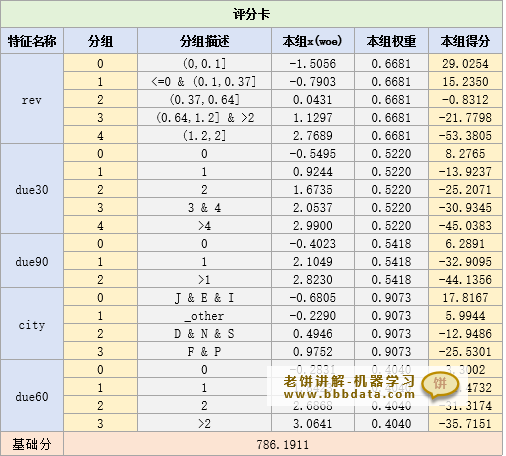
4.2.評分卡表
card.featureScore和card.baseScore里分別存放了特征得分與基礎,兩者合并后就是最終的評分卡表,如下:
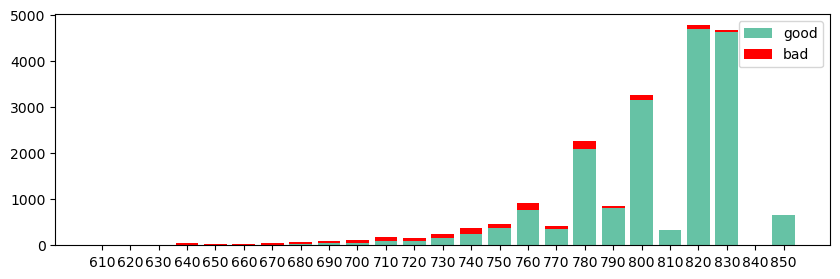
4.3.閾值表與分數分布圖
閾值表與分數分布圖,可以進一步使用report.get_threshold_tb來計算閾值表,以及用report.draw_score_disb則用于繪制分數分布圖。代碼如下:
# 計算閾值表與分數分布圖
thd_tb = br.report.get_threshold_tb(score,y,bin_step=10) # 閾值表
br.report.draw_score_disb(score,y,bin_step=10,figsize=(14, 4)) # 分數分布
評分閾值表的結果如下:

樣本的分數分布結果如下:
好了,以上就是如何制作一個評分卡了。
更多可以參考:
【1】老餅講解-評分卡
【2】bbbrisk評分卡API說明




linux內核)









物理層)




:Python序列結構-字典)