概述
對于MYSQL的INNODB存儲引擎的索引,大家是不陌生的,都能想到是 B+樹結構,可以加速SQL查詢。但對于B+樹索引,它到底“長”得什么樣子,它具體如何由一個個字節構成的,這些的基礎知識鮮有人深究。本篇文章從MYSQL行記錄開始說起,層層遞進,包括數據頁,B+樹聚簇索引,B+樹二級索引,最后在文章末尾給出MYSQL索引的建議。
表空間
首先,我們來了解一下 MySQL 的表空間。在 MySQL 中,所有的數據都被存儲在一個空間內,稱之為表空間,表空間內部又可以分為段(segment)、區(extent)、頁(page)、行(row),其邏輯結構如下圖:
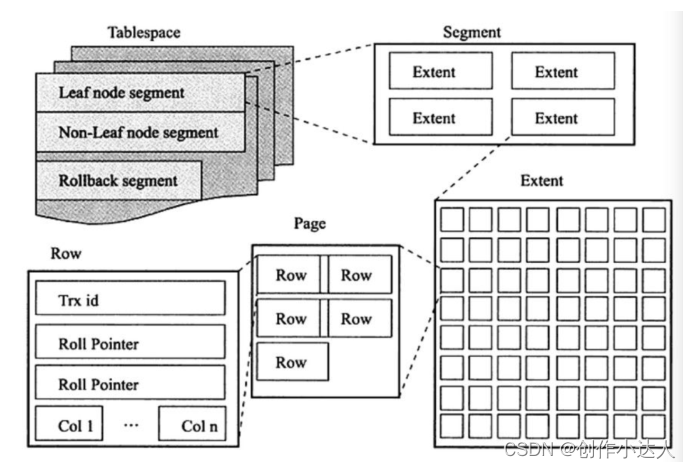
段(segment)
表空間是由不同的段組成的,常見的段有:數據段,索引段,回滾段等等,在 MySQL 中,數據是按照 B+ 樹來存儲,因此數據即索引,因此數據段即為 B+ 樹的葉子節點,索引段為 B+ 樹的非葉子節點,回滾段用于存儲undo日志,用于事務失敗后數據回滾以及在事務未提交之前通過undo日志獲取之前版本的數據,在?InnoDB 1.1?版本之前,一個 InnoDB 只支持一個回滾段,支持 1023 個并發修改事務同時進行,在?InnoDB 1.2?版本,將回滾段數量提高到了 128 個,也就是說可以同時進行128 * 1023個并發修改事務。
區(extent)
區是由連續頁組成的空間,每個區的固定大小為 1MB,為保證區中頁的連續性,InnoDB 會一次從磁盤中申請 4 ~ 5 個區,在默認不壓縮的情況下,一個區可以容納 64 個連續的頁。但是在開始新建表的時候,空表的默認大小為 96KB,是由于為了高效的利用磁盤空間,在開始插入數據時表會先利用 32 個頁大小的碎片頁來存儲數據,當這些碎片使用完后,表大小才會按照 MB 倍數來增加。
頁(page)
頁是 InnoDB 存儲引擎的最小管理單位,每頁大小默認是 16KB,從?InnoDB 1.2.x?版本開始,可以利用innodb_page_size來改變頁大小,但是改變只能在初始化 InnoDB 實例前進行修改,之后便無法進行修改,除非mysqldump導出創建新庫,常見的頁類型有:數據頁、undo頁、系統頁、事務數據頁、插入緩沖位圖頁、插入緩沖空閑列表頁、未壓縮的二進制大對象頁以及壓縮的二進制大對象頁等。
行(row)
行對應的是表中的行記錄,每頁存儲最多的行記錄也是有硬性規定的最多16KB/2-200,即 7992 行,其中 16KB 是頁大小。
Clustered Index 聚簇索引
MySQL InnoDB 引擎具有強制聚簇索引,通常使用主鍵。也就是主鍵就是Clustered Index,如果沒有主鍵按以下規則生成。
Clustered Index 條件優化級:
-
表有明確的PRIMARY KEY:使用PRIMARY KEY
-
無PRIMARY KEY:InnoDB 默認使用第一個 UNIQUE INDEX,且索引列需要全部定義為非空列(NOT NULL)作為Clustered Index
-
如無PRIMARY KEY,也沒有合適的UNIQUE INDEX,InnoDB將會在包含行ROW ID的合成列上生成一個名為GEN_CLUST_INDEX的隱藏Clustered Index
ROW ID:ROW ID是6 byte字段,由InnoDB分配,用于行排序。插入新行而單調增加,在物理上插入按ROW ID順序排列
注:UNIQUE INDEX 包含的列需要全部定義為NOT NULL非空,才會被當做Clustered Index
MyISAM 存儲引擎不支持聚簇索引并且一直使用堆表
2. 聚簇索引如何加速查詢
通過聚簇索引訪問行很快,因為索引搜索直接指向包含行數據的頁面。如果表很大,與使用與索引記錄不同的頁來存儲行數據的存儲組織相比,聚簇索引架構通常可以節省磁盤 I/O 操作。
3. Clustered Index 示例及查詢:
INNODB_INDEXES 表type字段說明:
-
0 = 非唯一索引的二級索引 :nonunique secondary index;
-
1 = 自動生成的聚簇索引:automatically generated clustered index (GEN_CLUST_INDEX);
-
2 = 唯一索引(非聚簇索引): unique nonclustered index;
-
3 = 聚簇索引 clustered index;
-
32 = 全文索引 full-text index
不同MySQL版本表名不同,使用命令查詢:SHOW TABLES FROM INFORMATION_SCHEMA LIKE 'INNODB_%';
自動生成名為GEN_CLUST_INDEX的Clustered Index示例:
-- 創建無主鍵、無唯一索引
CREATE TABLE `clustered_index_demo` (`id` int DEFAULT '0'
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_general_ci;-- 查詢表索引
-- 如5.7以下版本表名不同,使用命令查詢:SHOW TABLES FROM INFORMATION_SCHEMA LIKE 'INNODB_SYS%';
SELECT t2.INDEX_ID ,t2.`NAME` , t2.TABLE_ID , t2.`TYPE` , t2.N_FIELDS , t2.PAGE_NO , t2.`SPACE` , t2.MERGE_THRESHOLD
FROM information_schema.INNODB_TABLES t1
INNER JOIN information_schema.INNODB_INDEXES t2 ON t1.TABLE_ID = t2.TABLE_ID
WHERE t1.`NAME` = 'wiki/clustered_index_demo';-- 查詢結果| INDEX_ID | NAME | TABLE_ID | TYPE | N_FIELDS | PAGE_NO | SPACE | MERGE_THRESHOLD |
|----------|-----------------|----------|------|----------|---------|-------|-----------------|
| 3616 | GEN_CLUST_INDEX | 3276 | 1 | 5 | 4 | 2113 | 增加包含NOT NULL列的唯一索引示例:
Tips : 修改表結構,InnoDB將刪除原自動生成的GEN_CLUST_INDEX索引
-- 增加兩列
ALTER TABLE `wiki`.`clustered_index_demo`
ADD COLUMN `username` varchar(32) NOT NULL,
ADD COLUMN `name` varchar(64) NOT NULL;
-- 增加唯一索引
ALTER TABLE `wiki`.`clustered_index_demo`
ADD UNIQUE INDEX `IDX_UNIQUE` (`username`,`name`) USING BTREE;| INDEX_ID | NAME | TABLE_ID | TYPE | N_FIELDS | PAGE_NO | SPACE | MERGE_THRESHOLD |
|----------|------------|----------|------|----------|---------|-------|-----------------|
| 3620 | IDX_UNIQUE | 3278 | 3 | 5 | 4 | 2115 | 50 |
唯一索引包含NULL列
-- 將唯一索引,其中一列改為NULL, Clustered Index將被刪除,重新生成GEN_CLUST_INDEX
ALTER TABLE `wiki`.`clustered_index_demo`
CHANGE `username` `username` varchar(32) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL,
CHANGE `name` `name` varchar(64) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL;| INDEX_ID | NAME | TABLE_ID | TYPE | N_FIELDS | PAGE_NO | SPACE | MERGE_THRESHOLD |
|----------|-----------------|----------|------|----------|---------|-------|-----------------|
| 3625 | GEN_CLUST_INDEX | 3281 | 1 | 6 | 4 | 2118 | 50 |
| 3626 | IDX_UNIQUE | 3281 | 2 | 3 | 5 | 2118 | 查詢所有自動生成的Clustered Index
SELECTi.TABLE_ID,t.NAME
FROMinformation_schema.INNODB_INDEXES iJOIN information_schema.INNODB_TABLES t ON (i.TABLE_ID = t.TABLE_ID)
WHEREi.NAME = 'GEN_CLUST_INDEX';| TABLE_ID | NAME |
|----------|---------------------------|
| 3281 | wiki/clustered_index_demo |?輔助索引
除了聚簇索引之外的索引都可以稱之為輔助索引,與聚簇索引的區別在于輔助索引的葉子節點中存放的是主鍵的鍵值。一張表可以存在多個輔助索引,但是只能有一個聚簇索引,通過輔助索引來查找對應的航記錄的話,需要進行兩步,第一步通過輔助索引來確定對應的主鍵,第二步通過相應的主鍵值在聚簇索引中查詢到對應的行記錄,也就是進行兩次 B+ 樹搜索。相反,通過輔助索引來查詢主鍵的話,遍歷一次輔助索引就可以確定主鍵了,也就是所謂的索引覆蓋,不用回表。
創建輔助索引,可以創建單列的索引,也就是用一個字段來創建索引,也可以用多個字段來創建副主索引稱為聯合索引,創建聯合索引后,B+ 樹的節點存儲的鍵值數量不是 一個,而是多個,如下圖:
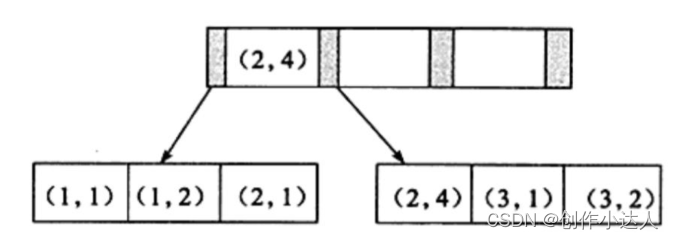
-
聯合索引的 B+ 樹和單鍵輔助索引的 B+ 樹是一樣的,鍵值都是排序的,通過葉子節點可以邏輯順序的讀出所有的數據,比如上圖所存儲的數據時,按照(a,b)這種形式
(1,1),(1,2),(2,1),(2,4),(3,1),(3,2)進行存放,這樣有個好處,那就是存放數據時排序了,當進行order by對某個字段進行排序時,可以減少復雜度,加速進行查詢; -
當用
select * from table where a=? and ?可以使用索引(a,b)來加速查詢,但是在查詢時有一個原則,SQL 的where條件的順序必須和二級索引一致,而且還遵循索引最左原則,select * from table where b=?則無法利用(a,b)索引來加速查詢。 -
輔助索引還有一個概念便是索引覆蓋,索引覆蓋的一個好處便是輔助索引不包含行記錄,因此其大小遠遠小于聚簇索引,利用輔助索引進行查詢可以減少大量的 IO 操作。
索引的優缺點及建議
?
優點:
-
對于等值查詢,可快速定位到對于的行記錄。
-
對于范圍查詢,可輔助縮小掃描區間。
-
當ORDER BY的列名 與 索引的列名完全一致時,可加快排序的順序。
-
當GROUP BY的列名 與 索引的列名完全一致時,可加快分組。
-
當二級索引列中 包含了 SELECT 關鍵字后面寫明的所有列,則在查詢完成二級索引之后無需進行回表操作,直接返回即可。這種情況,稱為【覆蓋索引】。
缺點:
建立索引占用磁盤空間。
對表中的數據進行 增加,刪除,修改 操作時,都需要修改各個索引樹,特別是如果新增的行記錄的主鍵順序不是遞增的,就會產生頁分裂,頁回收等操作,有較大的時間成本。
當二級索引列的值 的 不重復值的個數較少時,通過二級索引查詢找到的數據量就會比較多,相應的就會產生過多的回表操作。
在執行查詢語句的時候,首先要生成一個執行計劃。通常情況下,一個SQL在執行過程中最多使用一個二級索引,在生成執行計劃時需要計算使用不同索引執行查詢時所需的成本,最后選擇成本最低的那個索引執行查詢。因此,如果建立太多的索引,就會導致成本分析過程耗時太多,從而影響查詢語句的性能。
建議:
-
只為用于搜索,排序,分組的列創建索引。
-
索引的列需要有辨識性,盡可能地區分出不同的記錄。
-
索引列的類型盡量小。因為數據類型越小,索引占用的存儲空間就越少,在一個數據頁內就可以存放更多的記錄,磁盤I/O帶來的性能損耗也就越小。
-
如果需要對很長的字段進行快速查詢,可考慮為列前綴建立索引。【alter table table_M add index idx_key1(column_n(10)) --> ?將table_M表的 idx_key1列的前10個字符創建索引】
-
覆蓋索引,當二級索引列中包含了SELECT關鍵字后面寫明的所有列,則在查詢完成二級索引之后無需進行回表操作,直接返回即可。因此,編寫【select *】的時候,要想想是否必要
-
在查詢語句中,索引列不要參與條件值計算,也是把條件值計算完成之后,再和索引列對比。【否則MYSQL會認為搜索條件不能形成合適的掃描區間來減少掃描的記錄數量】
?
?





)

)











