大模型本身提供的功能,類似于windows中的一個exe小工具,我們可以本機離線調用然后完成具體的功能,但是別的機器需要訪問這個exe是不可行的。常見的做法就是用web容器封裝起來,提供一個http接口,然后接口在后端調用這個exe來實現需求。同理我們需要一個web容器把大模型封裝起來,然后通過API來提供AI服務。
這里對比本機離線調用和API服務調用,并通過FastAPI來實現AI的API服務化(LangChain也是通過這些框架提供的API服務)。
一、本機離線調用
看代碼:
from transformers import AutoTokenizer, AutoModelMODEL_PATH = 'c:\\ai\\llms\\chatglm3-6b'
TOKENIZER_PATH = 'c:\\ai\\llms\\chatglm3-6b'# 第一步,獲取大模型
tokenizer = AutoTokenizer.from_pretrained(TOKENIZER_PATH, trust_remote_code=True)
model = AutoModel.from_pretrained(MODEL_PATH, trust_remote_code=True, device_map="auto").eval()
# add .quantize(bits=4, device="cuda").cuda() before .eval() to use int4 model
# must use cuda to load int4 model# 第二步,定義交互過程函數
def chat_handler(query: str):response = model.chat(tokenizer,query,history=None,top_p=1,max_new_tokens=1024,temperature=0.1)print(response, end="", flush=True)# 第三步,實際交互
chat_handler('who are you')
實際調用過程是比較簡單的,從大模型指定路徑加載大模型,然后就可以通過調用chat實現交互。
看結果:

二、通過FastAPI來封裝API服務
OpenAI提供了一個很好的接口規范,其余大模型以及大模型框架在提供接口時都做了類似的兼容處理,包括接口名、傳參方式、參數格式等都仿照OpenAI的接口方式,這樣可以大幅降低學習成本和模型切換的成本,當你想嘗試不同的大模型時不需要做大量的改動。
接下來主要是通過FastAPI來封裝我們的AI后臺服務器。
2.1 構建服務端
2.1.1 使用工具
這里使用三個工具:
- FastAPI:FastAPI 是一個快速(高性能)的構建API的Web框架。
- Uvicorn:Uvicorn 是一款高效的ASGI服務器,主要是為了服務端的高效異步處理。
- Pydantic:Pydantic 是一款廣泛使用的數據校驗工具,主要是為了接口參數的規范和校驗。
通過使用三個工具,可以快速部署一個后端服務,并且這個服務可以對輸入參數進行方便的校驗,同時實現高效異步調控。
在服務端安裝三個工具:
> pip install fastapi uvicorn pydantic2.1.2 啟動服務端的代碼
from fastapi import FastAPI
from pydantic import BaseModel
import uvicorn
from transformers import AutoTokenizer, AutoModel, AutoModelForCausalLM# 第一步,加載大模型
model_dir = 'c:\\ai\\llms\\chatglm3-6b'
tokenizer = AutoTokenizer.from_pretrained(model_dir, trust_remote_code=True)
model = AutoModel.from_pretrained(model_dir, device_map="cuda", trust_remote_code=True).eval()# 第二步,創建FastAPI應用實例
app = FastAPI()# 第三步,定義請求類型,與OpenAI API兼容
class ChatCompletionRequest(BaseModel):model: strmessages: listmax_tokens: int = 1024temperature: float = 0.1# 第四步,定義交互函數
def chat_handle(messages: list, max_tokens: int, temperature: float):query = messages[0]["content"]response, history = model.chat(tokenizer,query=query,history=None,top_p=1,max_new_tokens=max_tokens,temperature=temperature)print(response)return response# 第五步,定義路由和處理函數,與OpenAI的API兼容
@app.post("/v1/chat/completions")
async def create_chat_completion(request: ChatCompletionRequest):# 調用自定義的文本生成函數response = chat_handle(request.messages, request.max_tokens, request.temperature)return {"choices": [{"message": {"content": response}}],"model": request.model}# 第六步,啟動FastAPI應用,默認端口為8000
if __name__ == "__main__":uvicorn.run(app, host="0.0.0.0", port=9999)
uvicorn.run(app, host="0.0.0.0", port=9999) 這里的host和port注意一下:
- host="0.0.0.0",表示可以遠程訪問此服務,host="127.0.0.1",表示只能本地訪問。
- port=9999,默認端口為8000,也可以自定義一個端口。
運行服務:
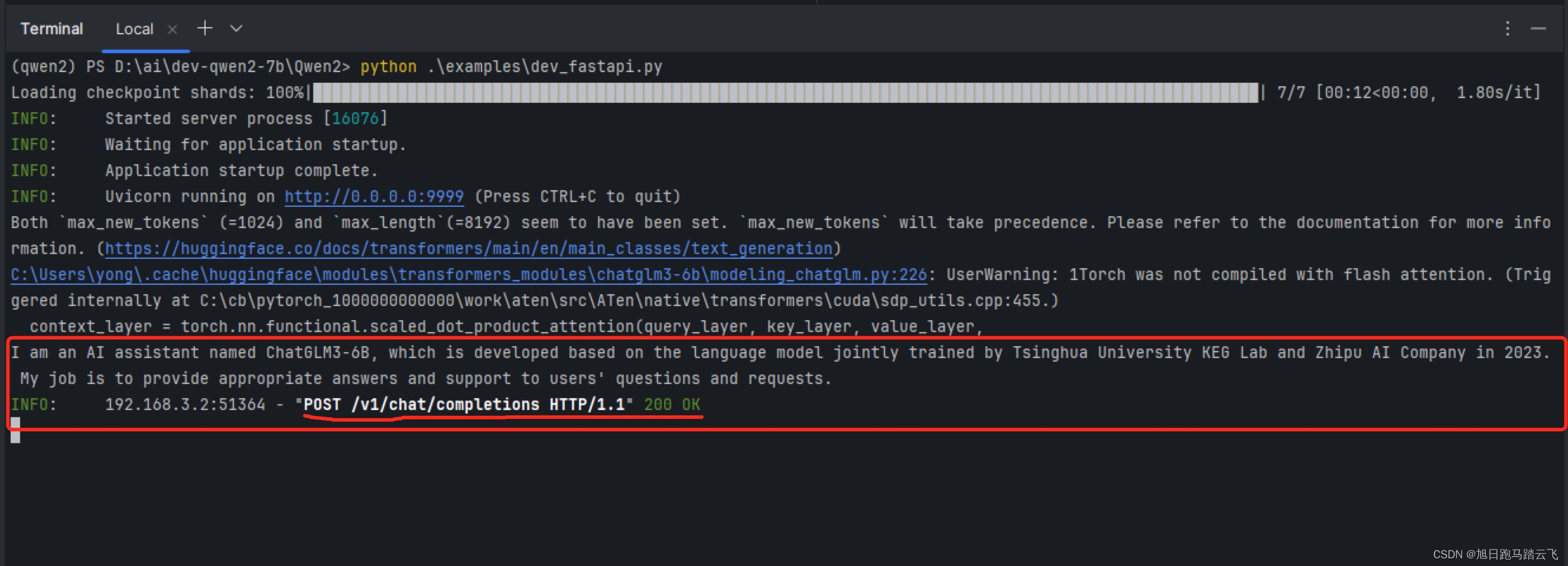
> python examples/dev_fastapi.py服務啟動輸出:
 表示服務已經啟動。
表示服務已經啟動。
2.2 客戶端調用
2.2.1 通過命令和工具調用
當服務端啟動后,可以通過各種客戶端工具來調用,比如curl,這里使用postman。

可以看到服務端正確返回了。
查看服務端輸出:
2.2.2 通過代碼調用
import requests
import json# 定義請求的URL
url = "http://192.168.3.154:9999/v1/chat/completions"# 定義請求頭
headers = {'Content-Type': 'application/json'}# 定義請求體
data = {"model": "qwen2-7b","messages": [{"role": "user", "content": "who are you?"}],"max_tokens": 1024,"temperature": 0.5
}
# 將字典轉換為JSON格式
data_json = json.dumps(data)# 發送POST請求
response = requests.post(url, headers=headers, data=data_json)# 檢查響應狀態碼
if response.status_code == 200:# 如果響應成功,打印響應內容print(response.json())
else:# 如果響應失敗,打印錯誤信息print(f"Error: {response.status_code}, {response.text}")
運行命令:
> python examples/dev_fastapi_client.py查看客戶端調用結果:

查看服務端輸出:
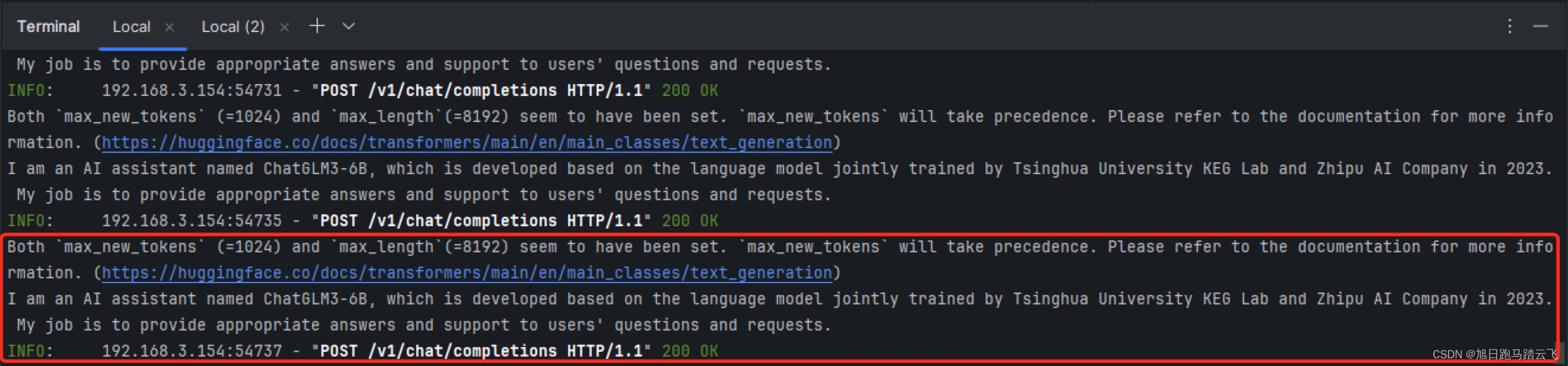













——ProgressiveMediaPeriod)





