這是一篇既照顧入門也能給高級工程師提供落地經驗的實戰筆記。
0. TL;DR(先上結論)
- 想穩:
acks=all+ 合理retries;需要“分區內不重不丟”→ 再加enable.idempotence=true且max.in.flight<=5。 - 想快:適度增大
batch.size與linger.ms,開啟compression=zstd,若可丟用acks=0。 - 想一致:跨分區/主題要“要么全成要么全不成”→ 用事務(
transactional.id),消費端read_committed。 - 不確定怎么配?先跑 Demo 看數據:
lesson_three/web_demo頁面支持一鍵預設、分區直方圖、吞吐歷史。
讀者畫像
- 初學者:只需看“工作流程概覽”“QoS 選型”“10 分鐘上手”,再跑 Web Demo。
- 高級工程師:關注“參數建議表”“常見坑”“生產就緒清單”“實戰案例”“調優路線”。
你將收獲
- 對 acks/冪等/事務/批量/壓縮的“白話”理解,知道各自代價與邊界。
- 一套可直接投產的默認配置與檢查清單。
- 可視化 Demo:改參數→立刻看到吞吐、分區分布、樣本偏移。
0.5 10 分鐘上手路線
- 啟動本地 Kafka,或將
KAFKA_BOOTSTRAP指到你的集群。 - 運行 Web Demo:
uvicorn lesson_three.web_demo.main:app --reload
- 瀏覽器打開
http://127.0.0.1:8000:- 點頂部卡片一鍵預設(吞吐/可靠/同 key 同分區)
- 看右側:JSON 結果、分區直方圖、吞吐歷史
通過 Demo 先把“感覺”建立起來,再回到本文查概念與參數細節。
1. 工作流程概覽
- 攔截器(可選) → 統一埋點/改寫消息
- 序列化器 → key/value 轉字節
- 分區器 → 選擇分區(同 key 同分區;無 key 用粘性分區器優化批量)
- 累加器 RecordAccumulator → 組成批(
batch.size/linger.ms/flush()觸發) - Sender 線程 → 取批、發往分區 leader
- Broker → 寫 leader 日志;按 acks 等待副本
- 回調/Future → 成功或異常
Producer 默認異步:
send()立即返回 Future;同步語義通常是對 Futureget()或使用回調。
2. ACK 機制(acks)
acks=0:不等響應,最快,可能丟。acks=1:leader 寫入就回,leader 掉線時可能丟。acks=all/-1:等 ISR 最小副本集合確認,最強持久性。
冪等/事務要求
acks=all。
小貼士(為啥):
acks=0不等任何確認,延遲最低但可能丟;適合可丟日志。acks=1等 leader,leader 掛時可能丟;適合對“極偶發丟失”容忍的業務。acks=all等同步副本,可靠但更慢;配合冪等/事務才能保證語義。
3. 批量、壓縮、異步
- 批量:
batch.size(單分區批字節上限)、linger.ms(積攢時延)。常用:batch.size=32–128KB,linger.ms=5–20ms。 - 壓縮:
compression.type=zstd|lz4|snappy|gzip(推薦 zstd)。 - 異步:默認異步;需要“業務確認” → 回調或
flush()/get()。
怎么配(經驗法則):
- 低延遲接口:
linger.ms<=5,batch.size32–64KB。 - 高吞吐埋點:
linger.ms=10–20,batch.size=64–128KB,compression=zstd。 - 網絡吃緊:優先開壓縮;CPU 緊張則降級
gzip/none。
4. 冪等性生產者
- 開啟:
enable.idempotence=true+acks=all - 建議:
max.in.flight.requests.per.connection<=5(保守有序),允許retries - 語義:分區內 Exactly-once(防重復)
為什么需要:
- 普通重試會導致同一分區重復寫;冪等用序號去重,避免“多扣一次款”“重復觸發”。
- 注意它只保證“分區內”恰一次;跨分區一致性需要事務。
5. 事務性生產者
- 目標:跨分區/主題的一致性(要么全成要么全不成)
- 配置:
transactional.id=<穩定唯一>(自動啟用冪等) - 流程:
initTransactions()→beginTransaction()→ 多次produce()→commitTransaction()/abortTransaction() - 消費端:
isolation.level=read_committed才只讀到已提交數據
使用時機:跨分區/多主題的原子寫入(訂單主表 + 變更日志、狀態轉換流水)。
代價:更高延遲、更多狀態管理;失敗路徑必須 abort_transaction()。
6. QoS(服務質量)解析
Kafka 不用 MQTT 的“QoS 0/1/2”叫法,但可用配置實現三種常見語義:最多一次 / 至少一次 / 恰一次。
6.1 語義與取舍
| 語義 | 定義 | 典型場景 | 風險/成本 |
|---|---|---|---|
| 最多一次 (At-most-once) | 可能丟,不重復 | 海量日志、低價值埋點 | 可靠性低,但延遲/吞吐最好 |
| 至少一次 (At-least-once) | 不丟,可重復 | 訂單事件、賬務(下游冪等) | 需去重;可能亂序 |
| 恰一次 (Exactly-once) | 不丟不重 | 強一致流水、跨主題雙寫 | 復雜度/開銷更高 |
6.2 參數映射(Python confluent-kafka)
決策速查:
- 可丟?→ 最多一次(吞吐優先)
- 不可丟,但可重放?→ 至少一次(下游去重)
- 不丟不重?→ 分區內冪等;跨分區需要事務 + read_committed
A. 最多一次(吞吐/時延優先)
conf = {"bootstrap.servers": "localhost:9092","acks": "0","enable.idempotence": False,"retries": 0,"compression.type": "zstd","linger.ms": 20,"batch.size": 128 * 1024,"max.in.flight.requests.per.connection": 8,
}
B. 至少一次(可靠優先,允許重復)
conf = {"bootstrap.servers": "localhost:9092","acks": "all","enable.idempotence": False, # 保持“至少一次”"compression.type": "zstd","linger.ms": 10,"batch.size": 64 * 1024,"request.timeout.ms": 30000,"delivery.timeout.ms": 120000,"retries": 2147483647, # 近似無限重試"max.in.flight.requests.per.connection": 6, # 吞吐高但可能亂序
}
C. 恰一次(分區內)
conf = {"bootstrap.servers": "localhost:9092","acks": "all","enable.idempotence": True, # 冪等"compression.type": "zstd","linger.ms": 10,"batch.size": 64 * 1024,"max.in.flight.requests.per.connection": 5, # 保守
}
D. 恰一次(事務,跨分區/主題)
from confluent_kafka import Producer, KafkaExceptionconf = {"bootstrap.servers": "localhost:9092","acks": "all","enable.idempotence": True,"transactional.id": "biz-tx-producer-001", # 穩定唯一"compression.type": "zstd","linger.ms": 10,
}
p = Producer(conf)
p.init_transactions()
try:p.begin_transaction()# ... 多次 p.produce()p.commit_transaction()
except KafkaException:p.abort_transaction()
finally:p.flush()
快速選型
-
可丟?→ 最多一次
-
不可丟,可重?→ 至少一次
-
不可丟不可重:
- 單分區/單主題→冪等
- 跨分區/多主題→事務(+
read_committed)
7. 參數建議表
| 參數 | 推薦/說明 |
|---|---|
acks | all(可靠);0/1(吞吐) |
enable.idempotence | true(防重復,分區內恰一次) |
transactional.id | 需要事務時設置穩定唯一值 |
linger.ms | 5–20ms(攢批) |
batch.size | 32–128KB |
compression.type | zstd |
max.in.flight.requests.per.connection | ≤5(配合冪等/順序) |
delivery.timeout.ms | 120000(端到端交付窗口) |
request.timeout.ms | 30000 |
8. Python 代碼示例
8.1 冪等生產(非事務)
from confluent_kafka import Producer
import socketconf = {"bootstrap.servers": "localhost:9092","client.id": socket.gethostname(),"acks": "all","enable.idempotence": True,"compression.type": "zstd","linger.ms": 10,"batch.size": 64 * 1024,"max.in.flight.requests.per.connection": 5,
}producer = Producer(conf)def dr_cb(err, msg):if err:print("Delivery failed:", err)else:print(f"Delivered to {msg.topic()}[{msg.partition()}]@{msg.offset()}")for i in range(100):producer.produce("demo-topic", key=f"k-{i%10}", value=f"v-{i}", on_delivery=dr_cb)producer.flush()
8.2 事務性生產
from confluent_kafka import Producer, KafkaExceptionconf = {"bootstrap.servers": "localhost:9092","acks": "all","enable.idempotence": True,"transactional.id": "order-tx-producer-001","compression.type": "zstd","linger.ms": 10,
}p = Producer(conf)
p.init_transactions()try:p.begin_transaction()for i in range(10):p.produce("orders", key=f"order-{i}", value=f"created-{i}")p.produce("orders-changelog", key=f"order-{i}", value=f"log-{i}")p.commit_transaction()
except KafkaException as e:p.abort_transaction()raise
finally:p.flush()
9. 實踐建議 & 常見坑
- 可靠性:
acks=all+min.insync.replicas>=2+replication.factor>=3;禁用unclean.leader.election。 - 順序與吞吐:
max.in.flight越大吞吐越高但更易亂序;冪等場景≤5更穩。 - 重試與時限:
delivery.timeout.ms控制“最終失敗”窗口;與retries/request.timeout.ms搭配。 - 監控:
record-send-rate、request-latency-avg、record-retry-rate、record-error-rate、compression-rate-avg、批大小均值等。 - 不要混用語義:冪等+acks=1/0 無法保證語義;事務端若消費端沒開
read_committed仍會讀到未提交。 - 熱點分區:同一個/少量 key 寫入過多導致傾斜;用“主鍵+鹽值”或更均勻的 key;需要有序時結合復合 key 但保留可聚合性。
- 壓縮依賴缺失:
snappy/lz4/zstd未安裝會觸發錯誤;本倉庫已做降級/回退,生產環境記得安裝依賴。 - IPv6 坑:macOS 上
localhost解析為::1可能連不上,用127.0.0.1或設置KAFKA_BOOTSTRAP。
10. 使用本倉庫封裝(kafka-python)快速上手
本倉庫
lesson_three/common.py封裝了穩健默認值,便于快速演示與接入。適合需要直接跑通的同學。
from lesson_three.common import make_producer, warmup_producer, close_safely
from datetime import datetimetopic = "demo.producer"
producer = make_producer(acks="all", # 可靠linger_ms=10, # 攢批batch_size=64 * 1024,compression_type="gzip", # 默認無需額外依賴;可換 zstd
)try:warmup_producer(producer, topic)for i in range(10):producer.send(topic,key=f"user-{i % 3}",value={"ts": datetime.now().isoformat(), "i": i},)producer.flush()
finally:close_safely(producer)
說明:該封裝基于 kafka-python,不提供“冪等/事務”語義;若需事務/冪等,請使用上文的 confluent-kafka 示例。
11. 典型業務場景 → 推薦配置映射
| 場景 | 目標 | 關鍵配置 | 備注 |
|---|---|---|---|
| 海量埋點/日志 | 吞吐與成本優先,可容忍少量丟失 | acks=0,compression=zstd,linger.ms=20,batch.size=128KB | 服務器端配合更高批量、異步落庫 |
| 訂單事件(允許重復) | 不丟但可重復 | acks=all,enable.idempotence=false,retries≈∞,delivery.timeout.ms=120s | 下游按業務鍵去重;max.in.flight 可放寬到 6–8 |
| 單分區強一致流水 | 分區內“恰一次” | acks=all,enable.idempotence=true,max.in.flight<=5 | 同一業務鍵路由到同一分區,避免跨分區一致性 |
| 跨主題雙寫(訂單+變更日志) | 跨分區/主題一致 | transactional.id 唯一、開啟事務;消費端 read_committed | 失敗時必須 abort_transaction() |
| IoT 傳感器高頻上報 | 延遲敏感、可容忍丟失 | acks=0/1,linger.ms<=5,compression=zstd | 批量不要過大,避免尾延遲 |
12. 生產就緒檢查清單(Checklist)
- 集群與主題
- 確認
replication.factor>=3、min.insync.replicas>=2 - 關閉
unclean.leader.election - 針對大消息配置
message.max.bytes與replica.fetch.max.bytes
- 確認
- Producer 端
- 可靠性:
acks=all+ 合理retries/delivery.timeout.ms - 順序:冪等場景將
max.in.flight.requests.per.connection<=5 - 吞吐:合理設置
batch.size與linger.ms,開啟compression.type=zstd - 觀測:埋點回調錯誤率、平均批大小、壓縮率、請求時延
- 可靠性:
- 事務流
transactional.id穩定唯一且可恢復- 失敗路徑必須
abort_transaction(),并處理補償邏輯 - 消費側開啟
isolation.level=read_committed
- 運維監控
- 指標:
record-send-rate、record-error-rate、request-latency-avg、record-retry-rate - Lag 監控與告警;主題分區熱點檢查
- 指標:
13. 實戰案例
案例 A:訂單創建 + 變更日志雙寫(事務)
需求:訂單主數據寫 orders,同時寫審計 orders-changelog,兩者必須同時成功或同時失敗。
關鍵點:使用事務性生產者;消費側使用 read_committed;失敗路徑 abort_transaction()。
from confluent_kafka import Producer, KafkaExceptionconf = {"bootstrap.servers": "localhost:9092","acks": "all","enable.idempotence": True,"transactional.id": "order-tx-producer-001","compression.type": "zstd",
}p = Producer(conf)
p.init_transactions()try:p.begin_transaction()p.produce("orders", key="order-1001", value="created")p.produce("orders-changelog", key="order-1001", value="audit-created")p.commit_transaction()
except KafkaException:p.abort_transaction()raise
finally:p.flush()
案例 B:埋點日志高吞吐上報(最多一次)
目標:極致吞吐與成本,允許少量丟失。
建議:acks=0、compression=zstd、linger.ms=20、batch.size=128KB。
from confluent_kafka import Producerconf = {"bootstrap.servers": "localhost:9092","acks": "0","compression.type": "zstd","linger.ms": 20,"batch.size": 128 * 1024,
}p = Producer(conf)
for i in range(100000):p.produce("tracking", value=f"event-{i}")
p.flush()
需要的話,我可以把這篇再導成 Markdown 文件或加一頁“參數對照速查卡”。
14. 在線 HTML 演示(本地運行)
為了直觀理解
acks/批量/壓縮/key對分區與吞吐的影響,提供了一個極簡的網頁 Demo(基于 FastAPI)。
目錄:lesson_three/web_demo
- 安裝依賴(建議虛擬環境)
pip install fastapi uvicorn kafka-python pydantic
- 啟動 Demo(默認 http://127.0.0.1:8000)
uvicorn lesson_three.web_demo.main:app --reload
- 打開瀏覽器訪問,填寫參數并發送
http://127.0.0.1:8000/
說明:
- 后端復用本倉庫
lesson_three/common.py的make_producer/warmup_producer封裝。 - 該 Demo 基于
kafka-python,用于直觀理解批量/壓縮/QoS 的實際效果。 - 如需“冪等/事務”語義,請參考上文
confluent-kafka示例。
15. Web Demo 實驗手冊(一步步做)
實驗前提:已按第 14 節啟動 Demo,瀏覽器打開 http://127.0.0.1:8000/。
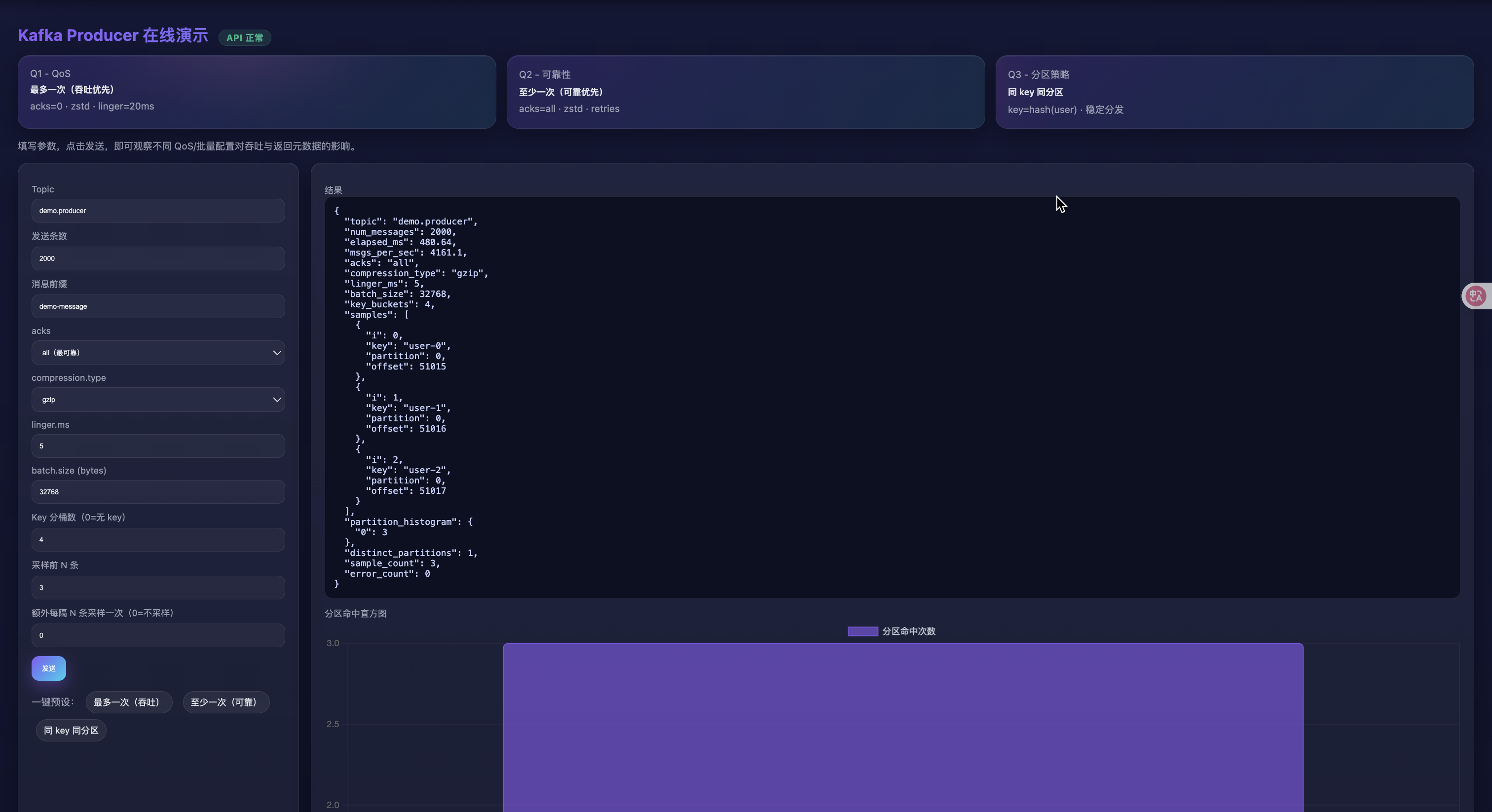
- 同 key 同分區(驗證分區器)
- 設置:
acks=all、key 分桶數=4、num_messages=1000、其他默認 - 觀察:返回 JSON 的
samples中相同key的partition應保持一致;partition_histogram會顯示命中的分區與次數。
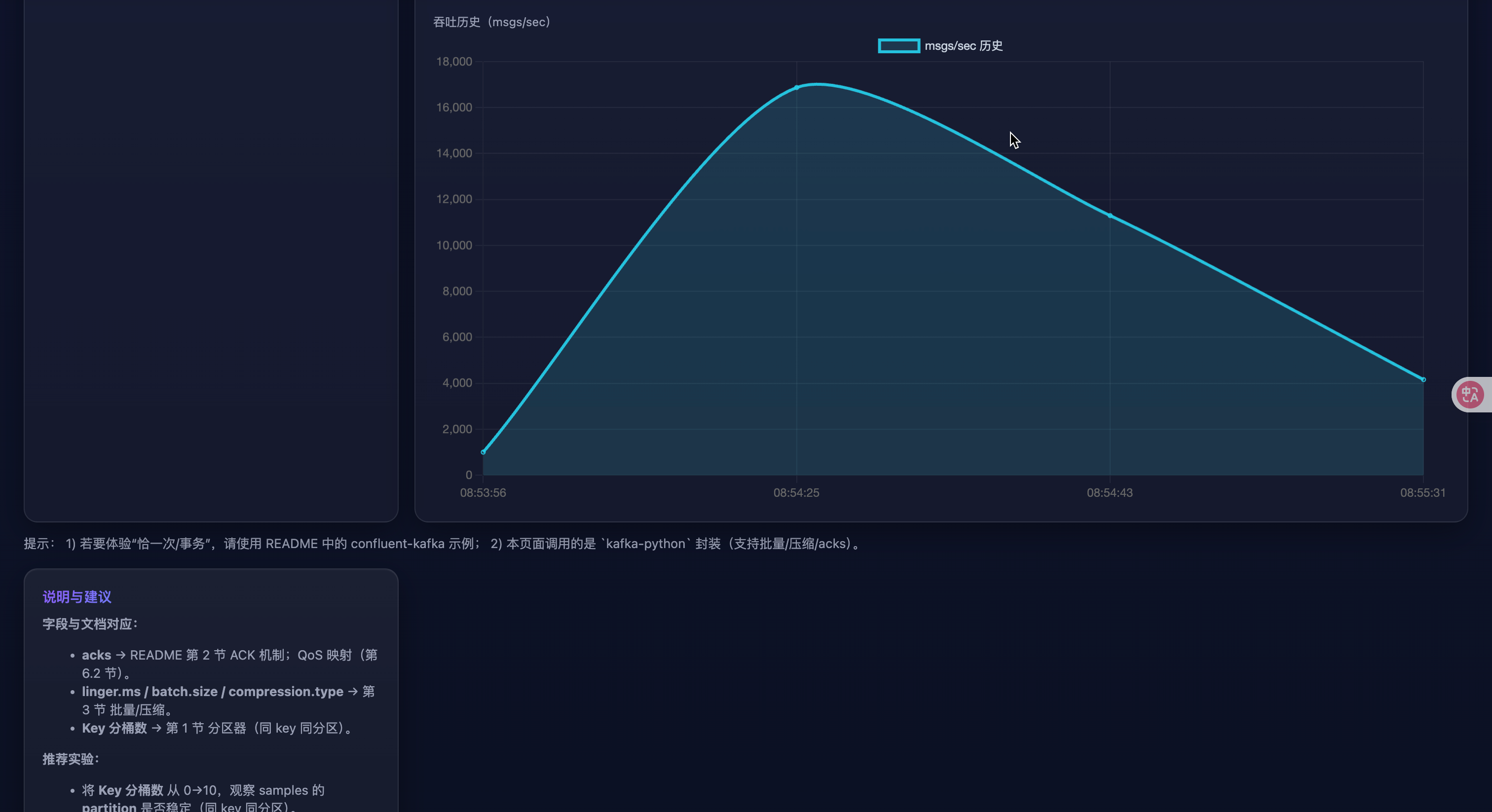
- 攢批換吞吐(驗證 batch/linger)
- 對比 A:
linger.ms=0、batch.size=32768與 B:linger.ms=20、batch.size=131072 - 觀察:B 的
msgs_per_sec通常更高,但elapsed_ms可能略大(延遲換吞吐)。
- 壓縮算法對比(網絡 vs CPU)
- 依次選擇
compression.type=none/gzip/zstd(消息量 10000+ 更明顯) - 觀察:
zstd在網絡瓶頸場景下吞吐更優;若 CPU 緊張,可能gzip/none更穩。
- 可靠性與時延取舍(acks)
- 對比:
acks=0、acks=1、acks=all - 觀察:acks 越強,
elapsed_ms越大;在 broker 異常時,acks=all可能返回錯誤或顯著變慢,acks=0“更快但有風險”。
- 分區傾斜(熱點 key)
- 設置:
key 分桶數=2,num_messages=5000 - 觀察:
partition_histogram若某分區遠高于其他分區,說明出現熱點,需優化 key 設計(見第 17 節)。
返回結果字段說明(來自 /api/send):
elapsed_ms:端到端發送耗時;msgs_per_sec:估算吞吐samples[]:采樣若干條寫入結果(含key/partition/offset或error)partition_histogram:采樣命中分區的計數直方圖distinct_partitions:命中的唯一分區數sample_count / error_count:采樣條數與失敗數
16. Web Demo 故障排查
-
API 返回非 JSON,頁面提示
Unexpected token 'I' ...:- 原因:后端 500 錯誤被瀏覽器當作文本解析。已在 Demo 中統一返回 JSON 錯誤并在前端降級顯示文本;若仍出現,請查看
uvicorn控制臺日志。
- 原因:后端 500 錯誤被瀏覽器當作文本解析。已在 Demo 中統一返回 JSON 錯誤并在前端降級顯示文本;若仍出現,請查看
-
Kafka 連不通或超時:
- 確認本地/遠端 Kafka 已啟動;必要時導出
KAFKA_BOOTSTRAP環境變量(建議127.0.0.1:9092避免 IPv6 解析)。 - 端口占用或網絡策略限制時,優先用 IP 而非
localhost。
- 確認本地/遠端 Kafka 已啟動;必要時導出
-
壓縮算法不可用:
kafka-python對snappy/lz4/zstd需要額外依賴;若未安裝會拋出斷言錯誤。Demo 將返回 500。- 解決:改用
gzip/none,或安裝對應壓縮庫(如pip install python-snappy lz4 zstandard)。
-
分區/偏移不顯示:
acks=0時無確認,不保證返回元數據;改用acks=1/all驗證。
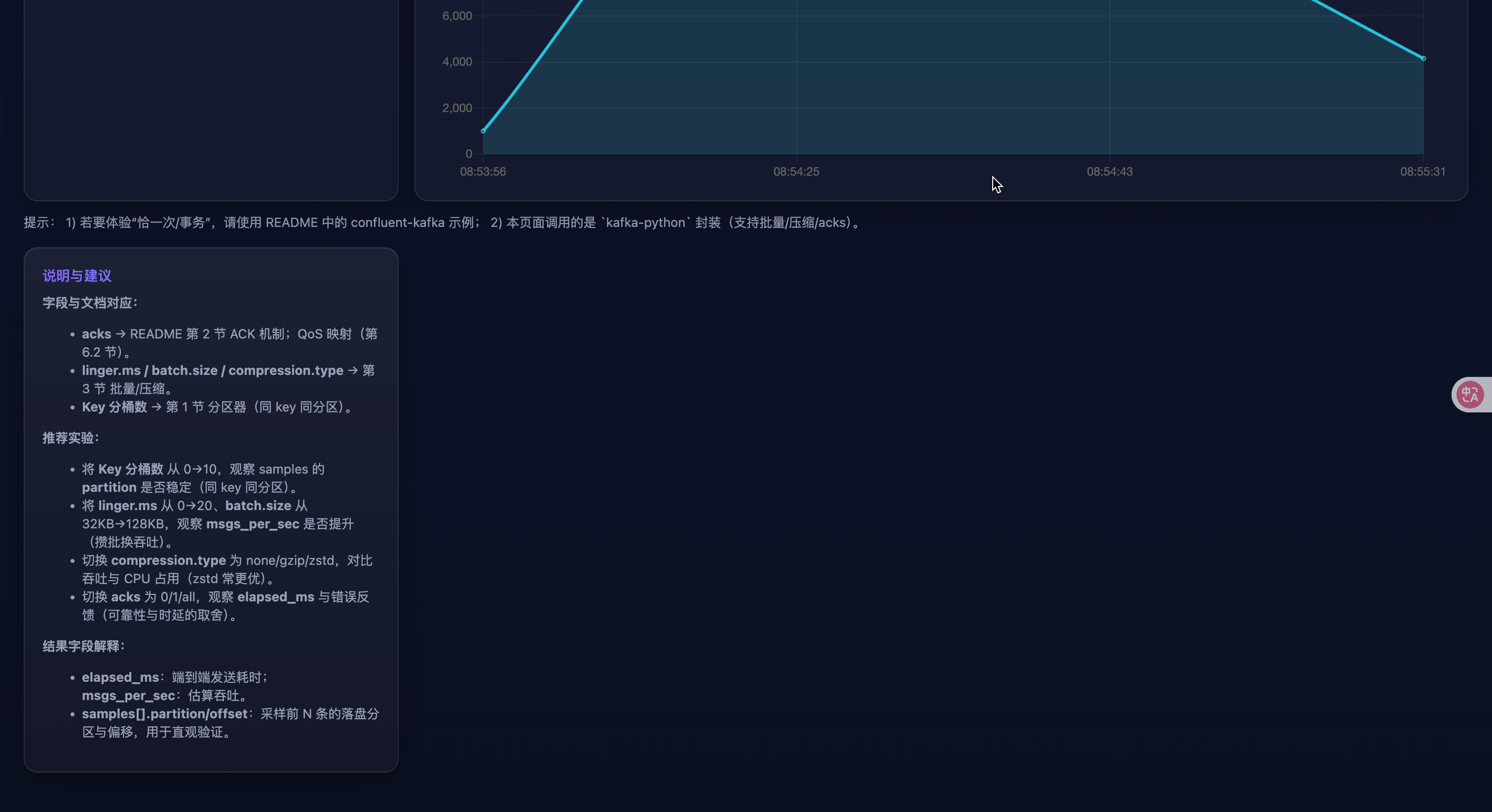
17. 生產者實踐技巧(落地經驗)
-
Key 設計與傾斜治理:
- 盡量使用業務主鍵或其哈希作為 key,保證同一實體有序且分散。
- 發現
partition_histogram傾斜時,可引入“復合 key(主鍵 + 鹽值)”、時間片打散,或增加分區數并配合再均衡。
-
壓縮選型:
- 優先
zstd(壓縮率/速度折中好);CPU 緊張或未裝依賴時可退回gzip。 - 關注
compression-rate-avg與端側 CPU 使用率,動態調參。
- 優先
-
順序與吞吐:
- 需要“分區內有序”且冪等 →
enable.idempotence=true+acks=all+max.in.flight<=5(在 confluent-kafka 中配置)。 - 追求吞吐 → 放寬
max.in.flight,增大batch.size,增加linger.ms。
- 需要“分區內有序”且冪等 →
-
超時與重試:
delivery.timeout.ms定義“最終失敗”窗口;與request.timeout.ms、retries配合使用。- 監控
record-retry-rate、record-error-rate,排查網絡抖動或 ISR 不足。
-
批大小與內存:
batch.size是單分區批上限;過大可能增加尾延遲與內存占用。- 搭配
linger.ms小步調優,觀察平均批大小與 99 線時延。
-
監控指標(建議接入可視化):
- 發送速率、請求時延、重試/錯誤率、平均批大小、壓縮率、每分區寫入速率;結合消費端
lag與分區熱點。
- 發送速率、請求時延、重試/錯誤率、平均批大小、壓縮率、每分區寫入速率;結合消費端
A. 術語小抄(Glossary)
- Producer:生產者客戶端,負責寫消息到 Kafka。
- RecordAccumulator:客戶端側的分區批緩沖區,受
batch.size/linger.ms影響。 - Partition:主題的分片;同一分區內寫入有序。
- Key(分區鍵):哈希后決定分區;同 key 同分區,便于聚合與有序。
- Sticky Partitioner:無 key 時使用的“粘性分區器”,提升批量效率。
- acks:寫入確認級別(0/1/all);越強越可靠,延遲越大。
- ISR(In-Sync Replicas):與 leader 同步的副本集合。
- Idempotent Producer:冪等生產者;分區內 Exactly-once(不重復)。
- Transactional Producer:事務生產者;跨分區/主題的原子性(要么全成)。
- EOS(Exactly-once Semantics):恰一次語義;分區內靠冪等,跨分區靠事務+
read_committed。 batch.size:單分區批上限字節;越大吞吐越高、尾延遲越高。linger.ms:攢批等待時間;增大可提升吞吐、增加延遲。max.in.flight.requests.per.connection:同連接并行請求數;大→吞吐高但易亂序。compression.type:壓縮算法(zstd/gzip/snappy/lz4/none)。delivery.timeout.ms:端到端交付窗口(超過視為失敗)。request.timeout.ms:單次請求超時。replication.factor:副本數;min.insync.replicas:可寫入需要的最小同步副本。unclean.leader.election:是否允許非同步副本選主;生產禁用以防數據倒退。read_committed:消費者只讀已提交的事務消息。- Lag:消費者相對最新偏移的滯后量。
B. 常見問題(FAQ)
Q1:acks=all 還可能丟嗎?
- 會的:當
replication.factor太小、min.insync.replicas設置不當或啟用了unclean.leader.election時,發生失敗切換可能導致丟失或倒退。生產建議:replication.factor>=3、min.insync.replicas>=2、禁用unclean.leader.election。
Q2:冪等就是全局恰一次嗎?
- 不是。冪等僅保證“分區內”不重復。跨分區/主題要恰一次需要事務,并在消費端打開
read_committed。
Q3:事務和冪等的關系?
- 事務會自動啟用冪等。冪等解決“分區內重復”,事務解決“跨分區原子性”。
Q4:吞吐很低怎么辦?
- 增大
batch.size與linger.ms,開啟compression=zstd;檢查網絡/磁盤瓶頸;放寬max.in.flight(非冪等場景)。
Q5:延遲太高怎么辦?
- 降低
linger.ms,適度減小batch.size;必要時用acks=1(權衡可靠性)。
Q6:為什么看到亂序?
- 重試 +
max.in.flight過大易亂序;冪等場景收斂到<=5;同 key 才能談“有序”。
Q7:如何判斷分區熱點?
- 觀察分區寫入速率、消費者 Lag 與本文 Web Demo 的
partition_histogram。熱點時優化 key(主鍵+鹽值/復合 key)或擴分區并再均衡。
Q8:壓縮用什么?
- 優先
zstd;CPU 緊張或依賴安裝困難時退gzip;網絡空閑時可暫不開啟。
Q9:KafkaTimeoutError: Timeout after waiting for 30 secs. 怎么辦?
- 多為連不通或 topic 不存在。優先使用 IPv4:
KAFKA_BOOTSTRAP=127.0.0.1:9092,確認kafka-topics.sh --create --topic <name>已創建;重啟 Demo 后再試。
Q10:Demo 為什么 acks=0 時 sample 沒有分區/偏移?
- 因為不等待確認,客戶端未必拿到元數據。以吞吐/耗時評估即可,驗證分區請改用
acks=1/all。




![【python實用小腳本-205】[HR揭秘]手工黨逐行查Bug的終結者|Python版代碼質量“CT機”加速器(建議收藏)](http://pic.xiahunao.cn/【python實用小腳本-205】[HR揭秘]手工黨逐行查Bug的終結者|Python版代碼質量“CT機”加速器(建議收藏))




——網絡連接場景的 C++ 實戰)





)
)


