一、引言
如今火爆的 GPT、LLaMA、通義千問、ChatGLM 等大語言模型,背后都離不開一個核心架構——Transformer。
2017 年,Google 在論文《Attention Is All You Need》中首次提出 Transformer 模型,徹底改變了自然語言處理的發展方向。它摒棄了傳統的循環結構(RNN/LSTM),完全依賴注意力機制實現高效、并行化的序列建模。

二、模型總覽:Encoder-Decoder 框架
論文提出的 Transformer 是一個典型的 Encoder-Decoder 結構,整體架構如下圖所示:
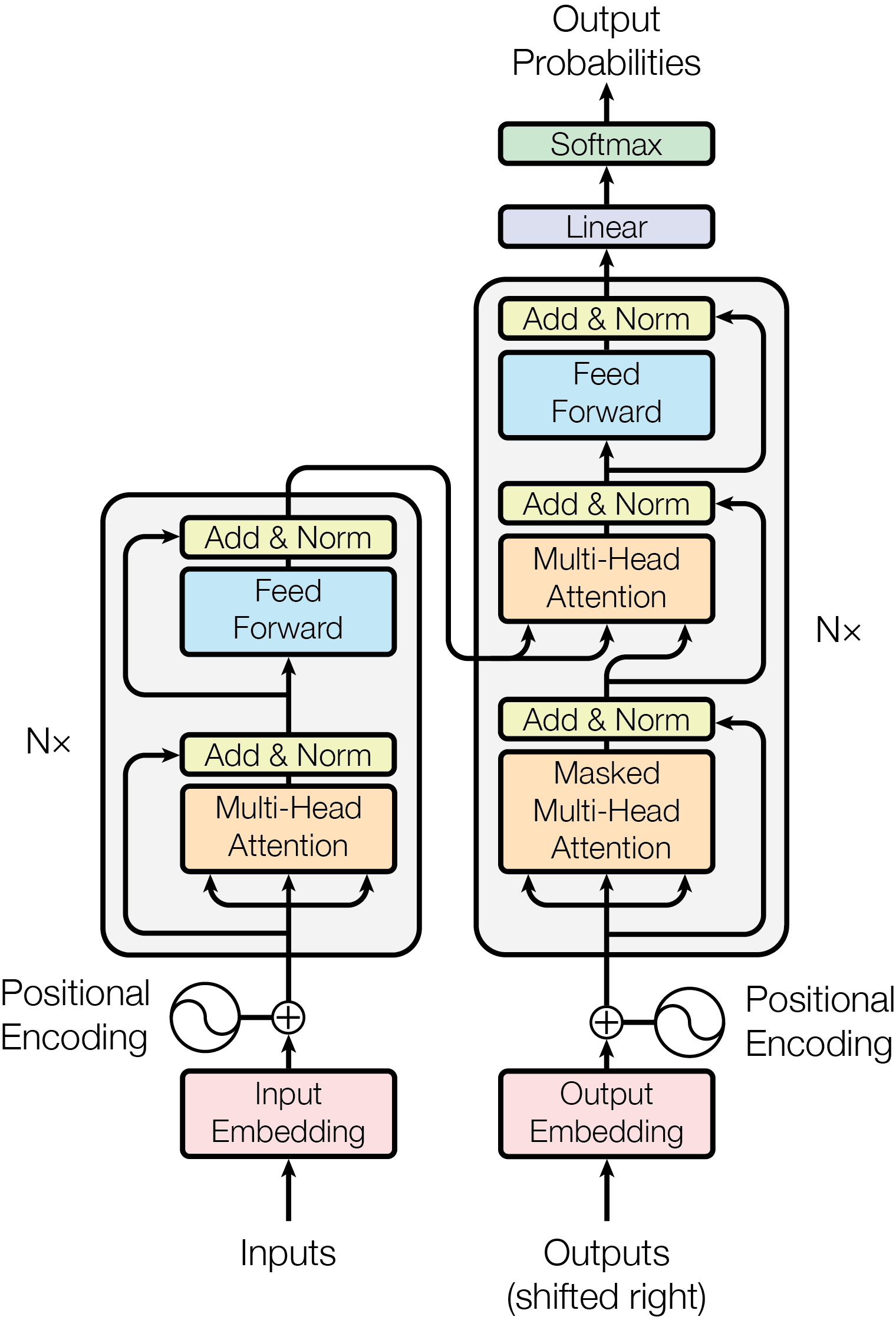
📌 圖1:Transformer 整體架構(源自論文 Fig.1)
🔹 Encoder:負責將輸入序列編碼為富含語義的表示。
🔹 Decoder:基于編碼結果,自回歸地生成輸出序列。
兩者均由 6 層相同結構的模塊堆疊而成,每一層都包含多頭注意力和前饋網絡。
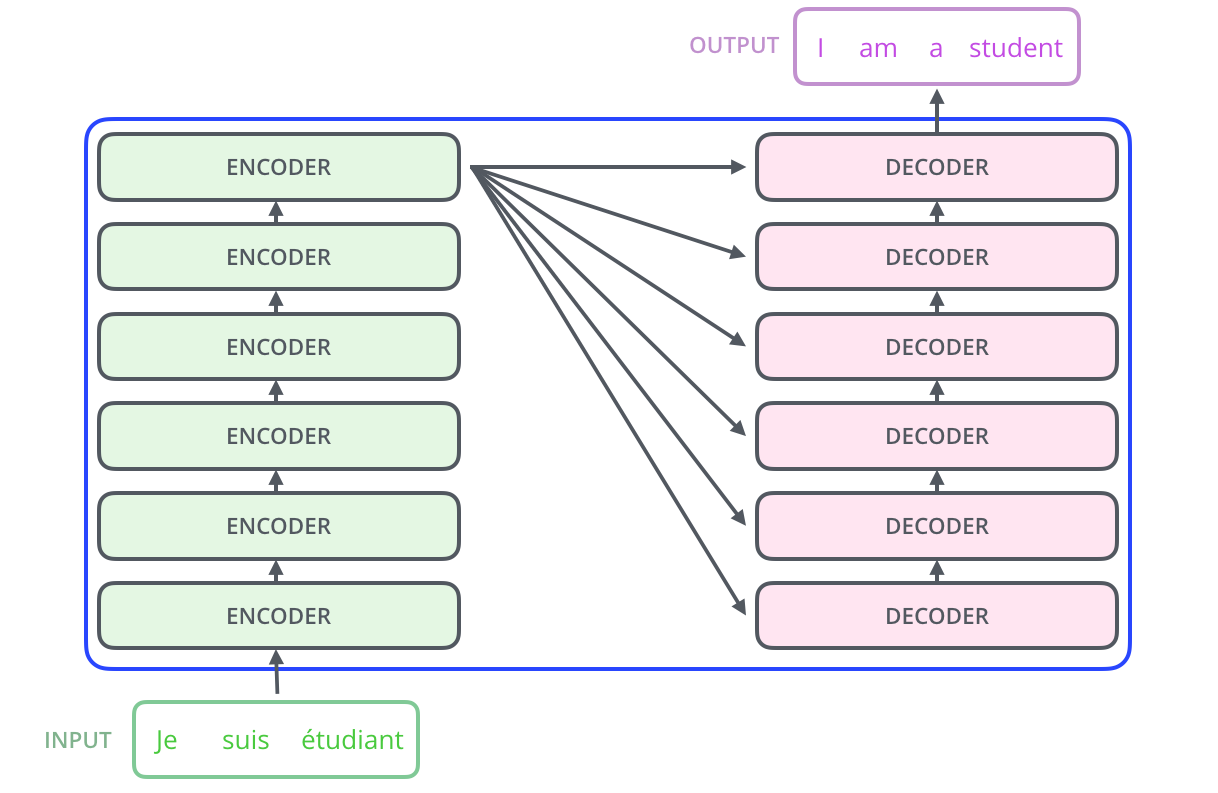
三、模型架構詳解(Model Architecture)
3.1 編碼器(Encoder)
每個編碼器層由兩個子層組成:
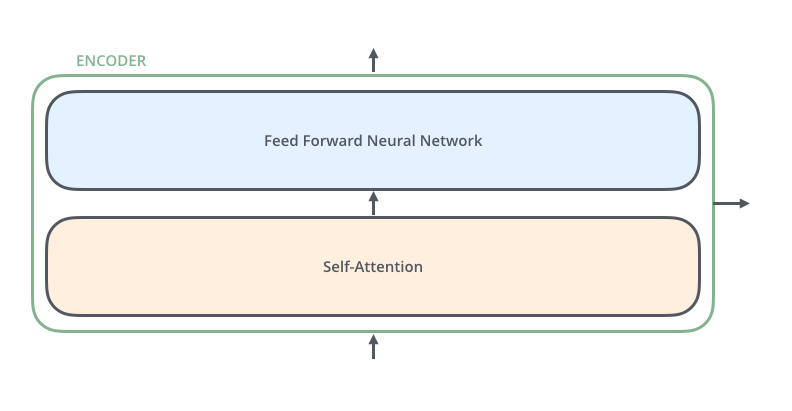
- 多頭自注意力機制(Multi-Head Self-Attention)
- 位置前饋網絡(Position-wise Feed-Forward Network, FFN)
-
每個子層后都有 殘差連接(Residual Connection) 和 層歸一化(LayerNorm):
由Transformer 結構組成的網絡結構通常都非常龐大。編碼器和解碼器均由很多層基本的Transformer塊組成,每一層中都包含復雜的非線性映射,這就導致模型的訓練比較困難。因此,研究人員在Transformer 塊中進一步引入了殘差連接與層歸一化技術,以進一步提升訓練的穩定性。具體來說,殘差連接主要是指使用一條直連通道直接將對應子層的輸入連接到輸出,避免在優化過程中因網絡過深而產生潛在的梯度消失問題。 -
所有層輸入輸出維度均為
d_model = 512
? 這種設計有助于梯度傳播,支持深層網絡訓練。
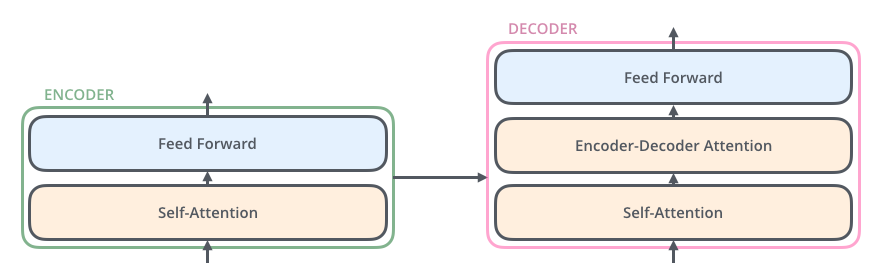
3.2 解碼器(Decoder)
解碼器結構更復雜一些,每層包含 三個子層:
- 掩碼多頭自注意力(Masked Multi-Head Self-Attention)
- 編碼器-解碼器注意力(Encoder-Decoder Attention)
- 位置前饋網絡(FFN)
流程如下:
🔹 為什么需要“掩碼”?
為了防止解碼時“偷看未來”。例如生成句子時:
“我 愛 吃 __”
模型在預測“吃”后面的詞時,不能看到后面的詞。因此使用 因果掩碼(Causal Mask),只允許關注當前位置及之前的位置。
掩碼矩陣示意(下三角):
[1, 0, 0, 0]
[1, 1, 0, 0]
[1, 1, 1, 0]
[1, 1, 1, 1]
3.3 注意力機制(Attention)
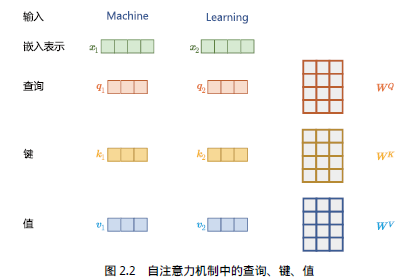
這是論文最核心的部分。標準注意力定義為:
Attention(Q,K,V)=softmax(QKTdk)V\text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)V Attention(Q,K,V)=softmax(dk??QKT?)V
其中:
- QQQ:Query,表示“我在找什么”
- KKK:Key,表示“我能被找到嗎”
- VVV:Value,表示“我提供什么信息”
通過 QKTQK^TQKT 計算相似度,softmax 歸一化后加權求和 VVV,得到輸出。
多頭注意力(Multi-Head Attention)
單次注意力可能只捕捉一種關系,因此論文提出“多頭”機制:
MultiHead(Q,K,V)=Concat(head1,...,headh)WO\text{MultiHead}(Q,K,V) = \text{Concat}(head_1, ..., head_h)W^O MultiHead(Q,K,V)=Concat(head1?,...,headh?)WO
其中每個 head 獨立計算:
headi=Attention(QWiQ,KWiK,VWiV)head_i = \text{Attention}(QW_i^Q, KW_i^K, VW_i^V) headi?=Attention(QWiQ?,KWiK?,VWiV?)
參數矩陣 WiQ,WiK,WiVW_i^Q, W_i^K, W_i^VWiQ?,WiK?,WiV? 不同,使每個 head 關注不同子空間的信息。
? 類比:多個專家從不同角度分析同一個問題,最后匯總決策。
?自注意力機制使模型能夠識別不同輸入部分的重要性,而不受距離的影響,從而
能夠捕捉輸入句子中的長距離依賴關系和復雜關系。
3.4 位置前饋網絡(Position-wise FFN)
前饋層接收自注意力子層的輸出作為輸入。
每個位置獨立通過一個兩層全連接網絡:
FFN(x)=max?(0,xW1+b1)W2+b2\text{FFN}(x) = \max(0, xW_1 + b_1)W_2 + b_2 FFN(x)=max(0,xW1?+b1?)W2?+b2?
通常設置為:d_model=512, d_ff=2048
雖然簡單,但它增強了模型的非線性表達能力。
四、詞嵌入與位置編碼(Embeddings & Positional Encoding)
4.1 詞嵌入(Token Embeddings)
輸入的每個詞先映射為 d_model 維的向量(如 512 維),與其他模型類似。
4.2 位置編碼(Positional Encoding)
由于 Transformer 沒有循環或卷積結構,無法感知詞序,因此必須顯式加入位置信息。具體來說,序列中每一個單詞所在的位置都對應一個向量。這一向量會與單詞表示對應相加并送入后續模塊中做進一步處理
論文使用正弦和余弦函數生成位置編碼:
PE(pos,2i)=sin?(pos100002i/dmodel)PE(pos,2i+1)=cos?(pos100002i/dmodel)PE_{(pos, 2i)} = \sin\left(\frac{pos}{10000^{2i/d_{\text{model}}}}\right) \\ PE_{(pos, 2i+1)} = \cos\left(\frac{pos}{10000^{2i/d_{\text{model}}}}\right) PE(pos,2i)?=sin(100002i/dmodel?pos?)PE(pos,2i+1)?=cos(100002i/dmodel?pos?)
這些編碼與詞嵌入相加,作為最終輸入:
Input=Word?Embedding+Positional?Encoding\text{Input} = \text{Word Embedding} + \text{Positional Encoding} Input=Word?Embedding+Positional?Encoding
? 優點:能表示相對位置,且可擴展到更長序列。
五、為什么 Transformer 能支撐大語言模型?
雖然原始 Transformer 是為機器翻譯設計的,但它的設計理念完美契合了大語言模型的需求:
| 特性 | 對大模型的意義 |
|---|---|
| 并行計算 | 可高效訓練千億參數模型 |
| 長距離依賴建模 | 能理解上下文數百詞外的信息 |
| 可堆疊性 | 層數越多,表達能力越強 |
| 注意力可視化 | 易于分析模型決策過程 |
現代大語言模型大多基于 Transformer 的變體:
| 模型類型 | 結構來源 | 典型代表 |
|---|---|---|
| Decoder-only | 僅保留解碼器 | GPT 系列、LLaMA、通義千問 |
| Encoder-only | 僅保留編碼器 | BERT、RoBERTa |
| Encoder-Decoder | 完整結構 | T5、BART |
🔹 GPT 就是典型的 Decoder-only 模型:去掉編碼器,僅用掩碼注意力進行自回歸生成。
六、總結:Transformer 的革命性意義
| 維度 | RNN/LSTM | CNN | Transformer |
|---|---|---|---|
| 并行性 | 差 | 中 | ? 極強 |
| 長程依賴 | 弱 | 一般 | ? 強 |
| 可解釋性 | 低 | 中 | ? 注意力可可視化 |
| 擴展性 | 有限 | 一般 | ? 支持超大規模 |
Transformer 的成功在于:
- 用注意力替代循環,實現高效并行
- 多頭機制 提升語義表達多樣性
- 位置編碼 解決順序感知問題
- 模塊化設計 易于擴展和改進
它不僅是 NLP 的里程碑,更是通向通用人工智能的重要一步。



介紹及使用)









實戰十八——圖像透視轉換)


:(十三)堆的應用)


