1、創建數據庫
語法:
CREATE DATABASE [IF NOT EXISTS] db_name [create_specification [,
create_specification] ...]
create_specification:
[DEFAULT] CHARACTER SET charset_name
[DEFAULT] COLLATE collation_name這里的CHARACTER SET表示指定數據庫采用的字符集
COLLATE 表示指定數據庫字符集的校驗規則
2、字符集和字符集校驗規則
字符集
字符集是一套符號和編碼的集合。它定義了數據庫可以存儲哪些字符,以及如何將這些字符轉換為二進制數據存儲到計算機中。
通俗解釋:
你可以把字符集想象成一本“密碼本”。這本密碼本規定了:
有哪些字符:比如字母?
A、a,中文?中,表情符號?😊?等。每個字符對應的編號(編碼)是什么:比如在?
ASCII?字符集中,字母?A?的編號是?65(二進制是?01000001)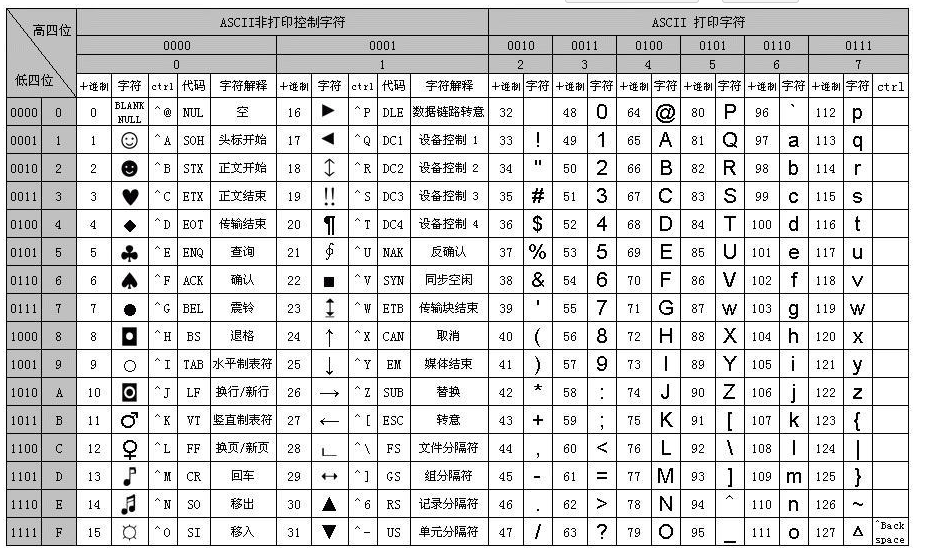
常見字符集:
ASCII:最早的英文字符集,包含英文字母、數字和一些控制字符,共128個字符。
ISO-8859-1 (Latin-1):擴展了 ASCII,加入了西歐語言字符,如?
?,??,???等。GB2312 / GBK / GB18030:中國國家標準,用于存儲簡體中文字符。GBK 是 GB2312 的擴展,GB18030 是更全面的擴展。
BIG5:繁體中文標準,主要用于臺灣、香港等地。
UTF-8:當今最重要的字符集。它是 Unicode 標準的一種可變長度實現,可以表示世界上幾乎所有語言的字符,包括大量表情符號和特殊符號。它是國際化的首選。
為什么重要?
如果字符集設置不正確,就會出現“亂碼”。例如,如果你用?GBK?編碼去解碼一段用?UTF-8?存儲的中文文本,顯示出來的就是一堆無法識別的字符。
字符集校驗規則
至于校驗規則是在字符集內,用于比較和排序字符的一套規則。它定義了字符如何被比較、排序以及是否區分大小寫和重音。
通俗解釋:
字符集定義了“有什么字”,而校驗規則定義了“這些字怎么排順序、怎么算相等”。
比如,有一組單詞:apple,?Apple,?Banana。
如果使用區分大小寫的校驗規則,排序可能是:
Apple,?Banana,?apple(根據 ASCII 碼,大寫字母在前)。如果使用不區分大小寫的校驗規則,排序可能是:
apple,?Apple,?Banana(a?和?A?被視為相同,按下一個字母排序)。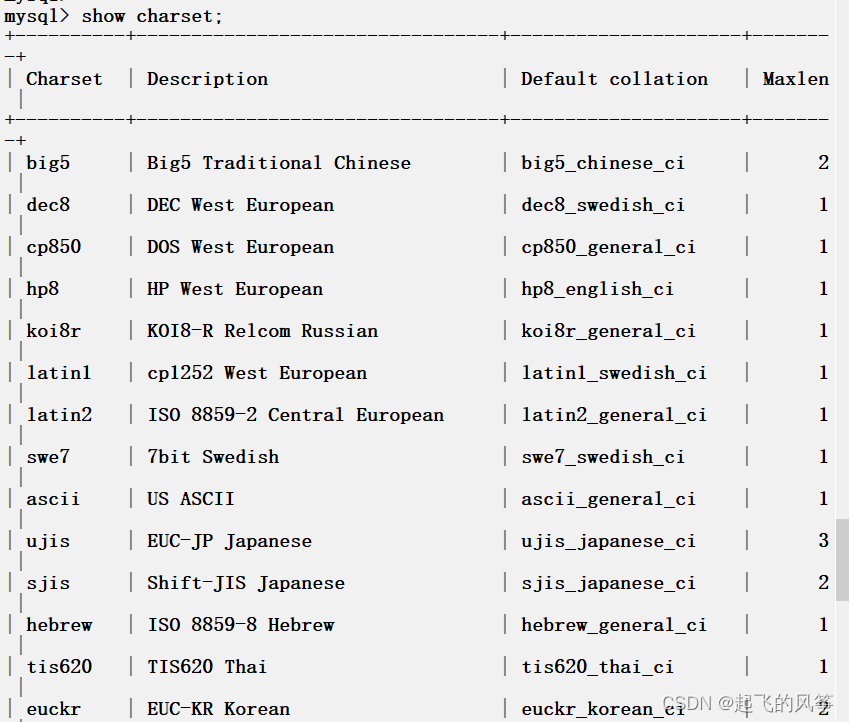
校驗規則通常包含以下信息:
是否區分大小寫(Case Sensitivity):
A?和?a?是否相同?_cs?(case sensitive):區分_ci?(case insensitive):不區分
是否區分重音(Accent Sensitivity):
a?和?á?是否相同?_as?(accent sensitive):區分_ai?(accent insensitive):不區分
其他規則,如是否區分空格等。
常見校驗規則(以 MySQL 的 utf8mb4 字符集為例):
utf8mb4_general_ci:一種較老的校驗規則,排序精度不高但速度快。不區分大小寫。utf8mb4_unicode_ci:基于 Unicode 標準進行排序和比較,能更準確地處理各種語言的排序(如德語中的??),速度稍慢。不區分大小寫。推薦使用。utf8mb4_0900_ai_ci:MySQL 8.0 引入的,基于更現代的 Unicode 9.0 標準,比?unicode_ci?更精確和高效。不區分重音,不區分大小寫。utf8mb4_bin:將每個字符直接根據其二進制編碼進行比較。這意味著它區分大小寫和重音。A?(0x41) 和?a?(0x61) 是不同的。
具體使用
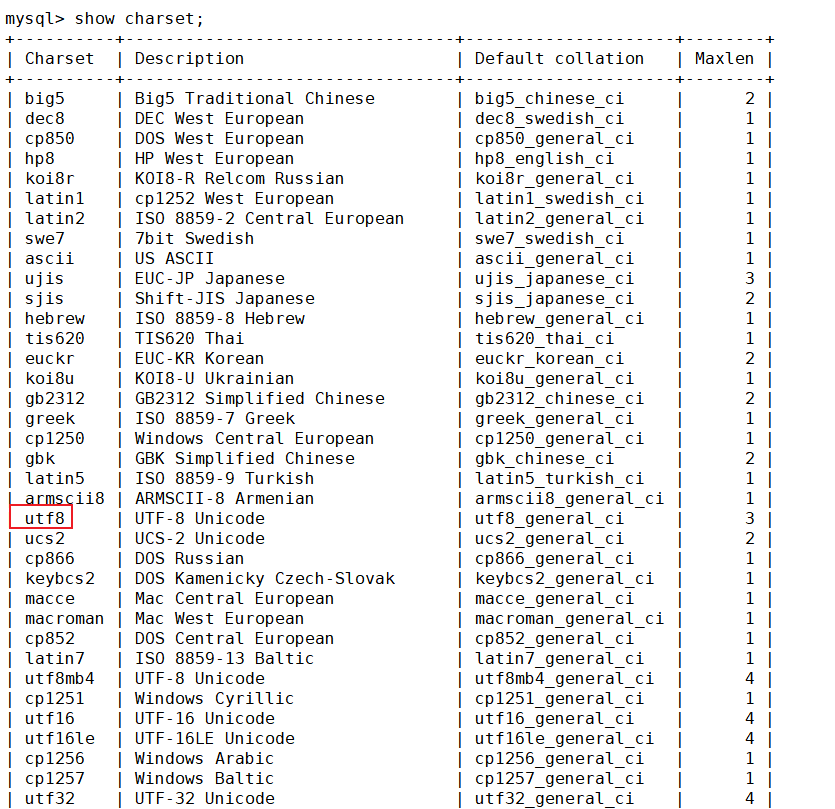
先來看看MySQL數據庫都支持哪些字符集和校驗規則
查看數據庫支持的字符集
show charset;這是表格一部分,可以在其中找到utf8字符集
查看數據庫支持的字符集校驗規則
show collation;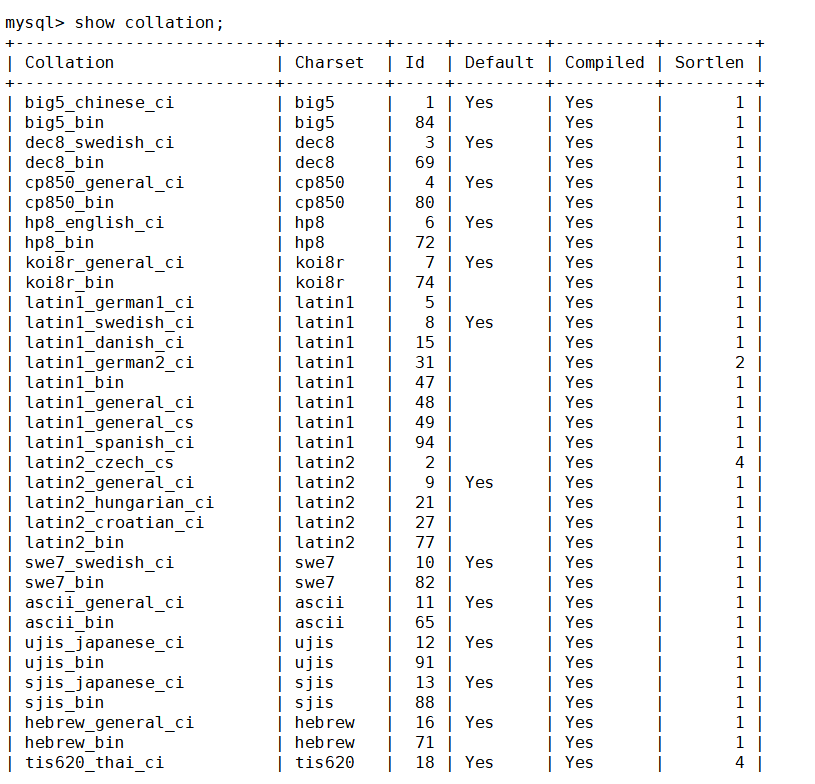
?首先創建一個數據庫
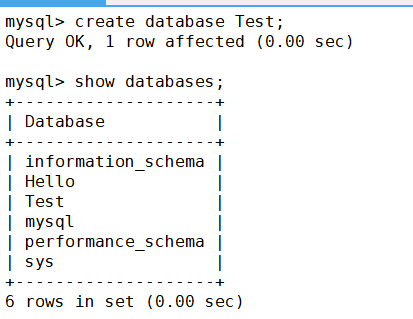
注:這里創建數據庫時沒有指名字符集和字符集校驗規則時,默認字符集就是utf8,校驗規則就是
utf8_ general_ ci(utf8_general_ci不會區分大小寫)
然后在庫里創建一個表,并插入若干個數據,最后查詢一下
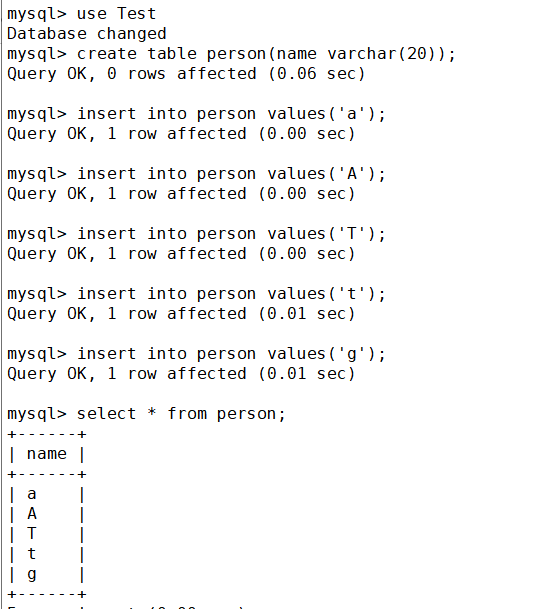
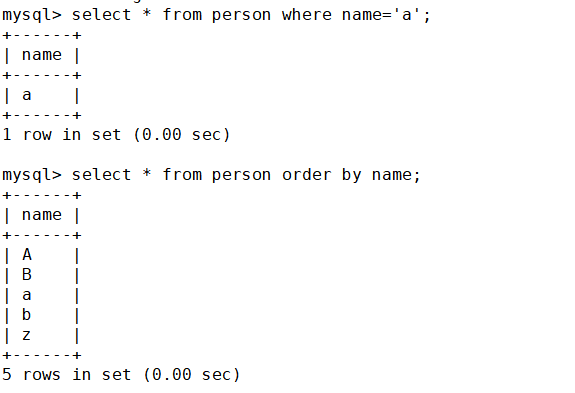
這是表里現有的數據,那么如果查一下字符’a‘呢?

可以發現并沒有區分大小寫
那如果是進行排序呢?

結果顯而易見。
然后再來創建一個數據庫test_db1,這時選用utf8_bin(區分大小寫)校驗規則

然后來查詢一下字符‘a'以及進行排序
上面還用到了兩個沒見過的子句
where 和 order by
where子句
功能:用來過濾行,決定哪些數據行能進入結果集。
用法:
select 列名
from 表名
where 條件表達式;特點:
在數據返回之前就執行過濾。
支持比較運算符(
=, >, <, >=, <=, <>)、邏輯運算符(AND, OR, NOT)、范圍(BETWEEN)、集合(IN)、模式匹配(LIKE)、空值判斷(IS NULL)等。
order by 子句
功能:用來對結果集排序,不影響數據存儲順序,只是展示時排序。
用法:
select 列名
from 表名
order by 列名 [asc|desc];asc升序(默認)。desc降序。
特點:
只能排在整個 SQL 的最后(
limit之前也可以)。可以按多個字段排序。
排序規則受 collation(排序規則) 影響,比如
utf8_general_ci大小寫不敏感,utf8_bin大小寫敏感。
操縱數據庫
顯示創建語句
show create database 數據庫名;
說明:
- MySQL 建議我們關鍵字使用大寫,但是不是必須的。
- 數據庫名字的反引號``,是為了防止使用的數據庫名剛好是關鍵字
- /*!40100 default.... */ 這個不是注釋,表示當前mysql版本大于4.01版本,就執行這句話
修改數據庫
語法:
ALTER DATABASE db_name
[alter_spacification [,alter_spacification]...]
alter_spacification:
[DEFAULT] CHARACTER SET charset_name
[DEFAULT] COLLATE collation_name對數據庫的修改主要指的是修改數據庫的字符集,校驗規則
這里修改一下test_db1數據庫的字符集
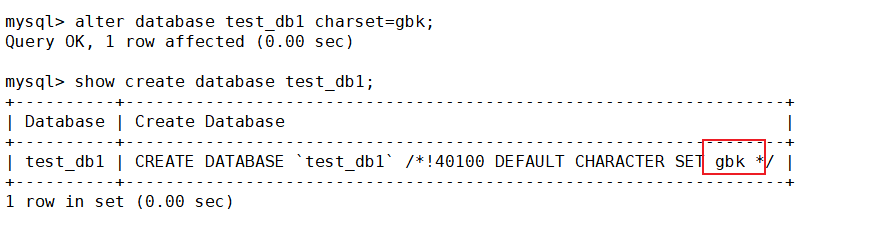
可以看到,默認執行的語句變了
數據庫刪除
語法:
DROP DATABASE [IF EXISTS] db_ name;執行刪除之后的結果:
- 數據庫內部看不到對應的數據庫
- 對應的數據庫文件夾被刪除,級聯刪除,里面的數據表全部被刪
注意:不要隨意刪除數據庫
數據庫備份
mysqldump -P3306 -u root -p 密碼 -B 數據庫名 > 數據庫備份存儲的文件路徑將test_db1備份到root目錄下的MySQL目錄里
注:這是在shell里面輸入,而不是在mysql里
這下可以在相關目錄里看見備份的文件了

如果再查看一下備份文件的內容呢?
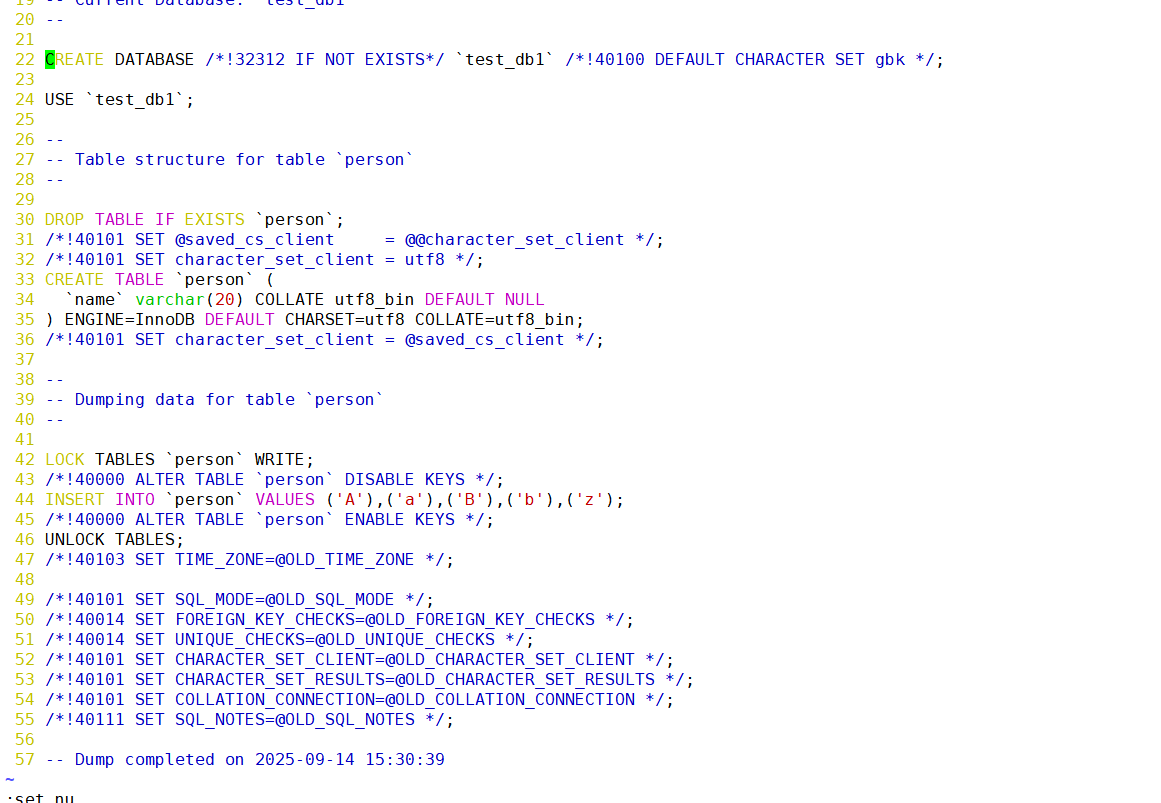
會發現原來是一串之前輸入過的mysql語句
那么既然已經備份了就可以刪除mysql里面的庫文件了
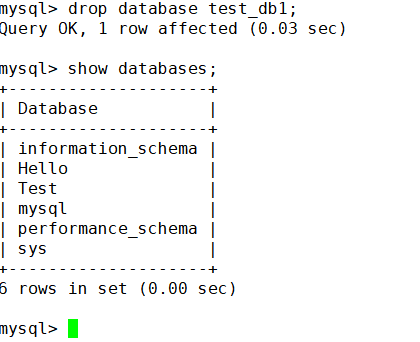
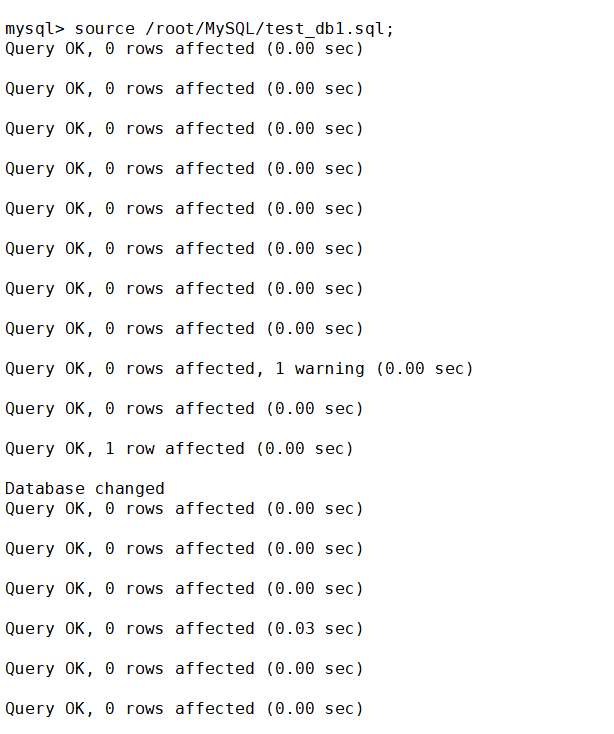
現在還原一下刪除的庫
這次是在mysql客戶端里輸入
source 相關路徑/mytest.sql;可以看到有很多語句被執行的提示
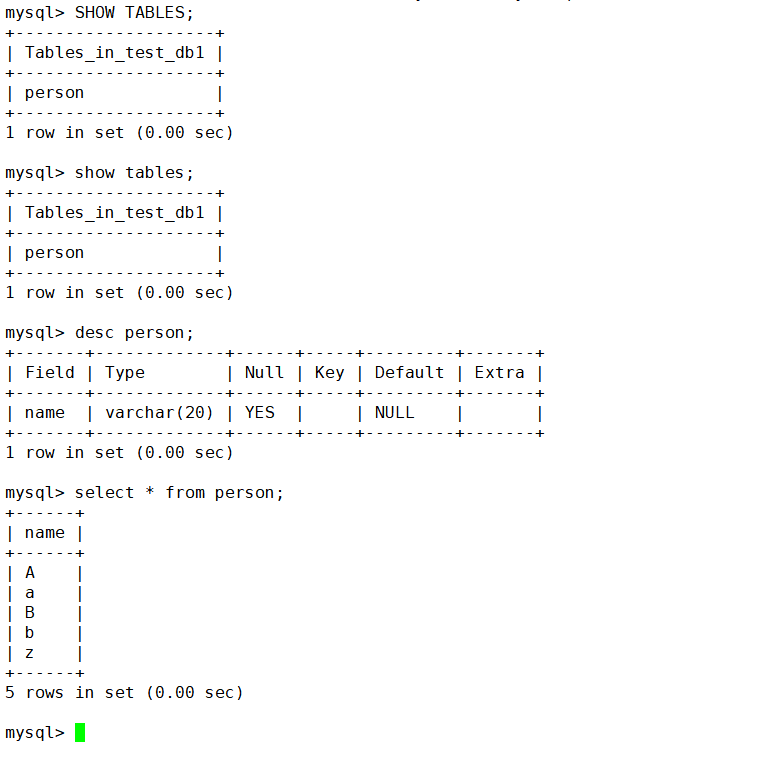
查看庫里都存在的表
show tables;查看表的結構
desc 表名;這樣刪除的庫就被還原了
如果備份的不是整個數據庫,而是其中的一張表,怎么做?
# mysqldump -u root -p 數據庫名 表名1 表名2 > 路徑
同時備份多個數據庫
# mysqldump -u root -p -B 數據庫名1 數據庫名2 ... > 數據庫存放路徑如果備份一個數據庫時,沒有帶上-B參數, 在恢復數據庫時,需要先創建空數據庫,然后使用數據庫,再使用source來還原
查看連接情況
show processlist可以看到目前只有我一個root用戶在連接數據庫

介紹及使用)









實戰十八——圖像透視轉換)


:(十三)堆的應用)





