作者:來自 Elastic?Drew Post

探索 Elastic Stack 告警的最新增強功能,包括改進的相關告警分組、將儀表盤鏈接到告警規則,以及將調查指南嵌入到告警中。
在 9.1 版本中,我們對告警進行了重大升級,幫助 SRE 和運維人員更快地過濾噪音,更快理解發生了什么,并在更少猜測的情況下采取有意義的行動。
以下是新功能:
改進的相關告警分組,帶有相關性評分和推理
我們增強了相關告警檢測,超越了表層的關聯。告警現在基于相關性評分分組,該評分反映了它們在以下維度上的關系強度:
-
共享的實體或資源(例如相同的主機、pod 或服務)
-
時間上的接近(告警在可疑的短時間窗口內觸發)
-
信號相似性(例如日志、指標和 traces 中的峰值指向相同的故障模式)
更重要的是,我們現在展示了原因。你會看到為什么一個告警被分組,不管是因為共享相同的 Kubernetes pod,具有相似的日志模式,還是由相同的上游異常觸發。這讓用戶對分組邏輯更有信心,并加速了根因分析。

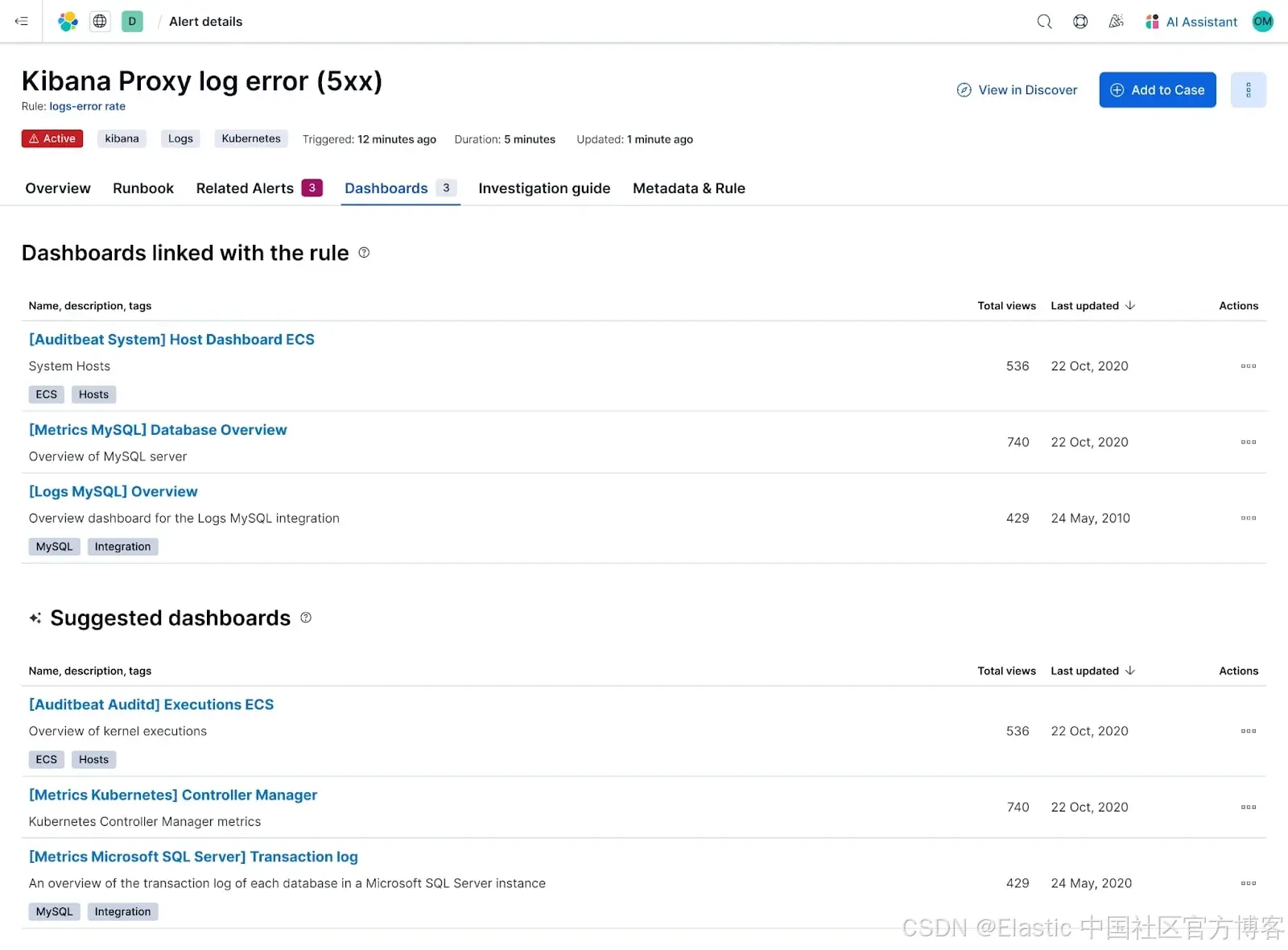
將儀表盤鏈接到告警規則并獲得智能建議
你現在可以將儀表盤直接鏈接到告警規則,讓響應者立即通過可視化方式查看該告警最重要的指標或日志。再也不用手忙腳亂地記住該檢查哪個儀表盤 —— 只需點擊即可。
而且我們讓這一功能更智能:Elastic 現在會根據告警的來源、規則邏輯或被監控的實體,自動推薦相關的儀表盤,幫助用戶無需事先配置就能快速進入正確的視圖。
調查指南嵌入到告警中
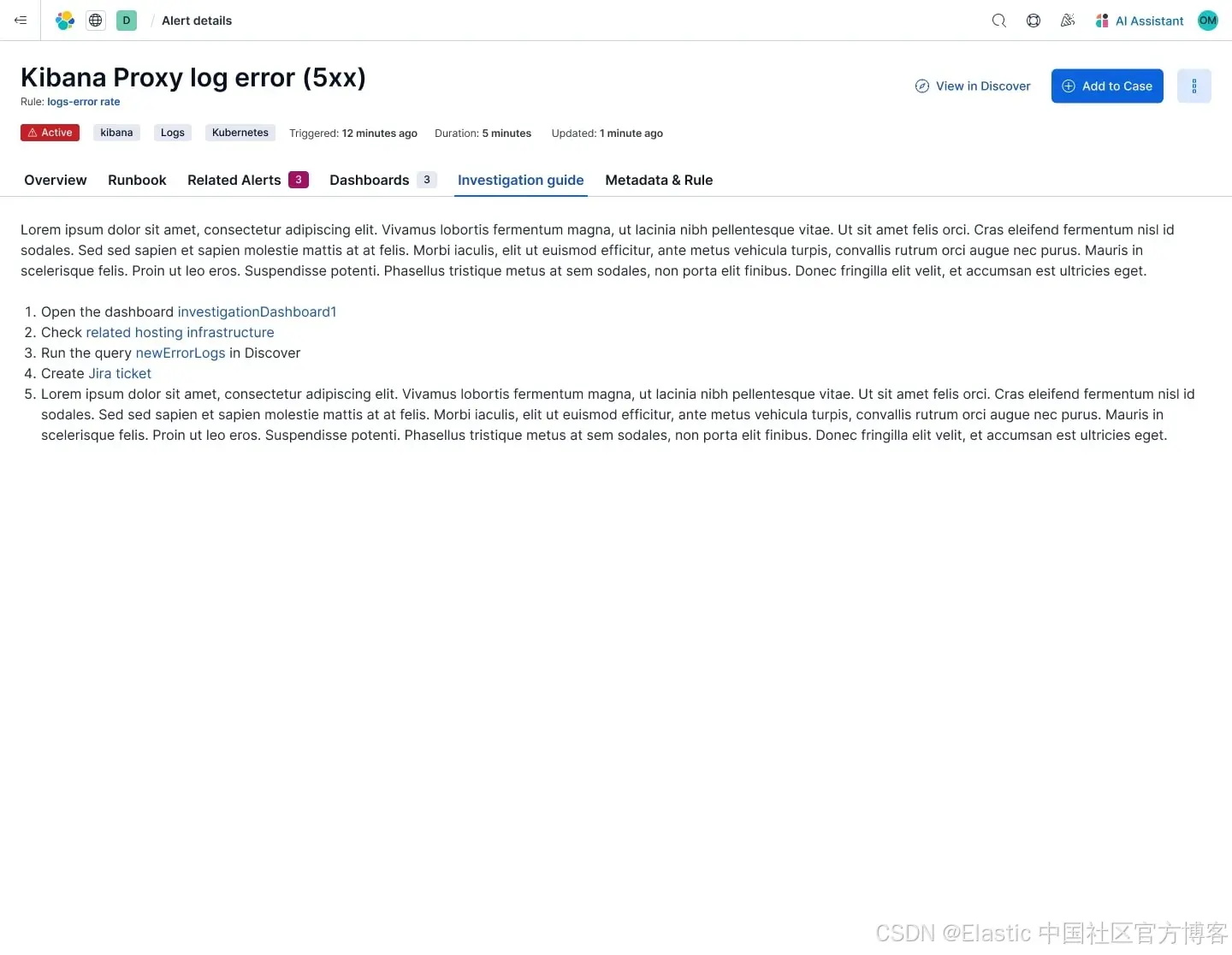
現在每個告警都可以配置一個調查指南,即一組預配置的、具備上下文感知的指令或后續步驟,專門針對該告警進行定制。可以把它看作是一個嵌入在你需要的時間和位置的操作手冊。
用它可以:
-
記錄你團隊的運行手冊和標準分診步驟,或鏈接到已有的運行手冊
-
引導初級工程師或值班響應者處理不熟悉的情況
-
自動化根本原因分析的前幾個步驟
為什么這很重要
這些改進的核心都是為了減少檢測時間 (MTTD) 和解決時間 (MTTR)。通過:
-
更智能(且透明)地對告警分組
-
在你需要的時候給你所需的 dashboards
-
在每個告警中嵌入面向行動的指南
我們讓你更接近真正精簡的事件響應工作流;不需要來回切換,不需要猜測,只有清晰。
另外,請看看我們在 Elastic Observability Labs 里與分析相關的其他文章:
-
在 Elastic Observability 中使用 AI Assistant 加速根本原因分析
-
Elastic Observability 中的所有日志分析功能
-
我們在 Elastic Observability 中對 OpenTelemetry 支持的最新進展
原文:https://www.elastic.co/observability-labs/blog/reduce-mttd-ml-machine-learning-observability















--Java版)


視頻剪裁)
