預訓練語言模型
本文較長,建議點贊收藏,以免遺失。更多AI大模型開發 學習視頻/籽料/面試題 都在這>>Github<< >>Gitee<<
3.1 Encoder-only PLM
在上一章,我們詳細講解了給 NLP 領域帶來巨大變革注意力機制以及使用注意力機制搭建的模型 Transformer,NLP 模型的里程碑式轉變也就自此而始。在上文對 Transformer 的講解中我們可以看到,Transformer 結構主要由 Encoder、Decoder 兩個部分組成,兩個部分分別具有不一樣的結構和輸入輸出。
針對 Encoder、Decoder 的特點,引入 ELMo 的預訓練思路,開始出現不同的、對 Transformer 進行優化的思路。例如,Google 僅選擇了 Encoder 層,通過將 Encoder 層進行堆疊,再提出不同的預訓練任務-掩碼語言模型(Masked Language Model,MLM),打造了一統自然語言理解(Natural Language Understanding,NLU)任務的代表模型——BERT。而 OpenAI 則選擇了 Decoder 層,使用原有的語言模型(Language Model,LM)任務,通過不斷增加模型參數和預訓練語料,打造了在 NLG(Natural Language Generation,自然語言生成)任務上優勢明顯的 GPT 系列模型,也是現今大火的 LLM 的基座模型。當然,還有一種思路是同時保留 Encoder 與 Decoder,打造預訓練的 Transformer 模型,例如由 Google 發布的 T5模型。
在本章中,我們將以 Encoder-Only、Encoder-Decoder、Decoder-Only 的順序來依次介紹 Transformer 時代的各個主流預訓練模型,分別介紹三種核心的模型架構、每種主流模型選擇的預訓練任務及其獨特優勢,這也是目前所有主流 LLM 的模型基礎。
3.1.1 BERT
BERT,全名為 Bidirectional Encoder Representations from Transformers,是由 Google 團隊在 2018年發布的預訓練語言模型。該模型發布于論文《BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding》,實現了包括 GLUE、MultiNLI 等七個自然語言處理評測任務的最優性能(State Of The Art,SOTA),堪稱里程碑式的成果。自 BERT 推出以來,預訓練+微調的模式開始成為自然語言處理任務的主流,不僅 BERT 自身在不斷更新迭代提升模型性能,也出現了如 MacBERT、BART 等基于 BERT 進行優化提升的模型。可以說,BERT 是自然語言處理的一個階段性成果,標志著各種自然語言處理任務的重大進展以及預訓練模型的統治地位建立,一直到 LLM 的誕生,NLP 領域的主導地位才從 BERT 系模型進行遷移。即使在 LLM 時代,要深入理解 LLM 與 NLP,BERT 也是無法繞過的一環。
(1)思想沿承
BERT 是一個統一了多種思想的預訓練模型。其所沿承的核心思想包括:
- Transformer 架構。正如我們在上一章所介紹的,在 2017年發表的《Attention is All You Need》論文提出了完全使用 注意力機制而拋棄 RNN、LSTM 結構的 Transformer 模型,帶來了新的模型架構。BERT 正沿承了 Transformer 的思想,在 Transformer 的模型基座上進行優化,通過將 Encoder 結構進行堆疊,擴大模型參數,打造了在 NLU 任務上獨居天分的模型架構;
- 預訓練+微調范式。同樣在 2018年,ELMo 的誕生標志著預訓練+微調范式的誕生。ELMo 模型基于雙向 LSTM 架構,在訓練數據上基于語言模型進行預訓練,再針對下游任務進行微調,表現出了更加優越的性能,將 NLP 領域導向預訓練+微調的研究思路。而 BERT 也采用了該范式,并通過將模型架構調整為 Transformer,引入更適合文本理解、能捕捉深層雙向語義關系的預訓練任務 MLM,將預訓練-微調范式推向了高潮。
接下來,我們將從模型架構、預訓練任務以及下游任務微調三個方面深入剖析 BERT,分析 BERT 的核心思路及優勢,幫助大家理解 BERT 為何能夠具備遠超之前模型的性能,也從而更加深刻地理解 LLM 如何能夠戰勝 BERT 揭開新時代的大幕。
(2)模型架構——Encoder Only
BERT 的模型架構是取了 Transformer 的 Encoder 部分堆疊而成,其主要結構如圖3.1所示:
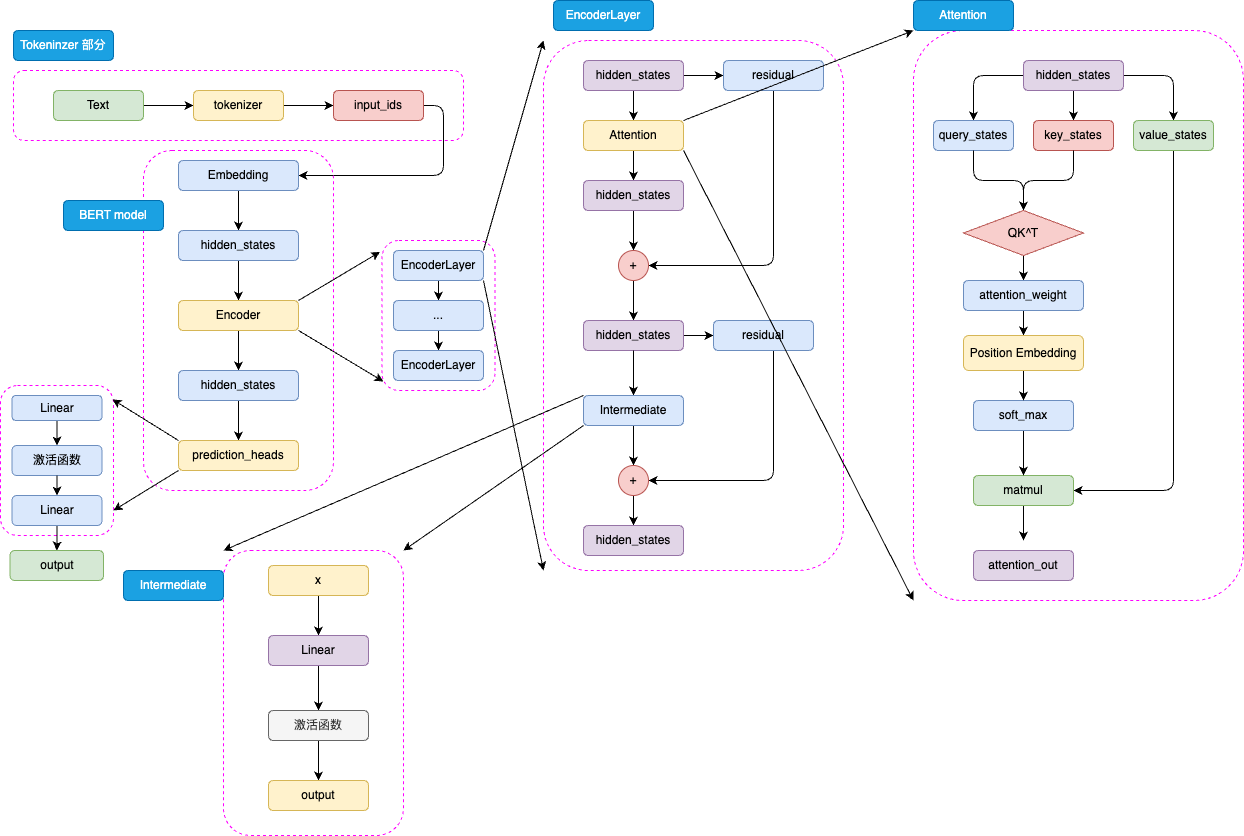
圖3.1 BERT 模型結構
BERT 是針對于 NLU 任務打造的預訓練模型,其輸入一般是文本序列,而輸出一般是 Label,例如情感分類的積極、消極 Label。但是,正如 Transformer 是一個 Seq2Seq 模型,使用 Encoder 堆疊而成的 BERT 本質上也是一個 Seq2Seq 模型,只是沒有加入對特定任務的 Decoder,因此,為適配各種 NLU 任務,在模型的最頂層加入了一個分類頭 prediction_heads,用于將多維度的隱藏狀態通過線性層轉換到分類維度(例如,如果一共有兩個類別,prediction_heads 輸出的就是兩維向量)。
模型整體既是由 Embedding、Encoder 加上 prediction_heads 組成:
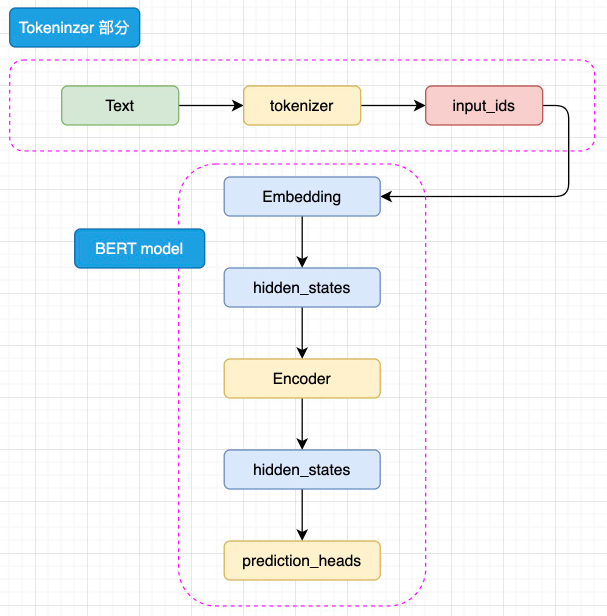
圖3.2 BERT 模型簡略結構
輸入的文本序列會首先通過 tokenizer(分詞器) 轉化成 input_ids(基本每一個模型在 tokenizer 的操作都類似,可以參考 Transformer 的 tokenizer 機制,后文不再贅述),然后進入 Embedding 層轉化為特定維度的 hidden_states,再經過 Encoder 塊。Encoder 塊中是堆疊起來的 N 層 Encoder Layer,BERT 有兩種規模的模型,分別是 base 版本(12層 Encoder Layer,768 的隱藏層維度,總參數量 110M),large 版本(24層 Encoder Layer,1024 的隱藏層維度,總參數量 340M)。通過Encoder 編碼之后的最頂層 hidden_states 最后經過 prediction_heads 就得到了最后的類別概率,經過 Softmax 計算就可以計算出模型預測的類別。
BERT 采用 WordPiece 作為分詞方法。WordPiece 是一種基于統計的子詞切分算法,其核心在于將單詞拆解為子詞(例如,“playing” -> [“play”, “##ing”])。其合并操作的依據是最大化語言模型的似然度。對于中文等非空格分隔的語言,通常將單個漢字作為原子分詞單位(token)處理。
prediction_heads 其實就是線性層加上激活函數,一般而言,最后一個線性層的輸出維度和任務的類別數相等,如圖3.3所示:
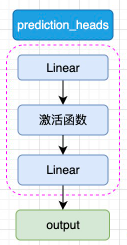
圖3.3 prediction_heads 結構
而每一層 Encoder Layer 都是和 Transformer 中的 Encoder Layer 結構類似的層,如圖3.4所示:
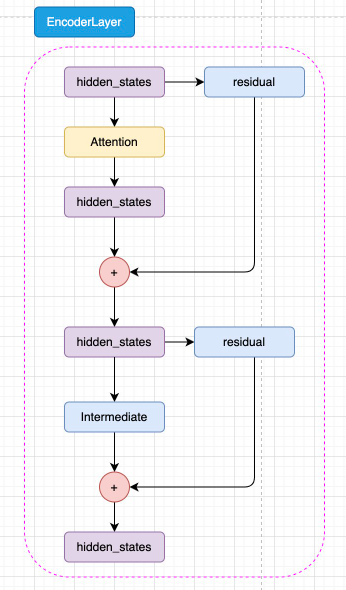
圖3.4 Encoder Layer 結構
如圖3.5所示,已經通過 Embedding 層映射的 hidden_states 進入核心的 attention 機制,然后通過殘差連接的機制和原輸入相加,再經過一層 Intermediate 層得到最終輸出。Intermediate 層是 BERT 的特殊稱呼,其實就是一個線性層加上激活函數:
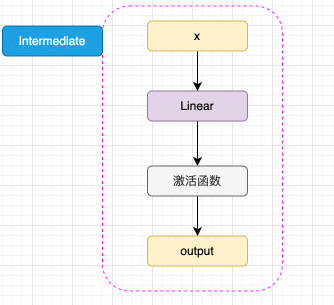
圖3.5 Intermediate 結構
注意,BERT 所使用的激活函數是 GELU 函數,全名為高斯誤差線性單元激活函數,這也是自 BERT 才開始被普遍關注的激活函數。GELU 的計算方式為:
GELU(x)=0.5x(1+tanh(2π)(x+0.044715x3))GELU(x) = 0.5x(1 + tanh(\sqrt{\frac{2}{\pi}})(x + 0.044715x^3))GELU(x)=0.5x(1+tanh(π2??)(x+0.044715x3))
GELU 的核心思路為將隨機正則的思想引入激活函數,通過輸入自身的概率分布,來決定拋棄還是保留自身的神經元。關于 GELU 的原理與核心思路,此處不再贅述,有興趣的讀者可以自行學習。
BERT 的 注意力機制和 Transformer 中 Encoder 的 自注意力機制幾乎完全一致,但是 BERT 將相對位置編碼融合在了注意力機制中,將相對位置編碼同樣視為可訓練的權重參數,如圖3.6所示:
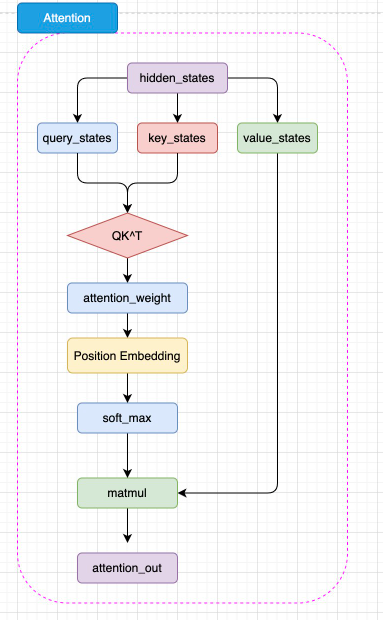
圖3.6 BERT 注意力機制結構
如圖,BERT 的注意力計算過程和 Transformer 的唯一差異在于,在完成注意力分數的計算之后,先通過 Position Embedding 層來融入相對位置信息。這里的 Position Embedding 層,其實就是一層線性矩陣。通過可訓練的參數來擬合相對位置,相對而言比 Transformer 使用的絕對位置編碼 Sinusoidal 能夠擬合更豐富的相對位置信息,但是,這樣也增加了不少模型參數,同時完全無法處理超過模型訓練長度的輸入(例如,對 BERT 而言能處理的最大上下文長度是 512 個 token)。
注:原始 BERT(即論文提出)使用和 Transformer 一致的絕對位置編碼,后續改進(包括 BERT 的各種變體)使用了上述相對位置編碼,為幫助讀者了解更全面的模型結構設計,此處選擇了改進版 BERT。
可以看出,BERT 的模型架構既是建立在 Transformer 的 Encoder 之上的,這也是為什么說 BERT 沿承了 Transformer 的思想。
(3)預訓練任務——MLM + NSP
相較于基本沿承 Transformer 的模型架構,BERT 更大的創新點在于其提出的兩個新的預訓練任務上——MLM 和 NSP(Next Sentence Prediction,下一句預測)。預訓練-微調范式的核心優勢在于,通過將預訓練和微調分離,完成一次預訓練的模型可以僅通過微調應用在幾乎所有下游任務上,只要微調的成本較低,即使預訓練成本是之前的數倍甚至數十倍,模型仍然有更大的應用價值。因此,可以進一步擴大模型參數和預訓練數據量,使用海量的預訓練語料來讓模型擬合潛在語義與底層知識,從而讓模型通過長時間、大規模的預訓練獲得強大的語言理解和生成能力。
因此,預訓練數據的核心要求即是需要極大的數據規模(數億 token)。毫無疑問,通過人工標注產出的全監督數據很難達到這個規模。因此,預訓練數據一定是從無監督的語料中獲取。這也是為什么傳統的預訓練任務都是 LM 的原因——LM 使用上文預測下文的方式可以直接應用到任何文本中,對于任意文本,我們只需要將下文遮蔽將上文輸入模型要求其預測就可以實現 LM 訓練,因此互聯網上所有文本語料都可以被用于預訓練。
但是,LM 預訓練任務的一大缺陷在于,其直接擬合從左到右的語義關系,但忽略了雙向的語義關系。雖然 Transformer 中通過位置編碼表征了文本序列中的位置信息,但這和直接擬合雙向語義關系還是有本質區別。例如,BiLSTM(雙向 LSTM 模型)在語義表征上就往往優于 LSTM 模型,就是因為 BiLSTM 通過雙向的 LSTM 擬合了雙向語義關系。因此,有沒有一種預訓練任務,能夠既利用海量無監督語料,又能夠訓練模型擬合雙向語義關系的能力?
基于這一思想,Jacob 等學者提出了 MLM,也就是掩碼語言模型作為新的預訓練任務。相較于模擬人類寫作的 LM,MLM 模擬的是“完形填空”。MLM 的思路也很簡單,在一個文本序列中隨機遮蔽部分 token,然后將所有未被遮蔽的 token 輸入模型,要求模型根據輸入預測被遮蔽的 token。例如,輸入和輸出可以是:
輸入:I <MASK> you because you are <MASK>
輸出:<MASK> - love; <MASK> - wonderful
由于模型可以利用被遮蔽的 token 的上文和下文一起理解語義來預測被遮蔽的 token,因此通過這樣的任務,模型可以擬合雙向語義,也就能夠更好地實現文本的理解。同樣,MLM 任務無需對文本進行任何人為的標注,只需要對文本進行隨機遮蔽即可,因此也可以利用互聯網所有文本語料實現預訓練。例如,BERT 的預訓練就使用了足足 3300M 單詞的語料。
不過,MLM 也存在其固有缺陷。LM 任務模擬了人自然創作的過程,其訓練和下游任務是完全一致的,也就是說,訓練時是根據上文預測下文,下游任務微調和推理時也同樣如此。但是 MLM 不同,在下游任務微調和推理時,其實是不存在我們人工加入的 <MASK> 的,我們會直接通過原文本得到對應的隱藏狀態再根據下游任務進入分類器或其他組件。預訓練和微調的不一致,會極大程度影響模型在下游任務微調的性能。針對這一問題,作者對 MLM 的策略進行了改進。
在具體進行 MLM 訓練時,會隨機選擇訓練語料中 15% 的 token 用于遮蔽。但是這 15% 的 token 并非全部被遮蔽為 <MASK>,而是有 80% 的概率被遮蔽,10% 的概率被替換為任意一個 token,還有 10% 的概率保持不變。其中 10% 保持不變就是為了消除預訓練和微調的不一致,而 10% 的隨機替換核心意義在于迫使模型保持對上下文信息的學習。因為如果全部遮蔽的話,模型僅需要處理被遮蔽的位置,從而僅學習要預測的 token 而丟失了對上下文的學習。通過引入部分隨機 token,模型無法確定需要預測的 token,從而被迫保持每一個 token 的上下文表征分布,從而具備了對句子的特征表示能力。且由于隨機 token 的概率很低,其并不會影響模型實質的語言理解能力。
除去 MLM,BERT 還提出了另外一個預訓練任務——NSP,即下一個句子預測。NSP 的核心思想是針對句級的 NLU 任務,例如問答匹配、自然語言推理等。問答匹配是指,輸入一個問題和若干個回答,要求模型找出問題的真正回答;自然語言推理是指,輸入一個前提和一個推理,判斷推理是否是符合前提的。這樣的任務都需要模型在句級去擬合關系,判斷兩個句子之間的關系,而不僅是 MLM 在 token 級擬合的語義關系。因此,BERT 提出了 NSP 任務來訓練模型在句級的語義關系擬合。
NSP 任務的核心思路是要求模型判斷一個句對的兩個句子是否是連續的上下文。例如,輸入和輸入可以是:
輸入:Sentence A:I love you.Sentence B: Because you are wonderful.
輸出:1(是連續上下文)輸入:Sentence A:I love you.Sentence B: Because today's dinner is so nice.
輸出:0(不是連續上下文)
通過要求模型判斷句對關系,從而迫使模型擬合句子之間的關系,來適配句級的 NLU 任務。同樣,由于 NSP 的正樣本可以從無監督語料中隨機抽取任意連續的句子,而負樣本可以對句子打亂后隨機抽取(只需要保證不要抽取到原本就連續的句子就行),因此也可以具有幾乎無限量的訓練數據。
在具體預訓練時,BERT 使用了 800M 的 BooksCorpus 語料和 2500M 的英文維基百科語料,90% 的數據使用 128 的上下文長度訓練,剩余 10% 的數據使用 512 作為上下文長度進行預訓練,總共約訓練了 3.3B token。其訓練的超參數也是值得關注的,BERT 的訓練語料共有 13GB 大小,其在 256 的 batch size 上訓練了 1M 步(40 個 Epoch)。而相較而言,LLM 一般都只會訓練一個 Epoch,且使用遠大于 256 的 batch size。
可以看到,相比于傳統的非預訓練模型,其訓練的數據量有指數級增長。當然,更海量的訓練數據需要更大成本的算力,BERT 的 Base 版本和 Large 版本分別使用了 16塊 TPU 和 64塊 TPU 訓練了 4天才完成。
(4)下游任務微調
作為 NLP 領域里程碑式的成果,BERT 的一個重大意義就是正式確立了預訓練-微調的兩階段思想,即在海量無監督語料上進行預訓練來獲得通用的文本理解與生成能力,再在對應的下游任務上進行微調。該種思想的一個重點在于,預訓練得到的強大能力能否通過低成本的微調快速遷移到對應的下游任務上。
針對這一點,BERT 設計了更通用的輸入和輸出層來適配多任務下的遷移學習。對每一個輸入的文本序列,BERT 會在其首部加入一個特殊 token <CLS>。在后續編碼中,該 token 代表的即是整句的狀態,也就是句級的語義表征。在進行 NSP 預訓練時,就使用了該 token 對應的特征向量來作為最后分類器的輸入。
在完成預訓練后,針對每一個下游任務,只需要使用一定量的全監督人工標注數據,對預訓練的 BERT 在該任務上進行微調即可。所謂微調,其實和訓練時更新模型參數的策略一致,只不過在特定的任務、更少的訓練數據、更小的 batch_size 上進行訓練,更新參數的幅度更小。對于絕大部分下游任務,都可以直接使用 BERT 的輸出。例如,對于文本分類任務,可以直接修改模型結構中的 prediction_heads 最后的分類頭即可。對于序列標注等任務,可以集成 BERT 多層的隱含層向量再輸出最后的標注結果。對于文本生成任務,也同樣可以取 Encoder 的輸出直接解碼得到最終生成結果。因此,BERT 可以非常高效地應用于多種 NLP 任務。
BERT 一經提出,直接在 NLP 11個賽道上取得 SOTA 效果,成為 NLU 方向上當之無愧的霸主,后續若干在 NLU 任務上取得更好效果的模型都是在 BERT 基礎上改進得到的。直至 LLM 時代,BERT 也仍然能在很多標注數據豐富的 NLU 任務上達到最優效果,事實上,對于某些特定、訓練數據豐富且強調高吞吐的任務,BERT 比 LLM 更具有可用性。
3.1.2 RoBERTa
BERT 作為 NLP 劃時代的杰作,同時在多個榜單上取得 SOTA 效果,也帶動整個 NLP 領域向預訓練模型方向遷移。以 BERT 為基礎,在多個方向上進行優化,還涌現了一大批效果優異的 Encoder-Only 預訓練模型。它們大都有和 BERT 類似或完全一致的模型結構,在訓練數據、預訓練任務、訓練參數等方面上進行了優化,以取得能力更強大、在下游任務上表現更亮眼的預訓練模型。其中之一即是同樣由 Facebook 發布的 RoBERTa。
前面我們說過,預訓練-微調的一個核心優勢在于可以使用遠大于之前訓練數據的海量無監督語料進行預訓練。因為在傳統的深度學習范式中,對每一個任務,我們需要從零訓練一個模型,那么就無法使用太大的模型參數,否則需要極大規模的有監督數據才能讓模型較好地擬合,成本太大。但在預訓練-微調范式,我們在預訓練階段可以使用盡可能大量的訓練數據,只需要一次預訓練好的模型,后續在每一個下游任務上通過少量有監督數據微調即可。而 BERT 就使用了 13GB(3.3B token)的數據進行預訓練,這相較于傳統 NLP 來說是一個極其巨大的數據規模了。
但是,13GB 的預訓練數據是否讓 BERT 達到了充分的擬合呢?如果我們使用更多預訓練語料,是否可以進一步增強模型性能?更多的,BERT 所選用的預訓練任務、訓練超參數是否是最優的?RoBERTa 應運而生。
(1)優化一:去掉 NSP 預訓練任務
RoBERTa 的模型架構與 BERT 完全一致,也就是使用了 BERT-large(24層 Encoder Layer,1024 的隱藏層維度,總參數量 340M)的模型參數。在預訓練任務上,有學者質疑 NSP 任務并不能提高模型性能,因為其太過簡單,加入到預訓練中并不能使下游任務微調時明顯受益,甚至會帶來負面效果。RoBERTa 設置了四個實驗組:
1. 段落構建的 MLM + NSP:BERT 原始預訓練任務,輸入是一對片段,每個片段包括多個句子,來構造 NSP 任務;
2. 文檔對構建的 MLM + NSP:一個輸入構建一對句子,通過增大 batch 來和原始輸入達到 token 等同;
3. 跨越文檔的 MLM:去掉 NSP 任務,一個輸入為從一個或多個文檔中連續采樣的完整句子,為使輸入達到最大長度(512),可能一個輸入會包括多個文檔;
4. 單文檔的 MLM:去掉 NSP 任務,且限制一個輸入只能從一個文檔中采樣,同樣通過增大 batch 來和原始輸入達到 token 等同
實驗結果證明,后兩組顯著優于前兩組,且單文檔的 MLM 組在下游任務上微調時性能最佳。因此,RoBERTa 在預訓練中去掉了 NSP,只使用 MLM 任務。
同時,RoBERTa 對 MLM 任務本身也做出了改進。在 BERT 中,Mask 的操作是在數據處理的階段完成的,因此后期預訓練時同一個 sample 待預測的 <MASK> 總是一致的。由于 BERT 共訓練了 40 個 Epoch,為使模型的訓練數據更加廣泛,BERT 將數據進行了四次隨機 Mask,也就是每 10個 Epoch 模型訓練的數據是完全一致的。而 RoBERTa 將 Mask 操作放到了訓練階段,也就是動態遮蔽策略,從而讓每一個 Epoch 的訓練數據 Mask 的位置都不一致。在實驗中,動態遮蔽僅有很微弱的優勢優于靜態遮蔽,但由于動態遮蔽更高效、易于實現,后續 MLM 任務基本都使用了動態遮蔽。
(2)優化二:更大規模的預訓練數據和預訓練步長
RoBERTa 使用了更大量的無監督語料進行預訓練,除去 BERT 所使用的 BookCorpus 和英文維基百科外,還使用了 CC-NEWS(CommonCrawl 數據集新聞領域的英文部分)、OPENWEBTEXT(英文網頁)、STORIES(CommonCrawl 數據集故事風格子集),共計 160GB 的數據,十倍于 BERT。
同時,RoBERTa 認為更大的 batch size 既可以提高優化速度,也可以提高任務結束性能。因此,實驗在 8K 的 batch size(對比 BERT 的 batch size 為 256)下訓練 31K Step,也就是總訓練 token 數和 BERT 一樣是 3.3B 時,模型性能更好,從而證明了大 batch size 的意義。在此基礎上,RoBERTa 一共訓練了 500K Step(約合 66個 Epoch)。同時,RoBERTa 不再采用 BERT 在 256 長度上進行大部分訓練再在 512 長度上完成訓練的策略,而是全部在 512 長度上進行訓練。
當然,更大的預訓練數據、更長的序列長度和更多的訓練 Epoch,需要預訓練階段更多的算力資源。訓練一個 RoBERTa,Meta 使用了 1024 塊 V100(32GB 顯存)訓練了一天。
(3)優化三:更大的 bpe 詞表
與 BERT 使用的 WordPiece 算法不同,RoBERTa 使用了 BPE 作為 Tokenizer 的編碼策略。BPE,即 Byte Pair Encoding,字節對編碼,是指以子詞對作為分詞的單位。例如,對“Hello World”這句話,可能會切分為“Hel,lo,Wor,ld”四個子詞對。而對于以字為基本單位的中文,一般會按照字節編碼進行切分。例如,在 UTF-8 編碼中,“我”會被編碼為“E68891”,那么在 BPE 中可能就會切分成“E68”,“891”兩個字詞對。
一般來說,BPE 編碼的詞典越大,編碼效果越好。當然,由于 Embedding 層就是把 token 從詞典空間映射到隱藏空間(也就是說 Embedding 的形狀為 (vocab_size, hidden_size),越大的詞表也會帶來模型參數的增加。
BERT 原始的 BPE 詞表大小為 30K,RoBERTa 選擇了 50K 大小的詞表來優化模型的編碼能力。
通過上述三個部分的優化,RoBERTa 成功地在 BERT 架構的基礎上刷新了多個下游任務的 SOTA,也一度成為 BERT 系模型最熱門的預訓練模型。同時,RoBERTa 的成功也證明了更大的預訓練數據、更大的預訓練步長的重要意義,這也是 LLM 誕生的基礎之一。
3.1.3 ALBERT
在 BERT 的基礎上,RoBERTa 進一步探究了更大規模預訓練的作用。同樣是基于 BERT 架構進行優化的 ALBERT 模型,則從是否能夠減小模型參數保持模型能力的角度展開了探究。通過對模型結構進行優化并對 NSP 預訓練任務進行改進,ALBERT 成功地以更小規模的參數實現了超越 BERT 的能力。雖然 ALBERT 所提出的一些改進思想并沒有在后續研究中被廣泛采用,但其降低模型參數的方法及提出的新預訓練任務 SOP 仍然對 NLP 領域提供了重要的參考意義。
(1)優化一:將 Embedding 參數進行分解
BERT 等預訓練模型具有遠超傳統神經網絡的參數量,如前所述,BERT-large 具有 24層 Encoder Layer,1024 的隱藏層維度,總共參數量達 340M。而這其中,Embedding 層的參數矩陣維度為 V?HV*HV?H,此處的 V 為詞表大小 30K,H 即為隱藏層大小 1024,也就是 Embedding 層參數達到了 30M。而這樣的設置還會帶來一個更大的問題,即 Google 探索嘗試搭建更寬(也就是隱藏層維度更大)的模型時發現,隱藏層維度的增加會帶來 Embedding 層參數的巨大上升,如果把隱藏層維度增加到 2048,Embedding 層參數就會膨脹到 61M,這無疑是極大增加了模型的計算開銷。
而從另一個角度看,Embedding 層輸出的向量是我們對文本 token 的稠密向量表示,從 Word2Vec 的成功經驗來看,這種詞向量并不需要很大的維度,Word2Vec 僅使用了 100維大小就取得了很好的效果。因此,Embedding 層的輸出也許不需要和隱藏層大小一致。
因此,ALBERT 對 Embedding 層的參數矩陣進行了分解,讓 Embedding 層的輸出維度和隱藏層維度解綁,也就是在 Embedding 層的后面加入一個線性矩陣進行維度變換。ALBERT 設置了 Embedding 層的輸出為 128,因此在 Embedding 層后面加入了一個 128?1024128*1024128?1024 的線性矩陣來將 Embedding 層的輸出再升維到隱藏層大小。也就是說,Embedding 層的參數從 V?HV*HV?H 降低到了 V?E+E?HV*E + E*HV?E+E?H,當 E 的大小遠小于 H 時,該方法對 Embedding 層參數的優化就會很明顯。
(2)優化二:跨層進行參數共享
通過對 BERT 的參數進行分析,ALBERT 發現各個 Encoder 層的參數出現高度一致的情況。由于 24個 Encoder 層帶來了巨大的模型參數,因此,ALBERT 提出,可以讓各個 Encoder 層共享模型參數,來減少模型的參數量。
在具體實現上,其實就是 ALBERT 僅初始化了一個 Encoder 層。在計算過程中,仍然會進行 24次計算,但是每一次計算都是經過這一個 Encoder 層。因此,雖然是 24個 Encoder 計算的模型,但只有一層 Encoder 參數,從而大大降低了模型參數量。在這樣的情況下,就可以極大程度地擴大隱藏層維度,實現一個更寬但參數量更小的模型。ALBERT 通過實驗證明,相較于 334M 的 BERT,同樣是 24層 Encoder 但將隱藏層維度設為 2048 的 ALBERT(xlarge 版本)僅有 59M 的參數量,但在具體效果上還要更優于 BERT。
但是,上述優化雖然極大程度減小了模型參數量并且還提高了模型效果,卻也存在著明顯的不足。雖然 ALBERT 的參數量遠小于 BERT,但訓練效率卻只略微優于 BERT,因為在模型的設置中,雖然各層共享權重,但計算時仍然要通過 24次 Encoder Layer 的計算,也就是說訓練和推理時的速度相較 BERT 還會更慢。這也是 ALBERT 最終沒能取代 BERT 的一個重要原因。
(3)優化三:提出 SOP 預訓練任務
類似于 RoBERTa,ALBERT 也同樣認為 NSP 任務過于簡單,在預訓練中無法對模型效果的提升帶來顯著影響。但是不同于 RoBERTa 選擇直接去掉 NSP,ALBERT 選擇改進 NSP,增加其難度,來優化模型的預訓練。
在傳統的 NSP 任務中,正例是由兩個連續句子組成的句對,而負例則是從任意兩篇文檔中抽取出的句對,模型可以較容易地判斷正負例,并不能很好地學習深度語義。而 SOP 任務提出的改進是,正例同樣由兩個連續句子組成,但負例是將這兩個的順序反過來。也就是說,模型不僅要擬合兩個句子之間的關系,更要學習其順序關系,這樣就大大提升了預訓練的難度。例如,相較于我們在上文中提出的 NSP 任務的示例,SOP 任務的示例形如:
輸入:Sentence A:I love you.Sentence B: Because you are wonderful.
輸出:1(正樣本)輸入:Sentence A:Because you are wonderful.Sentence B: I love you.
輸出:0(負樣本)
ALBERT 通過實驗證明,SOP 預訓練任務對模型效果有顯著提升。使用 MLM + SOP 預訓練的模型效果優于僅使用 MLM 預訓練的模型更優于使用 MLM + NSP 預訓練的模型。
通過上述三點優化,ALBERT 成功地以更小的參數實現了更強的性能,雖然由于其架構帶來的訓練、推理效率降低限制了模型的進一步發展,但打造更寬的模型這一思路仍然為眾多更強大的模型提供了參考價值。
作為預訓練時代的 NLP 王者,BERT 及 BERT 系模型在多個 NLP 任務上扮演了極其重要的角色。除去上文介紹過的 RoBERTa、ALBERT 外,還有許多從其他更高角度對 BERT 進行優化的后起之秀,包括進一步改進了預訓練任務的 ERNIE、對 BERT 進行蒸餾的小模型 DistilBERT、主打多語言任務的 XLM 等,本文就不再一一贅述。以 BERT 為代表的 Encoder-Only 架構并非 Transformer 的唯一變種,接下來,我們將介紹 Transformer 的另一種主流架構,與原始 Transformer 更相似、以 T5 為代表的 Encoder-Decoder 架構。
3.2 Encoder-Decoder PLM
在上一節,我們學習了 Encoder-Only 結構的模型,主要介紹了 BERT 的模型架構、預訓練任務和下游任務微調。BERT 是一個基于 Transformer 的 Encoder-Only 模型,通過預訓練任務 MLM 和 NSP 來學習文本的雙向語義關系,從而在下游任務中取得了優異的性能。但是,BERT 也存在一些問題,例如 MLM 任務和下游任務微調的不一致性,以及無法處理超過模型訓練長度的輸入等問題。為了解決這些問題,研究者們提出了 Encoder-Decoder 模型,通過引入 Decoder 部分來解決這些問題,同時也為 NLP 領域帶來了新的思路和方法。
在本節中,我們將學習 Encoder-Decoder 結構的模型,主要介紹 T5 的模型架構和預訓練任務,以及 T5 模型首次提出的 NLP 大一統思想。
3.2.1 T5
T5(Text-To-Text Transfer Transformer)是由 Google 提出的一種預訓練語言模型,通過將所有 NLP 任務統一表示為文本到文本的轉換問題,大大簡化了模型設計和任務處理。T5 基于 Transformer 架構,包含編碼器和解碼器兩個部分,使用自注意力機制和多頭注意力捕捉全局依賴關系,利用相對位置編碼處理長序列中的位置信息,并在每層中包含前饋神經網絡進一步處理特征。
T5 的大一統思想將不同的 NLP 任務如文本分類、問答、翻譯等統一表示為輸入文本到輸出文本的轉換,這種方法簡化了模型設計、參數共享和訓練過程,提高了模型的泛化能力和效率。通過這種統一處理方式,T5不僅減少了任務特定的模型調試工作,還能夠使用相同的數據處理和訓練框架,極大地提升了多任務學習的性能和應用的便捷性。接下來我們將會從模型結構、預訓練任務和大一統思想三個方面來介紹 T5 模型。
(1)模型結構:Encoder-Decoder
BERT 采用了 Encoder-Only 結構,只包含編碼器部分;而 GPT 采用了 Decoder-Only 結構,只包含解碼器部分。T5 則采用了 Encoder-Decoder 結構,其中編碼器和解碼器都是基于 Transformer 架構設計。編碼器用于處理輸入文本,解碼器用于生成輸出文本。編碼器和解碼器之間通過注意力機制進行信息交互,從而實現輸入文本到輸出文本的轉換。其主要結構如圖3.7所示:
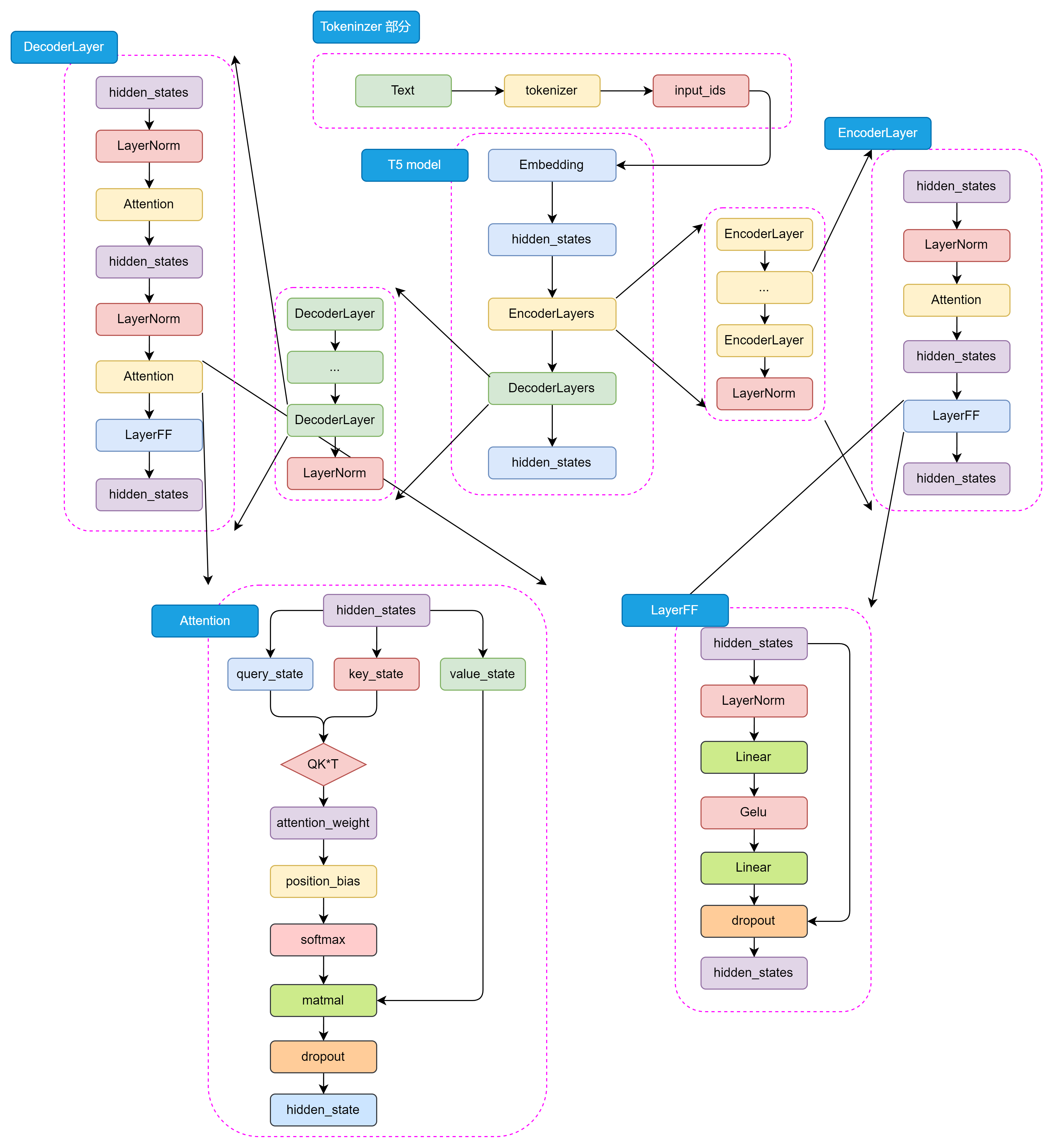
圖3.7 T5 模型詳細結構
如圖3.8所示,從整體來看 T5 的模型結構包括 Tokenizer 部分和 Transformer 部分。Tokenizer 部分主要負責將輸入文本轉換為模型可接受的輸入格式,包括分詞、編碼等操作。Transformer 部分又分為 EncoderLayers 和 DecoderLayers 兩部分,他們分別由一個個小的 Block組成,每個 Block 包含了多頭注意力機制、前饋神經網絡和 Norm 層。Block 的設計可以使模型更加靈活,像樂高一樣可以根據任務的復雜程度和數據集的大小來調整 Block 的數量和層數。
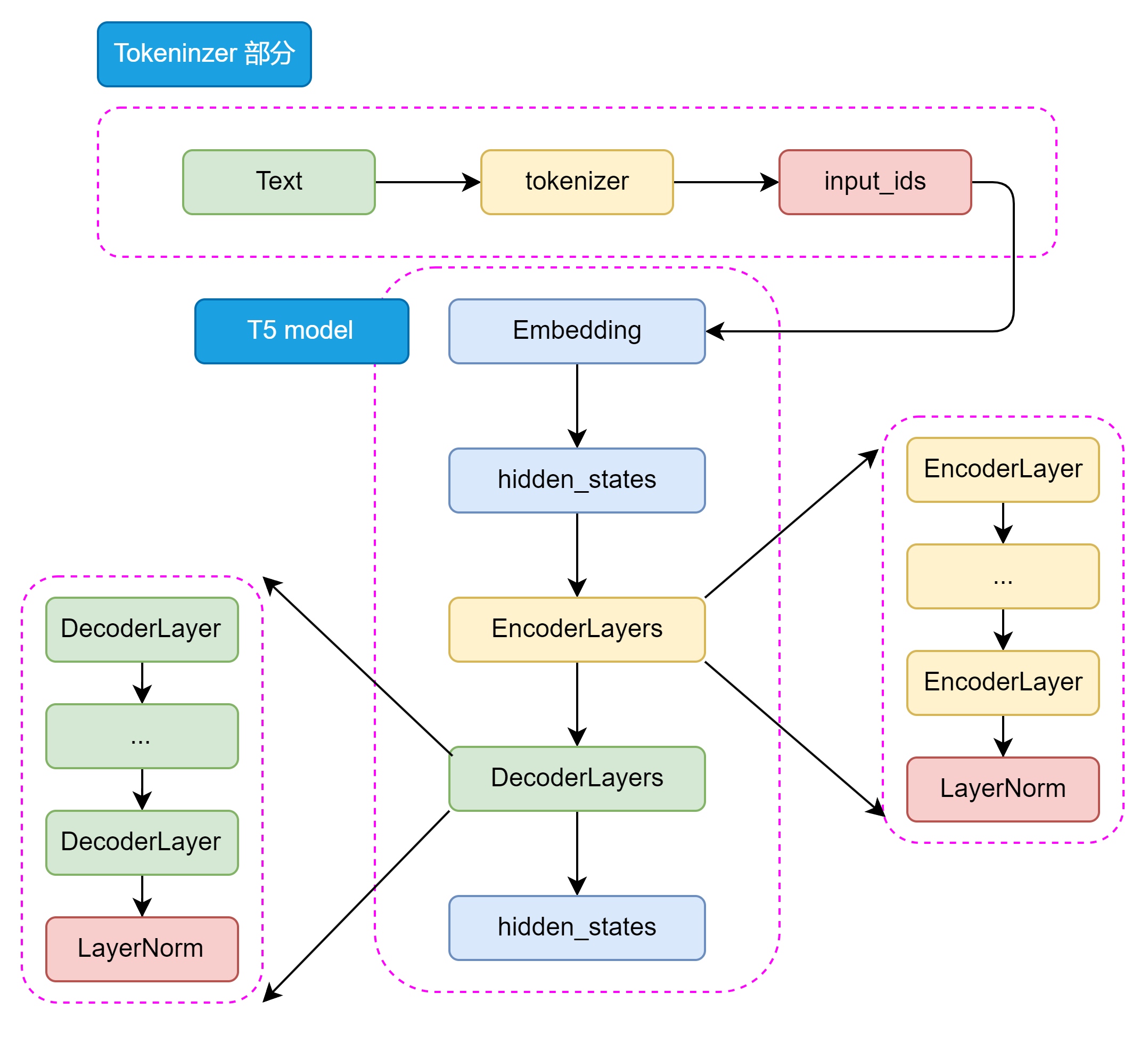
圖3.8 T5 模型整體結構
T5 模型的 Encoder 和 Decoder 部分都是基于 Transformer 架構設計的,主要包括 Self-Attention 和前饋神經網絡兩種結構。Self-Attention 用于捕捉輸入序列中的全局依賴關系,前饋神經網絡用于處理特征的非線性變換。
和 Encoder 不一樣的是,在 Decoder 中還包含了 Encoder-Decoder Attention 結構,用于捕捉輸入和輸出序列之間的依賴關系。這兩種 Attention 結構幾乎完全一致,只有在位置編碼和 Mask 機制上有所不同。如圖3.9所示,Encoder 和 Decoder 的結構如下:
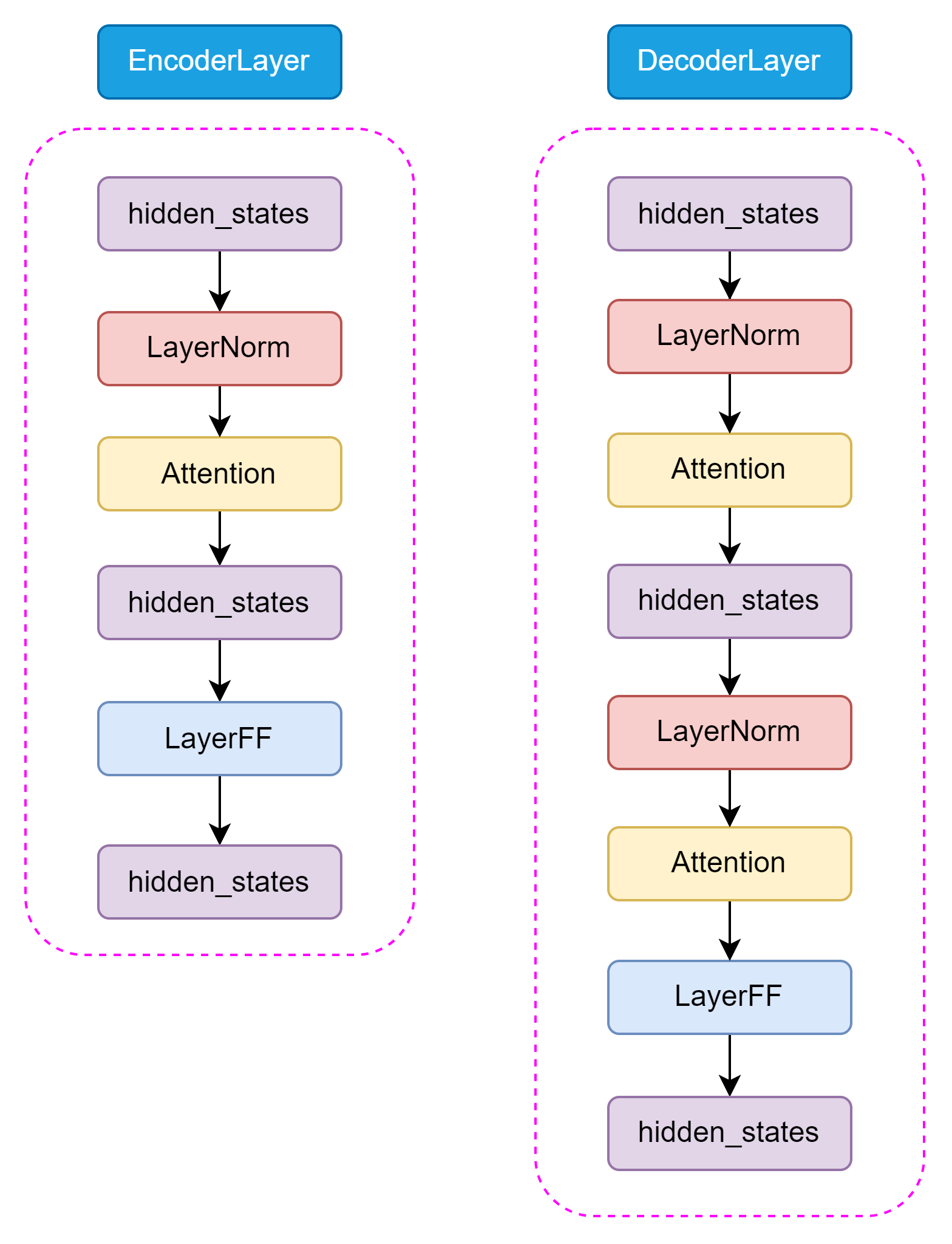
圖3.9 Encoder 和 Decoder
T5 的 Self-Attention 機制和 BERT 的 Attention 機制是一樣的,都是基于 Self-Attention 機制設計的。Self-Attention 機制是一種全局依賴關系建模方法,通過計算 Query、Key 和 Value 之間的相似度來捕捉輸入序列中的全局依賴關系。Encoder-Decoder Attention 僅僅在位置編碼和 Mask 機制上有所不同,主要是為了區分輸入和輸出序列。如圖3.10所示,Self-Attention 結構如下:
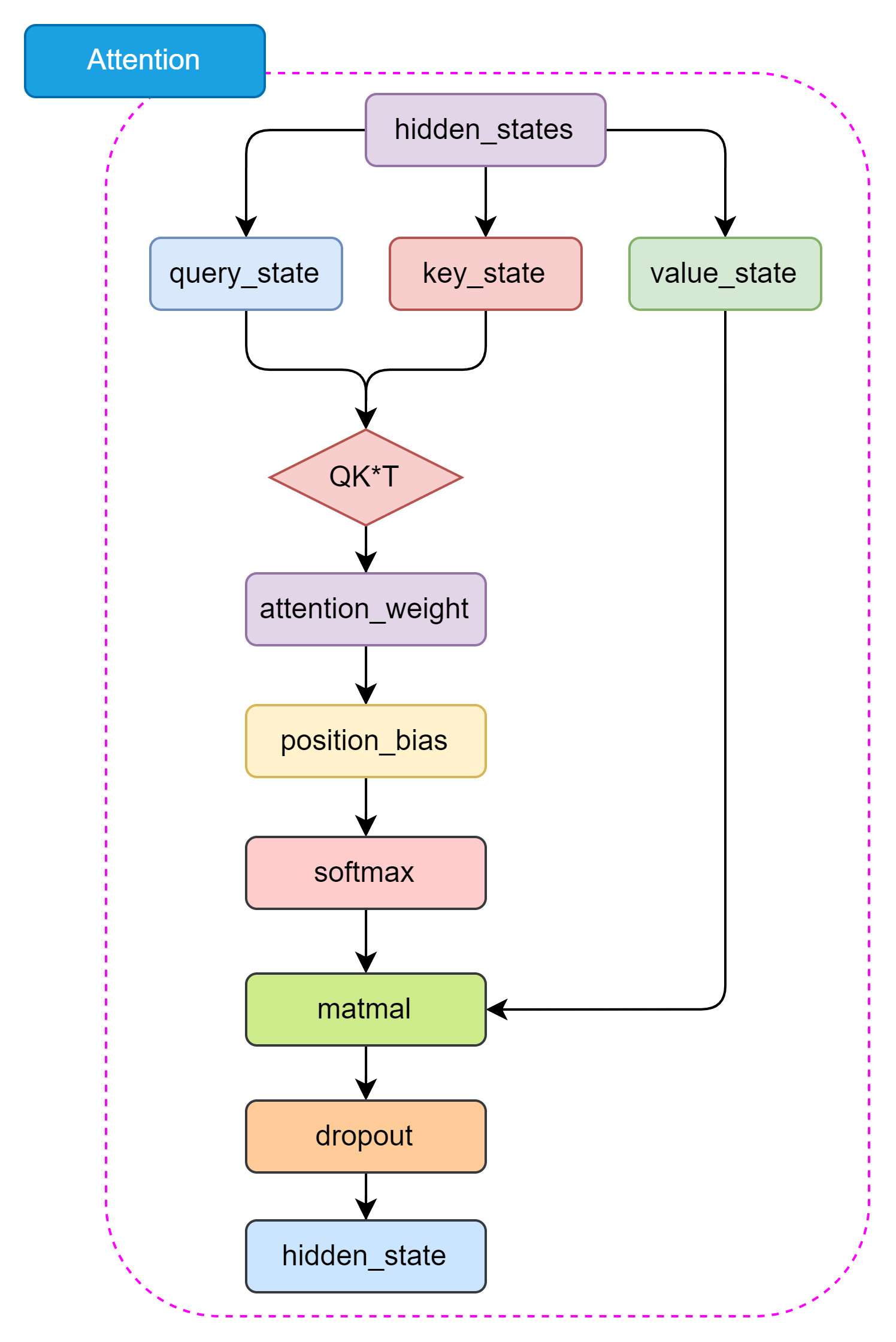 圖3.10 Self-Attention 結構
圖3.10 Self-Attention 結構
與原始 Transformer 模型不同,T5 模型的LayerNorm 采用了 RMSNorm,通過計算每個神經元的均方根(Root Mean Square)來歸一化每個隱藏層的激活值。RMSNorm 的參數設置與Layer Normalization 相比更簡單,只有一個可學參數,可以更好地適應不同的任務和數據集。RMSNorm函數可以用以下數學公式表示:
RMSNorm(x)=x1n∑i=1nxi2+??γ\text{RMSNorm}(x) = \frac{x}{\sqrt{\frac{1}{n}\sum_{i=1}^{n}x_i^2 + \epsilon}} \cdot \gamma RMSNorm(x)=n1?∑i=1n?xi2?+??x??γ
其中:
- xix_ixi? 是輸入向量的第 iii 個元素
- γ\gammaγ 是可學習的縮放參數
- nnn 是輸入向量的維度數量
- ?\epsilon? 是一個小常數,用于數值穩定性(以避免除以零的情況)
這種歸一化有助于通過確保權重的規模不會變得過大或過小來穩定學習過程,這在具有許多層的深度學習模型中特別有用。
(2)預訓練任務
T5 模型的預訓練任務是一個關鍵的組成部分,它能使模型能夠學習到豐富的語言表示,語言表示能力可以在后續的微調過程中被遷移到各種下游任務。訓練所使用的數據集是一個大規模的文本數據集,包含了各種各樣的文本數據,如維基百科、新聞、書籍等等。對數據經過細致的處理后,生成了用于訓練的750GB 的數據集 C4,且已在 TensorflowData 中開源。
我們可以簡單概括一下 T5 的預訓練任務,主要包括以下幾個部分:
- 預訓練任務: T5模型的預訓練任務是 MLM,也稱為BERT-style目標。具體來說,就是在輸入文本中隨機遮蔽15%的token,然后讓模型預測這些被遮蔽的token。這個過程不需要標簽,可以在大量未標注的文本上進行。
- 輸入格式: 預訓練時,T5將輸入文本轉換為"文本到文本"的格式。對于一個給定的文本序列,隨機選擇一些token進行遮蔽,并用特殊的占位符(token)替換。然后將被遮蔽的token序列作為模型的輸出目標。
- 預訓練數據集: T5 使用了自己創建的大規模數據集"Colossal Clean Crawled Corpus"(C4),該數據集從Common Crawl中提取了大量干凈的英語文本。C4數據集經過了一定的清洗,去除了無意義的文本、重復文本等。
- 多任務預訓練: T5 還嘗試了將多個任務混合在一起進行預訓練,而不僅僅是單獨的MLM任務。這有助于模型學習更通用的語言表示。
- 預訓練到微調的轉換: 預訓練完成后,T5模型會在下游任務上進行微調。微調時,模型在任務特定的數據集上進行訓練,并根據任務調整解碼策略。
通過大規模預訓練,T5模型能夠學習到豐富的語言知識,并獲得強大的語言表示能力,在多個NLP任務上取得了優異的性能,預訓練是T5成功的關鍵因素之一。
(3)大一統思想
T5模型的一個核心理念是“大一統思想”,即所有的 NLP 任務都可以統一為文本到文本的任務,這一思想在自然語言處理領域具有深遠的影響。其設計理念是將所有不同類型的NLP任務(如文本分類、翻譯、文本生成、問答等)轉換為一個統一的格式:輸入和輸出都是純文本。
例如:
- 對于文本分類任務,輸入可以是“classify: 這是一個很好的產品”,輸出是“正面”;
- 對于翻譯任務,輸入可以是“translate English to French: How are you?”, 輸出是“Comment ?a va?”。
T5通過大規模的文本數據進行預訓練,然后在具體任務上進行微調。這一過程與BERT、GPT等模型類似,但T5將預訓練和微調階段的任務統一為文本到文本的形式,使其在各種任務上的適應性更強。
我們可以通過圖3.11,更加直觀地理解 T5 的大一統思想:
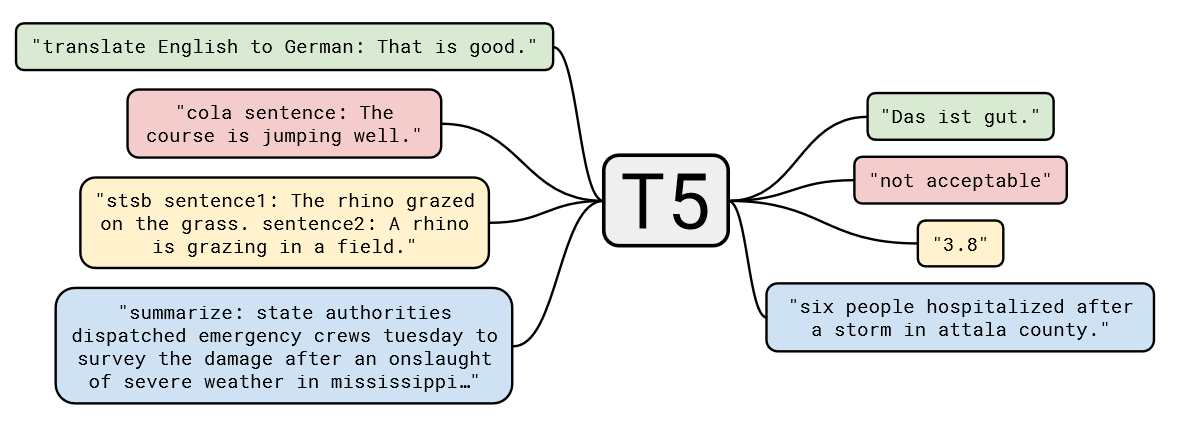
圖3.11 T5 的大一統思想
對于不同的NLP任務,每次輸入前都會加上一個任務描述前綴,明確指定當前任務的類型。這不僅幫助模型在預訓練階段學習到不同任務之間的通用特征,也便于在微調階段迅速適應具體任務。例如,任務前綴可以是“summarize: ”用于摘要任務,或“translate English to German: ”用于翻譯任務。
T5的大一統思想通過將所有NLP任務統一為文本到文本的形式,簡化了任務處理流程,增強了模型的通用性和適應性。這一思想不僅推動了自然語言處理技術的發展,也為實際應用提供了更為便捷和高效的解決方案。
3.3 Decoder-Only PLM
在前兩節中,我們分別講解了由 Transformer 發展而來的兩種模型架構——以 BERT 為代表的 Encoder-Only 模型和以 T5 為代表的 Encoder-Decoder 模型。那么,很自然可以想見,除了上述兩種架構,還可以有一種模型架構——Decoder-Only,即只使用 Decoder 堆疊而成的模型。
事實上,Decoder-Only 就是目前大火的 LLM 的基礎架構,目前所有的 LLM 基本都是 Decoder-Only 模型(RWKV、Mamba 等非 Transformer 架構除外)。而引發 LLM 熱潮的 ChatGPT,正是 Decoder-Only 系列的代表模型 GPT 系列模型的大成之作。而目前作為開源 LLM 基本架構的 LLaMA 模型,也正是在 GPT 的模型架構基礎上優化發展而來。因此,在本節中,我們不但會詳細分析 Decoder-Only 代表模型 GPT 的原理、架構和特點,還會深入到目前的主流開源 LLM,分析它們的結構、特點,結合之前對 Transformer 系列其他模型的分析,幫助大家深入理解當下被寄予厚望、被認為是 AGI 必經之路的 LLM 是如何一步步從傳統 PLM 中發展而來的。
首先,讓我們學習打開 LLM 世界大門的代表模型——由 OpenAI 發布的 GPT。
3.3.1 GPT
GPT,即 Generative Pre-Training Language Model,是由 OpenAI 團隊于 2018年發布的預訓練語言模型。雖然學界普遍認可 BERT 作為預訓練語言模型時代的代表,但首先明確提出預訓練-微調思想的模型其實是 GPT。GPT 提出了通用預訓練的概念,也就是在海量無監督語料上預訓練,進而在每個特定任務上進行微調,從而實現這些任務的巨大收益。雖然在發布之初,由于性能略輸于不久后發布的 BERT,沒能取得轟動性成果,也沒能讓 GPT 所使用的 Decoder-Only 架構成為學界研究的主流,但 OpenAI 團隊堅定地選擇了不斷擴大預訓練數據、增加模型參數,在 GPT 架構上不斷優化,最終在 2020年發布的 GPT-3 成就了 LLM 時代的基礎,并以 GPT-3 為基座模型的 ChatGPT 成功打開新時代的大門,成為 LLM 時代的最強競爭者也是目前的最大贏家。
本節將以 GPT 為例,分別從模型架構、預訓練任務、GPT 系列模型的發展歷程等三個方面深入分析 GPT 及其代表的 Decoder-Only 模型,并進一步引出當前的主流 LLM 架構——LLaMA。
(1) 模型架構——Decoder Only
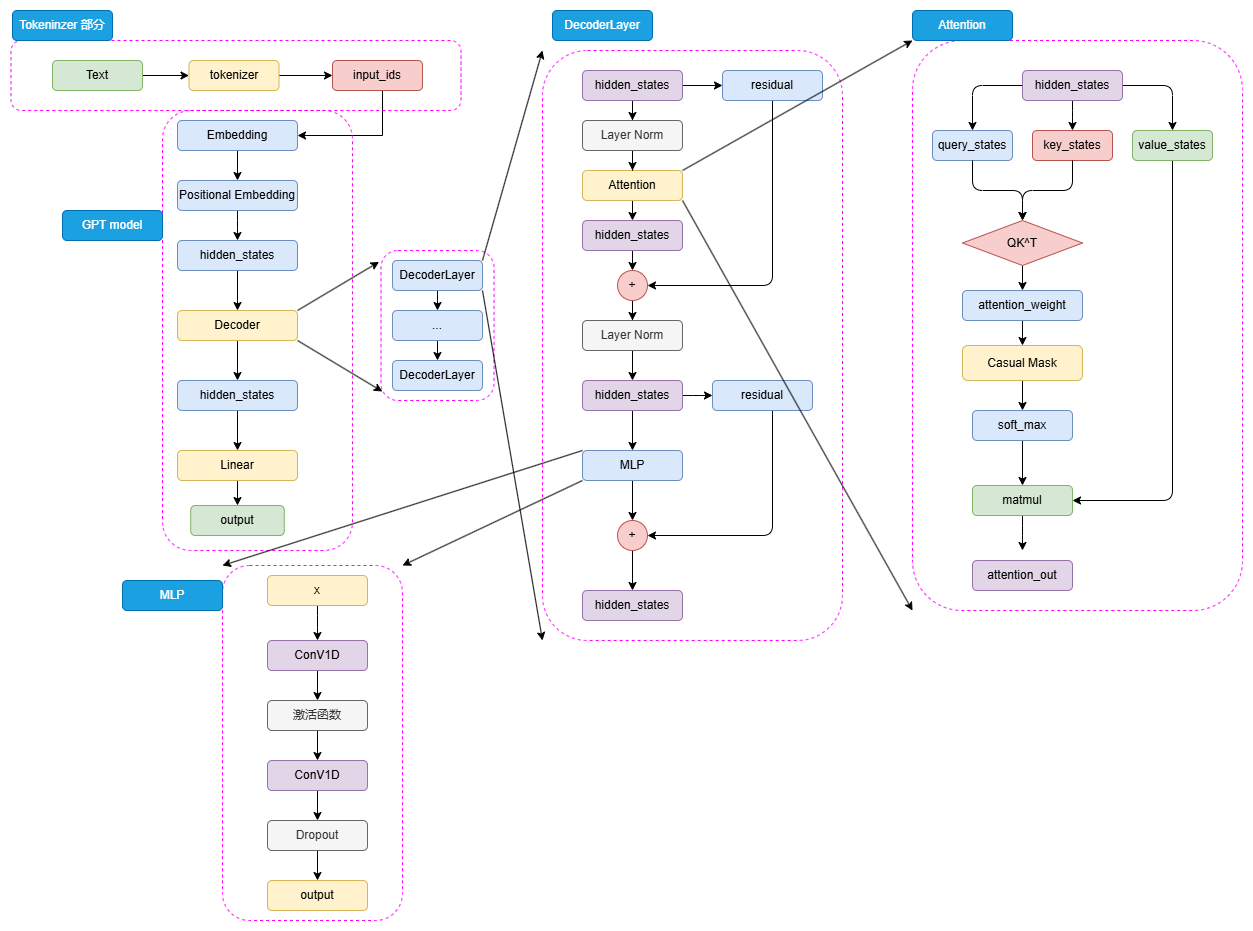
圖3.12 GPT 模型結構
如圖3.12可以看到,GPT 的整體結構和 BERT 是有一些類似的,只是相較于 BERT 的 Encoder,選擇使用了 Decoder 來進行模型結構的堆疊。由于 Decoder-Only 結構也天生適用于文本生成任務,所以相較于更貼合 NLU 任務設計的 BERT,GPT 和 T5 的模型設計更契合于 NLG 任務和 Seq2Seq 任務。同樣,對于一個自然語言文本的輸入,先通過 tokenizer 進行分詞并轉化為對應詞典序號的 input_ids。
輸入的 input_ids 首先通過 Embedding 層,再經過 Positional Embedding 進行位置編碼。不同于 BERT 選擇了可訓練的全連接層作為位置編碼,GPT 沿用了 Transformer 的經典 Sinusoidal 位置編碼,即通過三角函數進行絕對位置編碼,此處就不再贅述,感興趣的讀者可以參考第二章 Transformer 模型細節的解析。
通過 Embedding 層和 Positional Embedding 層編碼成 hidden_states 之后,就可以進入到解碼器(Decoder),第一代 GPT 模型和原始 Transformer 模型類似,選擇了 12層解碼器層,但是在解碼器層的內部,相較于 Transformer 原始 Decoder 層的雙注意力層設計,GPT 的 Decoder 層反而更像 Encoder 層一點。由于不再有 Encoder 的編碼輸入,Decoder 層僅保留了一個帶掩碼的注意力層,并且將 LayerNorm 層從 Transformer 的注意力層之后提到了注意力層之前。hidden_states 輸入 Decoder 層之后,會先進行 LayerNorm,再進行掩碼注意力計算,然后經過殘差連接和再一次 LayerNorm 進入到 MLP 中并得到最后輸出。
由于不存在 Encoder 的編碼結果,Decoder 層中的掩碼注意力也是自注意力計算。也就是對一個輸入的 hidden_states,會通過三個參數矩陣來生成 query、key 和 value,而不再是像 Transformer 中的 Decoder 那樣由 Encoder 輸出作為 key 和 value。后續的注意力計算過程則和 BERT 類似,只是在計算得到注意力權重之后,通過掩碼矩陣來遮蔽了未來 token 的注意力權重,從而限制每一個 token 只能關注到它之前 token 的注意力,來實現掩碼自注意力的計算。
另外一個結構上的區別在于,GPT 的 MLP 層沒有選擇線性矩陣來進行特征提取,而是選擇了兩個一維卷積核來提取,不過,從效果上說這兩者是沒有太大區別的。通過 N 個 Decoder 層后的 hidden_states 最后經過線性矩陣映射到詞表維度,就可以轉化成自然語言的 token,從而生成我們的目標序列。
(2)預訓練任務——CLM
Decoder-Only 的模型結構往往更適合于文本生成任務,因此,Decoder-Only 模型往往選擇了最傳統也最直接的預訓練任務——因果語言模型,Casual Language Model,下簡稱 CLM。
CLM 可以看作 N-gram 語言模型的一個直接擴展。N-gram 語言模型是基于前 N 個 token 來預測下一個 token,CLM 則是基于一個自然語言序列的前面所有 token 來預測下一個 token,通過不斷重復該過程來實現目標文本序列的生成。也就是說,CLM 是一個經典的補全形式。例如,CLM 的輸入和輸出可以是:
input: 今天天氣
output: 今天天氣很input: 今天天氣很
output:今天天氣很好
因此,對于一個輸入目標序列長度為 256,期待輸出序列長度為 256 的任務,模型會不斷根據前 256 個 token、257個 token(輸入+預測出來的第一個 token)… 進行 256 次計算,最后生成一個序列長度為 512 的輸出文本,這個輸出文本前 256 個 token 為輸入,后 256 個 token 就是我們期待的模型輸出。
在前面我們說過,BERT 之所以可以采用預訓練+微調的范式取得重大突破,正是因為其選擇的 MLM、NSP 可以在海量無監督語料上直接訓練——而很明顯,CLM 是更直接的預訓練任務,其天生和人類書寫自然語言文本的習慣相契合,也和下游任務直接匹配,相對于 MLM 任務更加直接,可以在任何自然語言文本上直接應用。因此,CLM 也可以使用海量的自然語言語料進行大規模的預訓練。
(3)GPT 系列模型的發展
自 GPT-1 推出開始,OpenAI 一直堅信 Decoder-Only 的模型結構和“體量即正義”的優化思路,不斷擴大預訓練數據集、模型體量并對模型做出一些小的優化和修正,來不斷探索更強大的預訓練模型。從被 BERT 壓制的 GPT-1,到沒有引起足夠關注的 GPT-2,再到激發了涌現能力、帶來大模型時代的 GPT-3,最后帶來了跨時代的 ChatGPT,OpenAI 通過數十年的努力證明了其思路的正確性。
下表總結了從 GPT-1 到 GPT-3 的模型結構、預訓練語料大小的變化:
| 模型 | Decoder Layer | Hidden_size | 注意力頭數 | 注意力維度 | 總參數量 | 預訓練語料 |
|---|---|---|---|---|---|---|
| GPT-1 | 12 | 3072 | 12 | 768 | 0.12B | 5GB |
| GPT-2 | 48 | 6400 | 25 | 1600 | 1.5B | 40GB |
| GPT-3 | 96 | 49152 | 96 | 12288 | 175B | 570GB |
GPT-1 是 GPT 系列的開山之作,也是第一個使用 Decoder-Only 的預訓練模型。但是,GPT-1 的模型體量和預訓練數據都較少,沿承了傳統 Transformer 的模型結構,使用了 12層 Decoder Block 和 768 的隱藏層維度,模型參數量僅有 1.17億(0.12B),在大小為 5GB 的 BooksCorpus 數據集上預訓練得到。可以看到,GPT-1 的參數規模與預訓練規模和 BERT-base 是大致相當的,但其表現相較于 BERT-base 卻有所不如,這也是 GPT 系列模型沒能成為預訓練語言模型時代的代表的原因。
GPT-2 則是 OpenAI 在 GPT-1 的基礎上進一步探究預訓練語言模型多任務學習能力的產物。GPT-2 的模型結構和 GPT-1 大致相當,只是擴大了模型參數規模、將 Post-Norm 改為了 Pre-Norm(也就是先進行 LayerNorm 計算,再進入注意力層計算)。這些改動的核心原因在于,由于模型層數增加、體量增大,梯度消失和爆炸的風險也不斷增加,為了使模型梯度更穩定對上述結構進行了優化。
GPT-2 的核心改進是大幅增加了預訓練數據集和模型體量。GPT-2 的 Decoder Block 層數達到了48(注意,GPT-2 共發布了四種規格的模型,此處我們僅指規格最大的 GPT-2 模型),隱藏層維度達到了 1600,模型整體參數量達 15億(1.5B),使用了自己抓取的 40GB 大小的 WebText 數據集進行預訓練,不管是模型結構還是預訓練大小都超過了 1代一個數量級。
GPT-2 的另一個重大突破是以 zero-shot(零樣本學習)為主要目標,也就是不對模型進行微調,直接要求模型解決任務。例如,在傳統的預訓練-微調范式中,我們要解決一個問題,一般需要收集幾百上千的訓練樣本,在這些訓練樣本上微調預訓練語言模型來實現該問題的解決。而 zero-shot 則強調不使用任何訓練樣本,直接通過向預訓練語言模型描述問題來去解決該問題。zero-shot 的思路自然是比預訓練-微調范式更進一步、更高效的自然語言范式,但是在 GPT-2 的時代,模型能力還不足夠支撐較好的 zero-shot 效果,在大模型時代,zero-shot 及其延伸出的 few-shot(少樣本學習)才開始逐漸成為主流。
GPT-3 則是更進一步展示了 OpenAI“力大磚飛”的核心思路,也是 LLM 的開創之作。在 GPT-2 的基礎上,OpenAI 進一步增大了模型體量和預訓練數據量,整體參數量達 175B,是當之無愧的“大型語言模型”。在模型結構上,基本沒有大的改進,只是由于巨大的模型體量使用了稀疏注意力機制來取代傳統的注意力機制。在預訓練數據上,則是分別從 CC、WebText、維基百科等大型語料集中采樣,共采樣了 45T、清洗后 570GB 的數據。根據推算,GPT-3 需要在 1024張 A100(80GB 顯存)的分布式訓練集群上訓練 1個月。
之所以說 GPT-3 是 LLM 的開創之作,除去其巨大的體量帶來了涌現能力的凸顯外,還在于其提出了 few-shot 的重要思想。few-shot 是在 zero-shot 上的改進,研究者發現即使是 175B 大小的 GPT-3,想要在 zero-shot 上取得較好的表現仍然是一件較為困難的事情。而 few-shot 是對 zero-shot 的一個折中,旨在提供給模型少樣的示例來教會它完成任務。few-shot 一般會在 prompt(也就是模型的輸入)中增加 3~5個示例,來幫助模型理解。例如,對于情感分類任務:
zero-shot:請你判斷‘這真是一個絕佳的機會’的情感是正向還是負向,如果是正向,輸出1;否則輸出0few-shot:請你判斷‘這真是一個絕佳的機會’的情感是正向還是負向,如果是正向,輸出1;否則輸出0。你可以參考以下示例來判斷:‘你的表現非常好’——1;‘太糟糕了’——0;‘真是一個好主意’——1。
通過給模型提供少量示例,模型可以取得遠好于 zero-shot 的良好表現。few-shot 也被稱為上下文學習(In-context Learning),即讓模型從提供的上下文中的示例里學習問題的解決方法。GPT-3 在 few-shot 上展現的強大能力,為 NLP 的突破帶來了重要進展。如果對于絕大部分任務都可以通過人為構造 3~5個示例就能讓模型解決,其效率將遠高于傳統的預訓練-微調范式,意味著 NLP 的進一步落地應用成為可能——而這,也正是 LLM 的核心優勢。
在 GPT 系列模型的基礎上,通過引入預訓練-指令微調-人類反饋強化學習的三階段訓練,OpenAI 發布了跨時代的 ChatGPT,引發了大模型的熱潮。也正是在 GPT-3 及 ChatGPT 的基礎上,LLaMA、ChatGLM 等模型的發布進一步揭示了 LLM 的無盡潛力。在下一節,我們將深入剖析目前 LLM 的普適架構——LLaMA。
3.3.2 LLaMA
LLaMA模型是由Meta(前Facebook)開發的一系列大型預訓練語言模型。從LLaMA-1到LLaMA-3,LLaMA系列模型展示了大規模預訓練語言模型的演進及其在實際應用中的顯著潛力。
(1) 模型架構——Decoder Only
與GPT系列模型一樣,LLaMA模型也是基于Decoder-Only架構的預訓練語言模型。LLaMA模型的整體結構與GPT系列模型類似,只是在模型規模和預訓練數據集上有所不同。如圖3.13是LLaMA模型的架構示意圖:
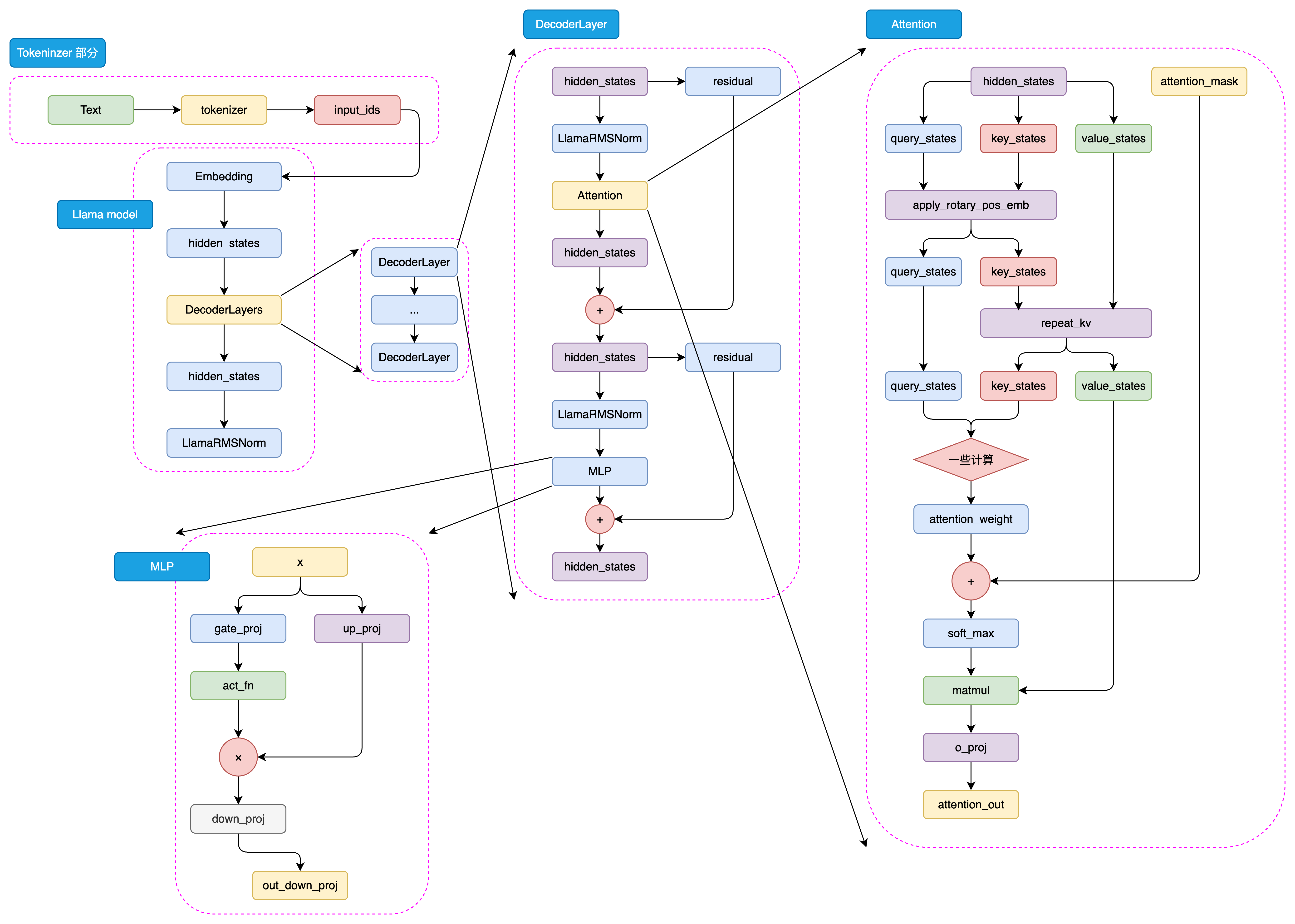
圖3.13 LLaMA-3 模型結構
與GPT類似,LLaMA模型的處理流程也始于將輸入文本通過tokenizer進行編碼,轉化為一系列的input_ids。這些input_ids是模型能夠理解和處理的數據格式。接下來,這些input_ids會經過embedding層的轉換,這里每個input_id會被映射到一個高維空間中的向量,即詞向量。同時,輸入文本的位置信息也會通過positional embedding層被編碼,以確保模型能夠理解詞序上下文信息。
這樣,input_ids經過embedding層和positional embedding層的結合,形成了hidden_states。hidden_states包含了輸入文本的語義和位置信息,是模型進行后續處理的基礎,hidden_states隨后被輸入到模型的decoder層。
在decoder層中,hidden_states會經歷一系列的處理,這些處理由多個decoder block組成。每個decoder block都是模型的核心組成部分,它們負責對hidden_states進行深入的分析和轉換。在每個decoder block內部,首先是一個masked self-attention層。在這個層中,模型會分別計算query、key和value這三個向量。這些向量是通過hidden_states線性變換得到的,它們是計算注意力權重的基礎。然后使用softmax函數計算attention score,這個分數反映了不同位置之間的關聯強度。通過attention score,模型能夠確定在生成當前詞時,應該給予不同位置的hidden_states多大的關注。然后,模型將value向量與attention score相乘,得到加權后的value,這就是attention的結果。
在完成masked self-attention層之后,hidden_states會進入MLP層。在這個多層感知機層中,模型通過兩個全連接層對hidden_states進行進一步的特征提取。第一個全連接層將hidden_states映射到一個中間維度,然后通過激活函數進行非線性變換,增加模型的非線性能力。第二個全連接層則將特征再次映射回原始的hidden_states維度。
最后,經過多個decoder block的處理,hidden_states會通過一個線性層進行最終的映射,這個線性層的輸出維度與詞表維度相同。這樣,模型就可以根據hidden_states生成目標序列的概率分布,進而通過采樣或貪婪解碼等方法,生成最終的輸出序列。這一過程體現了LLaMA模型強大的序列生成能力。
(2) LLaMA模型的發展歷程
LLaMA-1 系列:
- Meta于2023年2月發布了LLaMA-1,包括7B、13B、30B和65B四個參數量版本。
- 這些模型在超過1T token的語料上進行了預訓練,其中最大的65B參數模型在2,048張A100 80G GPU上訓練了近21天。
- LLaMA-1因其開源性和優異性能迅速成為開源社區中最受歡迎的大模型之一。
LLaMA-2 系列:
- 2023年7月,Meta發布了LLaMA-2,包含7B、13B、34B和70B四個參數量版本,除了34B模型外,其他均已開源。
- LLaMA-2將預訓練的語料擴充到了2T token,并將模型的上下文長度從2,048翻倍到了4,096。
- 引入了分組查詢注意力機制(Grouped-Query Attention, GQA)等技術。
LLaMA-3 系列:
- 2024年4月,Meta發布了LLaMA-3,包括8B和70B兩個參數量版本,同時透露400B的LLaMA-3還在訓練中。
- LLaMA-3支持8K長文本,并采用了編碼效率更高的tokenizer,詞表大小為128K。
- 使用了超過15T token的預訓練語料,是LLaMA-2的7倍多。
LLaMA模型以其技術創新、多參數版本、大規模預訓練和高效架構設計而著稱。模型支持從7億到數百億不等的參數量,適應不同規模的應用需求。LLaMA-1以其開源性和優異性能迅速受到社區歡迎,而LLaMA-2和LLaMA-3進一步通過引入分組查詢注意力機制和支持更長文本輸入,顯著提升了模型性能和應用范圍。特別是LLaMA-3,通過采用128K詞表大小的高效tokenizer和15T token的龐大訓練數據,實現了在多語言和多任務處理上的重大進步。Meta對模型安全性和社區支持的持續關注,預示著LLaMA將繼續作為AI技術發展的重要推動力,促進全球范圍內的技術應用和創新。
3.3.3 GLM
GLM 系列模型是由智譜開發的主流中文 LLM 之一,包括 ChatGLM1、2、3及 GLM-4 系列模型,覆蓋了指令理解、代碼生成等多種應用場景,曾在多種中文評估集上達到 SOTA 性能。
ChatGLM-6B 是 GLM 系列的開山之作,也是 2023年國內最早的開源中文 LLM,也是最早提出不同于 GPT、LLaMA 的獨特模型架構的 LLM。在整個中文 LLM 的發展歷程中,GLM 具有獨特且重大的技術意義。本節將簡要敘述 GLM 系列的發展,并介紹其不同于 GPT、LLaMA 系列模型的獨特技術思路。
(1)模型架構-相對于 GPT 的略微修正
GLM 最初是由清華計算機系推出的一種通用語言模型基座,其核心思路是在傳統 CLM 預訓練任務基礎上,加入 MLM 思想,從而構建一個在 NLG 和 NLU 任務上都具有良好表現的統一模型。
在整體模型結構上,GLM 和 GPT 大致類似,均是 Decoder-Only 的結構,僅有三點細微差異:
-
使用 Post Norm 而非 Pre Norm。Post Norm 是指在進行殘差連接計算時,先完成殘差計算,再進行 LayerNorm 計算;而類似于 GPT、LLaMA 等模型都使用了 Pre Norm,也就是先進行 LayerNorm 計算,再進行殘差的計算。相對而言,Post Norm 由于在殘差之后做歸一化,對參數正則化的效果更強,進而模型的魯棒性也會更好;Pre Norm相對于因為有一部分參數直接加在了后面,不需要對這部分參數進行正則化,正好可以防止模型的梯度爆炸或者梯度消失。因此,對于更大體量的模型來說,一般認為 Pre Norm 效果會更好。但 GLM 論文提出,使用 Post Norm 可以避免 LLM 的數值錯誤(雖然主流 LLM 仍然使用了 Pre Norm);
-
使用單個線性層實現最終 token 的預測,而不是使用 MLP;這樣的結構更加簡單也更加魯棒,即減少了最終輸出的參數量,將更大的參數量放在了模型本身;
-
激活函數從 ReLU 換成了 GeLUs。ReLU 是傳統的激活函數,其核心計算邏輯為去除小于 0的傳播,保留大于 0的傳播;GeLUs 核心是對接近于 0的正向傳播,做了一個非線性映射,保證了激活函數后的非線性輸出,具有一定的連續性。
(2)預訓練任務-GLM
GLM 的核心創新點主要在于其提出的 GLM(General Language Model,通用語言模型)任務,這也是 GLM 的名字由來。GLM 是一種結合了自編碼思想和自回歸思想的預訓練方法。所謂自編碼思想,其實也就是 MLM 的任務學習思路,在輸入文本中隨機刪除連續的 tokens,要求模型學習被刪除的 tokens;所謂自回歸思想,其實就是傳統的 CLM 任務學習思路,也就是要求模型按順序重建連續 tokens。
GLM 通過優化一個自回歸空白填充任務來實現 MLM 與 CLM 思想的結合。其核心思想是,對于一個輸入序列,會類似于 MLM 一樣進行隨機的掩碼,但遮蔽的不是和 MLM 一樣的單個 token,而是每次遮蔽一連串 token;模型在學習時,既需要使用遮蔽部分的上下文預測遮蔽部分,在遮蔽部分內部又需要以 CLM 的方式完成被遮蔽的 tokens 的預測。例如,輸入和輸出可能是:
輸入:I <MASK> because you <MASK>
輸出:<MASK> - love you; <MASK> - are a wonderful person
通過將 MLM 與 CLM 思想相結合,既適配逐個 token 生成的生成類任務,也迫使模型從前后兩個方向學習輸入文本的隱含關系從而適配了理解類任務。使用 GLM 預訓練任務產出的 GLM 模型,在一定程度上展現了其超出同體量 BERT 系模型的優越性能:
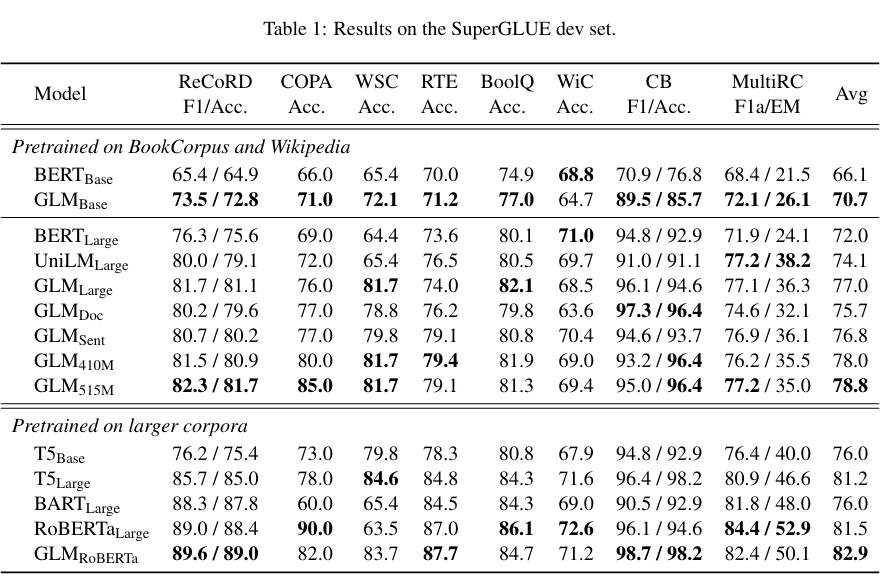
圖3.14 alt text
不過,GLM 預訓練任務更多的優勢還是展現在預訓練模型時代,邁入 LLM 時代后,針對于超大規模、體量的預訓練,CLM 展現出遠超 MLM 的優勢。通過將模型體量加大、預訓練規模擴大,CLM 預訓練得到的生成模型在文本理解上也能具有超出 MLM 訓練的理解模型的能力,因此,ChatGLM 系列模型也僅在第一代模型使用了 GLM 的預訓練思想,從 ChatGLM2 開始,還是回歸了傳統的 CLM 建模。雖然從 LLM 的整體發展路徑來看,GLM 預訓練任務似乎是一個失敗的嘗試,但通過精巧的設計將 CLM 與 MLM 融合,并第一時間產出了中文開源的原生 LLM,其思路仍然存在較大的借鑒意義。
(3)GLM 家族的發展
在 GLM 模型(即使用原生 GLM 架構及預訓練任務的早期預訓練模型)的基礎上,參考 ChatGPT 的技術思路進行 SFT 和 RLHF,智譜于 23年 3月發布了第一個中文開源 LLM ChatGLM-6B,成為了眾多中文 LLM 研究者的起點。ChatGLM-6B 在 1T 語料上進行預訓練,支持 2K 的上下文長度。
在 23年 6月,智譜就開源了 ChatGLM2-6B。相對于一代,ChatGLM2 將上下文長度擴展到了 32K,通過更大的預訓練規模實現了模型性能的大幅度突破。不過,在 ChatGLM2 中,模型架構就基本回歸了 LLaMA 架構,引入 MQA 的注意力機制,預訓練任務也回歸經典的 CLM,放棄了 GLM 的失敗嘗試。
ChatGLM3-6B 發布于 23年 10月,相對于二代在語義、數學、推理、代碼和知識方面都達到了當時的 SOTA 性能,但是官方給出的技術報告說明 ChatGLM3 在模型架構上相對二代沒有變化,最主要的優化來源是更多樣化的訓練數據集、更充足的訓練步驟和更優化的訓練策略。ChatGLM3 的另一個重要改進在于其開始支持函數調用與代碼解釋器,開發者可以直接使用開源的 ChatGLM3 來實現 Agent 開發,具有更廣泛的應用價值。
2024年 1月,智譜發布了支持 128K 上下文,包括多種類型的 GLM-4 系列模型,評估其在英文基準上達到了 GPT-4 的水平。不過,智譜并未直接開源 GLM-4,而是開源了其輕量級版本 GLM-4-9B 模型,其在 1T token 的多語言語料庫上進行預訓練,上下文長度為 8K,并使用與 GLM-4 相同的管道和數據進行后訓練。在訓練計算量較少的情況下,其超越了 Llama-3-8B,并支持 GLM-4 中所有工具的功能。
圖3.15展示了 GLM 系列模型在基準集上的表現演進:
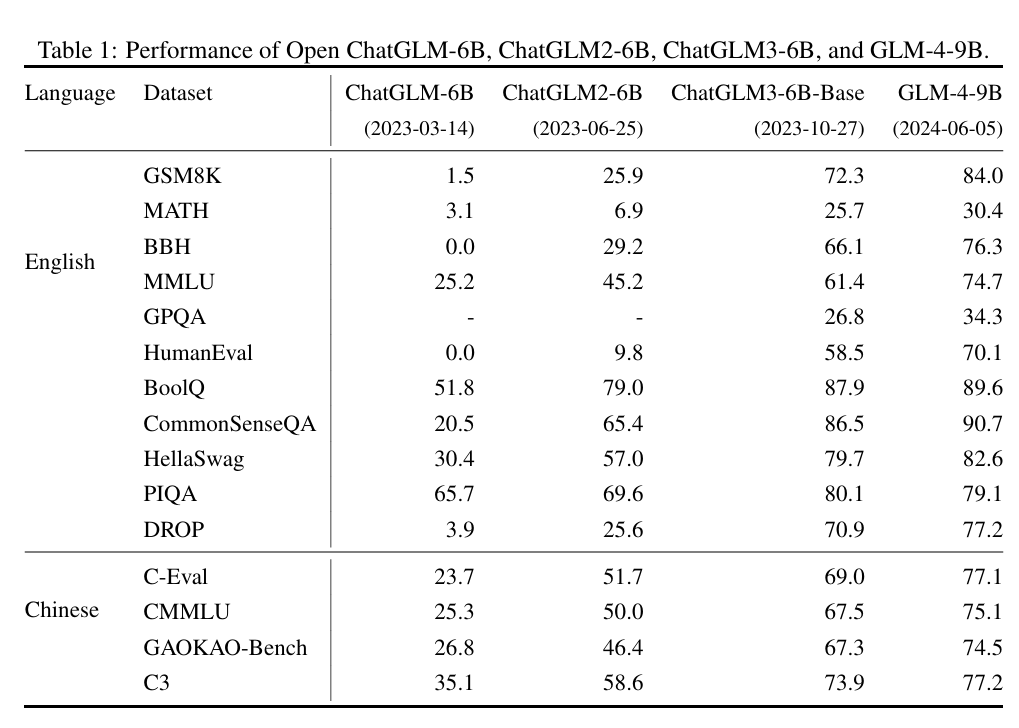
圖3.15 alt text









--Java版)


視頻剪裁)






