引言:你其實早就 “玩轉” 過機器學習?
提到 “機器學習”,你是不是第一時間聯想到復雜的代碼、密密麻麻的公式,還有那些讓人頭暈的 “算法”“模型”“訓練” 術語?仿佛它是高高在上的技術,離我們的日常無比遙遠?
但今天我要揭開一個小秘密:你可能早就在不知不覺中 “用過” 機器學習了!
想想看,你是否在 Excel 里處理過這樣的數據:比如 “廣告投入(x)與銷售額(y)”,假設你有 10 組數據(如下表),先把數據輸入 Excel 并插入散點圖,然后右鍵點擊圖表,選擇 “添加趨勢線”,再從彈出的選項里挑 “線性” 類型 —— 很快,Excel 就會畫出一條平滑的直線,旁邊還標注出趨勢線方程(比如 y=5.2x+18.6)和 R2 值(比如 0.92)。
廣告投入(萬元)x | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
銷售額(萬元)y | 25 | 30 | 38 | 42 | 48 | 55 | 62 | 68 | 75 | 80 |
別小看這個操作!當你完成這一系列步驟時,你已經親手完成了一次最基礎、最直觀的機器學習任務。而今天,我們就從這個你熟悉到不能再熟悉的 Excel 功能出發,一點點拆解機器學習的核心框架,讓那些看似高深的概念,都變得像 “添加趨勢線” 一樣簡單易懂。
第一部分:機器學習到底在做什么?—— 它的終極目標
其實機器學習的核心目標特別樸素,一句話就能說清:從已有數據中自動找出規律,再用這個規律預測未來的結果。
它不像我們想象中那么 “玄乎”,本質上就是在解決 “根據已知推未知” 的問題。比如:
- 預測房價時,它會根據 “房屋面積、地段、房齡” 這些已知信息(輸入),找出它們和 “房價”(輸出)之間的關系,進而預測一套新房的價格;
- 識別垃圾郵件時,它會分析 “郵件標題、內容里的關鍵詞、發件人信息”,總結出垃圾郵件的特征,然后判斷一封新郵件是不是垃圾郵件;
- 電商 APP 給你推薦商品時,它會梳理你的 “瀏覽記錄、購買歷史、收藏列表”,找到你喜歡的商品類型,再推送你可能感興趣的新品。
如果用更數學的語言來描述,機器學習的本質就是尋找一個合適的數學函數 y = f (x)。這里的 x 是我們能拿到的 “輸入數據”(比如房屋信息、郵件內容),y 是我們想得到的 “輸出結果”(比如房價、是否為垃圾郵件),而 f (x) 就是連接 x 和 y 的 “規律”—— 我們一開始并不知道 f (x) 具體長什么樣,但機器學習能幫我們從海量數據中,把這個 “隱藏的函數” 給 “學” 出來。
第二部分:如何實現機器學習?—— 標準工作流程拆解
就像我們做任何事情都有步驟一樣,機器學習也有一套固定的、經過無數實踐驗證的 “標準工作流程”。把這個流程理清,你就掌握了機器學習的 “骨架”。整個過程可通過以下流程圖清晰展示,共分為 6 個關鍵步驟,每一步都有明確的目標:
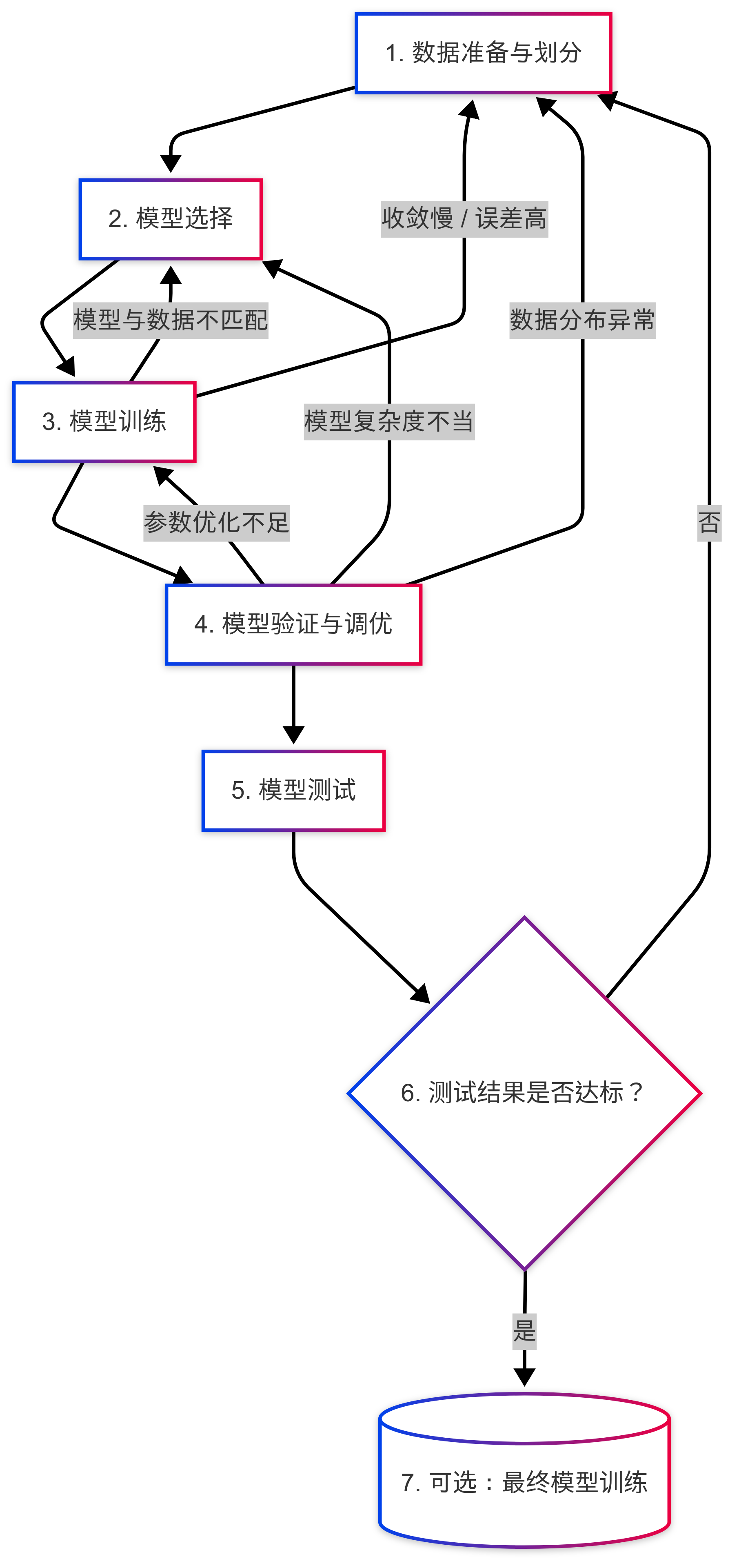
1. 數據準備與劃分:打好 “地基”
機器學習的一切都依賴數據,所以第一步必須把數據處理好。首先要做的是 “數據收集”—— 從數據庫、API 接口、Excel 表格等地方獲取需要的原始數據;然后是 “數據清洗”—— 刪除重復數據、填補缺失值、修正錯誤數據(比如把 “年齡 = 200” 這種明顯不合理的值處理掉),確保數據的準確性。
這一步里有個至關重要的操作:把清洗好的數據分成三部分 —— 訓練集、驗證集和測試集。它們的作用就像學生學習時的 “教材”“練習題” 和 “期末考試卷”,各自承擔不同的角色,缺一不可。比如上述 “廣告投入與銷售額” 數據,可按 7:2:1 的比例劃分,7 組數據作為訓練集,2 組作為驗證集,1 組作為測試集。
2. 模型選擇:選對 “工具”
數據準備好后,就要選擇 “模型” 了。模型其實就是我們前面提到的 “函數形式”,比如想找線性關系,就選 “線性模型”;想處理更復雜的非線性關系,就選 “決策樹”“神經網絡” 等。
這一步就像你修桌子時選擇工具:如果只是擰螺絲,用螺絲刀就夠了;如果要鋸木板,就得用鋸子。選對模型,后續的工作才能事半功倍。比如 “廣告投入與銷售額” 數據從散點圖看呈線性趨勢,選擇線性模型就很合適。
3. 模型訓練:讓模型 “學習” 規律
選好模型后,就進入 “訓練” 階段。我們會把 “訓練集” 數據輸入到模型里,讓模型通過專門的 “優化算法”(比如梯度下降),自動調整內部的 “參數”(比如線性模型 y=wx+b 里的 w 和 b)。
這個過程就像學生看教材學習:模型會不斷對比自己的 “預測結果” 和訓練集中的 “真實結果”,然后一點點修正參數,直到預測結果和真實結果的差距(誤差)越來越小 —— 就像學生通過看書,不斷糾正自己對知識點的理解一樣。比如用 “廣告投入與銷售額” 的 7 組訓練數據訓練線性模型,最終得到 w=5.2、b=18.6 的參數。
4. 模型驗證與調優:幫模型 “查漏補缺”
訓練完模型,不能直接用,得先 “檢驗” 一下它的水平。這時候 “驗證集” 就派上用場了:我們把驗證集數據輸入到訓練好的模型里,看它的預測效果如何(比如用準確率、誤差值等指標評估)。
如果效果不好,就要進行 “調優”:比如調整 “超參數”(不是模型內部的參數,而是我們人為設定的配置,比如學習率、決策樹的深度),或者換一個更合適的模型,然后重新訓練、重新驗證 —— 這個過程就像學生做練習題,發現哪里不會就回頭復習,直到練習題的正確率達標。
5. 模型測試:給模型做 “最終考核”
當模型在驗證集上表現足夠好時,就該用 “測試集” 做最終評估了。這里有個關鍵原則:測試集的數據,模型在訓練和驗證階段絕對不能見過。
因為測試集的作用是模擬 “真實的未知場景”,評估模型在沒見過的數據上的表現 —— 就像期末考試的題目都是學生沒做過的,只有這樣才能真實反映學生的學習水平。如果測試集的結果達標,說明這個模型可以用了;如果不達標,就得回到前面的步驟,重新優化。
6. (可選)最終模型訓練:讓模型 “火力全開”
如果測試結果滿意,還有一個可選步驟:把 “訓練集 + 驗證集” 合并成新的訓練數據,用之前確定好的模型和超參數,重新訓練一次,得到最終的部署模型。
為什么要這么做?因為驗證集本來也是優質數據,把它加進來一起訓練,能讓模型學到更多規律,性能更穩定 —— 就像學生考完試后,把教材和練習題再復習一遍,鞏固所有知識點,然后再去應對實際問題。
第三部分:核心概念速覽:5 分鐘搞懂關鍵術語
在繼續往下聊之前,我們先把幾個最核心的術語明確一下,避免后面出現理解偏差。這些術語就像機器學習的 “基礎詞匯”,記住它們,就能輕松看懂大部分內容:
- 模型 (Model):就是我們假設的 “函數形式”,比如線性模型 y=wx+b、決策樹模型、神經網絡模型等,它決定了我們用什么 “方式” 去尋找數據中的規律。
- 參數 (Parameters):模型內部可以自動學習的變量,比如線性模型里的 w(斜率)和 b(截距),訓練的過程就是調整這些參數的過程。
- 超參數 (Hyperparameters):需要我們在訓練前人為設定的 “配置項”,比如學習率(控制參數調整的速度)、決策樹的最大深度(控制模型的復雜度),超參數不能靠模型自動學習,只能通過驗證集調優。
- 訓練集 (Training Set):用來 “教” 模型學習的數據集,相當于學生的 “教材”,模型主要靠它來學習規律。
- 驗證集 (Validation Set):用來 “檢驗模型學習效果” 并 “調優” 的數據集,相當于學生的 “練習題”,幫助我們找到模型的最佳配置。
- 測試集 (Test Set):用來 “評估模型最終能力” 的數據集,相當于學生的 “期末考試卷”,是對模型真實性能的最終檢驗。
- 過擬合 (Overfitting):模型的 “致命問題” 之一。指模型把訓練數據里的 “噪聲”(比如數據記錄時的偶然誤差)都當成了 “規律”,導致在訓練集上表現很好,但在新數據(比如測試集)上表現很差。就像學生死記硬背了練習題的答案,換一道新題就不會做了。
第四部分:類比強化:Excel 擬合曲線 vs. 機器學習
機器學習的核心目的是預測未知,即當遇到未在訓練數據中出現的輸入 x 時,能通過學到的規律(模型)計算出對應的輸出 y。這一點在 Excel 擬合曲線操作中也有直觀體現,我們結合 “廣告投入與銷售額” 的 Excel 實操例子,把 Excel 的 “趨勢線” 操作和機器學習的標準流程完整對比:
Excel 擬合曲線實操示例
先將 “廣告投入與銷售額” 的 10 組數據輸入 Excel,A 列是 x(廣告投入),B 列是 y(銷售額),插入散點圖后,右鍵點擊散點選擇 “添加趨勢線”:
- 選 “線性” 趨勢線:Excel 自動生成趨勢線方程 y=5.2x+18.6,R2=0.92,散點圖上呈現一條穿過數據點中心的直線,能較好反映兩者線性關系;
- 若選 “多項式” 且階數設為 5:趨勢線會扭曲地穿過幾乎所有散點,但 R2 接近 1,此時若代入 x=11(未知廣告投入),計算出的 y 值會與實際預期偏差極大,這就是過擬合。
流程對比表
機器學習步驟 | Excel 擬合曲線操作(以 “廣告投入與銷售額” 為例) | 類比說明 |
1. 數據準備 | 將 x(1-10)、y(25-80)分別輸入 Excel A、B 列,整理成表格 | 無論是機器學習還是 Excel 擬合,“干凈的原始數據” 都是基礎,數據亂了,后續都白搭。 |
2. 數據劃分 | (隱含操作)心里確定用前 7 組數據畫趨勢線(訓練),留后 3 組檢驗(2 組驗證、1 組測試) | Excel 沒有明確的 “劃分” 功能,但理想情況下,會留部分數據檢驗,也能對 x=11 這類未知值預測。 |
3. 模型選擇 | 右鍵散點圖→“添加趨勢線”→選 “線性”(而非 “多項式”) | 選 “線性” 趨勢線,就是機器學習里的 “模型選擇”,為后續預測未知數據(如 x=11)打基礎。 |
4. 訓練與調參 | Excel 自動計算出趨勢線斜率 5.2、截距 18.6,生成方程 y=5.2x+18.6 | Excel 將 “選模型” 和 “算參數” 合并;機器學習則分開,先選線性模型,再用訓練集調參,最終都得到能預測未知的 “函數表達式”。 |
5. 模型評估 | 查看 R2=0.92(擬合優度高),且用第 8 組 x=8 驗證,預測 y=5.2×8+18.6=59.2,接近真實 y=68(誤差較小) | R2 越接近 1,對已知數據擬合越好,對未知數據預測越可靠,和機器學習用測試集驗證邏輯一致。 |
6. 警惕過擬合 | 選 5 階多項式,趨勢線扭曲穿過所有散點,但用 x=10 測試,預測 y 與真實 80 偏差大 | 這就是 “過擬合”!曲線貼合現有數據,卻丟失真實規律,導致未知 x 預測偏差大,機器學習需用驗證集避免。 |
7. 預測未知(核心目的) | 代入未知 x=11(廣告投入 11 萬元),用方程算 y=5.2×11+18.6=75.8(預測銷售額 75.8 萬元) | 這是機器學習核心目標的體現!機器學習訓練模型,就是為了對新輸入 x 輸出準確 y,Excel 算未知 y 同理。 |
這個類比的精髓,可總結成五句話,覆蓋機器學習核心目的:
- Excel 的 “趨勢線類型(如線性)” = 機器學習的 “模型選擇”,都是找合適規律形式;
- Excel 的 “斜率 5.2、截距 18.6” = 機器學習的 “參數”,構成預測未知的 “函數核心”;
- Excel 的 “R2=0.92 + 驗證集檢驗” = 機器學習的 “評估指標 + 測試集驗證”,判斷預測可靠性;
- Excel 的 “5 階多項式扭曲曲線” = 機器學習的 “過擬合”,都讓模型失去預測未知能力;
- Excel“x=11 算 y=75.8” = 機器學習 “用模型預測未知”,核心都是從已知推未知。
總結:從 Excel 到 AI,只差一套 “系統化流程”
看到這里,你應該能明白:機器學習不是什么 “魔法”,它和你在 Excel 里給 “廣告投入與銷售額” 數據畫線性趨勢線、算 x=11 對應 y 值的本質是一樣的 —— 都是找數據背后的數學關系,都是 “從已知推未知”。
但兩者的區別也很明顯:Excel 的擬合是 “簡單版”,適合少量、簡單數據,預測靠手動代入;而機器學習是 “進階版”,通過 “明確劃分數據集”“分離模型選擇與參數訓練”“用驗證集調優” 等系統機制,避免人為偏差,能處理百萬級數據和復雜模型(如圖像識別神經網絡),還能自動化預測。
開箱狀態預裝OEM原廠Win11系統)
)




)












