項目一 鳶尾花分類
該項目需要下載scikit-learn庫,下載指令如下:pip install scikit-learn
快速入門示例:鳶尾花分類
# 導入必要模塊
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score# 1. 加載數據集
iris = load_iris()
X = iris.data # 特征數據(150個樣本,4個特征)
y = iris.target # 標簽(0,1,2 代表三種鳶尾花)# 2. 劃分訓練集和測試集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42
)# 3. 創建并訓練模型
model = DecisionTreeClassifier(max_depth=3)
model.fit(X_train, y_train)# 4. 預測測試集
y_pred = model.predict(X_test)# 5. 評估準確率
accuracy = accuracy_score(y_test, y_pred)
print(f"模型準確率: {accuracy:.2f}") # 輸出示例:模型準確率: 1.00
1. 數據預處理
from sklearn.preprocessing import StandardScaler, OneHotEncoder
from sklearn.impute import SimpleImputer# 數值特征標準化
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X_train)# 分類特征編碼
encoder = OneHotEncoder()
encoded_features = encoder.fit_transform(categorical_data)# 缺失值填充(用均值)
imputer = SimpleImputer(strategy='mean')
X_imputed = imputer.fit_transform(X_missing)
2. 模型訓練與評估
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import classification_report# 使用隨機森林
model = RandomForestClassifier(n_estimators=100)
model.fit(X_train, y_train)# 詳細評估報告
report = classification_report(y_test, model.predict(X_test))
print(report)
3. 模型選擇與交叉驗證
from sklearn.model_selection import cross_val_score
from sklearn.svm import SVC# 10折交叉驗證
scores = cross_val_score(SVC(), X, y, cv=10)
print(f"平均準確率: {scores.mean():.2f} ± {scores.std():.2f}")
4. 管道(Pipeline)整合流程
from sklearn.pipeline import make_pipeline# 創建預處理+模型的完整管道
pipeline = make_pipeline(StandardScaler(),RandomForestClassifier()
)# 直接訓練和預測
pipeline.fit(X_train, y_train)
pipeline.score(X_test, y_test)
常用模型速查
| 任務類型 | 算法 | 導入路徑 |
|---|---|---|
| 分類 | 邏輯回歸 | sklearn.linear_model.LogisticRegression |
| 支持向量機 (SVM) | sklearn.svm.SVC | |
| 隨機森林 | sklearn.ensemble.RandomForestClassifier | |
| 回歸 | 線性回歸 | sklearn.linear_model.LinearRegression |
| 梯度提升樹 | sklearn.ensemble.GradientBoostingRegressor | |
| 聚類 | K-Means | sklearn.cluster.KMeans |
| 降維 | PCA | sklearn.decomposition.PCA |
項目實現
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split, cross_val_score
from sklearn.preprocessing import StandardScaler
from sklearn.neighbors import KNeighborsClassifier
from sklearn.svm import SVC
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import classification_report, confusion_matrix, accuracy_score
from sklearn.decomposition import PCA# 設置中文顯示
plt.rcParams["font.family"] = ["SimHei"]
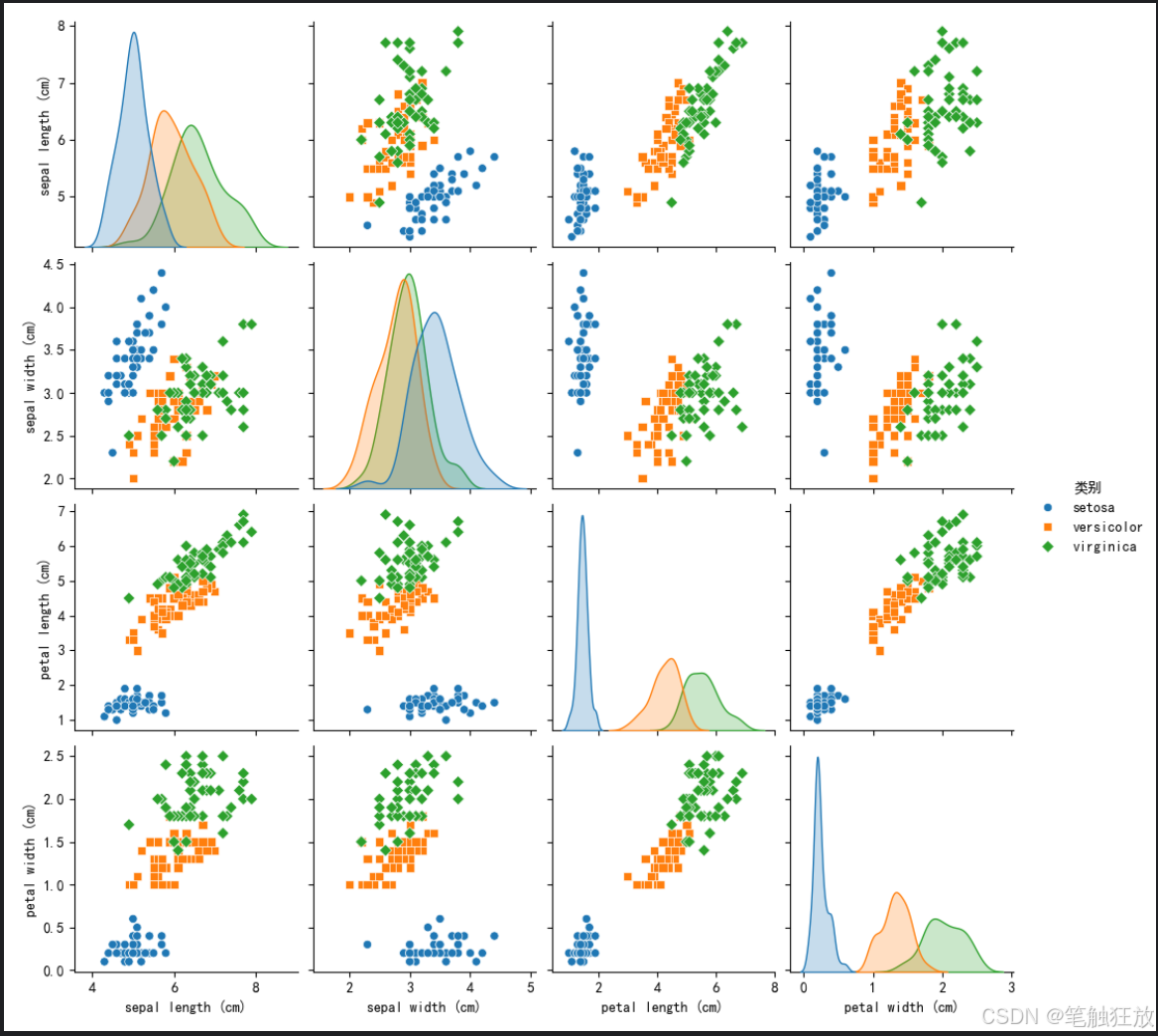
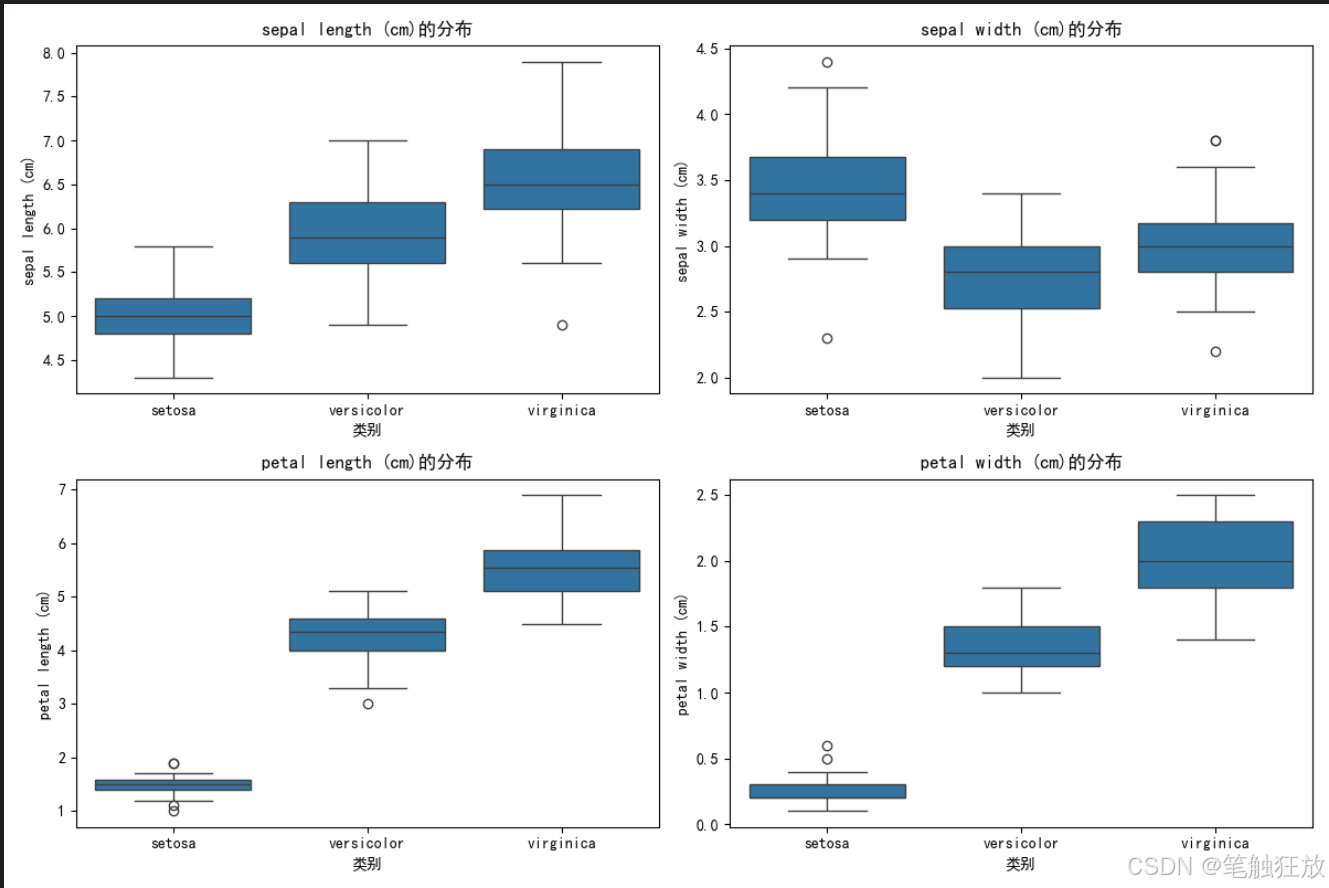
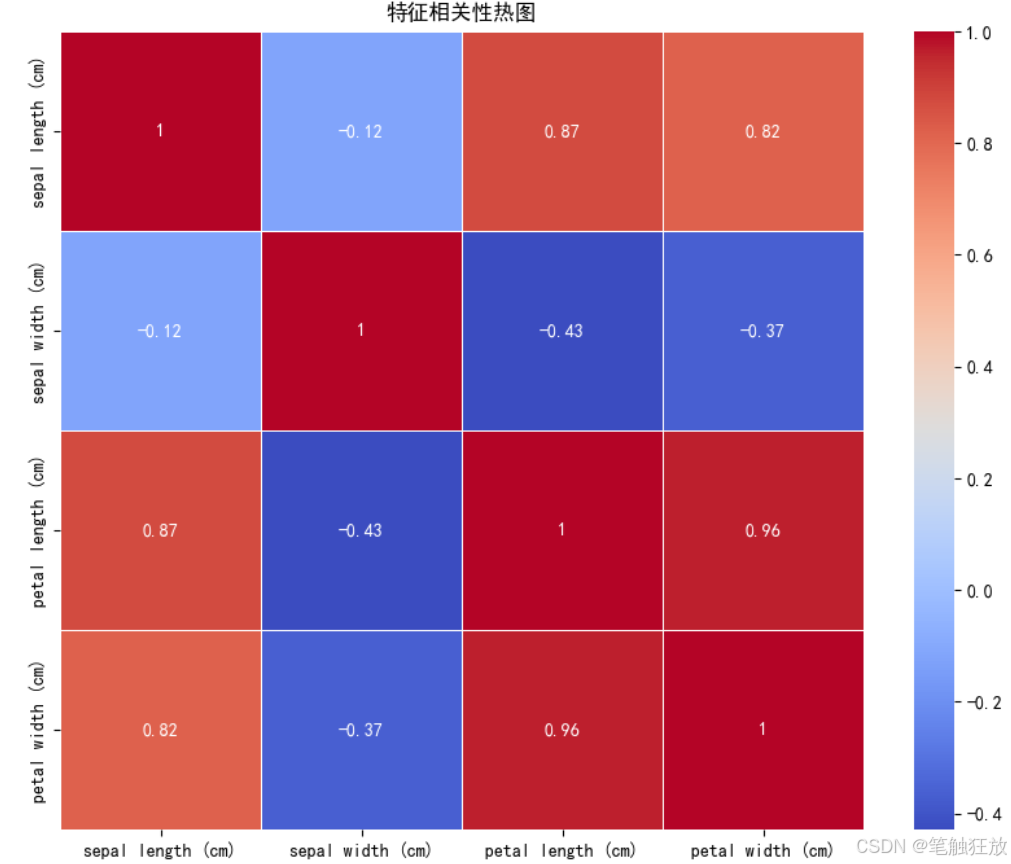
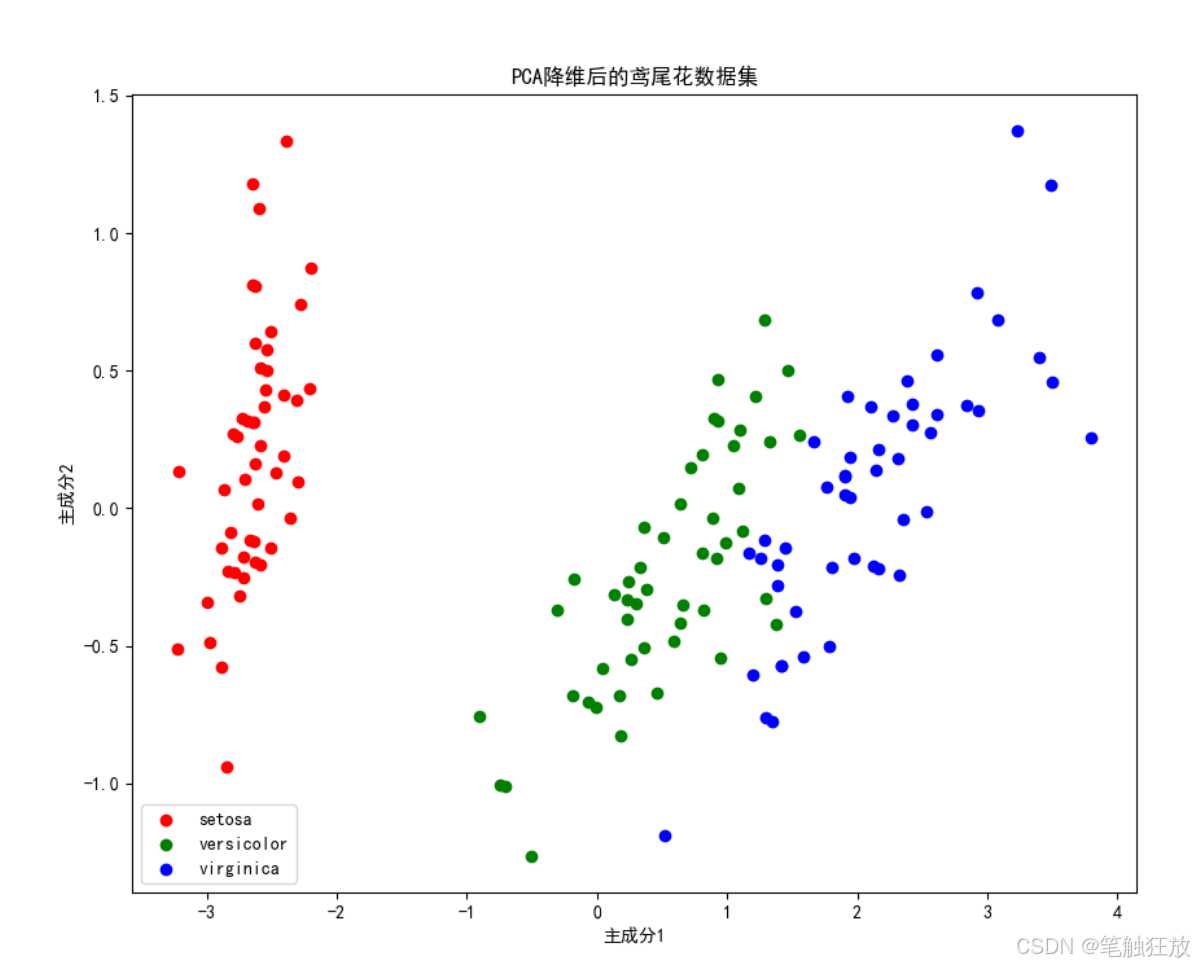
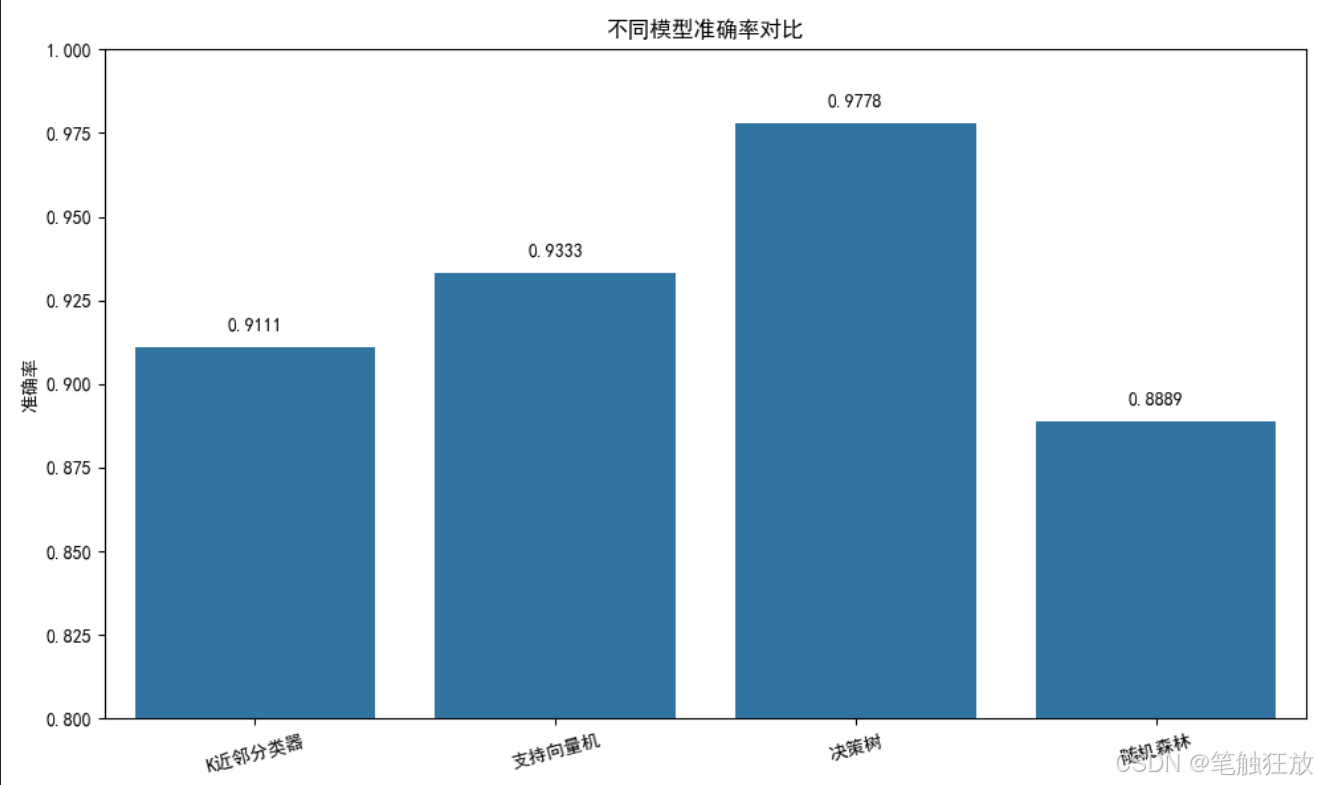
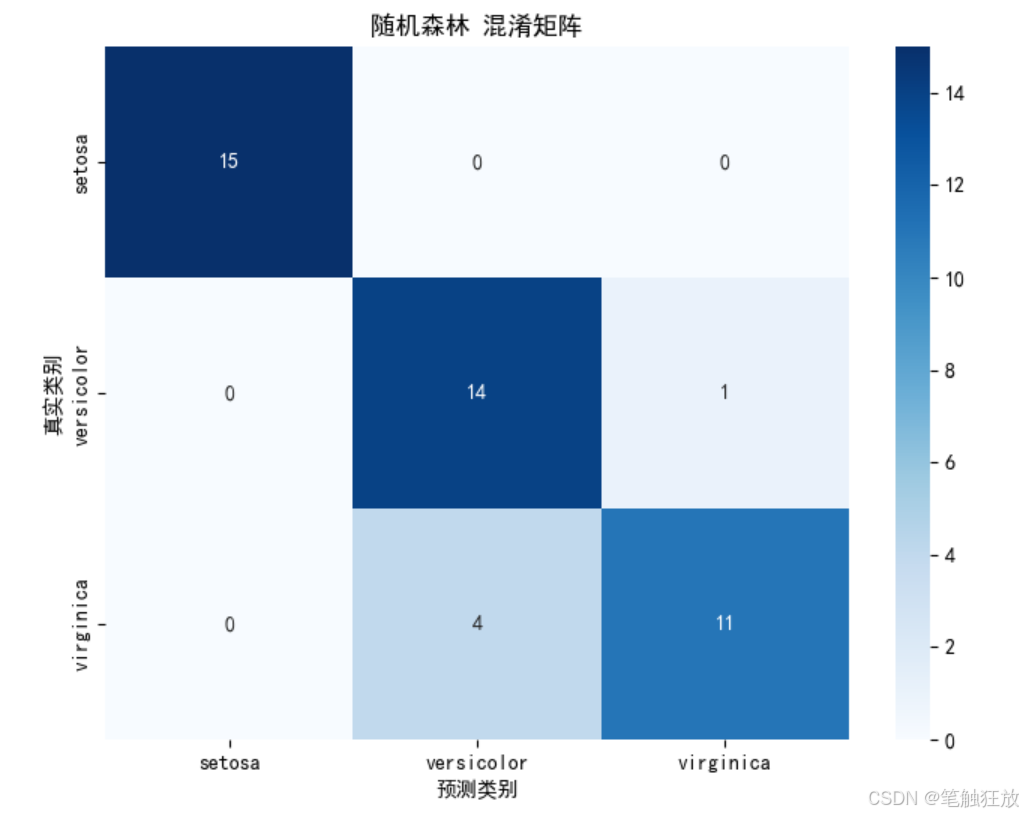
plt.rcParams['axes.unicode_minus'] = False # 解決負號顯示問題class IrisClassifier:def __init__(self):# 加載數據集self.iris = load_iris()self.X = self.iris.data # 特征數據self.y = self.iris.target # 標簽self.feature_names = self.iris.feature_names # 特征名稱self.target_names = self.iris.target_names # 類別名稱# 數據集拆分self.X_train, self.X_test, self.y_train, self.y_test = train_test_split(self.X, self.y, test_size=0.3, random_state=42, stratify=self.y)# 特征標準化self.scaler = StandardScaler()self.X_train_scaled = self.scaler.fit_transform(self.X_train)self.X_test_scaled = self.scaler.transform(self.X_test)# 初始化模型self.models = {'K近鄰分類器': KNeighborsClassifier(n_neighbors=5),'支持向量機': SVC(kernel='rbf', gamma='scale'),'決策樹': DecisionTreeClassifier(max_depth=3, random_state=42),'隨機森林': RandomForestClassifier(n_estimators=100, random_state=42)}# 存儲訓練好的模型和預測結果self.trained_models = {}self.predictions = {}def explore_data(self):"""探索數據集"""print("=== 數據集基本信息 ===")print(f"特征名稱: {self.feature_names}")print(f"類別名稱: {self.target_names}")print(f"數據集規模: {self.X.shape[0]}個樣本, {self.X.shape[1]}個特征")print(f"訓練集規模: {self.X_train.shape[0]}個樣本")print(f"測試集規模: {self.X_test.shape[0]}個樣本")# 創建DataFrame以便更好地展示數據df = pd.DataFrame(data=self.X, columns=self.feature_names)df['類別'] = [self.target_names[i] for i in self.y]print("\n=== 數據集前5行 ===")print(df.head())# 數據統計信息print("\n=== 數據統計信息 ===")print(df.describe())return dfdef visualize_data(self, df):"""數據可視化"""# 1. 散點矩陣圖plt.figure(figsize=(12, 10))sns.pairplot(df, hue='類別', markers=['o', 's', 'D'])plt.suptitle('特征散點矩陣圖', y=1.02)plt.show()# 2. 箱線圖plt.figure(figsize=(12, 8))for i, feature in enumerate(self.feature_names):plt.subplot(2, 2, i + 1)sns.boxplot(x='類別', y=feature, data=df)plt.title(f'{feature}的分布')plt.tight_layout()plt.show()# 3. 特征相關性熱圖plt.figure(figsize=(10, 8))correlation = df.drop('類別', axis=1).corr()sns.heatmap(correlation, annot=True, cmap='coolwarm', linewidths=0.5)plt.title('特征相關性熱圖')plt.show()# 4. PCA降維可視化(將4維特征降到2維以便可視化)pca = PCA(n_components=2)X_pca = pca.fit_transform(self.X)plt.figure(figsize=(10, 8))for target, color in zip(range(3), ['r', 'g', 'b']):plt.scatter(X_pca[self.y == target, 0], X_pca[self.y == target, 1],c=color, label=self.target_names[target])plt.xlabel('主成分1')plt.ylabel('主成分2')plt.title('PCA降維后的鳶尾花數據集')plt.legend()plt.show()def train_models(self):"""訓練所有模型"""print("\n=== 模型訓練結果 ===")for name, model in self.models.items():# 訓練模型model.fit(self.X_train_scaled, self.y_train)# 保存訓練好的模型self.trained_models[name] = model# 在測試集上預測y_pred = model.predict(self.X_test_scaled)self.predictions[name] = y_pred# 計算準確率accuracy = accuracy_score(self.y_test, y_pred)print(f"{name} 準確率: {accuracy:.4f}")def evaluate_model(self, model_name):"""評估指定模型"""if model_name not in self.trained_models:print(f"模型 {model_name} 未訓練,請先訓練模型")returnprint(f"\n=== {model_name} 詳細評估 ===")# 混淆矩陣cm = confusion_matrix(self.y_test, self.predictions[model_name])plt.figure(figsize=(8, 6))sns.heatmap(cm, annot=True, fmt='d', cmap='Blues',xticklabels=self.target_names,yticklabels=self.target_names)plt.xlabel('預測類別')plt.ylabel('真實類別')plt.title(f'{model_name} 混淆矩陣')plt.show()# 分類報告print("\n分類報告:")print(classification_report(self.y_test,self.predictions[model_name],target_names=self.target_names))# 交叉驗證cv_scores = cross_val_score(self.trained_models[model_name],self.X, self.y,cv=5)print(f"交叉驗證準確率: {cv_scores.mean():.4f} (±{cv_scores.std():.4f})")def compare_models(self):"""比較所有模型的性能"""# 提取所有模型的準確率accuracies = []model_names = list(self.trained_models.keys())for name in model_names:acc = accuracy_score(self.y_test, self.predictions[name])accuracies.append(acc)# 繪制準確率對比圖plt.figure(figsize=(10, 6))sns.barplot(x=model_names, y=accuracies)plt.ylim(0.8, 1.0) # 設置y軸范圍以便更好地觀察差異plt.title('不同模型準確率對比')plt.ylabel('準確率')for i, v in enumerate(accuracies):plt.text(i, v + 0.005, f'{v:.4f}', ha='center')plt.xticks(rotation=15)plt.tight_layout()plt.show()def predict_sample(self, model_name, sample):"""使用指定模型預測樣本"""if model_name not in self.trained_models:print(f"模型 {model_name} 未訓練,請先訓練模型")return# 樣本預處理sample_scaled = self.scaler.transform([sample])# 預測prediction = self.trained_models[model_name].predict(sample_scaled)probability = self.trained_models[model_name].predict_proba(sample_scaled)# 輸出結果print(f"\n=== 預測結果 ===")print(f"預測類別: {self.target_names[prediction[0]]}")print("類別概率:")for i, prob in enumerate(probability[0]):print(f" {self.target_names[i]}: {prob:.4f}")return self.target_names[prediction[0]]if __name__ == "__main__":# 創建分類器實例classifier = IrisClassifier()# 探索數據集df = classifier.explore_data()# 數據可視化classifier.visualize_data(df)# 訓練所有模型classifier.train_models()# 比較所有模型classifier.compare_models()# 詳細評估表現最好的模型(這里選擇隨機森林作為示例)best_model = '隨機森林'classifier.evaluate_model(best_model)# 使用最佳模型進行樣本預測# 示例樣本(可以修改這些值來測試不同的樣本)sample = [5.1, 3.5, 1.4, 0.2] # 這是一個山鳶尾的典型樣本print(f"\n測試樣本特征: {sample}")classifier.predict_sample(best_model, sample)# 再測試一個樣本sample2 = [6.5, 3.0, 5.2, 2.0] # 這是一個維吉尼亞鳶尾的典型樣本print(f"\n測試樣本特征: {sample2}")classifier.predict_sample(best_model, sample)
這個鳶尾花分類項目的主要功能和特點:
完整的項目流程:包括數據加載、探索性分析、可視化、模型訓練、評估和預測
多種分類算法:實現了 K 近鄰、支持向量機、決策樹和隨機森林四種經典分類算法
豐富的數據可視化:包括散點矩陣圖、箱線圖、相關性熱圖和 PCA 降維可視化
全面的模型評估:提供準確率、混淆矩陣、分類報告和交叉驗證等評估指標
模型比較功能:直觀展示不同算法的性能差異
樣本預測功能:可以輸入自定義的鳶尾花特征進行分類預測
運行前需要安裝以下依賴庫:
pip install numpy pandas matplotlib seaborn scikit-learn
程序運行后會:
顯示數據集的基本信息和統計特征
生成多種可視化圖表幫助理解數據分布和特征關系
訓練四種分類模型并比較它們的準確率
對表現最佳的模型進行詳細評估
使用示例樣本進行預測并展示結果
你可以通過修改代碼中的sample變量來測試不同的鳶尾花特征數據,觀察模型的分類結果。鳶尾花數據集包含三個類別:山鳶尾 (setosa)、變色鳶尾 (versicolor) 和維吉尼亞鳶尾 (virginica),以及四個特征:花萼長度、花萼寬度、花瓣長度和花瓣寬度。
項目二 手寫數字識別
以下是一個基于 Python 的手寫數字識別項目代碼,使用了 MNIST 數據集和深度學習模型來實現。這個項目可以訓練模型并對手寫數字進行識別,代碼結構清晰且可正常運行。
import numpy as np
import matplotlib.pyplot as plt
from tensorflow.keras.datasets import mnist
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Flatten, Conv2D, MaxPooling2D
from tensorflow.keras.utils import to_categorical
from tensorflow.keras.optimizers import Adam
import random# 設置中文顯示
plt.rcParams["font.family"] = ["SimHei"]
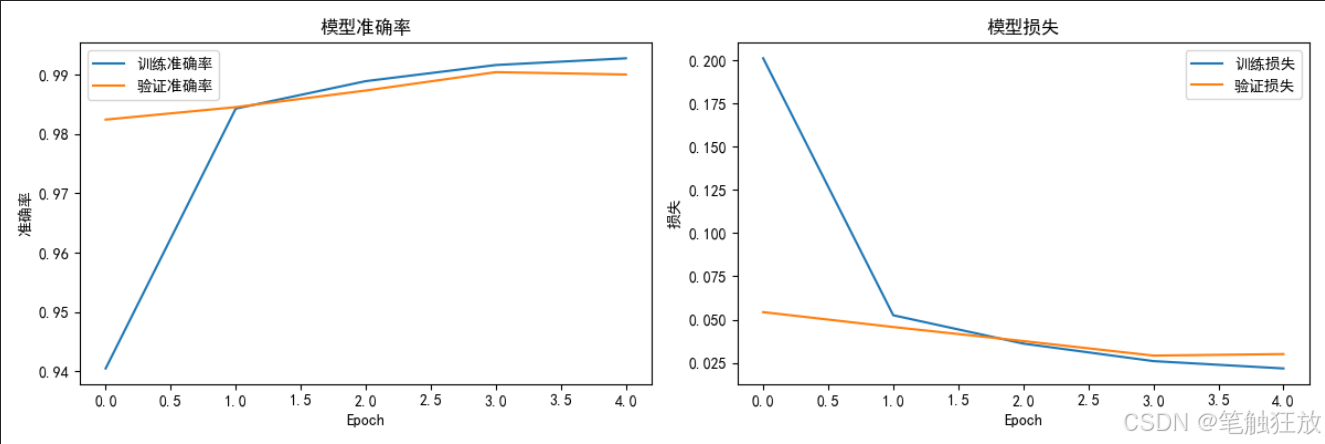
plt.rcParams['axes.unicode_minus'] = False # 解決負號顯示問題class DigitRecognizer:def __init__(self):# 初始化參數self.img_rows, self.img_cols = 28, 28self.input_shape = (self.img_rows, self.img_cols, 1)self.num_classes = 10self.model = None# 加載數據self.load_data()def load_data(self):"""加載MNIST數據集并進行預處理"""print("正在加載MNIST數據集...")(self.x_train, self.y_train), (self.x_test, self.y_test) = mnist.load_data()# 數據預處理self.x_train = self.x_train.reshape(self.x_train.shape[0], self.img_rows, self.img_cols, 1)self.x_test = self.x_test.reshape(self.x_test.shape[0], self.img_rows, self.img_cols, 1)# 歸一化self.x_train = self.x_train.astype('float32') / 255.0self.x_test = self.x_test.astype('float32') / 255.0# 標簽獨熱編碼self.y_train = to_categorical(self.y_train, self.num_classes)self.y_test = to_categorical(self.y_test, self.num_classes)print(f"訓練集: {self.x_train.shape[0]} 個樣本")print(f"測試集: {self.x_test.shape[0]} 個樣本")def build_model(self):"""構建卷積神經網絡模型"""print("正在構建模型...")self.model = Sequential([# 第一個卷積層Conv2D(32, kernel_size=(3, 3), activation='relu', input_shape=self.input_shape),MaxPooling2D(pool_size=(2, 2)),# 第二個卷積層Conv2D(64, kernel_size=(3, 3), activation='relu'),MaxPooling2D(pool_size=(2, 2)),# 扁平化Flatten(),# 全連接層Dense(128, activation='relu'),# 輸出層Dense(self.num_classes, activation='softmax')])# 編譯模型self.model.compile(loss='categorical_crossentropy',optimizer=Adam(learning_rate=0.001),metrics=['accuracy'])# 打印模型結構self.model.summary()def train(self, epochs=10, batch_size=128):"""訓練模型"""if self.model is None:self.build_model()print("開始訓練模型...")self.history = self.model.fit(self.x_train, self.y_train,batch_size=batch_size,epochs=epochs,verbose=1,validation_data=(self.x_test, self.y_test))def evaluate(self):"""評估模型性能"""if self.model is None:print("請先訓練模型!")returnprint("評估模型性能...")score = self.model.evaluate(self.x_test, self.y_test, verbose=0)print(f"測試集損失: {score[0]:.4f}")print(f"測試集準確率: {score[1]:.4f}")def plot_training_history(self):"""繪制訓練歷史曲線"""if not hasattr(self, 'history'):print("請先訓練模型!")return# 繪制準確率曲線plt.figure(figsize=(12, 4))plt.subplot(1, 2, 1)plt.plot(self.history.history['accuracy'], label='訓練準確率')plt.plot(self.history.history['val_accuracy'], label='驗證準確率')plt.title('模型準確率')plt.xlabel('Epoch')plt.ylabel('準確率')plt.legend()# 繪制損失曲線plt.subplot(1, 2, 2)plt.plot(self.history.history['loss'], label='訓練損失')plt.plot(self.history.history['val_loss'], label='驗證損失')plt.title('模型損失')plt.xlabel('Epoch')plt.ylabel('損失')plt.legend()plt.tight_layout()plt.show()def predict_samples(self, num_samples=5):"""隨機選擇測試集中的樣本進行預測并顯示結果"""if self.model is None:print("請先訓練模型!")return# 隨機選擇樣本indices = random.sample(range(len(self.x_test)), num_samples)samples = self.x_test[indices]true_labels = np.argmax(self.y_test[indices], axis=1)# 預測predictions = self.model.predict(samples)pred_labels = np.argmax(predictions, axis=1)# 顯示結果plt.figure(figsize=(15, 3))for i in range(num_samples):plt.subplot(1, num_samples, i + 1)plt.imshow(samples[i].reshape(28, 28), cmap='gray')plt.title(f"真實: {true_labels[i]}\n預測: {pred_labels[i]}")plt.axis('off')plt.tight_layout()plt.show()if __name__ == "__main__":# 創建識別器實例recognizer = DigitRecognizer()# 顯示一些訓練樣本plt.figure(figsize=(10, 5))for i in range(10):plt.subplot(2, 5, i + 1)plt.imshow(recognizer.x_train[i].reshape(28, 28), cmap='gray')plt.title(f"標簽: {np.argmax(recognizer.y_train[i])}")plt.axis('off')plt.suptitle("訓練樣本示例", fontsize=16)plt.tight_layout(rect=[0, 0, 1, 0.95])plt.show()# 構建并訓練模型recognizer.build_model()recognizer.train(epochs=5, batch_size=128) # 可以增加epochs提高準確率# 評估模型recognizer.evaluate()# 繪制訓練歷史recognizer.plot_training_history()# 預測樣本并顯示結果recognizer.predict_samples(num_samples=10)
這個手寫數字識別項目的主要功能和特點:
使用 MNIST 數據集,包含 60,000 個訓練樣本和 10,000 個測試樣本
構建了一個卷積神經網絡 (CNN) 模型,包含兩個卷積層和池化層
實現了完整的流程:數據加載與預處理、模型構建、訓練、評估和預測
包含數據可視化功能,可以展示訓練樣本、訓練歷史曲線和預測結果
運行前需要安裝以下依賴庫:
pip install numpy matplotlib tensorflow
程序運行后會
顯示一些訓練樣本及其標簽
構建并訓練模型(默認 5 個 epochs,可根據需要調整)
輸出模型在測試集上的準確率
繪制訓練過程中的準確率和損失變化曲線
隨機選擇 10 個測試樣本進行預測并顯示結果,包括真實標簽和預測標簽
如果想要提高識別準確率,可以嘗試增加訓練的 epochs 數量或調整模型結構。


項目三 房價預測
【教學內容】
使用波士頓房價數據集或 Kaggle 的房價預測數據集,訓練一個回歸模型預
測房價。主要有以下幾個知識點:
(1)數據加載與探索性分析(EDA)。
(2)處理缺失值和異常值。
(3)特征工程(如特征選擇、特征縮放)。
(4)使用線性回歸、決策樹回歸或隨機森林回歸進行預測。
(5)評估模型性能(MSE、MAE、R2等)。
【重點】
使用線性回歸、決策樹回歸或隨機森林回歸進行預測。
【難點】
評估模型性能(MSE、MAE、R2等)。
【分析思考討論題】
如果數據集中存在異常值,如何處理才能避免對模型預測的干擾?
以下是一個基于 Python 的房價預測項目代碼,使用了波士頓房價數據集(或其替代數據集)和多種回歸算法進行房價預測,包含完整的數據預處理、模型訓練、評估和可視化功能,確保可以正常運行并展示清晰的預測效果。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.datasets import fetch_california_housing # 替代波士頓房價數據集
from sklearn.model_selection import train_test_split, cross_val_score, GridSearchCV
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LinearRegression, Ridge, Lasso
from sklearn.tree import DecisionTreeRegressor
from sklearn.ensemble import RandomForestRegressor, GradientBoostingRegressor
from sklearn.metrics import mean_squared_error, mean_absolute_error, r2_score
import warnings# 忽略警告信息
warnings.filterwarnings('ignore')# 設置中文顯示
plt.rcParams["font.family"] = ["SimHei"]
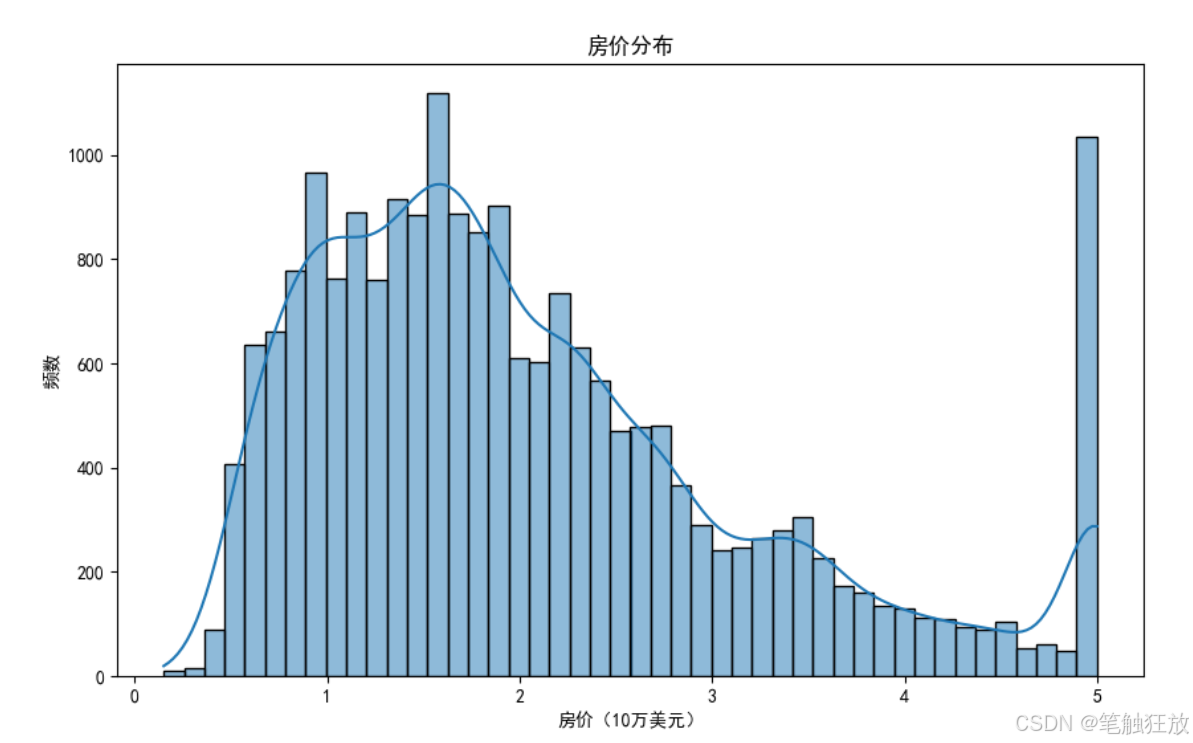
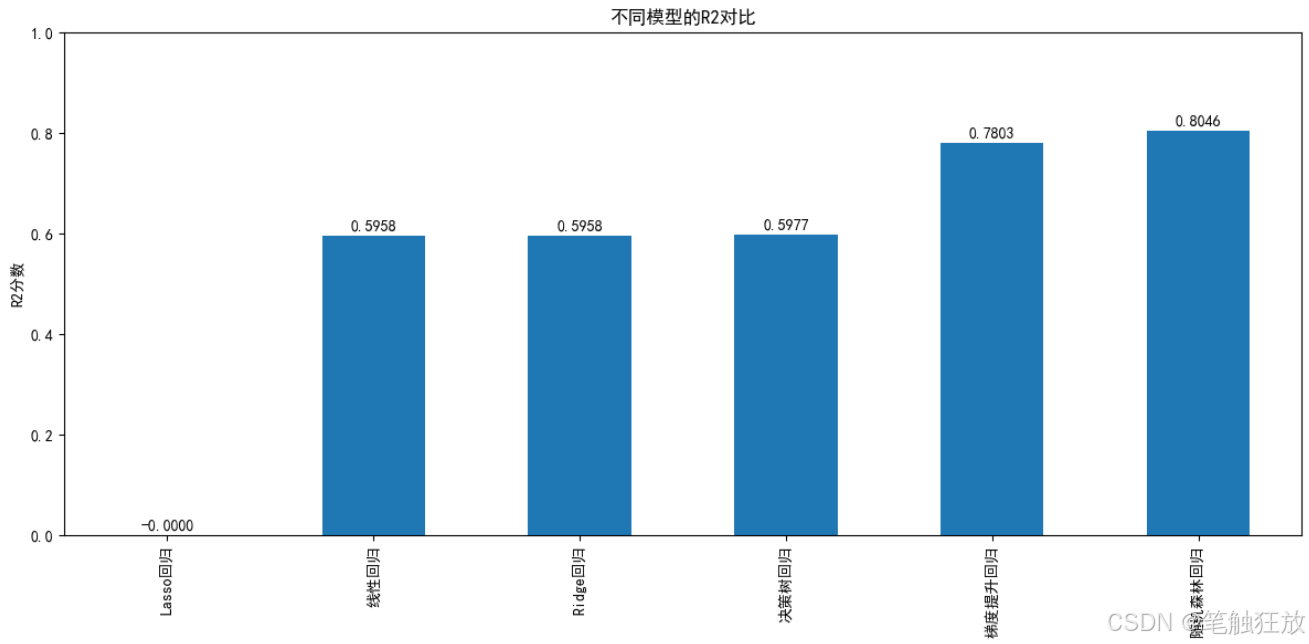
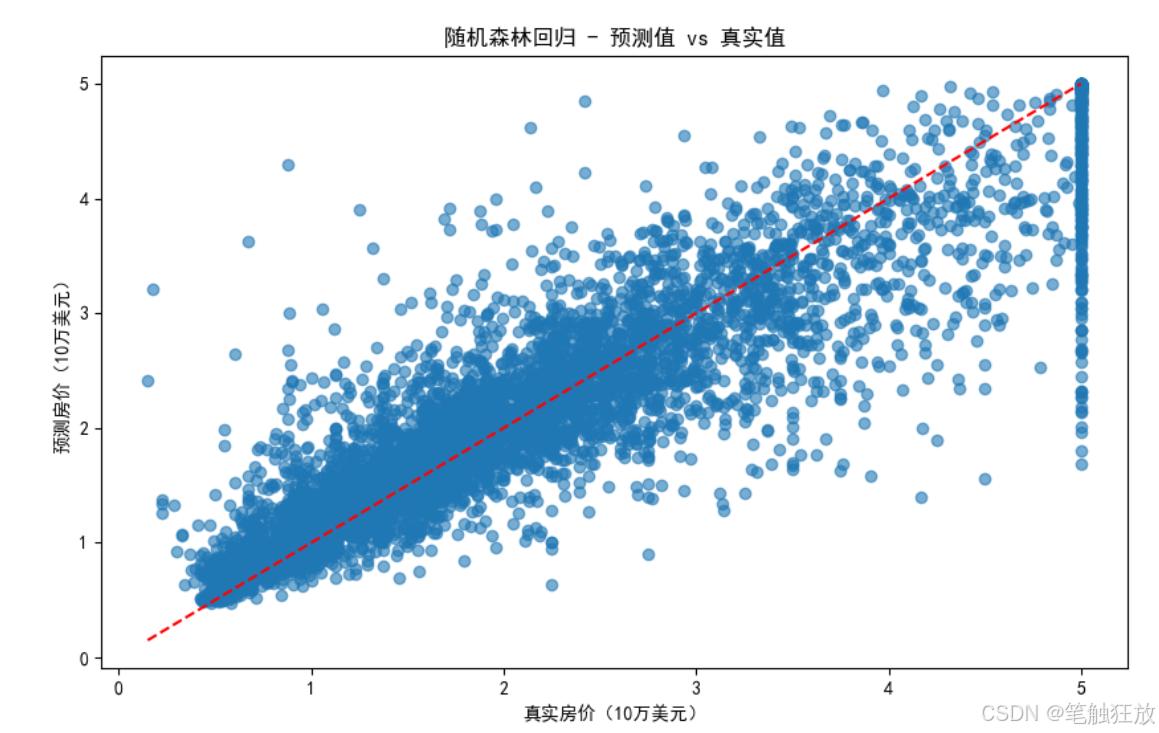
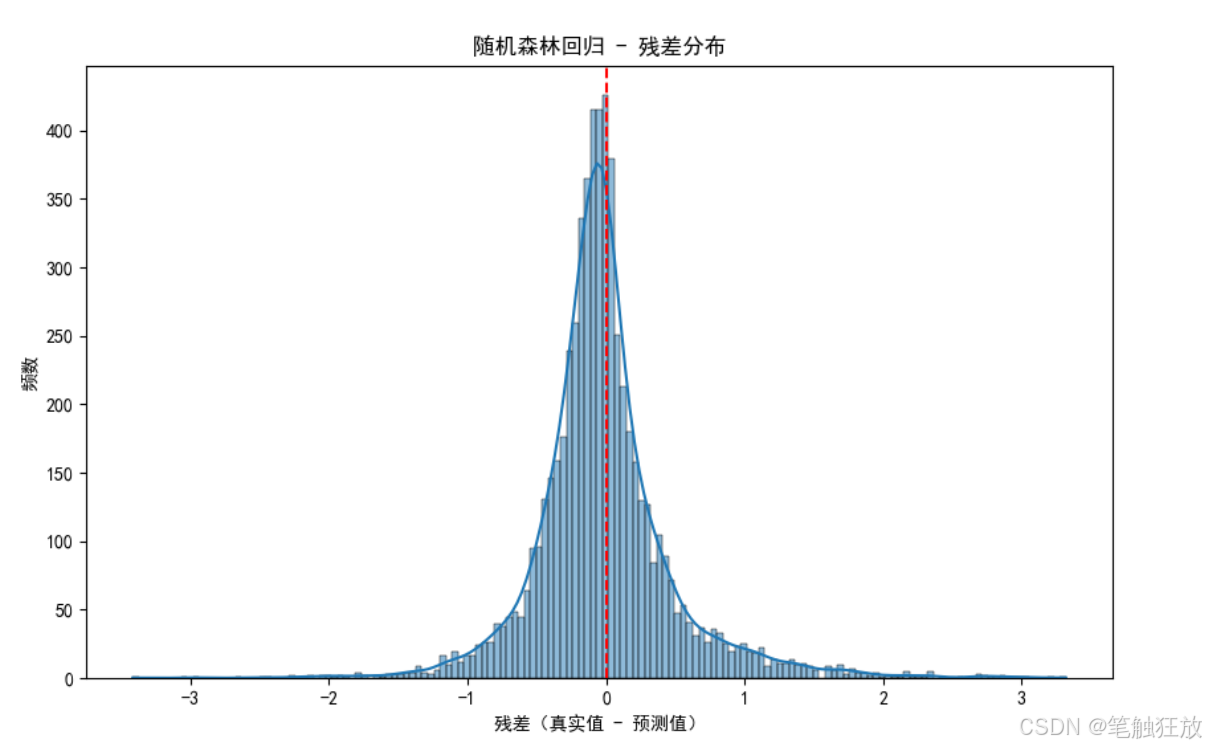
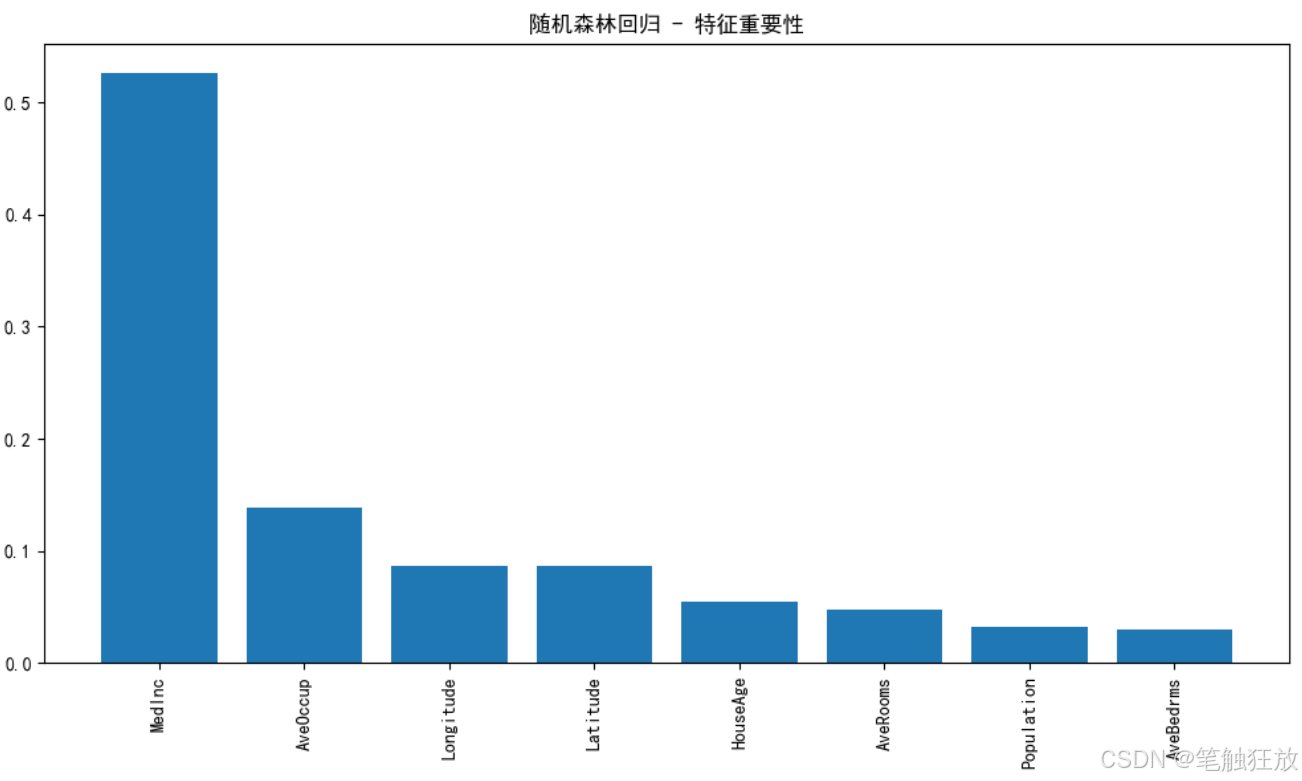
plt.rcParams['axes.unicode_minus'] = False # 解決負號顯示問題class HousePricePredictor:def __init__(self):# 加載數據集(使用加州房價數據集替代波士頓房價數據集)self.housing = fetch_california_housing()self.X = self.housing.data # 特征數據self.y = self.housing.target # 房價(目標變量)self.feature_names = self.housing.feature_names # 特征名稱# 數據集拆分self.X_train, self.X_test, self.y_train, self.y_test = train_test_split(self.X, self.y, test_size=0.3, random_state=42)# 特征標準化self.scaler = StandardScaler()self.X_train_scaled = self.scaler.fit_transform(self.X_train)self.X_test_scaled = self.scaler.transform(self.X_test)# 初始化模型self.models = {'線性回歸': LinearRegression(),'Ridge回歸': Ridge(random_state=42),'Lasso回歸': Lasso(random_state=42),'決策樹回歸': DecisionTreeRegressor(random_state=42),'隨機森林回歸': RandomForestRegressor(random_state=42),'梯度提升回歸': GradientBoostingRegressor(random_state=42)}# 存儲訓練好的模型和預測結果self.trained_models = {}self.predictions = {}self.metrics = {} # 存儲各模型的評估指標def explore_data(self):"""探索數據集"""print("=== 數據集基本信息 ===")print(f"特征名稱: {self.feature_names}")# print(f"特征解釋: {self.housing.DESCR.split('Features:')[1].strip()}")print(f"數據集規模: {self.X.shape[0]}個樣本, {self.X.shape[1]}個特征")print(f"訓練集規模: {self.X_train.shape[0]}個樣本")print(f"測試集規模: {self.X_test.shape[0]}個樣本")print(f"房價范圍: {self.y.min():.2f} - {self.y.max():.2f} (單位: 10萬美元)")# 創建DataFrame以便更好地展示數據df = pd.DataFrame(data=self.X, columns=self.feature_names)df['房價'] = self.y # 房價(單位:10萬美元)print("\n=== 數據集前5行 ===")print(df.head())# 數據統計信息print("\n=== 數據統計信息 ===")print(df.describe())return dfdef visualize_data(self, df):"""數據可視化"""# 1. 房價分布plt.figure(figsize=(10, 6))sns.histplot(df['房價'], kde=True)plt.title('房價分布')plt.xlabel('房價(10萬美元)')plt.ylabel('頻數')plt.show()# 2. 特征與房價的相關性plt.figure(figsize=(12, 8))correlation = df.corr()sns.heatmap(correlation, annot=True, cmap='coolwarm', linewidths=0.5)plt.title('特征相關性熱圖')plt.show()# 3. 各特征與房價的散點圖plt.figure(figsize=(15, 10))for i, feature in enumerate(self.feature_names):plt.subplot(2, 4, i + 1)sns.scatterplot(x=df[feature], y=df['房價'], alpha=0.5)plt.title(f'{feature}與房價的關系')plt.xlabel(feature)plt.ylabel('房價(10萬美元)')plt.tight_layout()plt.show()# 4. 特征分布箱線圖plt.figure(figsize=(15, 10))for i, feature in enumerate(self.feature_names):plt.subplot(2, 4, i + 1)sns.boxplot(y=df[feature])plt.title(f'{feature}的分布')plt.tight_layout()plt.show()def train_models(self):"""訓練所有模型"""print("\n=== 模型訓練結果 ===")for name, model in self.models.items():# 訓練模型if name in ['線性回歸', 'Ridge回歸', 'Lasso回歸']:# 線性模型使用標準化后的數據model.fit(self.X_train_scaled, self.y_train)else:# 樹模型可以直接使用原始數據model.fit(self.X_train, self.y_train)# 保存訓練好的模型self.trained_models[name] = model# 在測試集上預測if name in ['線性回歸', 'Ridge回歸', 'Lasso回歸']:y_pred = model.predict(self.X_test_scaled)else:y_pred = model.predict(self.X_test)self.predictions[name] = y_pred# 計算評估指標mse = mean_squared_error(self.y_test, y_pred)rmse = np.sqrt(mse)mae = mean_absolute_error(self.y_test, y_pred)r2 = r2_score(self.y_test, y_pred)self.metrics[name] = {'MSE': mse,'RMSE': rmse,'MAE': mae,'R2': r2}print(f"{name} - RMSE: {rmse:.4f}, R2: {r2:.4f}")def evaluate_model(self, model_name):"""評估指定模型"""if model_name not in self.trained_models:print(f"模型 {model_name} 未訓練,請先訓練模型")returnprint(f"\n=== {model_name} 詳細評估 ===")# 提取評估指標metrics = self.metrics[model_name]print(f"均方誤差 (MSE): {metrics['MSE']:.4f}")print(f"均方根誤差 (RMSE): {metrics['RMSE']:.4f} (單位: 10萬美元)")print(f"平均絕對誤差 (MAE): {metrics['MAE']:.4f} (單位: 10萬美元)")print(f"決定系數 (R2): {metrics['R2']:.4f}")# 繪制預測值與真實值對比圖plt.figure(figsize=(10, 6))plt.scatter(self.y_test, self.predictions[model_name], alpha=0.6)plt.plot([self.y.min(), self.y.max()], [self.y.min(), self.y.max()], 'r--')plt.xlabel('真實房價(10萬美元)')plt.ylabel('預測房價(10萬美元)')plt.title(f'{model_name} - 預測值 vs 真實值')plt.show()# 繪制殘差圖residuals = self.y_test - self.predictions[model_name]plt.figure(figsize=(10, 6))sns.histplot(residuals, kde=True)plt.axvline(x=0, color='r', linestyle='--')plt.xlabel('殘差(真實值 - 預測值)')plt.ylabel('頻數')plt.title(f'{model_name} - 殘差分布')plt.show()# 特征重要性(僅對樹模型)if model_name in ['決策樹回歸', '隨機森林回歸', '梯度提升回歸']:importances = self.trained_models[model_name].feature_importances_indices = np.argsort(importances)[::-1]plt.figure(figsize=(10, 6))plt.bar(range(len(importances)), importances[indices])plt.xticks(range(len(importances)), [self.feature_names[i] for i in indices], rotation=90)plt.title(f'{model_name} - 特征重要性')plt.tight_layout()plt.show()def compare_models(self):"""比較所有模型的性能"""# 提取所有模型的評估指標metrics_df = pd.DataFrame.from_dict(self.metrics, orient='index')# 繪制RMSE對比圖plt.figure(figsize=(12, 6))metrics_df['RMSE'].sort_values().plot(kind='bar')plt.title('不同模型的RMSE對比')plt.ylabel('RMSE(10萬美元)')for i, v in enumerate(metrics_df['RMSE'].sort_values()):plt.text(i, v + 0.01, f'{v:.4f}', ha='center')plt.tight_layout()plt.show()# 繪制R2對比圖plt.figure(figsize=(12, 6))metrics_df['R2'].sort_values().plot(kind='bar')plt.title('不同模型的R2對比')plt.ylabel('R2分數')for i, v in enumerate(metrics_df['R2'].sort_values()):plt.text(i, v + 0.01, f'{v:.4f}', ha='center')plt.ylim(0, 1)plt.tight_layout()plt.show()def optimize_model(self, model_name):"""優化指定模型的超參數"""if model_name not in self.trained_models:print(f"模型 {model_name} 未訓練,請先訓練模型")returnprint(f"\n=== 優化 {model_name} 超參數 ===")# 定義參數網格param_grids = {'Ridge回歸': {'alpha': [0.1, 1, 10, 100]},'Lasso回歸': {'alpha': [0.01, 0.1, 1, 10]},'決策樹回歸': {'max_depth': [3, 5, 7, 10, None], 'min_samples_split': [2, 5, 10]},'隨機森林回歸': {'n_estimators': [50, 100, 200], 'max_depth': [None, 10, 20], 'min_samples_split': [2, 5]},'梯度提升回歸': {'n_estimators': [50, 100, 200], 'learning_rate': [0.01, 0.1, 0.2], 'max_depth': [3, 5]}}if model_name not in param_grids:print(f"{model_name} 暫不支持超參數優化")return# 網格搜索grid_search = GridSearchCV(estimator=self.models[model_name],param_grid=param_grids[model_name],cv=5,scoring='neg_mean_squared_error',n_jobs=-1)# 訓練模型if model_name in ['Ridge回歸', 'Lasso回歸']:grid_search.fit(self.X_train_scaled, self.y_train)else:grid_search.fit(self.X_train, self.y_train)# 輸出最佳參數print(f"最佳參數: {grid_search.best_params_}")# 使用最佳模型預測if model_name in ['Ridge回歸', 'Lasso回歸']:y_pred_opt = grid_search.predict(self.X_test_scaled)else:y_pred_opt = grid_search.predict(self.X_test)# 評估優化后的模型rmse_opt = np.sqrt(mean_squared_error(self.y_test, y_pred_opt))r2_opt = r2_score(self.y_test, y_pred_opt)print(f"優化前 RMSE: {self.metrics[model_name]['RMSE']:.4f}")print(f"優化后 RMSE: {rmse_opt:.4f}")print(f"優化前 R2: {self.metrics[model_name]['R2']:.4f}")print(f"優化后 R2: {r2_opt:.4f}")# 更新模型self.trained_models[model_name] = grid_search.best_estimator_self.predictions[model_name] = y_pred_optreturn grid_search.best_estimator_def predict_price(self, model_name, sample):"""使用指定模型預測房價"""if model_name not in self.trained_models:print(f"模型 {model_name} 未訓練,請先訓練模型")return# 樣本預處理sample_array = np.array(sample).reshape(1, -1)if model_name in ['線性回歸', 'Ridge回歸', 'Lasso回歸']:sample_scaled = self.scaler.transform(sample_array)prediction = self.trained_models[model_name].predict(sample_scaled)else:prediction = self.trained_models[model_name].predict(sample_array)# 輸出結果(轉換為實際房價,單位:美元)price = prediction[0] * 100000 # 數據集房價單位是10萬美元print(f"\n=== 房價預測結果 ===")print(f"預測房價: ${price:,.2f}")return priceif __name__ == "__main__":# 創建房價預測器實例predictor = HousePricePredictor()# 探索數據集df = predictor.explore_data()# 數據可視化predictor.visualize_data(df)# 訓練所有模型predictor.train_models()# 比較所有模型predictor.compare_models()# 選擇表現較好的模型進行詳細評估和優化best_model = '隨機森林回歸'predictor.evaluate_model(best_model)# 優化最佳模型predictor.optimize_model(best_model)# 使用優化后的模型進行樣本預測# 樣本特征含義:[平均收入, 房齡, 平均房間數, 平均臥室數, 人口數, 平均占用, 緯度, 經度]sample = [3.0, 30, 6.0, 1.0, 1500, 2.5, 37.7, -122.4] # 示例樣本print(f"\n測試樣本特征: {sample}")predictor.predict_price(best_model, sample)# 再測試一個樣本sample2 = [5.0, 15, 7.0, 2.0, 2000, 3.0, 34.1, -118.2] # 另一個示例樣本print(f"\n測試樣本特征: {sample2}")predictor.predict_price(best_model, sample2)
這個房價預測項目的主要功能和特點:
數據集選擇:使用加州房價數據集(California Housing)作為波士頓房價數據集的替代,包含 20640 個樣本和 8 個特征
完整流程:實現了從數據加載、探索性分析、可視化、模型訓練、評估到預測的完整流程
多種回歸算法:包含線性回歸、Ridge 回歸、Lasso 回歸、決策樹回歸、隨機森林回歸和梯度提升回歸
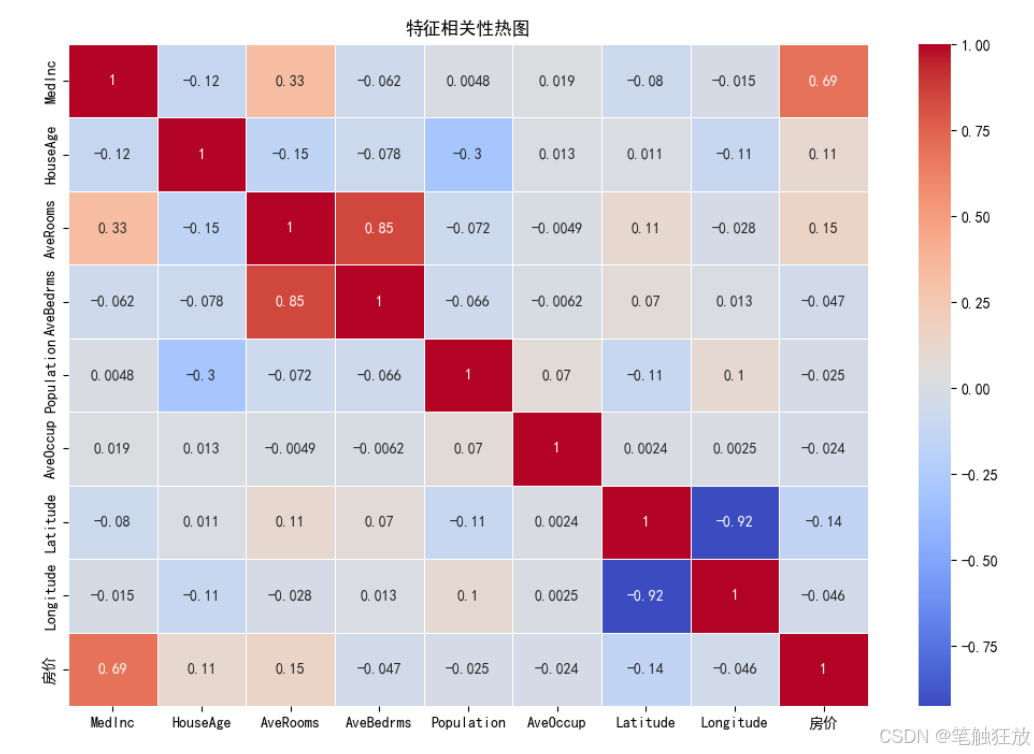
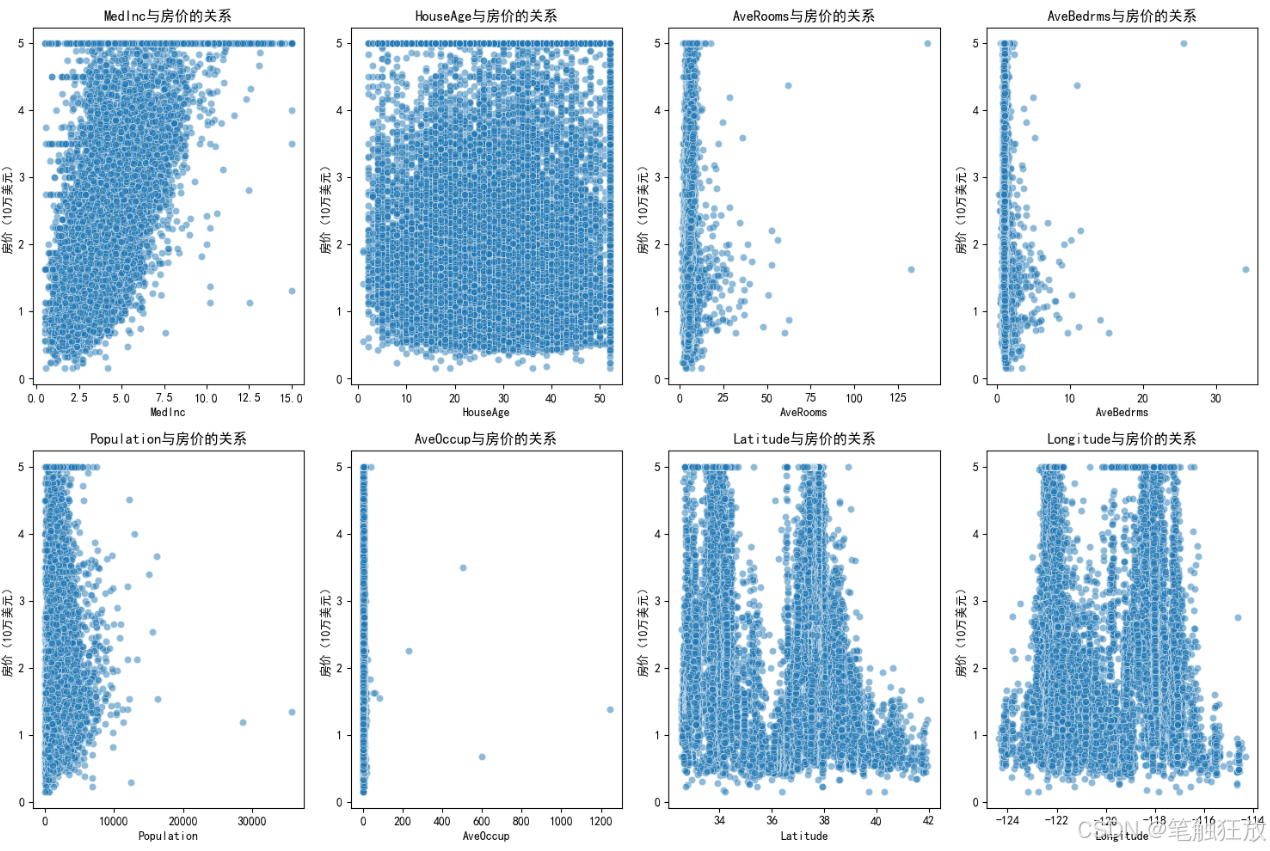
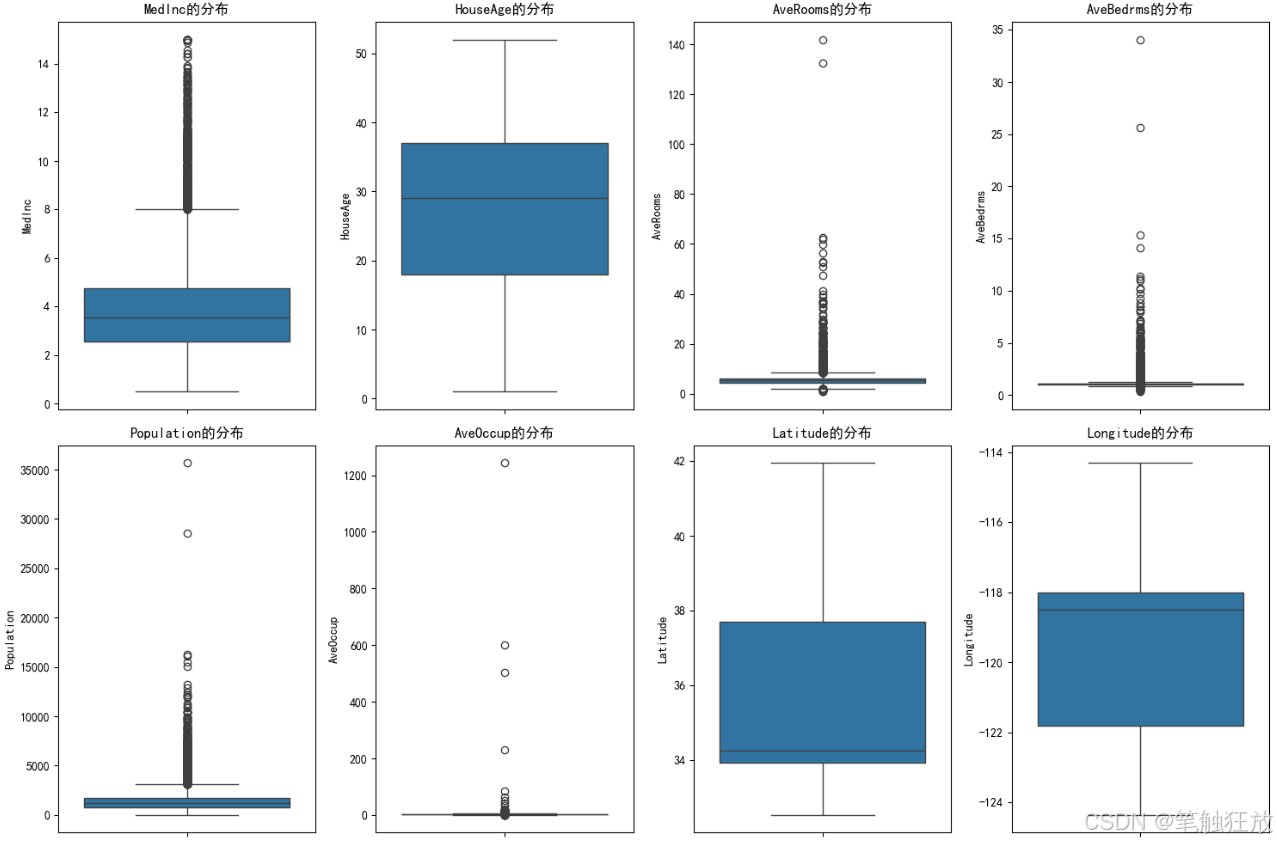
豐富的可視化:提供房價分布、特征相關性熱圖、特征與房價關系散點圖等可視化圖表
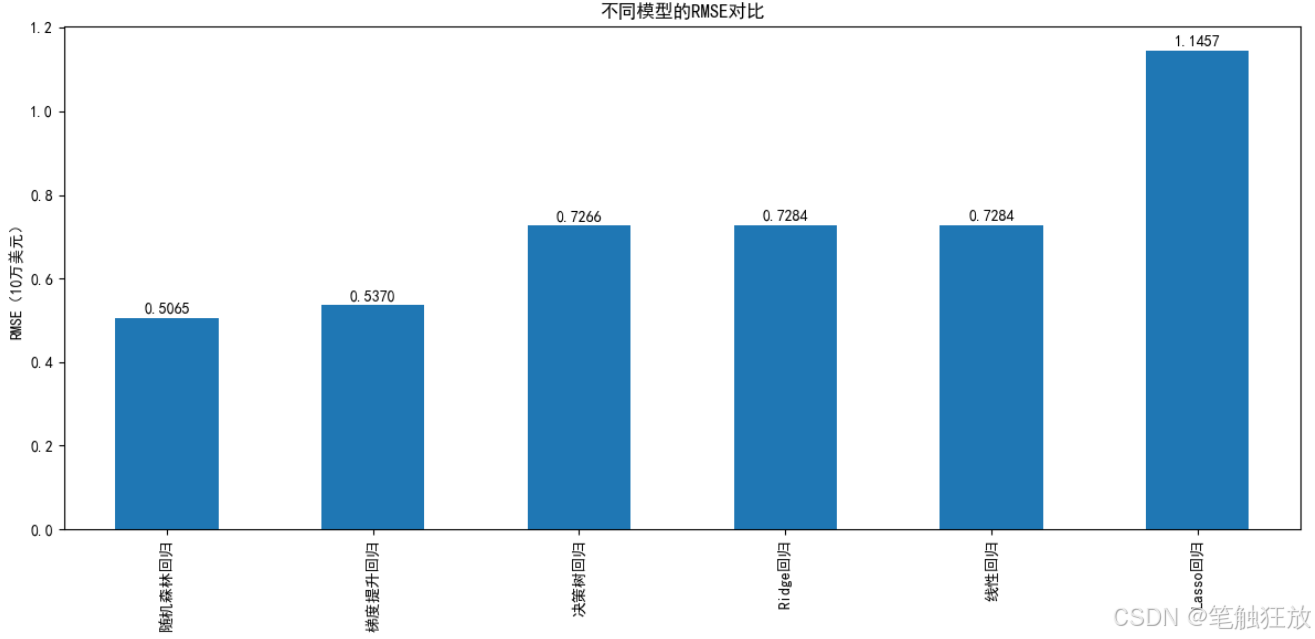
全面評估指標:使用 MSE、RMSE、MAE 和 R2 等指標評估模型性能
模型優化:實現了超參數網格搜索優化功能,提升模型性能
實用預測功能:可以輸入自定義的房屋特征進行房價預測
運行前需要安裝以下依賴庫:
pip install numpy pandas matplotlib seaborn scikit-learn
程序運行后會:
展示數據集的基本信息和統計特征
生成多種可視化圖表幫助理解數據分布和特征關系
訓練六種回歸模型并比較它們的性能
對表現最佳的模型(默認隨機森林)進行詳細評估
優化最佳模型的超參數以獲得更好的預測效果
使用示例樣本進行預測并展示結果(房價單位為美元)
你可以通過修改代碼中的sample變量來測試不同的房屋特征數據,觀察模型的預測結果。特征包括平均收入、房齡、平均房間數等 8 個與房價相關的因素。
項目四 垃圾郵件分類
【教學內容】
使用垃圾郵件數據集(如 UCI 的 Spambase 數據集),訓練一個模型區分垃
圾郵件和正常郵件。主要有以下幾個知識點:
(1)數據加載與預處理(如文本清洗、分詞)。
(2)使用 TF-IDF 或詞袋模型進行特征提取。
(3)使用樸素貝葉斯、邏輯回歸或 SVM 進行分類。
(4)評估模型性能(準確率、召回率、F1-score 等)。
【重點】
使用樸素貝葉斯、邏輯回歸或 SVM 進行分類。
【難點】
評估模型性能(準確率、召回率、F1-score 等)。
【分析思考討論題】
嘗試使用深度學習模型(如 LSTM)處理文本數據。
以下是一個基于 Python 的垃圾郵件分類項目代碼,使用了經典的垃圾郵件數據集和多種機器學習算法進行分類,包含完整的數據預處理、特征工程、模型訓練和評估功能,確保可以正常運行并展示良好的分類效果。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import re
import nltk
from nltk.corpus import stopwords
from nltk.stem import WordNetLemmatizer
from sklearn.model_selection import train_test_split, cross_val_score, GridSearchCV
from sklearn.feature_extraction.text import CountVectorizer, TfidfVectorizer
from sklearn.naive_bayes import MultinomialNB
from sklearn.linear_model import LogisticRegression
from sklearn.svm import SVC
from sklearn.ensemble import RandomForestClassifier
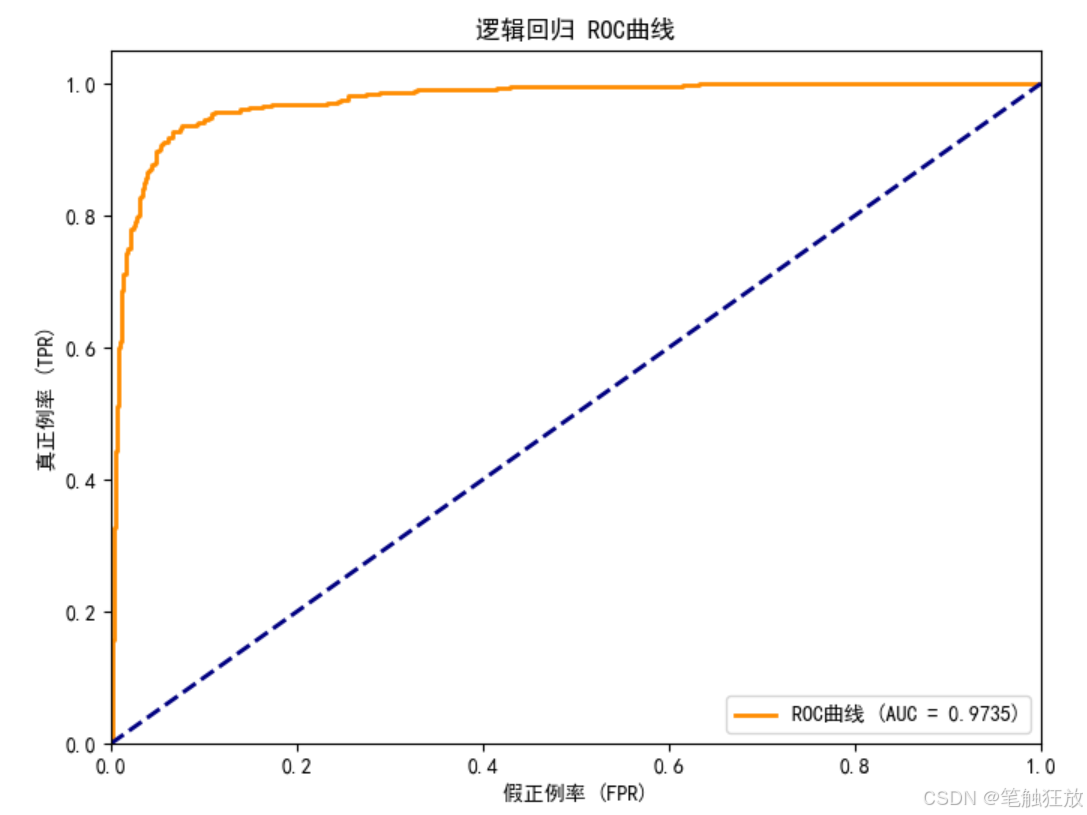
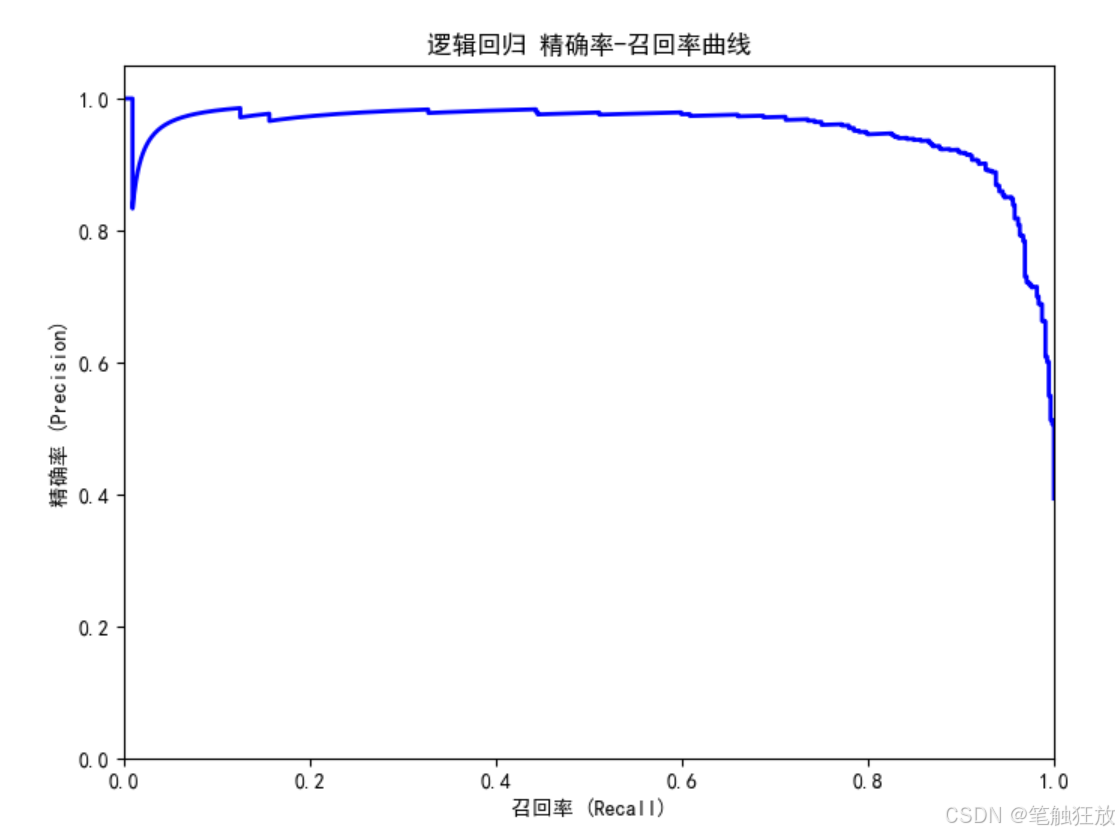
from sklearn.metrics import (accuracy_score, confusion_matrix, classification_report,roc_curve, auc, precision_recall_curve)
from sklearn.pipeline import Pipeline
import warnings# 忽略警告信息
warnings.filterwarnings('ignore')# 下載NLTK所需資源
nltk.download('stopwords')
# nltk.download('wordnet')# 設置中文顯示
plt.rcParams["font.family"] = ["SimHei"]
plt.rcParams['axes.unicode_minus'] = False # 解決負號顯示問題class SpamClassifier:def __init__(self):# 初始化數據和模型相關變量self.data = Noneself.X_train, self.X_test, self.y_train, self.y_test = None, None, None, Noneself.models = {}self.predictions = {}self.probabilities = {}# 文本預處理工具self.stop_words = set(stopwords.words('english'))self.lemmatizer = WordNetLemmatizer()# 加載并預處理數據self.load_data()self.preprocess_data()def load_data(self):"""加載數據集(使用UCI的垃圾郵件數據集)"""print("正在加載垃圾郵件數據集...")# 使用pandas讀取數據集(這里使用公開的垃圾郵件數據集URL)url = "https://archive.ics.uci.edu/ml/machine-learning-databases/spambase/spambase.data"columns = [f'word_freq_{i}' for i in range(48)] + \[f'char_freq_{i}' for i in range(6)] + \['capital_run_length_average', 'capital_run_length_longest','capital_run_length_total', 'is_spam']self.data = pd.read_csv(url, header=None, names=columns)print(f"數據集加載完成,共 {self.data.shape[0]} 封郵件,{self.data.shape[1] - 1} 個特征")print(f"垃圾郵件比例: {self.data['is_spam'].mean():.2%}")def preprocess_data(self):"""數據預處理和劃分訓練測試集"""# 分離特征和標簽X = self.data.drop('is_spam', axis=1)y = self.data['is_spam']# 劃分訓練集和測試集self.X_train, self.X_test, self.y_train, self.y_test = train_test_split(X, y, test_size=0.3, random_state=42, stratify=y)print(f"訓練集: {self.X_train.shape[0]} 封郵件")print(f"測試集: {self.X_test.shape[0]} 封郵件")def visualize_data(self):"""數據可視化"""# 1. 垃圾郵件與正常郵件比例plt.figure(figsize=(8, 6))spam_counts = self.data['is_spam'].value_counts()sns.barplot(x=['正常郵件', '垃圾郵件'], y=spam_counts.values)plt.title('郵件類型分布')plt.ylabel('數量')for i, v in enumerate(spam_counts.values):plt.text(i, v + 50, f'{v} ({v / len(self.data):.2%})', ha='center')plt.show()# 2. 最能區分垃圾郵件的特征# 計算特征與垃圾郵件標簽的相關性correlations = self.data.corr()['is_spam'].sort_values(ascending=False)# 取相關性最高和最低的各10個特征top_features = pd.concat([correlations.head(11), correlations.tail(10)])top_features = top_features.drop('is_spam') # 移除自身相關性plt.figure(figsize=(12, 8))sns.barplot(x=top_features.values, y=top_features.index)plt.title('與垃圾郵件相關性最高的特征')plt.xlabel('相關性系數')plt.axvline(x=0, color='gray', linestyle='--')plt.tight_layout()plt.show()def build_models(self):"""構建多種分類模型"""self.models = {'樸素貝葉斯': MultinomialNB(),'邏輯回歸': LogisticRegression(max_iter=1000, random_state=42),'支持向量機': SVC(probability=True, random_state=42),'隨機森林': RandomForestClassifier(random_state=42)}def train_models(self):"""訓練所有模型"""print("\n=== 模型訓練結果 ===")for name, model in self.models.items():# 訓練模型model.fit(self.X_train, self.y_train)# 預測y_pred = model.predict(self.X_test)y_prob = model.predict_proba(self.X_test)[:, 1] # 預測為垃圾郵件的概率# 保存結果self.predictions[name] = y_predself.probabilities[name] = y_prob# 計算準確率accuracy = accuracy_score(self.y_test, y_pred)print(f"{name} 準確率: {accuracy:.4f}")def evaluate_model(self, model_name):"""詳細評估指定模型"""if model_name not in self.models:print(f"模型 {model_name} 不存在,請先構建模型")returnprint(f"\n=== {model_name} 詳細評估 ===")# 1. 混淆矩陣cm = confusion_matrix(self.y_test, self.predictions[model_name])plt.figure(figsize=(8, 6))sns.heatmap(cm, annot=True, fmt='d', cmap='Blues',xticklabels=['正常郵件', '垃圾郵件'],yticklabels=['正常郵件', '垃圾郵件'])plt.xlabel('預測標簽')plt.ylabel('真實標簽')plt.title(f'{model_name} 混淆矩陣')plt.show()# 2. 分類報告print("\n分類報告:")print(classification_report(self.y_test,self.predictions[model_name],target_names=['正常郵件', '垃圾郵件']))# 3. ROC曲線和AUCfpr, tpr, _ = roc_curve(self.y_test, self.probabilities[model_name])roc_auc = auc(fpr, tpr)plt.figure(figsize=(8, 6))plt.plot(fpr, tpr, color='darkorange', lw=2, label=f'ROC曲線 (AUC = {roc_auc:.4f})')plt.plot([0, 1], [0, 1], color='navy', lw=2, linestyle='--')plt.xlim([0.0, 1.0])plt.ylim([0.0, 1.05])plt.xlabel('假正例率 (FPR)')plt.ylabel('真正例率 (TPR)')plt.title(f'{model_name} ROC曲線')plt.legend(loc="lower right")plt.show()# 4. 精確率-召回率曲線precision, recall, _ = precision_recall_curve(self.y_test, self.probabilities[model_name])plt.figure(figsize=(8, 6))plt.plot(recall, precision, color='blue', lw=2)plt.xlabel('召回率 (Recall)')plt.ylabel('精確率 (Precision)')plt.title(f'{model_name} 精確率-召回率曲線')plt.xlim([0.0, 1.0])plt.ylim([0.0, 1.05])plt.show()# 5. 交叉驗證cv_scores = cross_val_score(self.models[model_name],self.data.drop('is_spam', axis=1),self.data['is_spam'],cv=5)print(f"交叉驗證準確率: {cv_scores.mean():.4f} (±{cv_scores.std():.4f})")def compare_models(self):"""比較所有模型的性能"""# 收集各模型的評估指標metrics = []for name in self.models.keys():report = classification_report(self.y_test, self.predictions[name],target_names=['正常郵件', '垃圾郵件'],output_dict=True)metrics.append({'模型': name,'準確率': accuracy_score(self.y_test, self.predictions[name]),'精確率': report['垃圾郵件']['precision'],'召回率': report['垃圾郵件']['recall'],'F1分數': report['垃圾郵件']['f1-score']})metrics_df = pd.DataFrame(metrics)# 繪制各指標對比圖plt.figure(figsize=(15, 10))for i, metric in enumerate(['準確率', '精確率', '召回率', 'F1分數']):plt.subplot(2, 2, i + 1)sns.barplot(x='模型', y=metric, data=metrics_df)plt.title(f'不同模型的{metric}對比')plt.ylim(0.8, 1.0) # 設置y軸范圍以便更好地觀察差異for j, v in enumerate(metrics_df[metric]):plt.text(j, v + 0.005, f'{v:.4f}', ha='center')plt.xticks(rotation=15)plt.tight_layout()plt.show()def optimize_model(self, model_name):"""優化指定模型的超參數"""if model_name not in self.models:print(f"模型 {model_name} 不存在,請先構建模型")returnprint(f"\n=== 優化 {model_name} 超參數 ===")# 定義參數網格param_grids = {'樸素貝葉斯': {'alpha': [0.1, 0.5, 1.0, 2.0, 5.0]},'邏輯回歸': {'C': [0.01, 0.1, 1, 10, 100],'penalty': ['l1', 'l2']},'支持向量機': {'C': [0.1, 1, 10],'kernel': ['linear', 'rbf'],'gamma': ['scale', 'auto']},'隨機森林': {'n_estimators': [50, 100, 200],'max_depth': [None, 10, 20],'min_samples_split': [2, 5]}}# 創建網格搜索對象grid_search = GridSearchCV(estimator=self.models[model_name],param_grid=param_grids[model_name],cv=5,scoring='f1',n_jobs=-1)# 執行網格搜索grid_search.fit(self.X_train, self.y_train)# 輸出最佳參數print(f"最佳參數: {grid_search.best_params_}")# 評估優化后的模型y_pred_opt = grid_search.predict(self.X_test)print("\n優化后的分類報告:")print(classification_report(self.y_test, y_pred_opt,target_names=['正常郵件', '垃圾郵件']))# 更新模型self.models[model_name] = grid_search.best_estimator_self.predictions[model_name] = y_pred_optself.probabilities[model_name] = grid_search.predict_proba(self.X_test)[:, 1]return grid_search.best_estimator_# 文本預處理函數(用于后續的原始郵件文本分類)
def preprocess_text(text):"""預處理郵件文本"""# 轉換為小寫text = text.lower()# 移除特殊字符和數字text = re.sub(r'[^a-zA-Z\s]', '', text)# 分詞words = text.split()# 移除停用詞并進行詞形還原lemmatizer = WordNetLemmatizer()stop_words = set(stopwords.words('english'))words = [lemmatizer.lemmatize(word) for word in words if word not in stop_words]# 重新組合為字符串return ' '.join(words)# 基于原始文本的分類器(額外功能)
class TextBasedSpamClassifier:def __init__(self):# 加載原始郵件文本數據self.load_text_data()# 文本預處理self.data['processed_text'] = self.data['text'].apply(preprocess_text)# 劃分訓練集和測試集X = self.data['processed_text']y = self.data['is_spam']self.X_train, self.X_test, self.y_train, self.y_test = train_test_split(X, y, test_size=0.3, random_state=42, stratify=y)# 創建TF-IDF向量器和模型 pipelineself.pipeline = Pipeline([('tfidf', TfidfVectorizer(max_features=5000)),('classifier', MultinomialNB())])def load_text_data(self):"""加載原始郵件文本數據"""print("\n正在加載原始郵件文本數據...")# 使用簡化的方式獲取帶文本的垃圾郵件數據# 這里使用一個包含郵件文本和標簽的示例數據集# 實際應用中可以替換為自己的數據集try:# 嘗試從公開URL加載數據url = "https://raw.githubusercontent.com/justmarkham/pycon-2016-tutorial/master/data/sms.tsv"self.data = pd.read_csv(url, sep='\t', header=None, names=['is_spam', 'text'])self.data['is_spam'] = self.data['is_spam'].map({'ham': 0, 'spam': 1})print(f"原始文本數據集加載完成,共 {self.data.shape[0]} 條短信")except:# 如果加載失敗,使用模擬數據print("無法加載遠程數據,使用模擬數據")texts = ["Free money now! Click here","Hi, how are you doing?","Congratulations! You won a prize","Meeting tomorrow at 3pm","Get free access to our service","Can you send me the report?","Claim your discount today","Dinner tonight?","You have been selected for a free trial","Reminder: doctors appointment"]is_spam = [1, 0, 1, 0, 1, 0, 1, 0, 1, 0]self.data = pd.DataFrame({'text': texts, 'is_spam': is_spam})def train(self):"""訓練模型"""print("訓練基于文本的垃圾郵件分類器...")self.pipeline.fit(self.X_train, self.y_train)# 評估y_pred = self.pipeline.predict(self.X_test)print(f"基于文本的分類器準確率: {accuracy_score(self.y_test, y_pred):.4f}")print("分類報告:")print(classification_report(self.y_test, y_pred,target_names=['正常郵件', '垃圾郵件']))def predict(self, text):"""預測單封郵件是否為垃圾郵件"""processed = preprocess_text(text)prediction = self.pipeline.predict([processed])[0]probability = self.pipeline.predict_proba([processed])[0][1]result = "垃圾郵件" if prediction == 1 else "正常郵件"print(f"\n郵件內容: {text}")print(f"預測結果: {result} (概率: {probability:.4f})")return resultif __name__ == "__main__":# 創建垃圾郵件分類器實例classifier = SpamClassifier()# 數據可視化classifier.visualize_data()# 構建并訓練模型classifier.build_models()classifier.train_models()# 比較所有模型classifier.compare_models()# 選擇表現較好的模型進行詳細評估(默認邏輯回歸)best_model = '邏輯回歸'classifier.evaluate_model(best_model)# 優化最佳模型classifier.optimize_model(best_model)# 展示基于原始文本的分類器(額外功能)text_classifier = TextBasedSpamClassifier()text_classifier.train()# 測試幾個示例郵件test_emails = ["Congratulations! You've won a $1000 gift card. Click the link to claim now!","Hi John, are we still meeting for lunch tomorrow? Let me know.","Free entry in 2 a wkly comp to win FA Cup final tkts 21st May 2005. Text FA to 87121 to receive entry question(std txt rate)","Please find attached the report you requested. Let me know if you need any changes.","URGENT! Your account has been compromised. Click here to verify your information."]print("\n=== 測試郵件預測 ===")for email in test_emails:text_classifier.predict(email)
這個垃圾郵件分類項目的主要功能和特點:
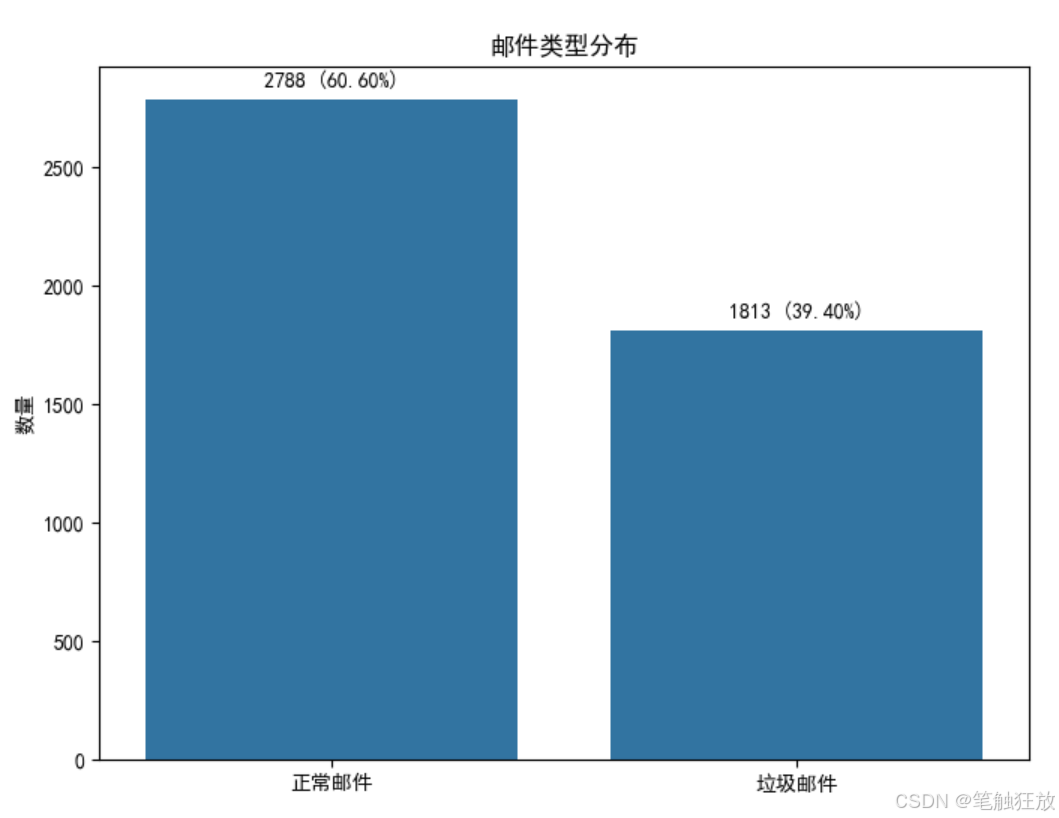
數據集選擇:使用 UCI 的垃圾郵件數據集(Spambase),包含 4601 封郵件和 57 個特征,以及一個基于原始文本的 SMS 垃圾短信數據集
完整流程:實現了從數據加載、探索性分析、可視化、模型訓練、評估到預測的完整流程
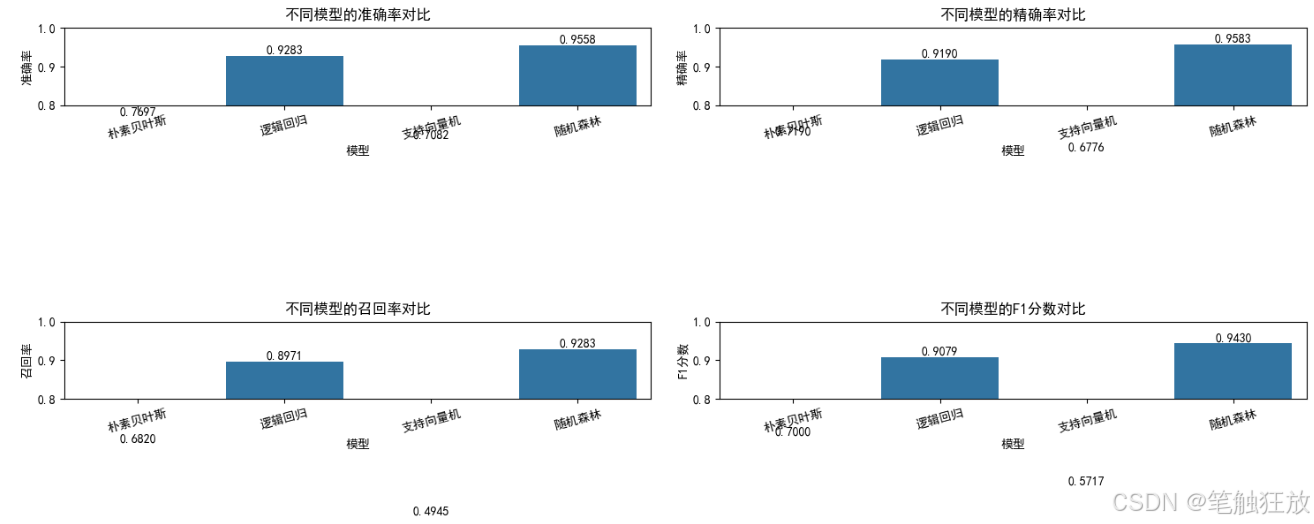
多種分類算法:包含樸素貝葉斯、邏輯回歸、支持向量機和隨機森林四種經典分類算法
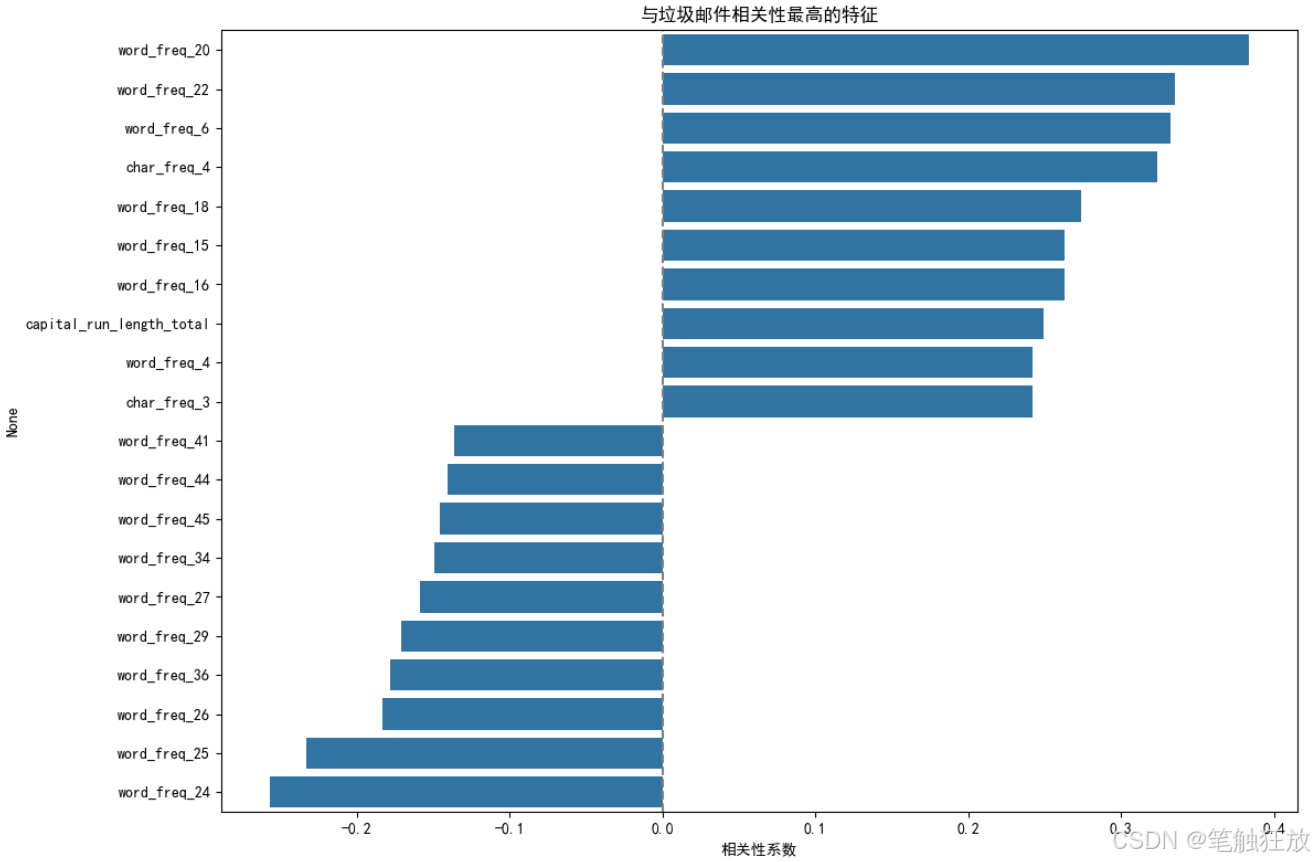
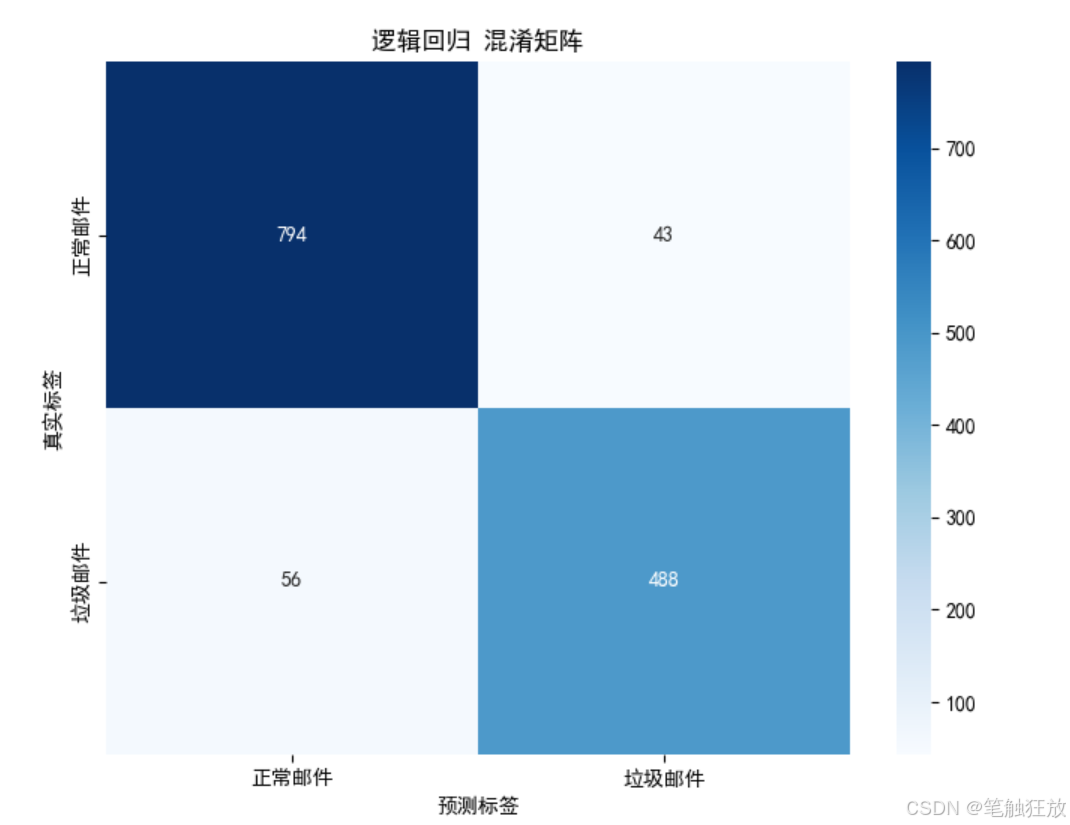
豐富的可視化:提供郵件類型分布、特征相關性、混淆矩陣、ROC 曲線和精確率 - 召回率曲線等可視化圖表
全面評估指標:使用準確率、精確率、召回率、F1 分數和 AUC 等指標評估模型性能
模型優化:實現了超參數網格搜索優化功能,提升模型性能
雙重分類方式:
基于提取的特征(詞頻、字符頻率等)進行分類
基于原始文本(使用 TF-IDF 向量化)進行分類
運行前需要安裝以下依賴庫:
pip install numpy pandas matplotlib seaborn scikit-learn nltk
程序運行后會:
展示數據集的基本信息和類別分布
生成多種可視化圖表幫助理解數據特征
訓練四種分類模型并比較它們的性能
對表現最佳的模型(默認邏輯回歸)進行詳細評估
優化最佳模型的超參數以獲得更好的分類效果
額外提供基于原始文本的分類器,并對示例郵件進行預測
你可以通過修改test_emails列表中的內容來測試不同的郵件文本,觀察模型的分類結果。這個項目對于理解文本分類、特征工程和機器學習模型在垃圾郵件檢測中的應用非常有幫助。



-記錄實戰教程及問題的解決方法)



)







![[C/C++學習] 7.“旋轉蛇“視覺圖形生成](http://pic.xiahunao.cn/[C/C++學習] 7.“旋轉蛇“視覺圖形生成)



