
在互聯網應用不斷發展的二十多年里,MySQL 一直是最廣泛使用的開源關系型數據庫之一。它憑借開源、輕量、靈活的優勢,支撐了無數網站、移動應用和企業系統。支撐 MySQL 長期發展的關鍵之一,就是 復制(Replication)技術。
復制機制不僅用于 讀寫分離,還廣泛應用于 高可用、容災備份、分布式架構。本文將詳細回顧 MySQL 復制技術的發展歷程,結合實際生產應用分析其意義,并對安全性進行客觀星級評比。
一、單機時代與最初的主從復制(基于語句的復制)
技術背景
在 2000 年前后,互聯網業務還處于起步階段,大多數系統訪問量有限,一臺 MySQL 單機即可滿足。但隨著門戶網站、早期電商的興起,讀請求和寫請求的壓力不斷上升,單機架構逐漸捉襟見肘。
技術實現
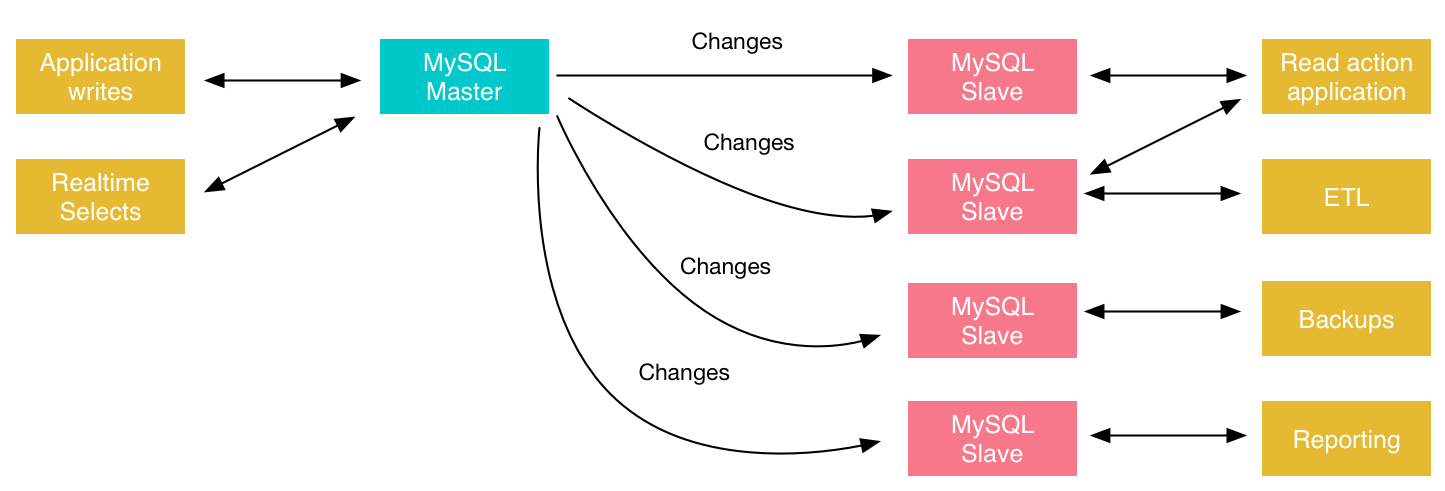
MySQL 在3.23(2001 年)首次引入了 主從復制(Master-Slave Replication),工作流程如下:
主庫將所有寫入操作記錄到 二進制日志(binlog)。
從庫的 IO 線程從主庫拉取 binlog,寫入 中繼日志(relay log)。
從庫的 SQL 線程順序執行 relay log 中的語句,重放主庫操作。
默認復制模式為 基于語句的復制(Statement-Based Replication, SBR),即直接把 SQL 語句寫入 binlog 并在從庫執行。
應用場景
讀多寫少的 新聞門戶、社區論壇:讀請求走從庫,寫請求走主庫。
早期電商的 商品瀏覽和 庫存更新場景:大多數讀流量分攤到多個從庫。
意義
以極低的成本實現了 水平擴展(增加從庫即可分擔讀壓力)。
奠定了互聯網應用架構中 讀寫分離 的雛形。
不足
對非確定性語句(如
NOW()、RAND())存在 重放歧義,導致主從數據不一致。主從延遲在高并發場景下仍可能積累。
二、行級復制(Row-Based Replication, RBR)
技術背景
隨著業務復雜化,SBR 的數據一致性問題暴露越來越多,尤其在金融、電商支付等場景下,任何數據不一致都可能導致嚴重事故。
技術實現
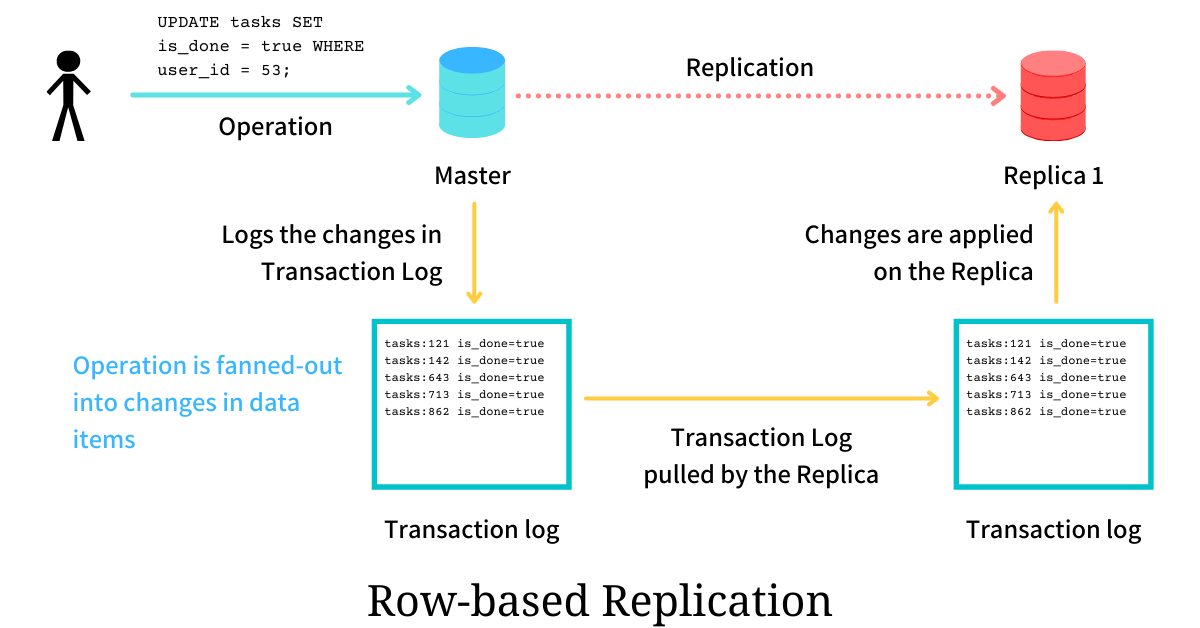
MySQL 5.1(2008 年)**引入 RBR,binlog 不再記錄 SQL,而是記錄 行數據的變更結果:
SBR:記錄語句
UPDATE user SET balance=balance+100 WHERE id=1;RBR:記錄變更行
id=1,舊值=500,新值=600
應用場景
支付、金融:賬戶余額必須絕對一致。
庫存管理:電商大促期間,庫存扣減的準確性直接影響發貨與售后。
意義
有效解決了 SBR 的一致性問題,實現了 強一致復制。
支持更復雜的語句,業務對數據準確性更有保障。
不足
binlog 體積更大,存儲與傳輸開銷增加。
對大批量更新,RBR 性能可能顯著下降。
三、混合復制(Mixed-Based Replication, MBR)
技術背景
單純使用 RBR,日志量過大,性能不佳;單純使用 SBR,又有一致性隱患。于是 MySQL 在 5.1 中同時推出 混合復制模式(MBR)。
技術實現
普通的確定性語句 → 使用 SBR,提高性能。
非確定性、存在歧義的語句 → 使用 RBR,保證一致性。
應用場景
電商網站:商品瀏覽、大批量商品更新場景用 SBR;庫存扣減、訂單支付用 RBR。
內容分發平臺:大規模數據同步時更靈活。
意義
在 效率與一致性之間找到平衡,適合大部分互聯網中型業務。
不足
自動選擇機制并不總是“最優”,有時仍需人工配置。
四、并行復制(Parallel Replication)
技術背景
隨著互聯網進入 移動互聯網和大數據時代(2010s),主庫 QPS 可達數萬,但從庫單線程回放卻跟不上,導致 主從延遲數十秒甚至數分鐘,無法滿足實時性需求。
技術實現
5.6(2013):庫級并行復制,不同數據庫的事務可并行執行。
5.7(2015):基于組提交的并行復制,同一庫中不同事務可并行。
8.0(2018):基于 Write Set,利用事務寫集合判斷是否沖突,實現接近主庫的并行度。
應用場景
電商大促:秒殺期間主庫高并發寫入,從庫延遲必須縮小到毫秒級,才能快速切換。
金融系統:實時交易要求從庫與主庫幾乎同步。
意義
極大縮短了主從延遲,使 高可用架構真正可用。
提升了 容災切換 的可靠性。
不足
并行度受限于事務沖突,如果業務邏輯高度集中,效果有限。
五、全局事務 ID(GTID)與自動故障轉移
技術背景
在早期 MySQL 架構中,主從切換必須人工定位 binlog 文件名和位置,繁瑣且容易出錯,嚴重時會導致數據丟失。
技術實現
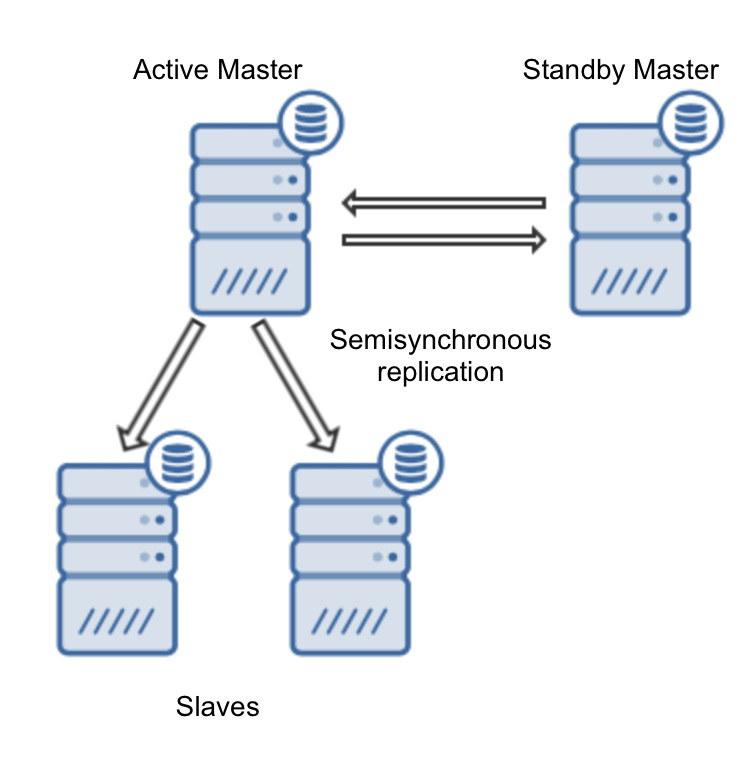
MySQL 5.6 引入 GTID(Global Transaction Identifier),每個事務生成唯一標識。
主從切換時,無需關心 binlog 文件位置,只需比對 GTID 集合。
自動化工具(如 MHA、Orchestrator)可據此快速完成切換。
應用場景
高可用架構:互聯網金融、電商平臺需要快速主從切換。
云數據庫:自動化容災切換的核心機制。
意義
顯著降低了人工失誤風險。
推動了 MySQL 自動化高可用 的發展。
不足
本身不提高一致性,仍依賴復制模式(SBR/RBR)。
六、組復制與 InnoDB Cluster
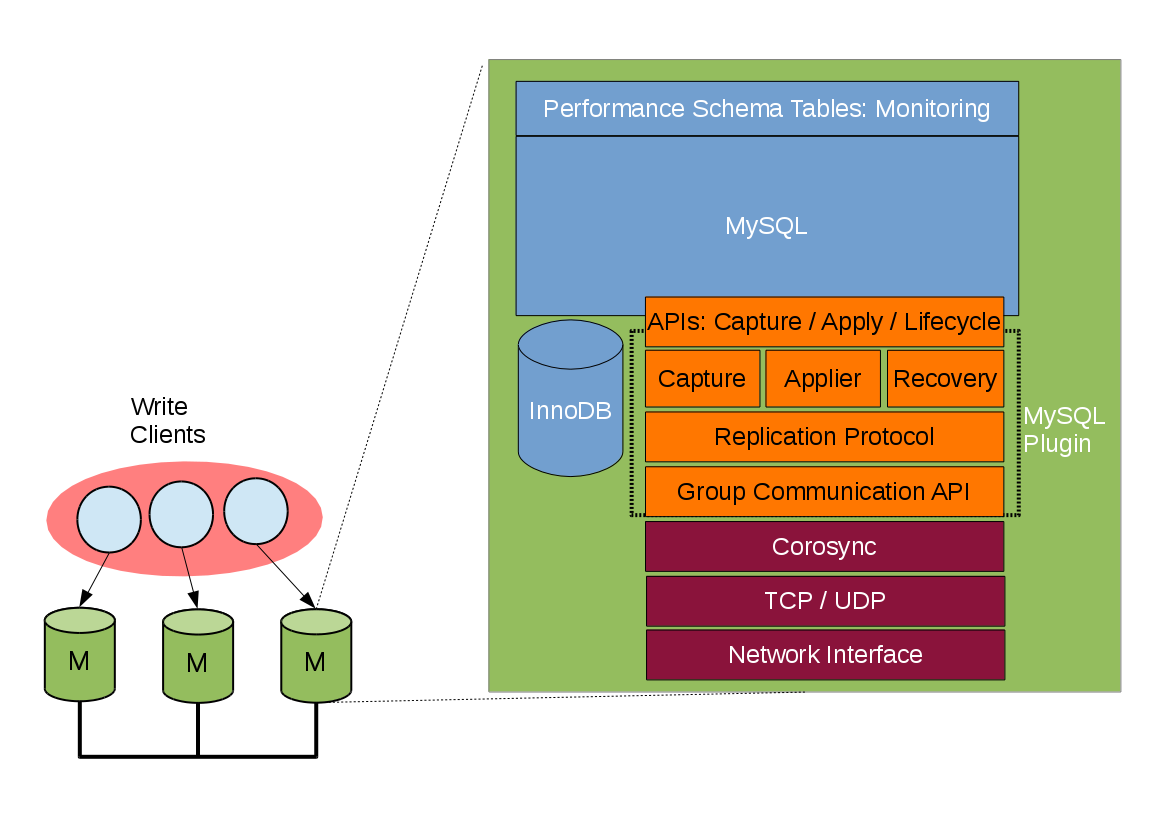
技術背景
進入 云計算時代(2016+),企業對數據庫的需求已不只是擴展性,還需要 分布式一致性 和 自動高可用。
技術實現
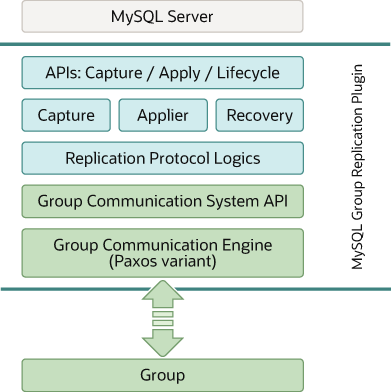
組復制(Group Replication, GR):基于 Paxos/Raft 協議,事務提交需獲得多數節點確認。
InnoDB Cluster:官方高可用集群方案,集成組復制、MySQL Router、Shell 管理工具。
應用場景
金融支付系統:保障交易的強一致性和自動容災。
電商大促:保證在節點宕機時快速恢復,業務不中斷。
IoT/實時采集:海量并發寫入場景下仍保證一致性。
意義
標志著 MySQL 從 單機復制 走向 分布式一致性集群。
為傳統企業和云廠商提供了官方級高可用解決方案。
不足
架構和管理復雜度顯著上升。
吞吐量相比異步復制有所犧牲。
七、安全性評比
不同復制技術在數據一致性、容錯能力、防丟失風險上有明顯差異:
| 技術階段 | 安全性星級 | 評語 |
|---|---|---|
| 語句復制(SBR) | ★★☆☆☆ | 高效,但易出現不一致,適合安全性要求低的讀寫分離。 |
| 行級復制(RBR) | ★★★★☆ | 強一致性,金融/支付首選,但日志開銷大。 |
| 混合復制(MBR) | ★★★☆☆ | 折中方案,整體安全性中等。 |
| 并行復制 | ★★★★☆ | 縮短延遲,降低風險,但仍依賴底層復制模式。 |
| GTID 復制 | ★★★★☆ | 簡化主從切換,減少運維錯誤,提升安全性。 |
| 組復制 & InnoDB Cluster | ★★★★★ | 內置一致性協議,支持沖突檢測與自動選主,是最高等級的安全方案。 |
八、總結
2000s:SBR → RBR —— 從低成本擴展到數據一致性保障
2010s:并行復制 + GTID —— 緩解延遲瓶頸,提升高可用性
2020s:組復制/InnoDB Cluster —— 邁向分布式強一致與自動容災
可以說,MySQL 復制技術的發展史,就是互聯網架構在 擴展性 — 一致性 — 高可用 三個維度不斷進化的縮影。

)







![[C/C++學習] 7.“旋轉蛇“視覺圖形生成](http://pic.xiahunao.cn/[C/C++學習] 7.“旋轉蛇“視覺圖形生成)









