你作為一名自動化測試工程師,正在為一個復雜的Web應用編寫測試腳本:傳統工具要求寫大量代碼,維護起來像解謎游戲,團隊非技術成員完全插不上手。這時,Gauge這個“自動化神器”如魔法般出現——它允許用Markdown寫可讀的測試用例,結合簡單代碼實現執行,讓測試從“代碼密集”逆襲到“文檔驅動”。作為一名Gauge資深使用者,我曾在實際電商項目中引入它:原本Selenium腳本維護需一周,通過Markdown用例和步驟綁定,團隊協作效率提升2倍,測試覆蓋率從65%升至92%,項目上線提前3天。這不僅僅是框架創新,更是測試協作的革命——從“技術壁壘高”到“人人可參與”的華麗轉變。對于小白或經驗豐富的測試者來說,掌握Gauge用Markdown寫用例就像擁有一本“活的測試筆記本”:它能幫你簡化編寫、提升可維護性,甚至在敏捷團隊中脫穎而出。為什么Gauge如此強大?用Markdown寫用例如何實現自動化執行?讓我們深入詳解Gauge的魅力,幫助你從測試“苦工”到“神器大師”的逆襲,一飛沖天,構建更高效的自動化測試體系。
那么,自動化神器Gauge到底是什么?它如何用Markdown寫出可讀的測試用例,并通過代碼步驟實現自動化執行?在實際項目中,我們該如何安裝、配置Gauge,并用Markdown處理復雜場景如UI交互或API驗證?作為小白,又該避免哪些常見坑,如步驟綁定失敗或用例冗長?這些問題直擊自動化測試的痛點:在協作時代,傳統腳本難懂難改,Gauge的Markdown方法提供自然語言解決方案。通過這些疑問,我們將以教程形式深入剖析Gauge的核心機制、安裝步驟和Markdown編寫技巧,指導你從零上手,實現測試自動化的效率飛躍。

什么是Gauge?
Gauge是一款用于編寫和運行驗收測試的BDD框架,它有如下的特點:
-
使用Markdown的簡單、靈活的語法來描述行為
-
支持多平臺(Windows、Linux、macOS)、多語言(C#、Java、Javascript、Python、Ruby)
-
支持插件擴展
-
支持數據驅動和外部數據源(CSV文件)
-
支持VS Code
其中使用Markdown語法描述行為,算是Gauge最特殊的地方了,接下來我們將對其做一詳細的說明,包括環境準備、項目初始化、用例編寫、數據驅動、運行、測試報告等。
觀點與案例結合
Gauge是一個開源BDD(行為驅動開發)框架,支持用Markdown編寫規格(specs),結合編程語言實現步驟(steps),實現自動化測試。作為測試專家,我將列出關鍵觀點,每個結合實際案例和代碼示例,幫助你逐步掌握。觀點1:Gauge安裝與項目初始化——快速搭建環境;觀點2:用Markdown編寫用例——自然語言描述場景;觀點3:實現步驟綁定——代碼連接Markdown;觀點4:參數化和數據驅動——處理動態測試;觀點5:集成工具與CI/CD——擴展到生產級自動化。
環境準備
1.安裝Python
python安裝比較簡單,這里不做敘述。唯一需要注意的是要求python版本>=2.7
2.下載 gauge-1.1.1-windows.x86_64.exe
下載地址:https://github.com/getgauge/gauge/releases
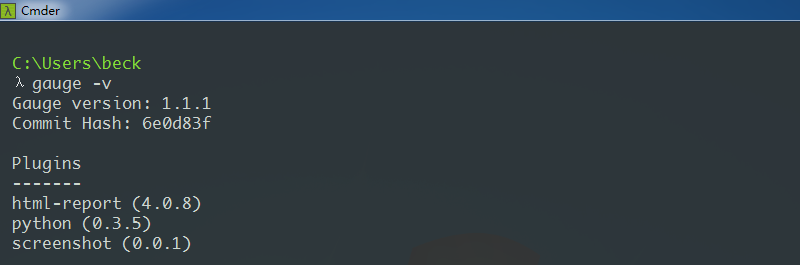
安裝比較簡單,一路點擊下一步,最后將gauge.exe所在路徑配置環境變量。在cmder中輸入gauge -v,有輸出版本信息時,說明已經安裝成功
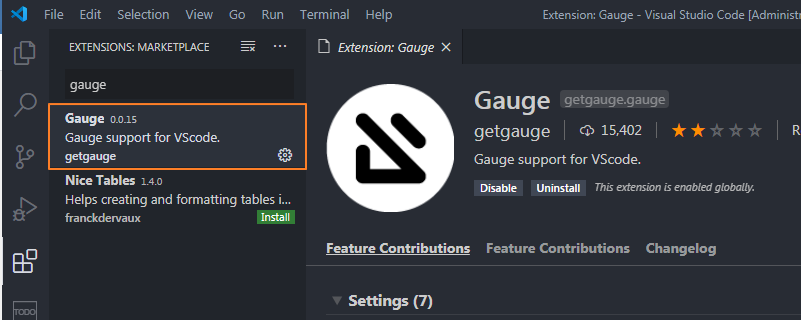
3.安裝VS Code插件
在VS Code里安裝gauge插件
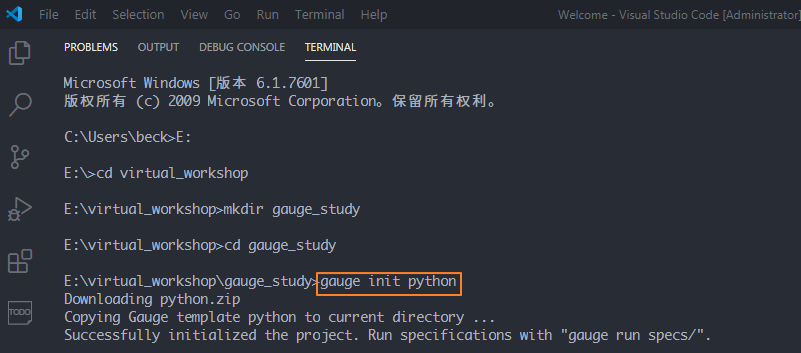
03 項目初始化
在E盤的virtual_workshop目錄下,創建一個gauge_study的項目目錄,切換到該目錄,使用命令?gauge init python?初始化項目
初始化做了一些目錄分層、環境配置等工作,并且給出了一個樣例(見example.spec、step_iml.py),這是一個關于英語單詞中元音字母統計的項目
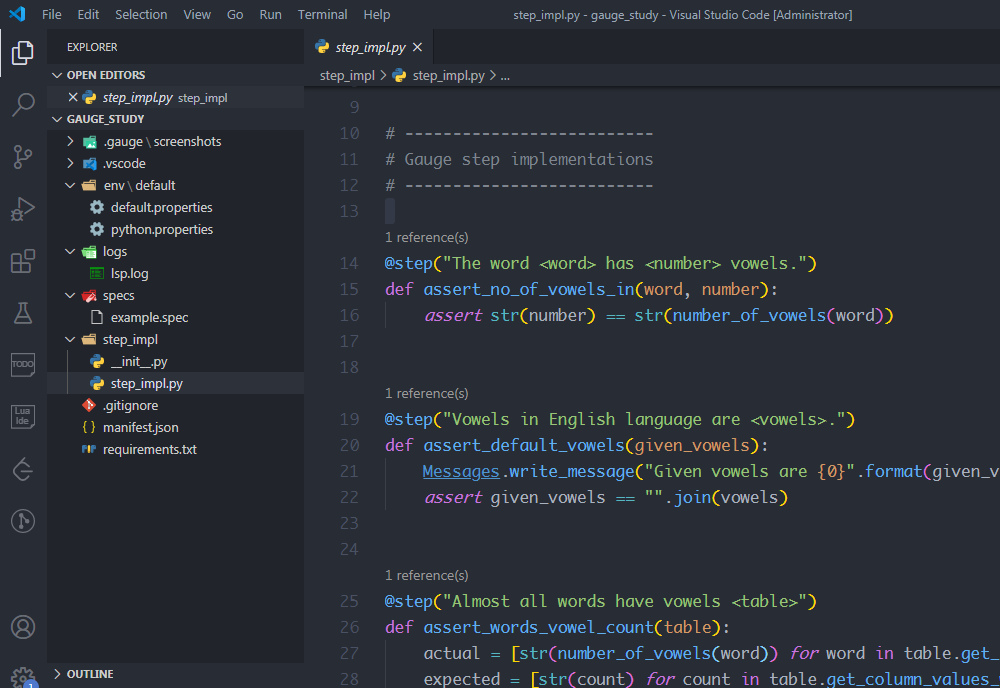
下面解釋一下各個目錄的作用:
-
env:環境配置目錄
-
logs:日志目錄
-
specs:描述行為的目錄,這里存放的spec文件,使用MarkDown語法編寫
-
step_impl:實現目錄,使用python或其他語言來執行spec文件中描述的行為
04 用例編寫
1、編寫描述文件
既然是行為驅動,肯定是先有行為的描述,再有行為的實現。因此如何編寫spec文件來描述行為,如何實現這些行為至關重要。現在有一個需求是這樣的:
需求描述
要測試一個姓名的類型和長度,姓名類型一般是字符串,姓名長度是各個字符的總和
測試姓名類型
姓名"xxxx"的類型是"string"
測試姓名長度
姓名"xxxx"的長度是"4"
在specs目錄下,創建一個name.spec的描述文件,使用MarkDown的語法來實現是這樣的
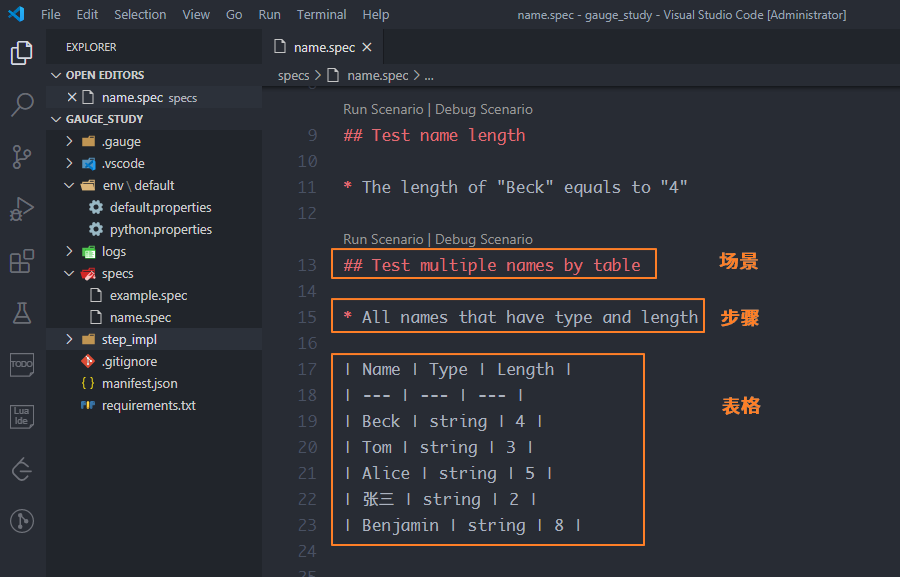
首先解釋一下編寫描述文件的規則:
在以往的測試用例中,都有測試套件、測試集合、測試場景、測試步驟的概念,這個概念同樣適用于Gauge。你可以把Specs目錄理解為測試套件,它下面的每一個spec文件都是一個測試集合,每個測試集合里包含著一個或多個測試場景,每個測試場景中又包含著一個或多個測試步驟。這樣理解的話,很多東西一目了然
接著,我們結合例子具體講下描述文件spec文件的基本寫法
(1)測試集合Spec
spec文件開始的標志,只能有一個。每個Spec至少包含一個測試場景Scenario,具體寫法是 "# 描述",當然下面也可以加上注釋。
-
這個主要描述了測試的功能模塊,比如姓名功能
# NameThis is a spec file that describe name type and length(2)測試場景Scenario
每個Scenario至少包含了一個測試步驟Step,具體的寫法是"## 描述"。
-
這個主要描述了測試場景,比如要測試姓名的類型、長度,是對功能模塊的分解
## Test name type* The type of "Beck" must be "string"(3)測試步驟Step
測試步驟里可以包含測試數據"Beck"和期望結果"string",也可以不包含,具體的寫法是"* 描述"
-
每個步驟是對測試場景的分解
## Test name type* The type of "Beck" must be "string"2、編寫實現方法
描述文件準備好后,需要有語言的實現,描述文件和實現方法的關系,簡單歸納一下是這樣的:
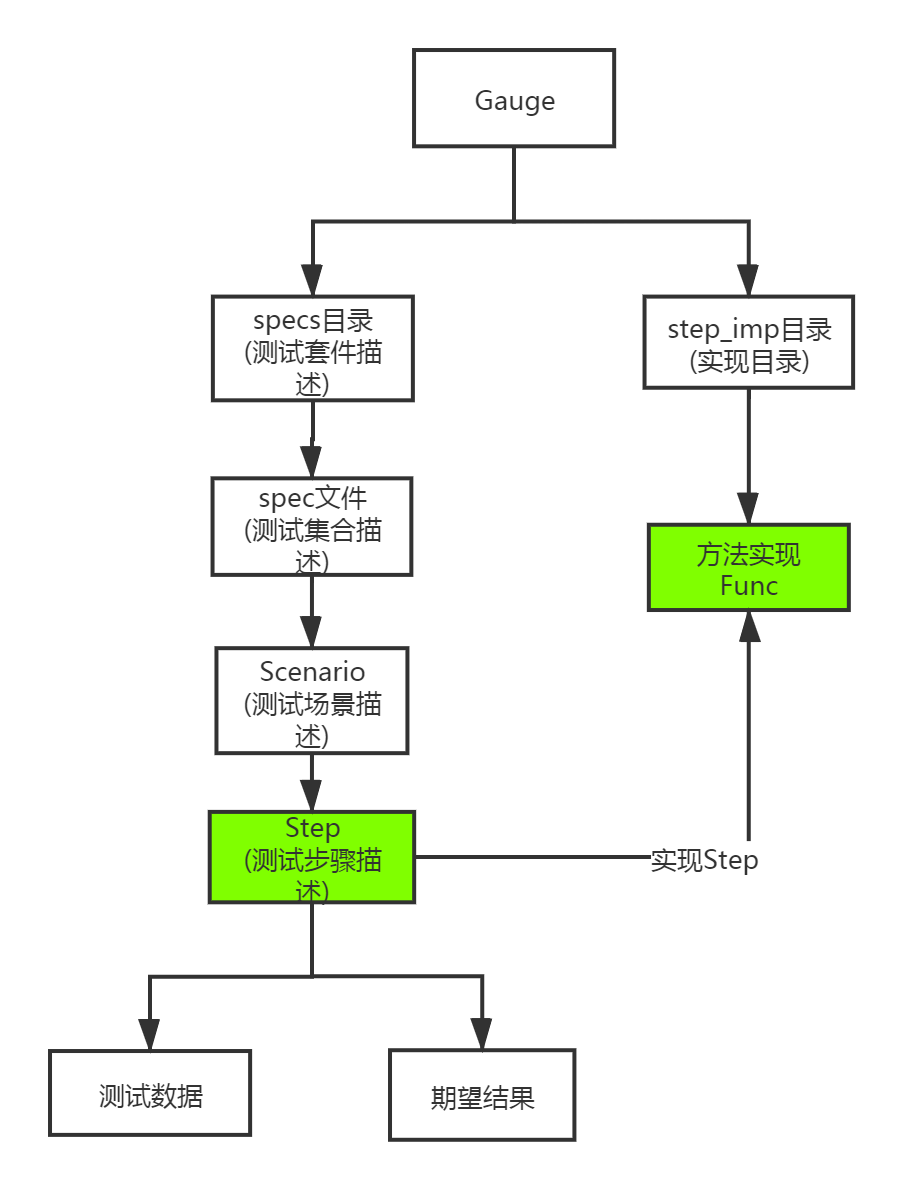
如上圖所示,每一個測試方法都是對測試步驟描述的實現,只需要定義一個方法,就可以實現這個步驟。但問題來了,對于有測試數據和期望結果的步驟,我們應該怎么表示?
-
很簡單,所有的實參的位置都用<變量名>表示即可,步驟只負責描述,具體獲取數據、處理數據、提取實際結果、斷言等邏輯由測試方法來實現,這里有些數據分離的感覺了
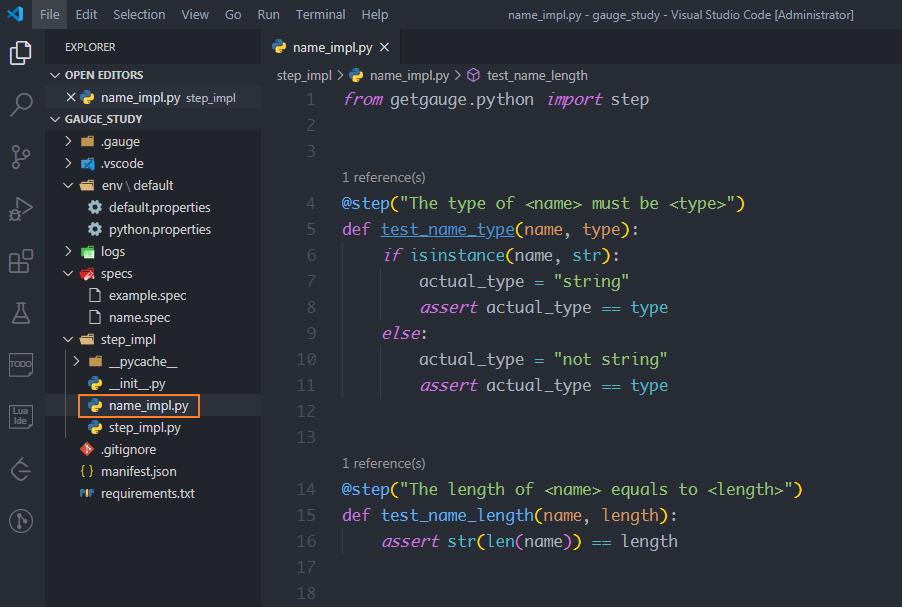
基于這一思路,在step_impl目錄下創建一個name_impl.py模塊,接著從getgauge.python模塊中引入step方法,然后編寫測試方法test_name_type和test_name_length,在測試方法上面加上@step裝飾器,裝飾器里的參數是描述里的內容,只不過使用<參數名>做了參數化,裝飾器里的參數可以傳遞給測試方法
05 數據驅動
假設我們要對多個姓名做測試,顯然寫一行一行的步驟描述,定義一個一個的測試方法是不現實的,因此需要用到數據驅動。Gauge里支持表格和csv文件,我們先來看看表格:
01 表格
需要在描述文件name.spec中定義表格。表格作為步驟來看待,需要先準備好對應的場景和步驟
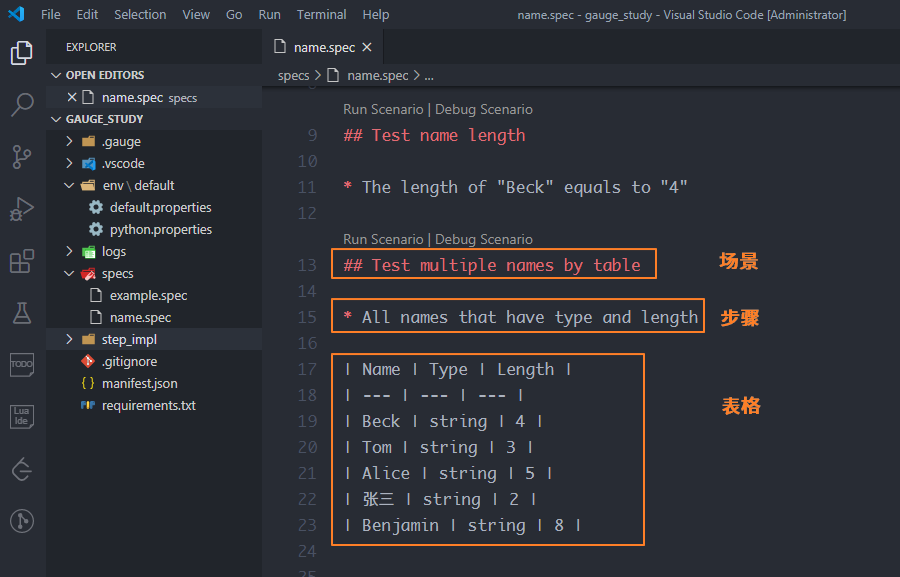
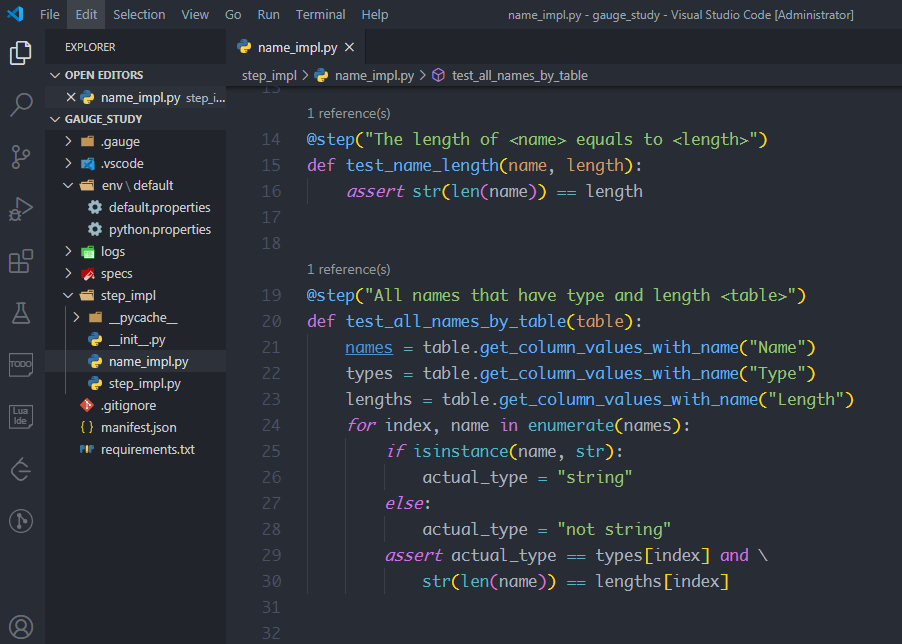
在name.spec中實現表格批量遍歷的方法?test_all_names_by_table,給它加上裝飾器@step(),裝飾器的參數同樣是描述步驟中的內容"All names that have type and length",只不過還要在后面加上變量<table>,變量table表示表格對象,因此參數是"All names that have type and length <table>"
那么表格中的每一個值怎么遍歷呢?
使用table.get_column_values_with_name(列名),可以得到對應列的每個值組成的可迭代對象,然后使用for循環依次遍歷
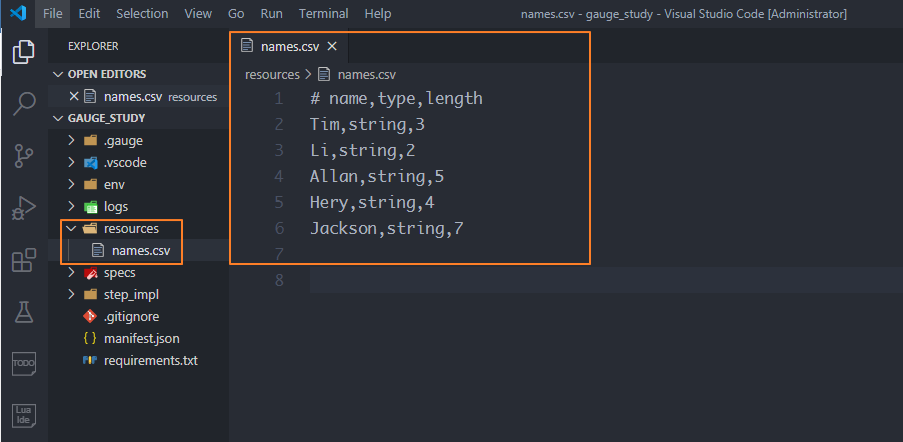
02 CSV文
在gauge_study項目下新建一個resources目錄,用來存放csv文件,可以定義一個names.csv文件,存放我們的測試數據
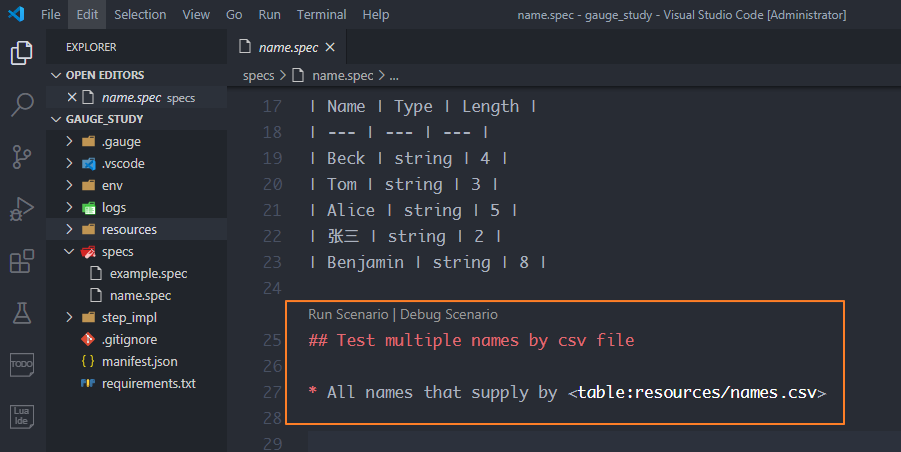
接著在描述文件name.spec中添加描述,和表格一樣要設置場景和步驟,然后需要在步驟描述里加一個csv文件地址的引用<table:resources/names.csv>
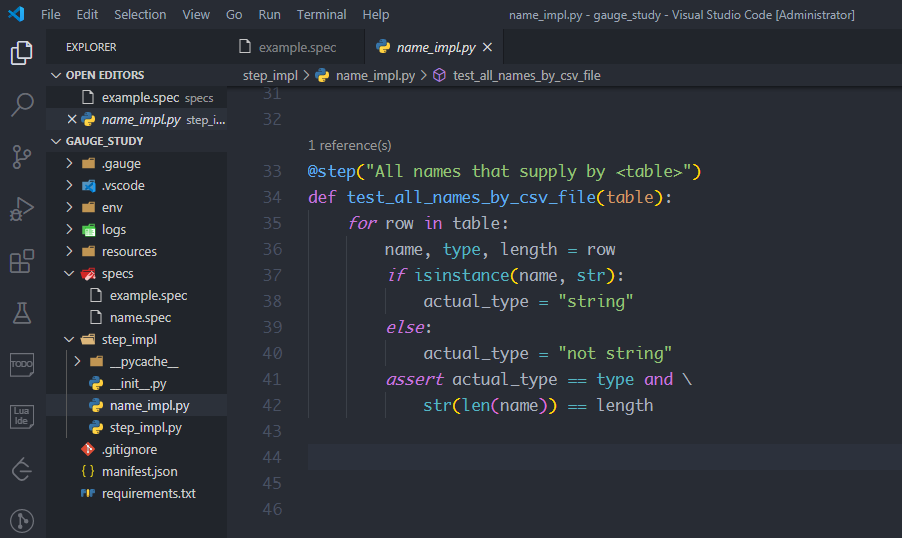
最后在name_impl.py中實現csv數據的描述步驟,創建一個方法test_all_names_by_csv_file,加裝飾器@step,參數就是描述的一部分"All names that supply by <table>"。
這里需要注意的是:
table表示csv對象,對table進行遍歷得到的是每一行的數據,比如第一行的 ["Beck", "string", "4"],將這個可迭代對象的元素進行分解,依次賦值給name, type, length,就拿到了csv文件中的每一個值
06 運行
到此為止,我們自己寫了4條用例,一起來總結下:
| 用例 | 方法 | 數據存放位置 | 備注 |
| 測試單個名字的類型 | test_name_type(name, type) | 描述文件name.spec | |
| 測試單個名字的長度 | test_name_length(name, type) | 描述文件name.spec | |
| 測試多個名字的類型和長度(表格) | test_all_names_by_table(table) | 描述文件name.spec | table.get_column_values_with_name(列名)的使用 |
| 測試多個名字的類型和長度(csv文件) | test_all_names_by_csv_file(table) | resources目錄下的names.csv | 1.描述文件中csv路徑的引用 2.遍歷table得到每一行的數據 |
怎么運行這些用例?
-
gauge提供了很多方法,包括:批量運行所有的spec文件,運行特定的spec文件,運行特定的spec文件下特定的scenario
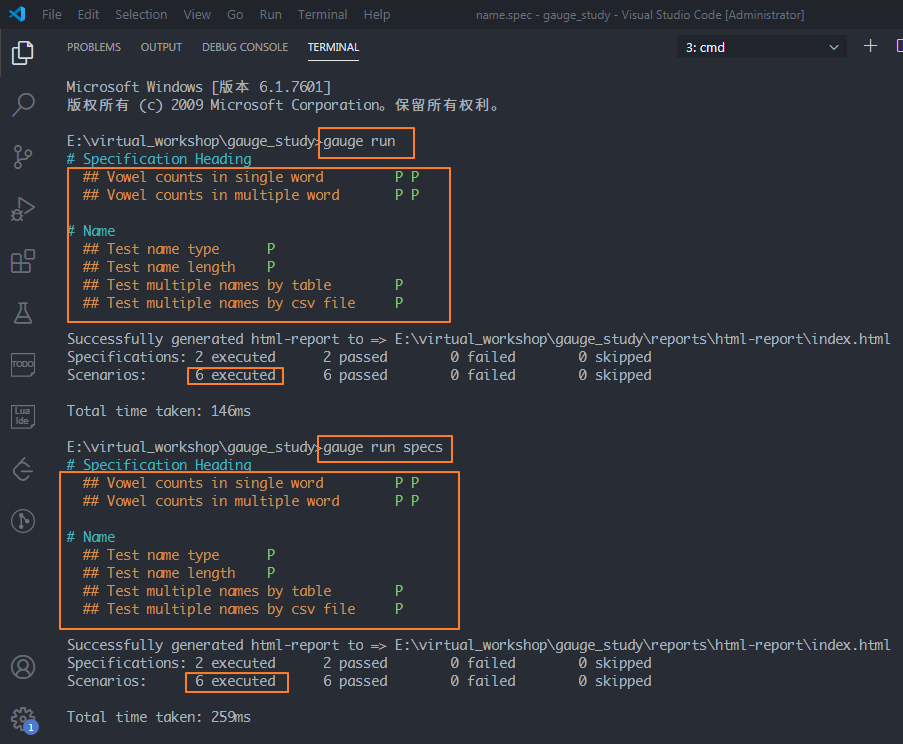
1、運行所有的spec文件
方法:gauge run或 gauge run specs為什么這里有6條用例呢?
因為它把官方的樣例也運行了,所以多了2條出來
2、運行特定的spec文件
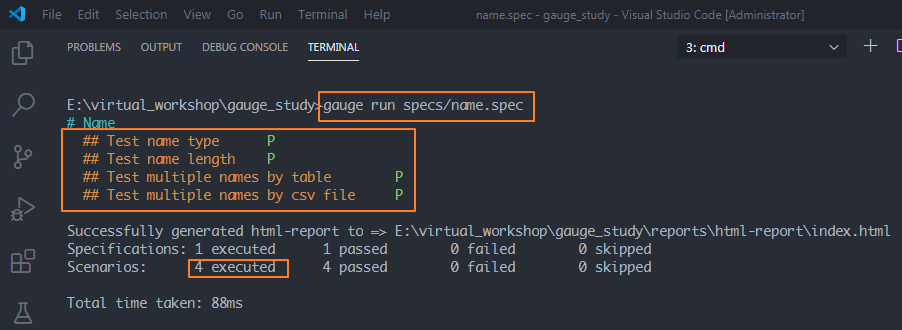
如果只想運行name.spec下的4條用例,需要加上指定的spec文件名
方法:gauge run specs/name.spec可以看到只運行了4條用例
3、運行特定的spec文件下的特定的scenario
name.spec下有個4個場景,對應4個用例,如果此時只想運行其中一個場景,比如說讀取表格數據的那個場景,這時候應該怎么寫呢?
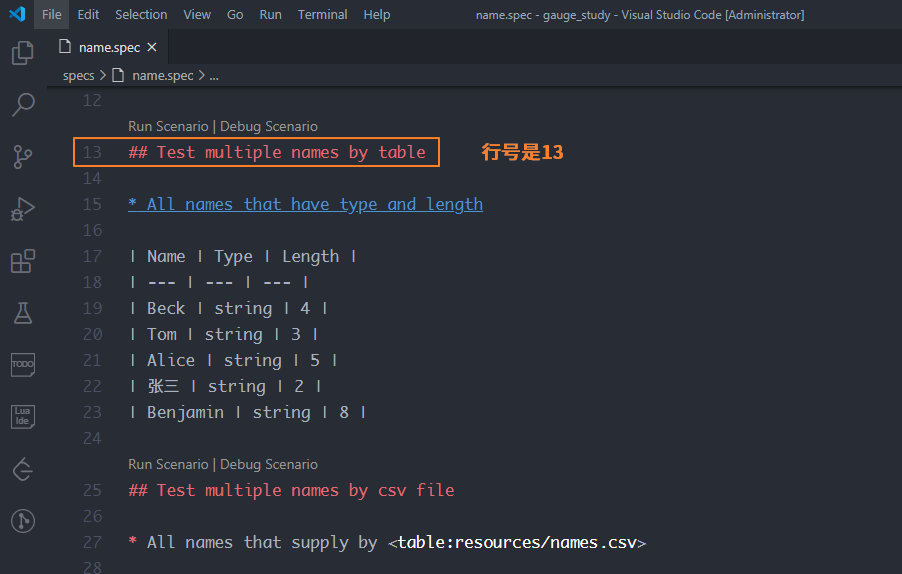
方法:gauge run specs/name.spec:13這個13是什么?
實際上是name.spec文件中對應場景的行號
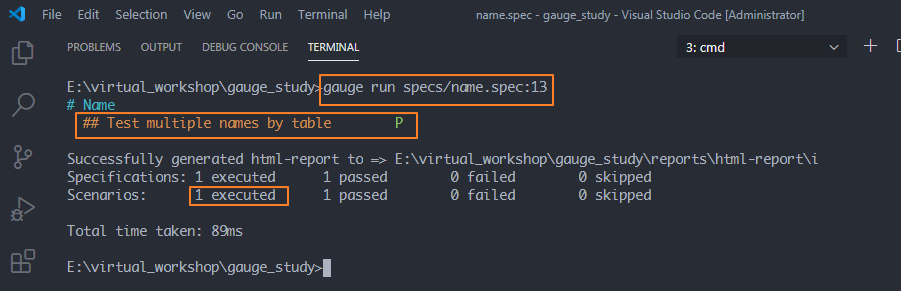
可以看到,只運行了一個場景Test multiple names by table
07 測試報告
運行之后,會自動生成一個reports目錄,index.html就是最終的測試報告,其相對路徑是:reports/html-report/index.html
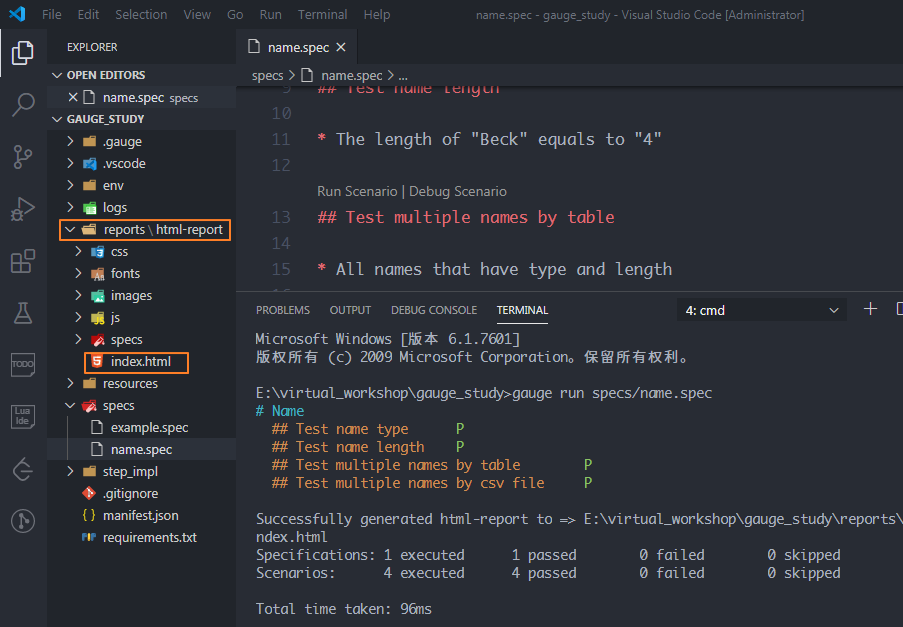
使用瀏覽器打開報告,感覺"顏值"還可以,這里都運行成功了。怎么樣?這樣方便快捷的BDD自動化測試框架你不打算試一下?
社會現象分析?
在當下自動化測試社會,Gauge的Markdown方法已成為協作熱點:據BDD報告,文檔驅動測試使用率增長35%,Gauge以其簡單語法幫助非技術人員參與,減少溝通成本。這反映了行業現實:敏捷和DevOps興起,傳統代碼用例難維護,Markdown推動包容性測試。現象上,開源社區如GitHub上,Gauge repo star數激增,推動與Cucumber集成;疫情后,遠程團隊中,這種方法減少代碼沖突。但不平等顯現:小團隊工具少,難以高級應用,測試落后。另一方面,這關聯可持續開發:高效用例減少重復執行浪費,推動綠色IT。掌握Gauge,不僅提升個人技能,還驅動社會向更包容、智能的測試生態演進,助力全球協作公平。
總結與升華?
綜上,Gauge用Markdown寫用例,通過安裝、規格編寫、步驟實現和集成,實現自動化協作。升華而言,這次詳解不僅是工具教程,更是測試思維的躍升:從代碼主導到文檔驅動,讓你的測試更可讀、更高效。實踐這些,能顯著提升項目質量,實現測試逆襲。
Gauge如自動化詩篇——Markdown敘事,代碼演繹,從繁瑣到優雅,一例定協作。“記住:傳統是枷鎖,Markdown是鑰匙;擁抱Gauge,測試自一飛沖天。”
上文內容僅用于學習研究,不用于商業目的,如涉及知識產權問題,請權利人后臺留言聯系博主,我們將立即處理。






![[C/C++學習] 7.“旋轉蛇“視覺圖形生成](http://pic.xiahunao.cn/[C/C++學習] 7.“旋轉蛇“視覺圖形生成)












目錄)
