Kafka概述
kafka是一個分布式的基于發布/訂閱模式的消息隊列,主要用于大數據實時處理領域。kafka采取了發布/訂閱模式,消息的發布者不會將消息直接發送給特定的訂閱者,而是將發布的消息分為不同的類別,訂閱者只接受感興趣的消息。
消息隊列
-
傳統的消息隊列的主要應用場景包括:緩存/削峰、解耦和異步通信。
-
緩沖/削峰:有助于控制和優化數據流經過系統的速度,解決生產消息和消費消息的處理速度不一致的情況。
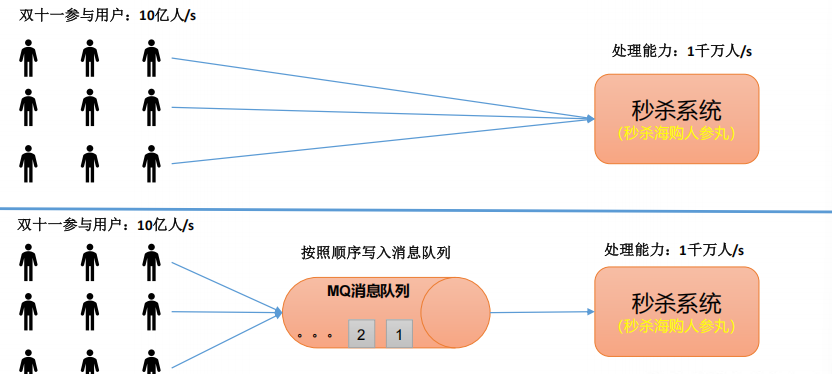
-
解耦:允許獨立的擴展或修改兩邊的處理過程,只要確保它們遵守同樣的接口約束。
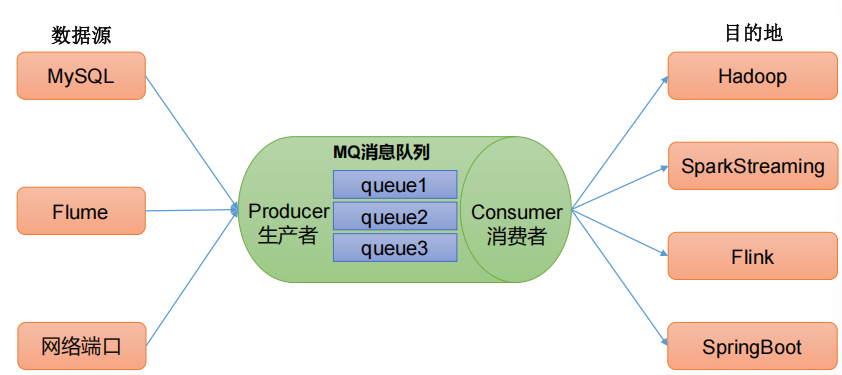
-
異步通信:允許用戶把一個消息放入隊列,但并不立即處理它,然后在需要的時候再去處理它們。
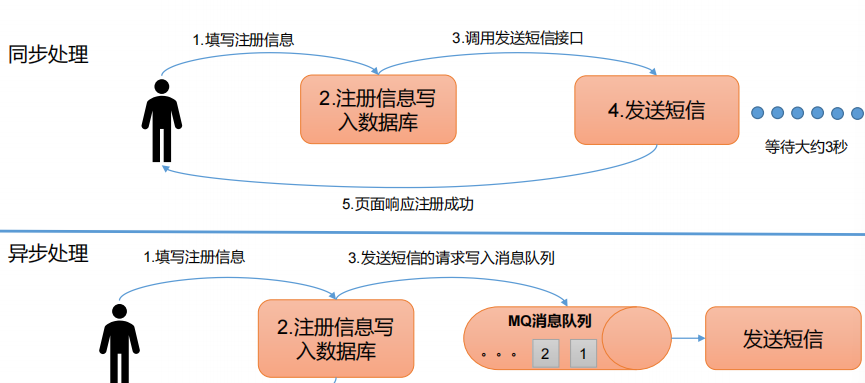
-
-
消息隊列的兩種模式
- 點對點模式:消費者主動拉取數據,消息收到后清除mq里的消息
- 發布/訂閱模式:可以有多個topic主題;消費者消費數據之后,不刪除數據;每個消費者相互獨立,都可以消費到數據。
Kafka基礎架構
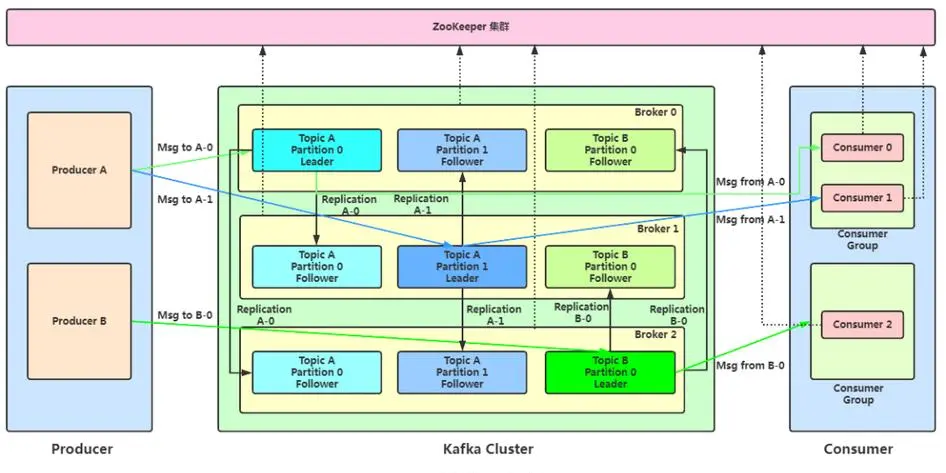
- Producer:消息生產者,就是向 Kafka broker 發消息的客戶端。
- Consumer:消息消費者,向 Kafka broker 取消息的客戶端。
- Consumer Group(CG):消費者組,由多個 consumer 組成。消費者組內每個消費者負責消費不同分區的數據,一個分區只能由一個組內消費者消費;消費者組之間互不影響。所有的消費者都屬于某個消費者組,即消費者組是邏輯上的一個訂閱者。
- Broker:一臺 Kafka 服務器就是一個 broker。一個集群由多個 broker 組成。一個broker 可以容納多個 topic。
- Topic:可以理解為一個隊列,生產者和消費者面向的都是一個 topic。
- Partition:為了實現擴展性,一個非常大的 topic 可以分布到多個 broker(即服務器)上,一個 topic 可以分為多個partition,每個 partition 是一個有序的隊列。
- Replica:副本。一個 topic 的每個分區都有若干個副本,一個 Leader 和若干個Follower。
- Leader:每個分區多個副本的“主”,生產者發送數據的對象,以及消費者消費數據的對象都是 Leader。
- Follower:每個分區多個副本中的“從”,實時從 Leader 中同步數據,保持和Leader 數據的同步。Leader 發生故障時,某個 Follower 會成為新的 Leader。
- zk中記錄誰是leader,kafka2.8之后也可以不配置zk。
Kafka的安裝部署
筆者是采用k8s的方式在云服務器上部署kafka的,具體的安裝步驟,大家可以參考這篇博客:https://blog.csdn.net/weixin_46619605/article/details/146170695,這里就不再敘述。
Kafka的命令行操作
主題命令行操作
-
查看操作主題命令參數
bin/kafka-topics.sh -
查看當前服務器中的所有topic
bin/kafka-topics.sh --bootstrap-server xx:xx --list
生產者命令行操作
- 查看操作生產者命令參數
bin/kafka-console-producer.sh
消費者命令行操作
-
查看操作消費者命令參數
bin/kafka-console-consumer.sh

生產者消息發送流程
- 發送原理
在消息發送的過程中,涉及到了兩個線程——main 線程和 Sender 線程。在 main 線程中創建了一個雙端隊列 RecordAccumulator。main 線程將消息發送給RecordAccumulator,Sender 線程不斷從 RecordAccumulator 中拉取消息發送到 Kafka Broker。
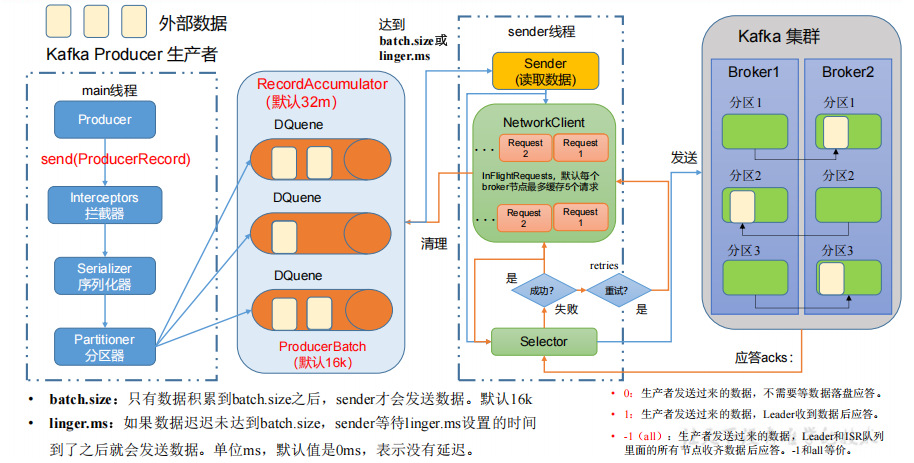
- 生產者分區
- 便于合理使用存儲資源,每個Partition在一個Broker上存儲,可以把海量的數據按照分區切割成一塊一塊數據存儲在多臺Broker上。合理控制分區的任務,可以實現負載均衡的效果。
- 提高并行度,生產者可以以分區為單位發送數據;消費者可以以分區為單位進行消費數據。
Kafka Broker總體工作流程
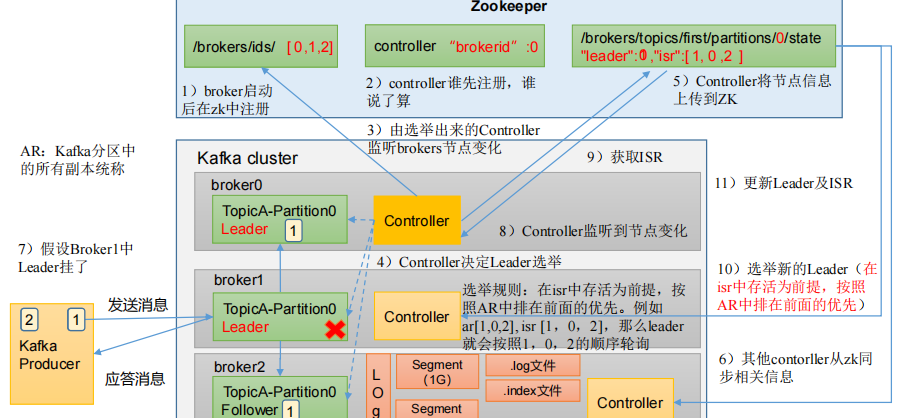
Kafka副本
- Kafka 副本作用:提高數據可靠性。
- Kafka 默認副本 1 個,生產環境一般配置為 2 個,保證數據可靠性;太多副本會增加磁盤存儲空間,增加網絡上數據傳輸,降低效率。
- Kafka 中副本分為:Leader 和 Follower。Kafka 生產者只會把數據發往 Leader,然后 Follower 找 Leader 進行同步數據。
- Kafka 分區中的所有副本統稱為 AR(Assigned Repllicas)。
AR = ISR + OSR
ISR,表示和 Leader 保持同步的 Follower 集合。如果 Follower 長時間未向 Leader 發送通信請求或同步數據,則該 Follower 將被踢出 ISR。該時間閾值由 replica.lag.time.max.ms參數設定,默認 30s。Leader 發生故障之后,就會從 ISR 中選舉新的 Leader。
OSR,表示 Follower 與 Leader 副本同步時,延遲過多的副本。

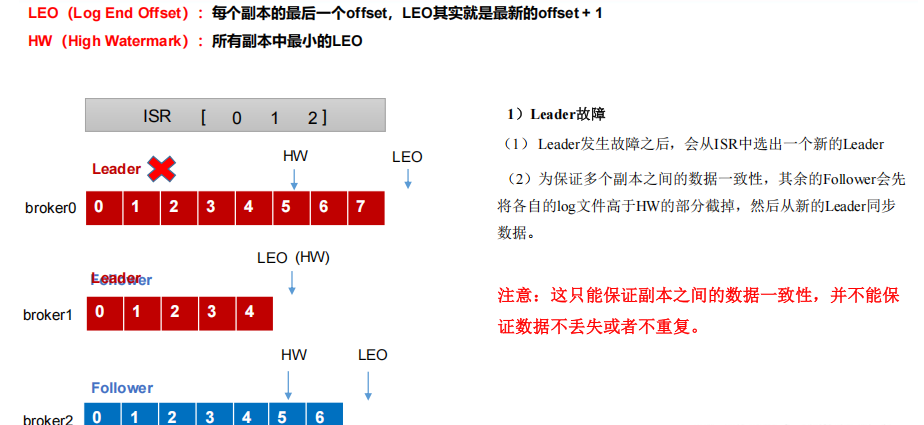
文件存儲機制
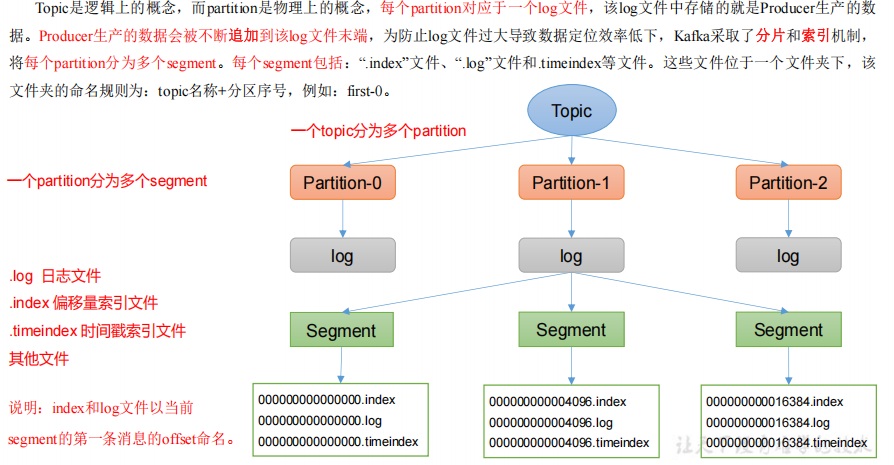
文件清理策略
Kafka 中默認的日志保存時間為 7 天,可以通過調整如下參數修改保存時間。
- log.retention.hours,最低優先級小時,默認 7 天。
- log.retention.minutes,分鐘。
- log.retention.ms,最高優先級毫秒。
- log.retention.check.interval.ms,負責設置檢查周期,默認 5 分鐘。
Kafka中提供的日志清理策略有delete和compact。
- delete日志刪除:將過期數據刪除
log.cleanup.policy = delete 所有數據啟用刪除策略- 基于時間:默認打開。以 segment 中所有記錄中的最大時間戳作為該文件時間戳。
- 基于大小:默認關閉。超過設置的所有日志總大小,刪除最早的 segment。
log.retention.bytes,默認等于-1,表示無窮大。
- compact日志壓縮:對于相同的key的不同value值,只保留最后一個版本。
高效讀寫數據
- Kafka 本身是分布式集群,可以采用分區技術,并行度高
- 讀數據采用稀疏索引,可以快速定位要消費的數據
- 順序寫磁盤
Kafka 的 producer 生產數據,要寫入到 log 文件中,寫的過程是一直追加到文件末端,為順序寫。官網有數據表明,同樣的磁盤,順序寫能到 600M/s,而隨機寫只有 100K/s。這與磁盤的機械機構有關,順序寫之所以快,是因為其省去了大量磁頭尋址的時間。 - 頁緩存+零拷貝技術
PageCache頁緩存:Kafka重度依賴底層操作系統提供的PageCache功 能。當上層有寫操作時,操作系統只是將數據寫入PageCache。當讀操作發生時,先從PageCache中查找,如果找不到,再去磁盤中讀取。實際上PageCache是把盡可能多的空閑內存都當做了磁盤緩存來使用。
零拷貝:Kafka的數據加工處理操作交由Kafka生產者和Kafka消費者處理。Kafka Broker應用層不關心存儲的數據,所以就不用走應用層,傳輸效率高。
Kafka消費方式
- pull模式:consumer采用從broker中主動拉取數據。kafka采用這種方式。不足之處,如果kafka沒有數據,消費者可能會陷入循環中,一直返回空數據。
- push模式:Kafka沒有采用這種方式,因為由broker決定消息發送速率,很難適應所有消費者的消費速率。
Kafka消費者工作流程
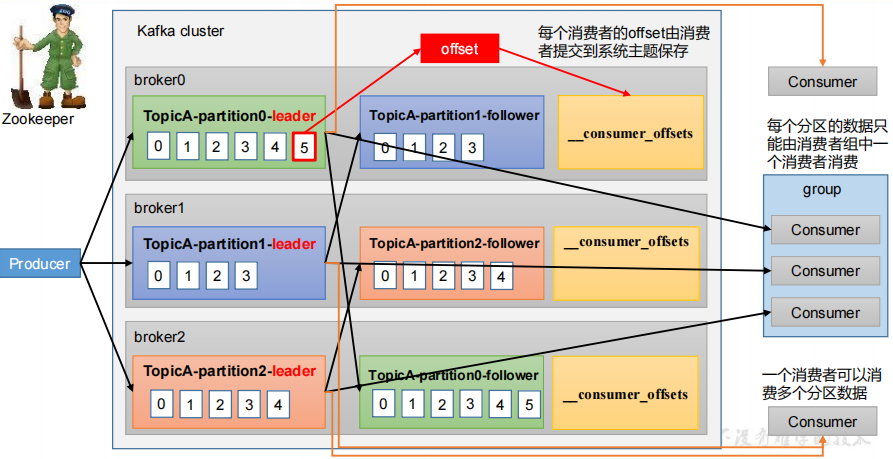
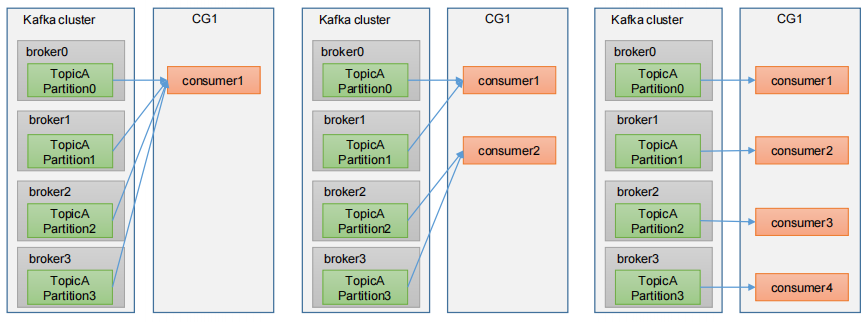
消費者組原理
Consumer Group(CG):消費者組,由多個consumer組成。形成一個消費者組的條件,是所有消費者的groupid相同。
- 消費者組內每個消費者負責消費不同分區的數據,一個分區只能由一個組內消費者消費。
- 消費者組之間互不影響。所有的消費者都屬于某個消費者組,即消費者組是邏輯上的一個訂閱者。
- 如果向消費組中添加更多的消費者,超過主題分區數量,則有一部分消費者就會閑置,不會接收任何消息。
消費者組初始化流程
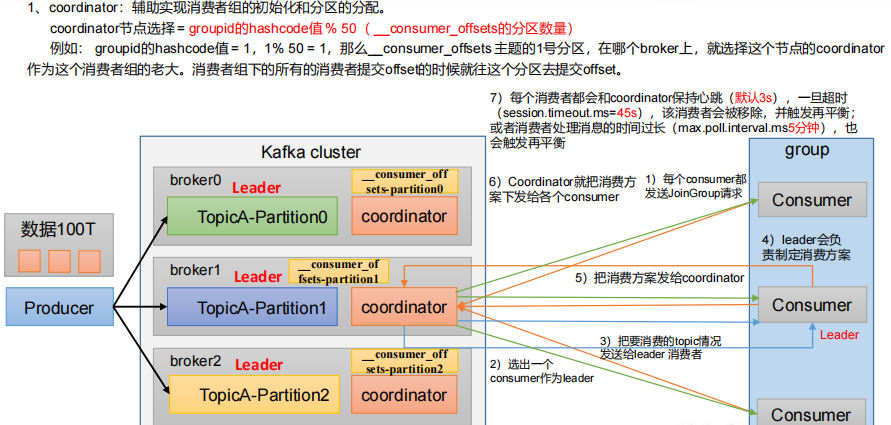
消費者詳細消費流程
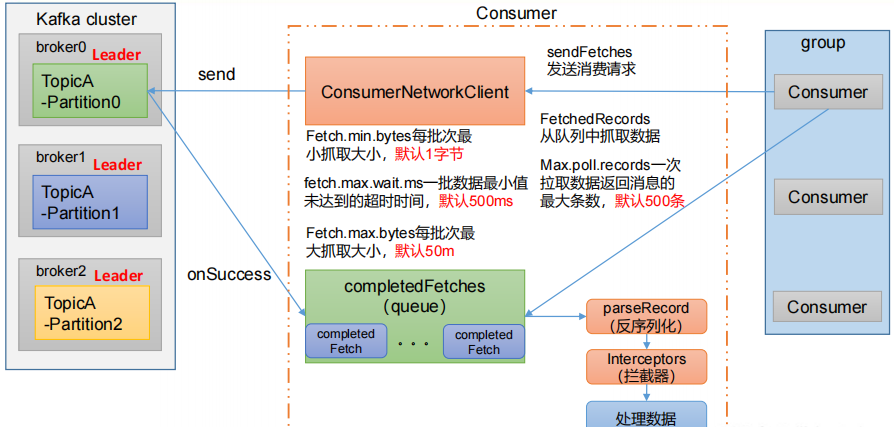
消費offset 位移
__consumer_offsets 主題里面采用 key 和 value 的方式存儲數據。key 是 group.id+topic+分區號,value 就是當前 offset 的值。每隔一段時間,kafka 內部會對這個 topic 進行compact,也就是每個 group.id+topic+分區號就保留最新數據。
-
為了使我們能夠專注于自己的業務邏輯,Kafka提供了自動提交offset的功能。
自動提交offset的相關參數:- enable.auto.commit:是否開啟自動提交offset功能,默認是true
- auto.commit.interval.ms:自動提交offset的時間間隔,默認是5s
-
雖然自動提交offset十分簡單便利,但由于其是基于時間提交的,開發人員難以把握offset提交的時機。因此Kafka還提供了手動提交offset的API。手動提交offset的方法有兩種:分別是commitSync(同步提交)和commitAsync(異步提交)。兩者的相同點是,都會將本次提交的一批數據最高的偏移量提交;不同點是,同步提交阻塞當前線程,一直到提交成功,并且會自動失敗重試(由不可控因素導致,也會出現提交失敗);而異步提交則沒有失敗重試機制,故有可能提交失敗。
- commitSync(同步提交):必須等待offset提交完畢,再去消費下一批數據。
- commitAsync(異步提交) :發送完提交offset請求后,就開始消費下一批數據了。
指定Offset消費
auto.offset.reset = earliest | latest | none 默認是 latest。
當 Kafka 中沒有初始偏移量(消費者組第一次消費)或服務器上不再存在當前偏移量時(例如該數據已被刪除),該怎么辦?
- earliest:自動將偏移量重置為最早的偏移量,–from-beginning。
- latest(默認值):自動將偏移量重置為最新偏移量。
- none:如果未找到消費者組的先前偏移量,則向消費者拋出異常。
- 任意指定 offset 位移開始消費。
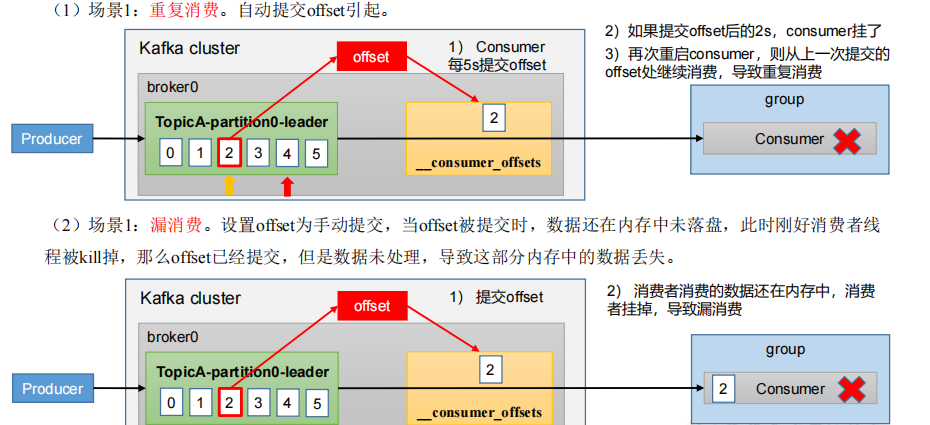
漏消費和重復消費
重復消費:已經消費了數據,但是 offset 沒提交。
漏消費:先提交 offset 后消費,有可能會造成數據的漏消費。
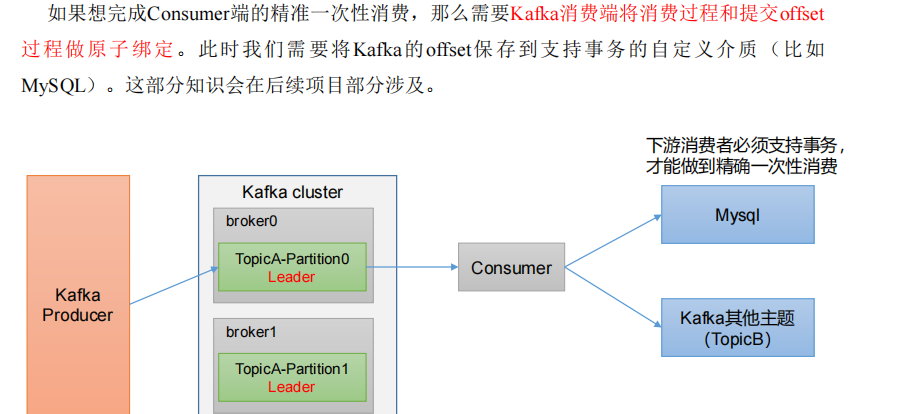
消費者事務
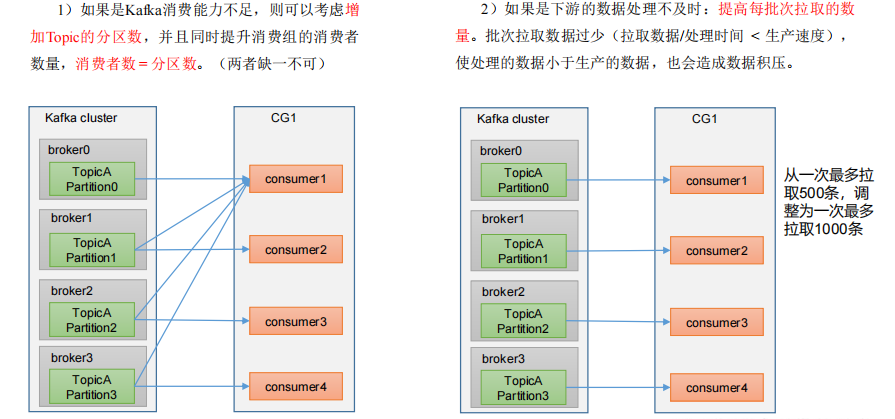
數據積壓(消費者如何提高吞吐量)
-記錄實戰教程及問題的解決方法)



)







![[C/C++學習] 7.“旋轉蛇“視覺圖形生成](http://pic.xiahunao.cn/[C/C++學習] 7.“旋轉蛇“視覺圖形生成)






