這篇論文主要講了兩方面
1.為了解決模型在正常標注的現實圖像上訓練的缺陷問題、提出了新的模型訓練數據和訓練方法
- 真實標記圖像存在缺點:標簽噪聲(深度傳感器可能存在空洞、玻璃等物體反射導致精度不準確)、標簽細節粗糙(深度圖邊緣不明確,導致預測可能會過渡平滑)、人工標注費時費力成本高
- 合成數據的優點:細節標記清晰、深度為真實值、且獲取方便快捷
- 合成數據的缺陷:與真實圖像之間存在分布差異,合成圖像場景覆蓋范圍有限,場景是單一的,是通過預定義形成的固定場景類型,畢竟最終要部署識別的是真實圖像,所以僅用合成數據不能在真實圖像上得到很好的效果。
針對以上優缺點,作者提出了一種結合了合成圖像和真實圖像的訓練方法,使得模型既能獲得清晰的細節和真實的深度,又能省去人工標注并完美覆蓋真實場景。其訓練流程如下圖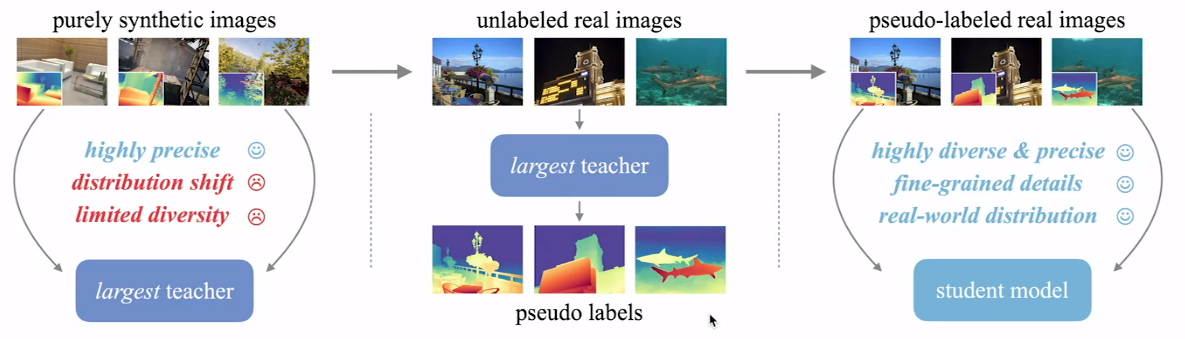
- 先完全使用生成圖像在最大的模型上進行訓練得到最大的教師模型,這個模型是高度精確的、但和真實世界圖像數據分布不一致、且圖像多樣性有限。
- 然后使用該模型識別未經標記的真實圖像,得到偽標記的真實圖像。
- 這些偽標記圖像作為數據集參與最終學生模型的訓練,得到最終高度多樣和精確、很好的粒度細節、真實的世界分布。
- 這樣訓練的學生模型能更好地處理真實世界的圖像數據,完成深度估計等視覺任務。
2.針對現有評估基準、提出了新的評判標準
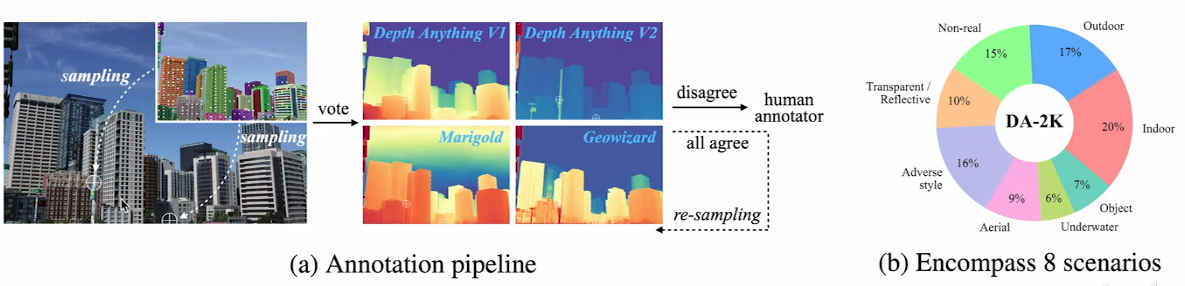
- 現有評估基準使用的圖像數據是存在大量噪聲的,如下圖左所示鏡子內部深度在評估時使用的標注數據錯誤而模型識別出的深度正確,右圖顯示有部分細節處存在噪聲和空洞,而模型則能很好識別這些細節。

- 新的評估標準中在目標圖像中取大量樣本點,在這些樣本點中取兩兩為一對,使用四個模型對這些點的相對遠近進行投票,如果四個模型所認為的遠近都一致則通過,否則交由人工判斷。
- 新的評估標準中的圖像多樣性也非常豐富,如右圖所示。



![[C/C++學習] 7.“旋轉蛇“視覺圖形生成](http://pic.xiahunao.cn/[C/C++學習] 7.“旋轉蛇“視覺圖形生成)












目錄)


