數據集包含2149名患者的廣泛健康信息,每名緩則的ID范圍從4751到6900不等,該數據集包含人口統計詳細信息,生活方式因素、病史、臨床測量、認知和功能評估、癥狀以及阿爾茲海默癥的診斷。
一、準備工作
1、硬件準備
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import torch
import torch.nn as nn
import torch.nn.functional as F# 設置GPU
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(device)
2、導入數據
df = pd.read_csv('./alzheimers_disease_data.csv')
# 刪除最后一列和第一列
df = df.iloc[:, 1:-1]
df.head()

二、構建數據集
1、標準化
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScalerX = df.iloc[:, :-1]
y = df.iloc[:, -1]# 將每一列特征標準化為標準正態分布,注意,標準化是針對每一列而言的
scaler = StandardScaler()
X = scaler.fit_transform(X)
2、劃分數據集
X = torch.tensor(np.array(X), dtype=torch.float32)
y = torch.tensor(np.array(y), dtype=torch.int64)X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.1, random_state=1)X_train.shape, y_train.shape
3、構建數據加載器
from torch.utils.data import TensorDataset, DataLoadertrain_dl = DataLoader(TensorDataset(X_train, y_train), batch_size=32, shuffle=False)
test_dl = DataLoader(TensorDataset(X_test, y_test), batch_size=32, shuffle=False)
三、模型訓練
1、構建模型
class model_rnn(nn.Module):def __init__(self):super(model_rnn, self).__init__()self.rnn0 = nn.RNN(input_size=32, hidden_size=200, num_layers=1, batch_first=True)self.fc0 = nn.Linear(200, 50)self.fc1 = nn.Linear(50, 2)def forward(self, x):out, hidden1 = self.rnn0(x)out = self.fc0(out)out = self.fc1(out)return outmodel = model_rnn().to(device)
model

2、定義訓練函數
# 訓練循環
def train(dataloader, model, loss_fn, optimizer):size = len(dataloader.dataset) # 訓練集的大小num_batches = len(dataloader) # 批次數目, (size/batch_size,向上取整)train_loss, train_acc = 0, 0 # 初始化訓練損失和正確率for X, y in dataloader: # 獲取圖片及其標簽X, y = X.to(device), y.to(device)# 計算預測誤差pred = model(X) # 網絡輸出loss = loss_fn(pred, y) # 計算網絡輸出和真實值之間的差距,targets為真實值,計算二者差值即為損失# 反向傳播optimizer.zero_grad() # grad屬性歸零loss.backward() # 反向傳播optimizer.step() # 每一步自動更新# 記錄acc與losstrain_acc += (pred.argmax(1) == y).type(torch.float).sum().item()train_loss += loss.item()train_acc /= sizetrain_loss /= num_batchesreturn train_acc, train_loss
3、測試函數
def test (dataloader, model, loss_fn):size = len(dataloader.dataset) # 測試集的大小num_batches = len(dataloader) # 批次數目, (size/batch_size,向上取整)test_loss, test_acc = 0, 0# 當不進行訓練時,停止梯度更新,節省計算內存消耗with torch.no_grad():for imgs, target in dataloader:imgs, target = imgs.to(device), target.to(device)# 計算losstarget_pred = model(imgs)loss = loss_fn(target_pred, target)test_loss += loss.item()test_acc += (target_pred.argmax(1) == target).type(torch.float).sum().item()test_acc /= sizetest_loss /= num_batchesreturn test_acc, test_loss
4、正式訓練
loss_fn = nn.CrossEntropyLoss() # 創建損失函數
learn_rate = 5e-5
opt = torch.optim.Adam(model.parameters(), lr= learn_rate)epochs = 50train_loss = []
train_acc = []
test_loss = []
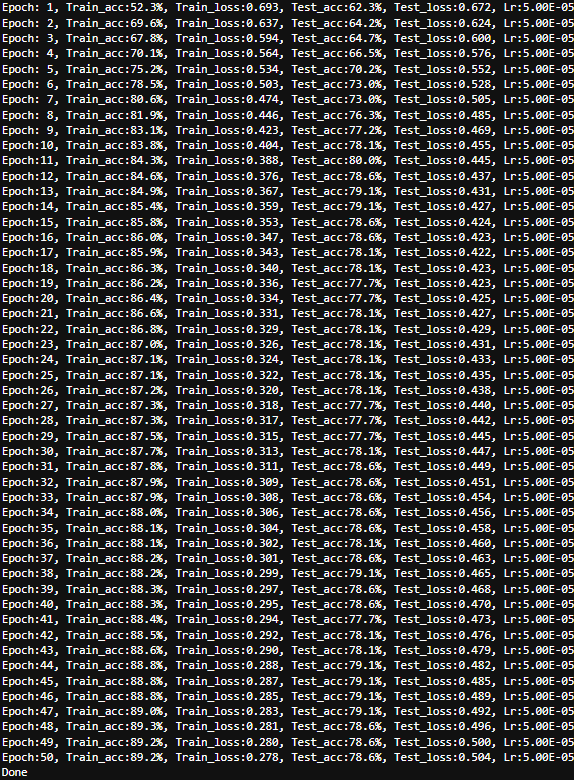
test_acc = []for epoch in range(epochs):model.train()epoch_train_acc, epoch_train_loss = train(train_dl, model, loss_fn, opt)model.eval()epoch_test_acc, epoch_test_loss = test(test_dl, model, loss_fn)train_acc.append(epoch_train_acc)train_loss.append(epoch_train_loss)test_acc.append(epoch_test_acc)test_loss.append(epoch_test_loss)# 獲取當前的學習率lr = opt.state_dict()['param_groups'][0]['lr']template = ('Epoch:{:2d}, Train_acc:{:.1f}%, Train_loss:{:.3f}, Test_acc:{:.1f}%, Test_loss:{:.3f}, Lr:{:.2E}')print(template.format(epoch+1, epoch_train_acc*100, epoch_train_loss,epoch_test_acc*100, epoch_test_loss, lr))print('Done')
四、模型評估
1.Loss與Accuracy圖
import matplotlib.pyplot as plt
#隱藏警告
import warnings
warnings.filterwarnings("ignore") #忽略警告信息
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用來正常顯示中文標簽
plt.rcParams['axes.unicode_minus'] = False # 用來正常顯示負號
plt.rcParams['figure.dpi'] = 100 #分辨率from datetime import datetime
current_time = datetime.now()epochs_range = range(epochs)plt.figure(figsize=(12, 3))
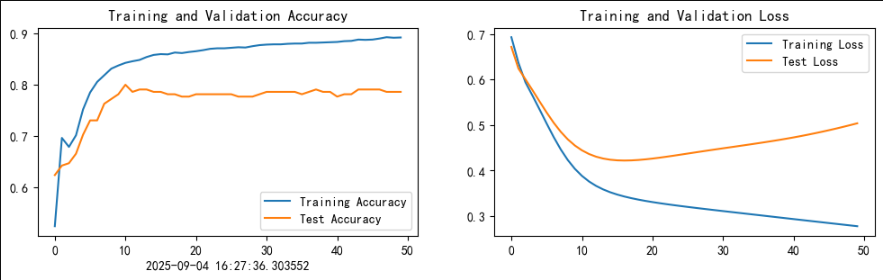
plt.subplot(1, 2, 1)plt.plot(epochs_range, train_acc, label='Training Accuracy')
plt.plot(epochs_range, test_acc, label='Test Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')
plt.xlabel(current_time)plt.subplot(1, 2, 2)
plt.plot(epochs_range, train_loss, label='Training Loss')
plt.plot(epochs_range, test_loss, label='Test Loss')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.show()
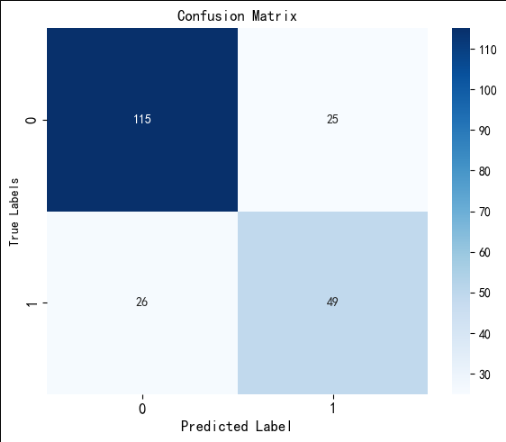
2、混沌矩陣
print("====================輸入數據Shape為====================")
print("X_test.shape: ",X_test.shape)
print("y_test.shape: ",y_test.shape)pred = model(X_test.to(device)).argmax(1).cpu().numpy()
print("====================輸出數據Shape為====================")
print("pred.shape: ",pred.shape)

import matplotlib.pyplot as plt
from sklearn.metrics import confusion_matrix, ConfusionMatrixDisplay# 計算混淆矩陣
cm = confusion_matrix(y_test, pred)plt.figure(figsize=(6,5))
# plt.suptitle('Confusion Matrix')
sns.heatmap(cm, annot=True, fmt='d', cmap='Blues')# 修改字體大小
plt.xticks(fontsize=12)
plt.yticks(fontsize=12)
plt.title('Confusion Matrix', fontsize=12)
plt.xlabel('Predicted Label', fontsize=12)
plt.ylabel('True Labels', fontsize=10)# 調整布局防止重疊
plt.tight_layout()# 顯示圖形
plt.show()
五、預測
六、總結
當然,在學習完RNN及其演進模型(如LSTM、GRU)后,對“如何處理序列數據”進行總結是非常有價值的。這能幫你建立起一個清晰的知識框架。
以下是一個系統性的總結,涵蓋了從核心思想、關鍵挑戰到解決方案和現代最佳實踐。
處理序列數據的核心思想與總結
- 核心目標:處理帶有“順序依賴”的數據
序列數據的根本特征是??數據點之間的順序關系蘊含重要信息??。例如,一句話中單詞的順序、一段音樂中音符的先后、股票價格隨時間的變化等。模型的目標是學習這種順序依賴關系,并做出預測、分類或生成。 - 基礎架構:循環神經網絡 (RNN)
RNN提供了處理序列數據的基本范式:
??核心機制??: ??循環連接??。網絡為每個時間步的輸入進行處理,并將一個“隱藏狀態(Hidden State)”傳遞給下一個時間步。這個隱藏狀態作為“記憶”,承載了之前所有時間步的摘要信息。
h_t = f(W * h_{t-1} + U * x_t + b)
??優勢??: 參數共享(所有時間步共用同一組參數),理論上可以處理任意長度的序列。
??典型結構??:
??一對一??: 單個輸入 -> 單個輸出(例如,圖像分類)
??一對多??: 單個輸入 -> 序列輸出(例如,圖像字幕生成)
??多對一??: 序列輸入 -> 單個輸出(例如,情感分析)
??多對多??: 序列輸入 -> 序列輸出(例如,機器翻譯、股票預測)
3. 核心挑戰與致命缺陷:梯度消失/爆炸
??問題??: 當序列很長時,RNN在反向傳播(BPTT)過程中,梯度需要連續乘以相同的權重矩陣,導致梯度呈指數級縮小(消失)或增大(爆炸)。
??后果??: ??模型無法學習長期依賴關系??。它變得“健忘”,只能記住近期信息,而難以利用序列早期的重要信息。這嚴重限制了基礎RNN在長序列任務上的應用。
4. 解決方案:門控機制 (Gating Mechanism)
為了解決長期依賴問題,引入了更為強大的循環單元,其核心思想是使用“門”來精確控制信息的流動。
??LSTM (長短期記憶網絡)??:
??核心??: 引入了??細胞狀態(Cell State)?? 作為“信息高速公路”和三個門(??輸入門、遺忘門、輸出門??)。
??工作方式??: 門(Sigmoid函數)決定讓多少信息通過(0~1)。遺忘門決定從細胞狀態中丟棄什么信息;輸入門決定添加什么新信息。這使得LSTM可以長期保存和傳遞關鍵信息。
??GRU (門控循環單元)??:
??核心??: LSTM的簡化版,將LSTM的三個門合并為兩個:??更新門??和??重置門??。
??特點??: 參數更少,訓練速度更快,但在大多數任務上的效果與LSTM相當。它成為了一個非常流行且高效的默認選擇。
??小結:RNN -> LSTM/GRU 的演進,是為了解決基礎RNN的“短期記憶”問題,其核心技術創新是“門控”。??
5. 更深與更廣:架構的擴展
??深度RNN??: 將多個RNN層堆疊起來,底層處理低級特征(如字符、音素),高層處理高級特征(如語義、意圖),以增強模型的表達能力。
??雙向RNN (Bi-RNN/Bi-LSTM/Bi-GRU)??: 同時運行兩個獨立的RNN,一個從序列開頭到結尾(正向),一個從結尾到開頭(反向),然后將它們的輸出合并。
??優勢??: 對于任何一個時間點,模型都擁有??完整的上下文信息??(過去和未來)。這在自然語言處理(如閱讀理解、命名實體識別)中極其重要。
現代范式:注意力機制與Transformer
盡管LSTM/GRU解決了長期依賴,但仍存在序列計算無法并行、信息壓縮丟失等問題。這催生了更革命的架構:
??注意力機制 (Attention Mechanism)??:
??核心思想??: 允許模型在生成輸出時,直接“關注”并加權輸入序列中的任何部分,而不是強制將所有信息壓縮到最后一個隱藏狀態。
??優勢??: 極大地改善了長序列性能,提供了更好的可解釋性(可以看到模型在關注哪里)。
??Transformer??:
??核心??: ??完全基于自注意力機制(Self-Attention)??,徹底拋棄了循環結構。
??優勢??:
1.??極高的并行化能力??: 訓練速度遠超RNN/LSTM。
2.??全局建模能力??: 一步計算即可捕捉序列中任意兩個元素之間的關系,無論距離多遠。
??影響??: Transformer及其衍生模型(如BERT, GPT)已成為當前NLP乃至跨模態領域(視覺、音頻)的絕對主流架構。
在學完循環神經網絡RNN后,同時學習完門控機制后,GRU的優勢(相對于RNN)??解決了核心缺陷??,極大緩解了梯度消失問題,具有強大的長序列建模能力。收斂更快??: 訓練過程更穩定,收斂速度通常更快。
??性能卓越??: 在絕大多數任務上的性能遠超傳統RNN。
??GRU的劣勢(相對于RNN):??
結構更復雜??,參數更多,計算量稍大。
??過擬合風險??稍高。那么,GRU和LSTM又如何選擇呢?(你可能會問的下一個問題)??
GRU通常被認為是LSTM的一個更輕量、更快的替代品。它們的性能在大多數任務上??非常接近??,沒有絕對的贏家。
??優先選擇GRU??:當計算資源受限、訓練速度是關鍵因素,或者數據集較小時,GRU是一個很好的選擇,因為它用更少的參數達到了與LSTM相似的性能。
??優先選擇LSTM??:在一些非常長和復雜的序列任務上(如語音識別、音樂生成),LSTM憑借其更精細的門控控制(三個獨立的門),可能擁有微弱的優勢,但這并非絕對。
??最佳實踐是:?? 在你的特定數據集上同時試驗GRU和LSTM,選擇表現更好的那個。
??GRU是對傳統RNN的一次重大升級??。它通過巧妙的門控設計,以可接受的計算成本為代價,成功解決了RNN的核心痛點,使其成為處理序列數據的強大而高效的模型。在學習上,從RNN到GRU/LSTM的演進,是理解如何通過設計更復雜的細胞結構來優化梯度流和信息保存的關鍵一步。


)







![[C/C++學習] 7.“旋轉蛇“視覺圖形生成](http://pic.xiahunao.cn/[C/C++學習] 7.“旋轉蛇“視覺圖形生成)








