鋒哥原創的Scikit-learn Python機器學習視頻教程:
2026版 Scikit-learn Python機器學習 視頻教程(無廢話版) 玩命更新中~_嗶哩嗶哩_bilibili
課程介紹

本課程主要講解基于Scikit-learn的Python機器學習知識,包括機器學習概述,特征工程(數據集,特征抽取,特征預處理,特征降維等),分類算法(K-臨近算法,樸素貝葉斯算法,決策樹等),回歸與聚類算法(線性回歸,欠擬合,邏輯回歸與二分類,K-means算法)等。
Scikit-learn Python機器學習 - 特征預處理 - 歸一化 (Normalization):MinMaxScaler
不同特征可能有不同的量綱和范圍(如身高、體重、年齡),歸一化使各特征在相同尺度上進行比較,避免某些特征因數值較大而主導模型。
我們將特征縮放至一個特定的范圍(默認是 [0, 1])。
歸一化(Normalization)公式,也稱為最小-最大歸一化(Min-Max Normalization)
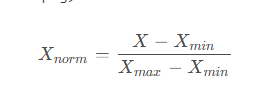
公式含義 這個公式將原始數據 X 從其原始范圍轉換到 [ 0,1] 的范圍內。
公式各部分解釋

工作原理

特點

應用場景 歸一化在機器學習和數據挖掘中非常常用,特別是:
-
特征縮放,使不同量綱的特征可比較
-
梯度下降算法中加速收斂
-
神經網絡中防止梯度消失或爆炸
-
圖像處理中的像素值標準化
在Scikit-learn中,使用MinMaxScaler進行歸一化操作。在初始化 MinMaxScaler 對象時,最重要的參數是:
-
feature_range: tuple(min, max), 默認=(0, 1)-
作用:指定你想要將數據縮放到的目標范圍。
-
示例:如果想縮放到 [-1, 1],則設置
feature_range=(-1, 1)。
-
我們看一個示例:
import numpy as np
import pandas as pd
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import MinMaxScaler
?
# 創建示例數據,包含不同類型的問題
data = {'age': [25, 30, np.nan, 45, 60, 30, 15], ?# 數值,含缺失值'salary': [50000, 54000, 60000, np.nan, 100000, 40000, 20000], ?# 數值,尺度大,含缺失值'country': ['USA', 'UK', 'China', 'USA', 'India', 'China', 'UK'], ?# 分類型'gender': ['M', 'F', 'F', 'M', 'M', 'F', 'F'] ?# 分類型
}
?
df = pd.DataFrame(data)
print("原始數據:")
print(df)
?
# 策略通常為 mean(均值), median(中位數), most_frequent(眾數), constant(固定值)
imputer = SimpleImputer(strategy='mean')
?
# 我們只對數值列進行填充
numeric_features = ['age', 'salary']
df_numeric = df[numeric_features]
?
# fit 計算用于填充的值(這里是均值),transform 應用填充
imputer.fit(df_numeric)
df[numeric_features] = imputer.transform(df_numeric)
?
print("\n處理缺失值后:")
print(df)
?
minmax_scaler = MinMaxScaler()
?
df_numeric = df[['age', 'salary']]
# 根據數據訓練生成模型
minmax_scaler.fit(df_numeric)
# 根據模型訓練數據
df_normalized = minmax_scaler.transform(df_numeric)
?
print("\n歸一化后的數值特征(范圍[0,1]):")
print(df_normalized)運行結果:
歸一化后的數值特征(范圍[0,1]):
[[0.22222222 0.375 ][0.33333333 0.425 ][0.42592593 0.5 ][0.66666667 0.425 ][1. 1. ][0.33333333 0.25 ][0. 0. ]]

:文法+單詞第8回3 復習 +考え方6)










)





)