Kaggle - LLM Science Exam
Science Exam Simple Approach w/ Model Hub | Kaggle
Platypus2-70B with Wikipedia RAG | Kaggle
5個選項只有一個選項正確,目標:回答一個選項序列(只有前三個有效)
輸出正確選項 (可以多輸出幾個選項 防止第一選項是錯的 要讓正確選擇盡量靠前)
以下為一個簡單版本的直接調用大模型,還有一個復雜版本的 RAG + 分布式運行 70B 超大模型
目錄
簡單實現版:?設置prompt 直接調用大模型(無訓練過程)
1. 數據集&模型導入
2.?組合構建選項問題的提示詞
3.?回答第一個問題例子
4.?post_process 模型輸出修正
5. 輸出+提交
一、RAG + 分片并行計算
1. RAG 理論概述
2. RAG 工作流程總結
3. SentenceTransformer 類? ?文本->向量
4.?RAG 檢索 整合上下文context幫助LLM
二、有限GPU內存下運行超大模型
1. 四大關鍵技術
2. 三階段流程
3.?模型權重分片存儲+符號鏈接虛擬文件系統
4.?權重加載器類 (WeightsLoader)
5.?分片LLAMA模型類 (ShardedLlama)?
6.?將原始數據 tokenizer 轉換為模型能理解的 標準化輸入
7.?模型運行函數
8. 將之前的函數和類 總流程運行
9. 訓練集 結果評估
簡單實現版:?設置prompt 直接調用大模型(無訓練過程)
Kaggle - LLM Science Exam-simple(直接調用大模型)
1. 數據集&模型導入
選的是 flan-t5 的小模型;適用于做小選擇題;
(有個弊端是 只會輸出一個選項 但根據題目要求 按正確概率從前到后輸出五個選項更好)
import pandas as pdimport warnings
warnings.simplefilter("ignore")import torch
from transformers import T5Tokenizer, T5ForConditionalGenerationllm = '/kaggle/input/flan-t5/pytorch/base/4'
model = T5ForConditionalGeneration.from_pretrained(llm)
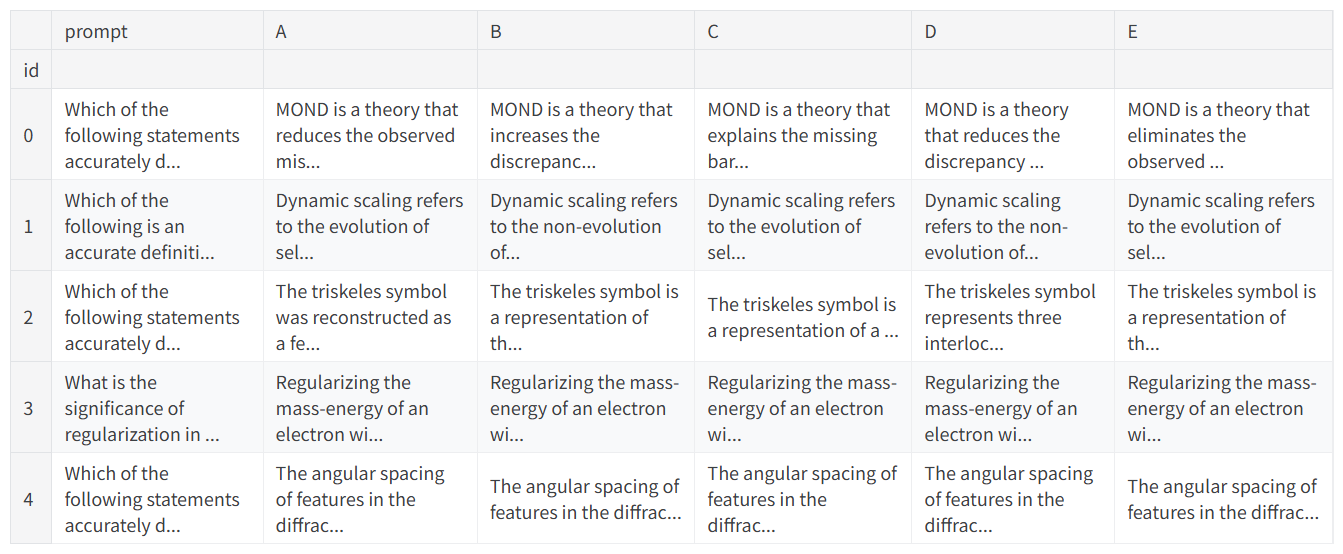
tokenizer = T5Tokenizer.from_pretrained(llm)test = pd.read_csv('/kaggle/input/kaggle-llm-science-exam/test.csv', index_col='id')
test.head()數據格式為 prompt 對應問題;還有五個選項; train 還包含正確答案 answer
2.?組合構建選項問題的提示詞
(可以將kaggle的題干發給deepseek 讓它生成一個比較準確的prompt )下例為
''' 你是一個善于回答科學選擇題的專家。請遵循以下步驟:
1. 仔細分析以下問題和所有選項。
2. 判斷每個選項作為答案的正確可能性。
3. 將五個選項字母(A、B、C、D、E)按可能性從高到低排序。
4. 最終只輸出排序后的字母序列,字母之間用單個空格分隔,不要輸出任何其他文字。
例如,如果你認為B最可能正確,其次是A,然后是D、C、E,你應該輸出:B A D C E
現在請回答以下問題:? '''
def format_input(df, idx):preamble = 'You are an expert skilled at answering scientific multiple-choice questions. Please follow these steps:/\nCarefully analyze the following question and all options./\nEvaluate the likelihood of each option being the correct answer./\nRank the five option letters (A, B, C, D, E) in order from most likely to least likely to be correct./\nFinally, output only the sequenced letters in order, separated by single spaces, without any additional text./\nFor example, if you believe option B is most likely correct, followed by A, then D, C, and E, you should output: B A D C E /\nNow please answer the following question:.'# 前面那段話 + 問題和五個選項prompt = df.loc[idx, 'prompt']a = df.loc[idx, 'A']b = df.loc[idx, 'B']c = df.loc[idx, 'C']d = df.loc[idx, 'D']e = df.loc[idx, 'E']input_text = f"{preamble}\n\n{prompt}\n\nA) {a}\nB) {b}\nC) {c}\nD) {d}\nE) {e}"return input_text3.?回答第一個問題例子
tokenizer input? ?->? ?generate output? ?->? ?decode answer
inputs = tokenizer(format_input(test, 0), return_tensors="pt")
outputs = model.generate(**inputs)
answer = tokenizer.batch_decode(outputs, skip_special_tokens=True)
print(answer)4.?post_process 模型輸出修正
湊滿五個選項;把少的字母拼在答案的后面
比如只輸出 D 就輸出 D ABCE
def post_process(predictions):valid = set(['A', 'B', 'C', 'D', 'E'])# 如果模型輸出中沒有任何有效字母if set(predictions).isdisjoint(valid):final_pred = 'A B C D E' # 返回默認答案else:final_pred = []for prediction in predictions:if prediction in valid: # 只保留有效字母final_pred += prediction# 添加缺失的字母to_add = valid - set(final_pred)final_pred.extend(list(to_add))# 格式化為空格分隔final_pred = ' '.join(final_pred)return final_pred5. 輸出+提交
submission = pd.read_csv('/kaggle/input/kaggle-llm-science-exam/sample_submission.csv', index_col='id')for idx in test.index:inputs = tokenizer(format_input(test, idx), return_tensors="pt")outputs = model.generate(**inputs)answer = tokenizer.batch_decode(outputs, skip_special_tokens=True)submission.loc[idx, 'prediction'] = post_process(answer)display(submission.head())
submission.to_csv('submission.csv')方案二 運用RAG + 分片并行加載70B超大模型?
Platypus2-70B with Wikipedia RAG | Kaggle
一、RAG + 分片并行計算
1. RAG 理論概述
Retrieval-Augmented Generation (RAG) 是一種結合信息檢索和文本生成的混合模型架構,主要包含兩個核心組件:
-
檢索器 (Retriever):從大規模知識庫中檢索與輸入相關的文檔或段落
-
生成器 (Generator):基于檢索到的上下文信息生成高質量的答案
RAG 的優勢在于:
-
能夠訪問外部知識,減少模型幻覺
-
不需要重新訓練整個模型即可更新知識
-
提供可追溯的信息來源
2. RAG 工作流程總結
-
查詢編碼:將問題+選項編碼為高維向量
-
向量檢索:在 FAISS 索引中查找相似文檔
-
上下文構建:整合檢索到的相關文檔
-
準備生成:為后續的 LLM 提供增強的上下文信息
3. SentenceTransformer 類? ?文本->向量
功能:將文本句子轉換為高維向量表示(嵌入向量)embeddings
整體工作流程
-
輸入:原始文本句子列表
-
預處理:添加檢索提示前綴 → 分詞 → 填充/截斷
-
編碼:通過預訓練模型獲取句子表示
-
后處理:L2歸一化 → 轉移到CPU → 轉換為numpy
-
輸出:形狀為?
[num_sentences, embedding_dim]?的嵌入矩陣
1. 初始化 device;checkpoint;model;tokenizer
class SentenceTransformer:def __init__(self, checkpoint, device="cuda:0"):self.device = device # 設置計算設備(GPU或CPU)self.checkpoint = checkpoint # 預訓練模型的路徑或名稱self.model = AutoModel.from_pretrained(checkpoint).to(self.device).half() # 加載模型并轉換為半精度self.tokenizer = AutoTokenizer.from_pretrained(checkpoint) # 加載對應的分詞器2. 分詞處理 transform? ??分詞 → 填充/截斷
def transform(self, batch):# 對批量文本進行分詞處理tokens = self.tokenizer(batch["text"], truncation=True, # 截斷超過最大長度的文本padding=True, # 填充較短序列以保證批次統一return_tensors="pt", # 返回PyTorch張量max_length=MAX_SEQ_LEN # 最大序列長度限制(512))return tokens.to(self.device) # 將張量移動到指定設備3.?創建數據加載器 get_dataloader? ? ?添加前綴 + 取batch_size 加載數據,用在batch循環中
def get_dataloader(self, sentences, batch_size=32):# 添加檢索專用的提示前綴sentences = ["Represent this sentence for searching relevant passages: " + x for x in sentences]# 創建Hugging Face數據集對象dataset = Dataset.from_dict({"text": sentences})# 設置實時轉換函數dataset.set_transform(self.transform)# 創建PyTorch數據加載器dataloader = DataLoader(dataset, batch_size=batch_size, # 控制每次處理的樣本數量shuffle=False # 不 shuffle,保持原始順序)return dataloader4. 編碼 encode? ? 循環batch的數據集 -> 模型輸出 -> L2歸一化 -> 嵌入矩陣
def encode(self, sentences, show_progress_bar=False, batch_size=32):# 創建數據加載器dataloader = self.get_dataloader(sentences, batch_size=batch_size)# 可選進度條顯示pbar = tqdm(dataloader) if show_progress_bar else dataloaderembeddings = [] # 存儲所有嵌入向量for batch in pbar: # 循環加載的數據集with torch.no_grad(): # 禁用梯度計算,節省內存# 前向傳播獲取模型輸出e = self.model(**batch).pooler_output# L2歸一化,使向量處于單位球面上e = F.normalize(e, p=2, dim=1)# 轉移到CPU并轉換為numpy數組embeddings.append(e.detach().cpu().numpy())# 合并所有批次的嵌入向量embeddings = np.concatenate(embeddings, axis=0)return embeddings4.?RAG 檢索 整合上下文context幫助LLM
-
將測試集中的問題編碼為向量
-
在FAISS向量數據庫中搜索最相關的Wikipedia 維基百科 經過預處理和解析的科學相關內容
-
提取并整合相關文檔作為上下文信息context 為后續的LLM生成階段提供知識支持
1.?將測試集中的問題編碼為向量
加載句子嵌入模型 SentenceTransformer;
構建查詢文本:將問題與所有選項拼接,形成更豐富的查詢 將測試集中的問題編碼為向量
# 加載句子嵌入模型(BGE-small-en-v1.5),用于將文本轉換為向量表示
model = SentenceTransformer(MODEL_PATH, device="cuda:0")# 構建查詢文本:將問題與所有選項拼接,形成更豐富的查詢 得到嵌入embedding
f = lambda row : " ".join([row["prompt"], row["A"], row["B"], row["C"], row["D"], row["E"]])
inputs = df.apply(f, axis=1).values
prompt_embeddings = model.encode(inputs, show_progress_bar=False)2. 在FAISS向量數據庫搜索
實現了大規模向量數據庫的高效相似度搜索
從海量知識庫中快速檢索最相關的文檔,為LLM提供準確的上下文信息
# 加載預構建的FAISS向量索引文件
MODEL_PATH = "/kaggle/input/bge-small-faiss/"
faiss_index = faiss.read_index(MODEL_PATH + '/faiss.index')NUM_TITLES=5 # 為每個查詢檢索最相關的5個文檔# 在FAISS索引中執行相似度搜索,查找與每個查詢最相關的文檔
# [1]返回第二個元素:search()返回(distances, indices)元組,只需要索引位置
search_index = faiss_index.search(np.float32(prompt_embeddings), NUM_TITLES)[1]3.?搜索最相關的Wikipedia文檔 拼接為context 上下文
# 加載預處理好的Wikipedia段落數據集 包含解析和擴展后的科學相關文本內容
dataset = load_from_disk("/kaggle/input/all-paraphs-parsed-expanded")# 遍歷測試集中的每個問題,構建對應的上下文
for i in range(len(df)):df.loc[i, "context"] = "-" + "\n-".join([dataset[int(j)]["text"] for j in search_index[i]])# 內存清理
faiss_index.reset() # 重置FAISS索引,釋放內部資源
del faiss_index, prompt_embeddings, model, dataset # 刪除對象引用,加速垃圾回收
clean_memory() # 執行深度內存清理:垃圾回收、C層內存整理、GPU緩存清空二、有限GPU內存下運行超大模型
在單個T4 GPU(16GB內存)上運行Platypus2-70B模型(約140GB),面臨內存容量嚴重不足的問題。傳統方法需要將整個模型加載到GPU內存,但這里采用了創新的分層加載和流水線處理方案。
1. 四大關鍵技術
1.?模型分片存儲與動態加載
-
分片存儲:將70B模型拆分為多個部分存儲在磁盤上
-
按需加載:只在需要時才將特定層加載到GPU內存
-
符號鏈接:創建虛擬文件系統,讓程序以為模型是完整的
2.?分層處理流水線
-
逐層處理:不是一次性加載整個模型,而是按層順序處理
-
內存復用:處理完一層后立即釋放該層內存,加載下一層
-
CPU-GPU協作:在CPU內存中預加載下一層權重,減少等待時間
3.?多GPU并行計算
-
數據并行:將測試數據分割到多個GPU上同時處理
-
權重共享:多個GPU共享同一套模型權重,避免重復存儲
-
線程安全:使用同步機制確保權重加載的協調性
4.?內存優化策略
-
半精度計算:使用float16而非float32,減少50%內存占用
-
注意力優化:使用Flash Attention減少內存使用
-
緩存管理:及時清理GPU和CPU內存碎片
2. 三階段流程
準備階段
-
建立虛擬模型文件系統
-
初始化空模型結構(不占用實質內存)
-
準備多GPU協調機制
推理階段(逐樣本逐層處理)
-
輸入處理:將問題+選項+上下文轉換為token序列
-
分層計算:每層依次 加載權重到GPU +?計算輸出 +?釋放內存
-
結果收集:逐層傳遞中間結果,最終得到預測分數
后處理階段
-
對每個選項計算置信度分數
-
排序得到Top-3預測
-
生成提交格式
3.?模型權重分片存儲+符號鏈接虛擬文件系統
-
分片存儲:模型權重被預先分割存儲在多個文件中
-
虛擬整合:通過符號鏈接創建統一的文件系統視圖
權重分別在這三個文件
# 創建符號鏈接虛擬文件系統checkpoint_path = Path("/root/.cache/")
checkpoint_path.mkdir(exist_ok=True, parents=True)for part in [1, 2, 3]:source_dir = Path(f'/kaggle/input/platypus2-chuhac2-part{part}')for path in source_dir.glob("*"):(checkpoint_path / path.name).symlink_to(path)4.?權重加載器類 (WeightsLoader)
每次有一部分GPU需要申請參數,給這些GPU分發參數。?
要求:所有設備都請求同一層
class WeightsLoader:def __init__(self, checkpoint_path, devices):self.checkpoint_path = Path(checkpoint_path)self.states = {device: None for device in devices} # 設備狀態跟蹤self.state_dict = None # 當前加載的權重字典self.condition = Condition() # 線程同步條件變量def get_state_dict(self, device):# 等待權重加載完成,然后獲取權重字典with self.condition:while self.states[device] is not None: # 等待當前加載完成self.condition.wait()result = self.state_dictself.states[device] = Noneif not any(self.states.values()): # 所有設備都獲取完畢self.condition.notify_all()return resultdef set_state_dict(self, layer_name, device):# 請求加載指定層的權重with self.condition:self.states[device] = layer_name # 標記設備需要該層if all(self.states.values()): # 所有設備都請求同一層assert len(set(self.states.values())) == 1 # 確保請求一致# 實際加載權重到CPU內存self.state_dict = load_file(self.checkpoint_path / (layer_name + ".safetensors"), device="cpu")for d in self.states: # 重置所有設備狀態self.states[d] = Noneself.condition.notify_all() # 通知所有等待線程5.?分片LLAMA模型類 (ShardedLlama)?
實現:分層初始化機制 + 分層加載與執行
1. 架構設計? 參數 + 層的順序
class ShardedLlama:def __init__(self, checkpoint_path, weights_loader, device="cuda:0", dtype=torch.float16):self.checkpoint_path = Path(checkpoint_path)self.weights_loader = weights_loader # 權重加載器實例self.device = deviceself.dtype = dtype # 半精度節省內存# 初始化空模型結構(幾乎不占內存)self.config = AutoConfig.from_pretrained(self.checkpoint_path)self.tokenizer = AutoTokenizer.from_pretrained(checkpoint_path)self.init_model() # 創建模型框架# 定義層處理順序self.layer_names = ["model.embed_tokens"] + [f"model.layers.{i}" for i in range(len(self.model.model.layers))] + ["model.norm", "value_head"]2.?分層初始化機制
def init_model(self):# 使用空權重初始化模型結構with init_empty_weights(): # 關鍵:不分配實際內存self.model = AutoModelForCausalLM.from_config(self.config)self.model.lm_head = torch.nn.Linear(8192, 8, bias=False)self.model.eval()self.model = BetterTransformer.transform(self.model) # 啟用Flash Attentionself.model.tie_weights()# 提取層引用以便逐層處理self.layers = [self.model.model.embed_tokens] + list(self.model.model.layers) + [self.model.model.norm, self.model.lm_head]# 只將緩沖區移到設備(占用內存很少)for buffer_name, buffer in self.model.named_buffers():set_module_tensor_to_device(self.model, buffer_name, self.device, value=buffer, dtype=self.dtype)3.?分層加載與執行
使用線程池實現加載與計算重疊;
預加載下一層 獲取權重 + 計算結果(選項順序)+ 釋放空間
def __call__(self, inputs):# 每次調用前清理內存并重新初始化del self.modelclean_memory()self.init_model()# 準備輸入數據batch = [(prefix.to(self.device), suffix.to(self.device)) for prefix, suffix in inputs]# 使用線程池實現加載與計算重疊with ThreadPoolExecutor() as executor, torch.inference_mode():# 預加載第一層future = executor.submit(self.load_layer_to_cpu, "model.embed_tokens")# 逐層處理流水線for i, (layer_name, layer) in enumerate(zip(self.layer_names, self.layers)):# 獲取當前層權重,并預加載下一層state_dict = future.result()if (i + 1) < len(self.layer_names):future = executor.submit(self.load_layer_to_cpu, self.layer_names[i + 1])# 將權重轉移到GPUself.move_layer_to_device(state_dict)# 執行當前層計算for j, (prefix, suffix) in enumerate(batch):if layer_name == "model.embed_tokens":batch[j] = (layer(prefix), layer(suffix)) # 嵌入層elif layer_name == "model.norm":batch[j] = (None, layer(suffix[torch.arange(n_suffixes), suffix_eos[j]][:, None])) # 歸一化elif layer_name == "value_head":batch[j] = layer(suffix)[:, 0].mean(1).detach().cpu().numpy() # 輸出層else:# Transformer層:使用KV緩存優化len_p, len_s = prefix.shape[1], suffix.shape[1]new_prefix, (k_cache, v_cache) = layer(prefix, use_cache=True, attention_mask=attention_mask[:, :, -len_p:, -len_p:])# 使用緩存計算suffixpos = position_ids[:, len_p:len_p + len_s].expand(n_suffixes, -1)attn = attention_mask[:, :, -len_s:, -len_p - len_s:].expand(n_suffixes, -1, -1, -1)kv_cache = (k_cache.expand(n_suffixes, -1, -1, -1), v_cache.expand(n_suffixes, -1, -1, -1))new_suffix = layer(suffix, past_key_value=kv_cache, position_ids=pos, attention_mask=attn)[0]batch[j] = (new_prefix, new_suffix)# 釋放當前層內存layer.to("meta") # 移回元設備(釋放GPU內存)clean_memory() # 強制垃圾回收6.?將原始數據 tokenizer 轉換為模型能理解的 標準化輸入
系統提示詞 + instruction + 選項 + 問題文本 + 拼接context上下文
def get_tokens(row, tokenizer): # 系統提示詞模板,定義任務格式system_prefix = "Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.\n\n### Instruction:\n{instruction}\n\n### Input:\nContext:\n{context}"# 具體任務指令,明確模型職責instruction = "Your task is to analyze the question and answer below. If the answer is correct, respond yes, if it is not correct respond no. As a potential aid to your answer, background context from Wikipedia articles is at your disposal, even if they might not always be relevant."# 處理五個選項,生成對應的suffix輸入prompt_suffix = [f"{row[letter]}\n\n### Response:\n" for letter in "ABCDE"]suffix = tokenizer(prompt_suffix, return_tensors="pt", return_attention_mask=False, truncation=True, max_length=MAX_LENGTH, padding=True)["input_ids"][:, 1:]# 處理問題文本部分prompt_question = f"\nQuestion: {row['prompt']}\nProposed answer: "question = tokenizer(prompt_question, return_tensors="pt", return_attention_mask=False, truncation=True, max_length=max(0, MAX_LENGTH - suffix.shape[1]))["input_ids"][:, 1:]# 處理上下文信息,整合Wikipedia檢索結果prompt_context = system_prefix.format(instruction=instruction, context=row["context"])max_length = min(MAX_CONTEXT, max(0, MAX_LENGTH - question.shape[1] - suffix.shape[1]))context = tokenizer(prompt_context, return_tensors="pt", return_attention_mask=False, truncation=True, max_length=max_length)["input_ids"]# 組合前綴部分(上下文+問題)prefix = torch.cat([context, question], dim=1)return prefix, suffix7.?模型運行函數
ShardedLlama + input分批次 + 推理得到output
def run_model(device, df, weights_loader):# 初始化分片模型實例model = ShardedLlama(checkpoint_path, weights_loader, device=device)# 創建數據處理函數(部分應用tokenizer)f = partial(get_tokens, tokenizer=model.tokenizer)# 為DataFrame的每一行生成模型輸入inputs = df.apply(f, axis=1).values# 將輸入數據分割成多個批次batches = np.array_split(inputs, N_BATCHES)outputs = []# 逐批次執行模型推理for i, batch in enumerate(batches):outputs += model(batch) # 調用模型前向傳播return outputs # 返回所有推理結果8. 將之前的函數和類 總流程運行
weights_loader權重加載器 + run_model 跑模型
output 為每個選項的概率;按照概率倒序 前三名
# 僅在測試集模式下執行完整推理流程
if IS_TEST_SET:# 檢測所有可用的CUDA設備devices = [f"cuda:{i}" for i in range(torch.cuda.device_count())]# 創建權重加載器實例,用于多設備權重協調weights_loader = WeightsLoader(checkpoint_path, devices)# 創建部分應用函數,固定權重加載器參數f = partial(run_model, weights_loader=weights_loader)# 使用線程池執行器進行并行計算with ThreadPoolExecutor() as executor:# 將數據分割并映射到各個設備執行outputs = list(executor.map(f, devices, np.array_split(df, 2)))outputs = sum(outputs, []) # 扁平化結果列表# 處理模型輸出,生成最終預測n = len(df)for i, scores in enumerate(outputs):# 按得分降序排序,獲取Top-3選項索引top3 = np.argsort(scores)[::-1]# 將索引轉換為選項字母df.loc[i, "prediction"] = " ".join(["ABCDE"[j] for j in top3])# 訓練集模式下的性能評估if "answer" in df.columns:# 詳細準確率計算 在下一部分中
else:# 非測試集模式生成默認預測df["prediction"] = "A B C"# 保存最終預測結果到提交文件
df[["prediction"]].to_csv("submission.csv")9. 訓練集 結果評估
對于訓練集 拿出 prediction的Top3;看百分之多少的問題 answer出現在預測的第 1,2,3 位置
# 僅在訓練集模式下執行評估(有標準答案)
if "answer" in df.columns:# 提取每個樣本的Top-1, Top-2, Top-3預測for i in range(n):df.loc[i, "top_1"] = df.loc[i, "prediction"][0] # Top-1預測(第一個字符)df.loc[i, "top_2"] = df.loc[i, "prediction"][2] # Top-2預測(第三個字符,跳過空格)df.loc[i, "top_3"] = df.loc[i, "prediction"][4] # Top-3預測(第五個字符,跳過空格)# 計算各Top級別的正確樣本數top_i = [(df[f"top_{i}"] == df["answer"]).sum() for i in [1, 2, 3]]# 輸出詳細性能報告print(f"top1 : {top_i[0]}/{n}, top2 : {top_i[1]}/{n}, top3 : {top_i[2]}/{n} (total={sum(top_i)} / {n})")print(f"Accuracy: {100*top_i[0]/n:.1f}%, map3: {100*(top_i[0] + top_i[1]*1/2 + top_i[2]*1/3).sum()/n:.1f}%")
)





)

)









