一、問題定位
1、慢查詢日志
-- 查看當前設置 SHOW VARIABLES LIKE 'slow_query%'; ? -- 開啟慢查詢日志(my.cnf永久配置) [mysqld] slow_query_log = 1 slow_query_log_file = /var/log/mysql/slow.log long_query_time = 1 ?-- 超過1秒的查詢 log_queries_not_using_indexes = 1 -- 記錄未使用索引的查詢 ? -- 動態設置 SET GLOBAL slow_query_log = 'ON'; SET GLOBAL long_query_time = 1;
2、分析工具
| 工具 | 使用場景 | 命令示例 |
|---|---|---|
| mysqldumpslow | 官方自帶,基礎分析 | mysqldumpslow -s t -t 10 -g 'select' /path/to/slow.log |
| pt-query-digest | 高級分析,生成詳細報告 | pt-query-digest slow.log > report.txt |
| Percona Toolkit | 專業級分析,支持多維度統計 | pt-query-digest --filter '$event->{arg} =~ m/SELECT/i' slow.log |
二、優化方案
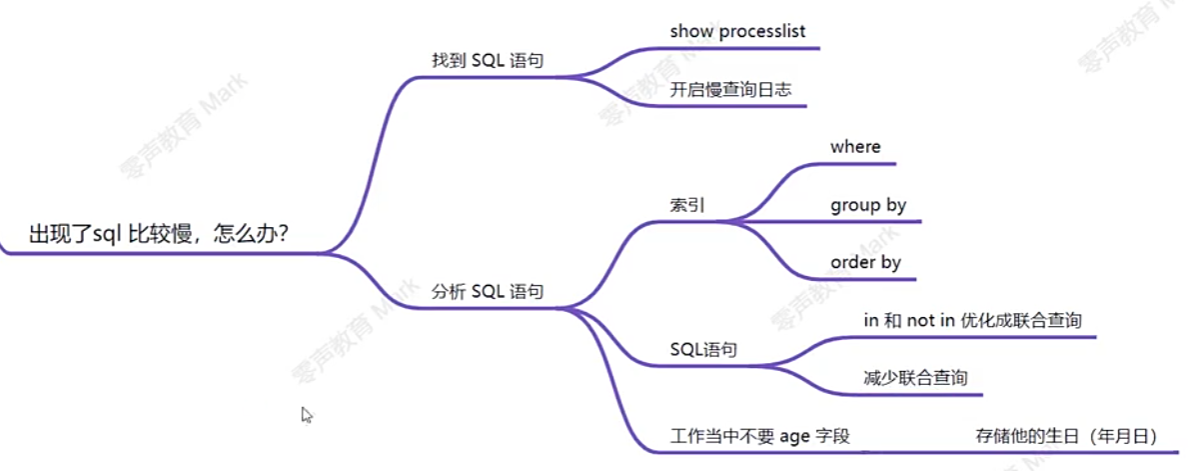
對于慢查詢SQL的優化方式中,首先需要定位慢查詢SQL到底是為什么那么慢。EXPLAIN命令可以查看慢查詢SQL的執行計劃。
1、索引優化
針對慢查詢SQL,一大部分SQL慢查詢的原因是沒有命中索引或者索引設計不合理或者SQL語句不合理導致全盤掃描或者索引失效。
對于索引使用盡量遵守以下原則以提高索引使用效率。
-
查詢頻次較高且數據量大的表建立索引;索引選擇使用頻次較高,過濾效果好的列或者組合;
-
使用短索引;節點包含的信息多,較少磁盤 IO 操作;比如: smallint , tinyint ;
-
對于很長的動態字符串,考慮使用前綴索引;
-
對于組合索引,考慮最左側匹配原則、覆蓋索引;
-
盡量選擇區分度高的列作為索引;該列的值相同的越少越好;
-
盡量擴展索引,在現有索引的基礎上,添加復合索引;最多 6 個索引;
-
不要 select *; 盡量只列出需要的列字段;方便使用覆蓋索引;
-
索引列,列盡量設置為非空;
對于索引的使用盡量滿足上述各項原則。除上述規則外還要注意一些情況是否造成索引失效導致全盤掃描。
索引失效的情況:
-
select ... where A and B 若 A 和 B 中有一個不包含索引,則索引失效;
-
索引字段參與運算,則索引失效;例如: from_unixtime(idx) = '2021-04-30'; 改成 idx = unix_timestamp("2021-04-30");
-
索引字段發生隱式轉換,則索引失效;例如:將列隱式轉換為某個類型,實際等價于在索引列上作用了隱式轉換函數;
-
LIKE 模糊查詢,通配符 % 開頭,則索引失效;
-
組合索引中,沒使用第一列索引,索引失效;
-
在索引字段上使用NOT <> != 索引失效;例如:id <> 0可以修改為 id > 0 or id < 0;
2、SQL語句子查詢優化
????????對于SQL語句盡量不要使用子查詢,對應優化方式可以將in 和 not in 優化為聯合查詢。并且在沒有必要使用聯合查詢時就盡量不用。可以通過進行單表查詢后返回數據在程序中進行join、merge操作數據。
?更多資料:0voice · GitHub







)





)





)