編譯器
- gcc編譯器
- 編譯器自舉
- 動靜態庫
- 動靜態庫的差異
gcc編譯器
眾所周知,代碼運行的前提是經過四個步驟的
- 預處理,其進行宏替換,去注釋,條件編譯,頭文件展開的工作,在gcc的選項中對應gcc -E,其就會生成預處理后的代碼,正常的后綴為i,雖然Linux并不以后綴為識別文件的標準,但存在后綴會更好一些。
- 編譯,生成匯編代碼,對應gcc -S,后綴為s
- 匯編,生成機器可識別代碼,對應gcc -c,后綴為o,雖然在匯編之后代碼已經成為了二進制代碼,但是仍然無法運行,因為沒有進行連接,即使只有一個源文件也是需要連接的,
- 連接,生成可執行文件或庫文件,對應gcc,即不帶選項就會直接生成可執行代碼。
編譯器自舉
眾所周知后,計算機語言發展歷史為
首先計算機是二進制的原因是二進制足夠的簡單,歷史上出現過三進制的計算機,但也被拋進了歷史的垃圾堆。
而CPU為什么能夠執行二進制,編寫的二進制代碼其實是一個指令集,而CPU是能夠識別并執行這些指令集的,每一個二進制序列都是一個命令,CPU的解碼單元就是為此而生的。
那么為什么會出現后續的匯編語言再到C語言呢?
原因就是人們很難去理解二進制,所以會出現匯編語言,使得一些指令被翻譯成人類可以識別的語言,比如0111(加法),在匯編中變為了add,0101(移動),在匯編中變為了mov,這樣相比于人們難以理解的二進制代碼變為了一個個文字,使得計算機更加的能貼近人們的生活,也讓程序員能夠更加便捷的去編寫代碼,同樣C語言的誕生也是如此。
但匯編語言在其被發明的時候,計算機為什么能夠執行匯編代碼?難道在匯編語言被發明的時候就出現了匯編的編譯器嗎?并不是,而是在出現匯編語言的時候,先使用二進制去寫一份匯編語言的編譯器,之后在此基礎上,在用匯編語言來寫一份自己的編譯器,此為編譯器自舉。
動靜態庫
在上述我們已經了解到在經過匯編后的二進制代碼是無法被執行的,但為什么二進制代碼無法被執行呢?因為編寫的代碼會套用很多庫文件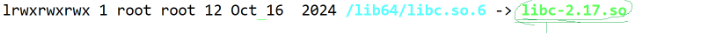
比如圖示中的libc-2.17.so就是C標準庫,如果沒有進行連接將庫與二進制代碼連接起來,那么源代碼中關于庫的相關代碼就無法運行。

像代碼在連接過程去自己尋找標準庫連接的就是動態庫,如果我們將標準庫復制到源代碼中,此時不在經過連接就可以直接運行,這種就是靜態庫,但與此同時,可執行程序的體積將會擴大。當然靜態庫并不是直接將庫給拷貝到源文件中,而是在編譯時選擇 -static選項,是強制要求編譯器采用靜態連接的方式進行編譯。
動靜態庫的差異
如上述所說,采用動靜態庫的第一個差異就是可執行文件的體積差異,但如果庫丟失或損壞,那么經過動態連接的程序是無法執行的,但如果是靜態連接,是不受影響的,當然編譯器默認都是采用動態連接動態庫的,這種更高效一些。












![【題解 | 兩種做法】洛谷 P4208 [JSOI2008] 最小生成樹計數 [矩陣樹/枚舉]](http://pic.xiahunao.cn/【題解 | 兩種做法】洛谷 P4208 [JSOI2008] 最小生成樹計數 [矩陣樹/枚舉])






