- 作者:Daojie Peng1^{1}1, Jiahang Cao1,2^{1,2}1,2, Qiang Zhang1,2^{1,2}1,2, Jun Ma1,3^{1,3}1,3
- 單位:1^{1}1香港科技大學(廣州),2^{2}2北京人形機器人創新中心,3^{3}3香港科技大學
- 論文標題:LOVON: Legged Open-Vocabulary Object Navigator
- 論文鏈接:https://arxiv.org/pdf/2507.06747
- 項目主頁:https://daojiepeng.github.io/LOVON/
- 代碼鏈接:https://github.com/DaojiePENG/LOVON
主要貢獻

- 提出統一框架LOVON,整合了LLMs、開放詞匯視覺檢測和L2MM,用于規劃和執行復雜的開放世界長時域導航任務。
- 開發了基于拉普拉斯方差的運動模糊過濾方法,解決了動態模糊問題,提高了系統的魯棒性。同時,引入了機器人執行邏輯,確保對各種環境的適應性。
- 通過仿真和多種足式機器人平臺(Unitree Go2、B2和H1-2)的實驗驗證了系統的有效性,結果表明LOVON能夠在非結構化環境中成功執行開放詞匯對象搜索和導航任務。
研究背景
- 近年來,LLMs在自然語言理解、推理和任務分解方面取得了顯著進展,被廣泛應用于機器人領域的高級任務規劃。
- 開放詞匯視覺感知技術也取得了突破性進展,使機器人能夠識別和理解超出預定義類別的多樣化對象。
- 足式機器人因其出色的地形適應能力,在復雜環境中展現出巨大潛力。然而,大多數研究集中在單一任務上,如行走、跳躍、攀爬和短距離導航,缺乏對復雜長時域任務的全面考慮。
問題表述
- 任務描述:機器人需要在任意開放世界環境中執行長時域任務,搜索不同目標。長時域任務 TlT_lTl? 被定義為一系列子任務的集合 Tl={Ti∣T1,T2,…?}T_l = \{T_i|T_1, T_2, \dots\}Tl?={Ti?∣T1?,T2?,…},每個子任務對應搜索特定目標 OiO_iOi?。任務描述是靈活的,允許不同的任務目標。
- 核心挑戰:機器人需要自主地搜索和識別不同的子目標(目標),根據任務指令以不同速度導航至這些目標。這些子目標在任務過程中可能會發生變化,要求機器人能夠動態適應。
- 目標:開發一個雙系統模型:
- 高級策略:能夠將復雜的任務指令 TlT_lTl? 分解為具體的子任務指令 Iins={Ii∣I1,I2,…?}I_{ins} = \{I_i|I_1, I_2, \dots\}Iins?={Ii?∣I1?,I2?,…} 并執行任務規劃。
- 低級策略:基于具體的子任務指令 IiI_iIi? 和視頻流輸入 IRGBI_{RGB}IRGB?,生成運動向量 Vm∈R3V_m \in \mathbb{R}^3Vm?∈R3 以實現精確的運動控制。該模型應能夠適應各種足式機器人,確保在實際應用中的多功能性。
方法
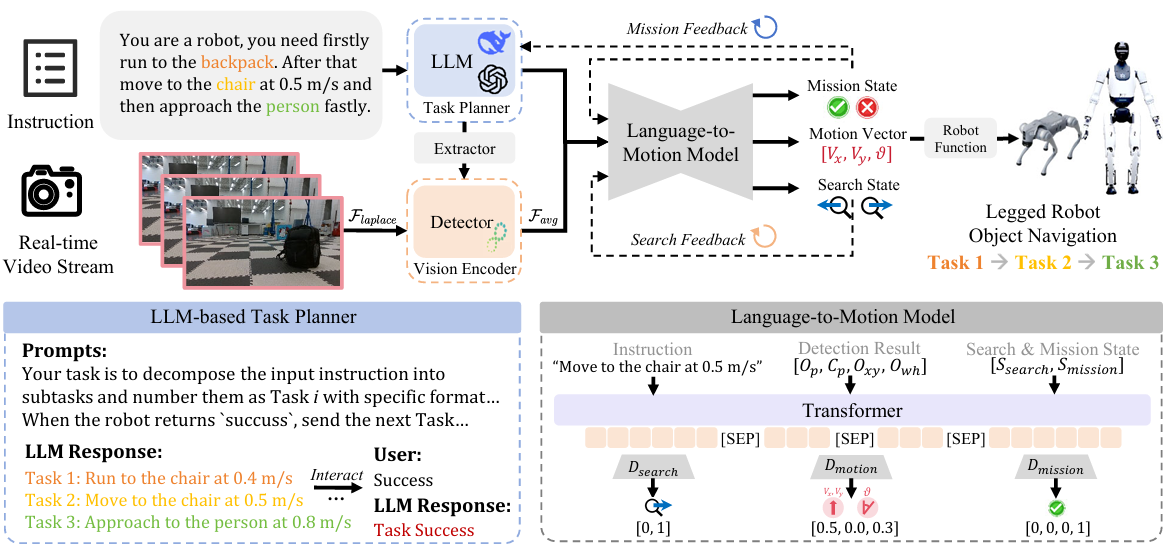
- 最初,LLM將人類的長時域任務重新配置為基本任務指令。這些指令隨后傳遞給指令對象提取器(IOE)以識別目標對象。
- 檢測模型處理捕獲的視頻流,輸入圖像使用拉普拉斯濾波器進行預處理。
- 最后,將任務指令、目標對象、邊界框、任務狀態和搜索狀態結合起來作為提出的L2MM的輸入,L2MM生成機器人的控制向量和反饋狀態,以逐步完成所有任務。
多模態輸入處理
- LOVON整合了兩個預訓練模型:用于視覺輸入處理的對象檢測模型和用于長時域任務管理的LLM。LLM的輸入包括系統描述 IsysI_{sys}Isys?、用戶的長序列任務描述 TlT_lTl? 和來自L2MM的反饋 OfO_fOf?。利用這些輸入,LLM生成具體任務指令 IiI_iIi?,使LOVON能夠通過產生實現任務目標所需的指令來執行長序列任務:
Iins=fLLM(Isys,Tl,Of) I_{ins} = f_{LLM}(I_{sys}, T_l, O_f) Iins?=fLLM?(Isys?,Tl?,Of?) - 接著,提出的IOE將指令映射到檢測類別。IOE使用兩層Transformer和感知層來預測對象類別:
Iobject=fIOE(Im)∈C I_{object} = f_{IOE}(I_m) \in C Iobject?=fIOE?(Im?)∈C
其中 CCC 表示檢測模型能夠識別的類別集合。 - 關于視覺處理,對象檢測模型以RGB圖像 IRGBI_{RGB}IRGB? 和 IobjectI_{object}Iobject? 作為輸入,并輸出所需的檢測信息如下:
Om,Cp,Oxy,Owh=fdet(IRGB,Iobject) O_m, C_p, O_{xy}, O_{wh} = f_{det}(I_{RGB}, I_{object}) Om?,Cp?,Oxy?,Owh?=fdet?(IRGB?,Iobject?)
使用歸一化格式表示檢測結果,預測的對象記為 OmO_mOm?,置信度分數為 CpC_pCp?,邊界框中心位置為 Oxy=[xn,yn]O_{xy} = [x_n, y_n]Oxy?=[xn?,yn?]。邊界框的寬度和高度分別表示為 Owh=[wn,hn]O_{wh} = [w_n, h_n]Owh?=[wn?,hn?]。此外,還應用移動平均濾波器對對象檢測模型的輸出邊界框進行平滑處理,進一步提高穩定性。
基于拉普拉斯方差的運動模糊過濾

- 當足式機器人處于運動狀態時,由此產生的波動會導致捕獲的幀出現運動模糊。尤其是在機器人動態運動的最初幾幀,模糊現象更為嚴重,這對視覺模型來說是一個挑戰。
- 為了解決這個問題,提出了一種基于拉普拉斯方差的方法,用于檢測和過濾運動模糊的幀。這一預處理步驟通過減輕機器人運動和振動引起的運動模糊和失真,提高了輸入到基于對象檢測的視覺語言管道的魯棒性。
- 具體來說,首先將RGB幀 IRGBI_{RGB}IRGB? 轉換為灰度圖像 IgrayI_{gray}Igray?。然后,應用拉普拉斯算子以增強高頻分量,得到拉普拉斯響應。計算拉普拉斯響應的方差以評估幀的清晰度。如果方差低于閾值 TblurT_{blur}Tblur?,則將該幀歸類為模糊幀,并用上一個清晰的幀替換它。閾值 TblurT_{blur}Tblur? 是針對機器人場景進行經驗校準的。
語言到運動模型(L2MM)
- 提出的L2MM是負責預測運動和提供反饋的核心模塊。L2MM采用編碼器 - 解碼器架構。編碼器接收由以下組件組成的輸入序列:前一個任務指令 Im0I_{m0}Im0?、當前任務指令 Im1I_{m1}Im1?、預測的對象 OpO_pOp?、預測的置信度 CpC_pCp?、中心位置 OxyO_{xy}Oxy?、歸一化邊界框的寬度和高度 OwhO_{wh}Owh?、當前任務狀態 SmS_mSm? 以及當前搜索狀態 SsS_sSs?。這些輸入通過特殊標記 [SEP] 分隔后進行拼接,即 Iencoder={Im0,Im1,Op,Cp,Oxy,Owh,Sm,Ss}I_{encoder} = \{I_{m0}, I_{m1}, O_p, C_p, O_{xy}, O_{wh}, S_m, S_s\}Iencoder?={Im0?,Im1?,Op?,Cp?,Oxy?,Owh?,Sm?,Ss?}。編碼器處理該序列并輸出潛在狀態 lel_ele?。
- 該架構使模型能夠同時預測運動向量、任務狀態和搜索狀態,從而使機器人不僅能夠精確控制其運動,還能夠理解長任務序列并提供相關反饋。
損失函數
根據任務的不同,模型使用不同的損失函數進行訓練:
- 運動向量損失:對于運動向量頭 DmotionD_{motion}Dmotion?,使用均方誤差損失,并使用系數 β\betaβ 來衡量預測運動向量與實際運動向量之間的差異:
LMSE=1N∑i=1Nβ(Vipred?Vitrue)2 L_{MSE} = \frac{1}{N} \sum_{i=1}^{N} \beta (V_{i}^{pred} - V_{i}^{true})^2 LMSE?=N1?i=1∑N?β(Vipred??Vitrue?)2 - 任務和搜索狀態損失:對于任務和搜索狀態頭 DmissionD_{mission}Dmission? 和 DsearchD_{search}Dsearch?,使用交叉熵損失來比較預測狀態與真實標簽:
LCE=?∑i=1Nyilog?(pi) L_{CE} = -\sum_{i=1}^{N} y_i \log(p_i) LCE?=?i=1∑N?yi?log(pi?)
其中 yiy_iyi? 是真實標簽,pip_ipi? 是每個類別的預測概率。
機器人任務執行的功能邏輯
- 執行新任務:機器人將當前任務指令與上一個任務指令進行比較,如果發現它們不同,機器人就會開始執行新的任務。
- 奔向目標對象:一旦機器人檢測到任務目標,它就會根據運動向量和檢測結果向該目標移動。
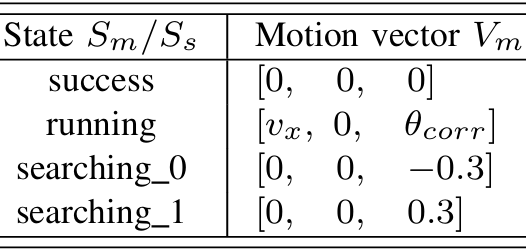
- 搜索丟失的目標對象:如果機器人失去了對任務目標的跟蹤,它會自動切換到搜索狀態,并調整其運動以重新找到目標。
- 保持當前狀態:機器人會根據實時視覺輸入保持其當前狀態,直到觸發狀態轉換,確保任務執行的一致性。
- 完成任務:機器人會持續監測任務目標,一旦目標的邊界框大小達到成功閾值,機器人就會停止并切換到成功狀態。
數據集準備
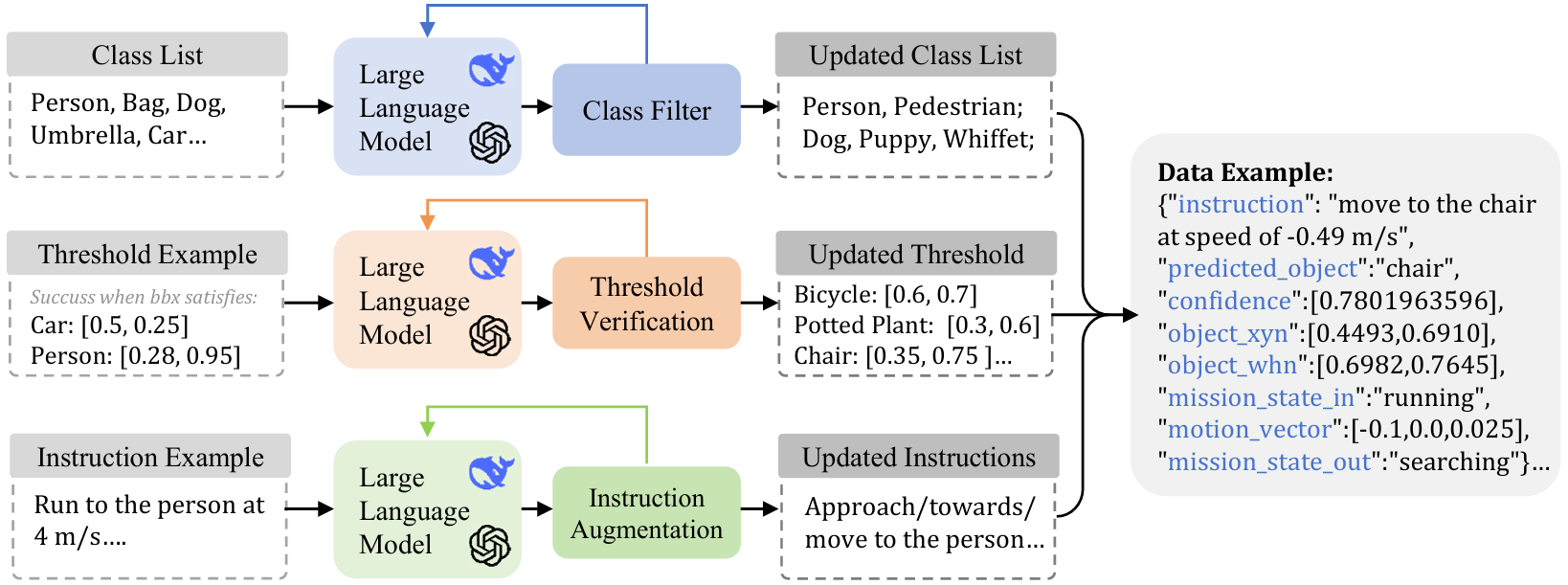
數據集生成流程包括三個主要部分:
- 檢測類別同義詞擴展:使用LLM為預定義的對象類別生成同義詞,豐富對象類別,提高模型在不同對象描述下的泛化能力。
- 指令變體生成:為了增強語言模塊,使用LLM生成任務指令的釋義。這使得模型能夠處理多樣化的句子結構,同時保留核心信息,提高其適應性。
- 對象類別的閾值生成:根據初始示例定義對象檢測的成功閾值,然后使用LLM為其他類別調整這些閾值,確保模型能夠處理不同大小的對象。
- 數據集生成特點:在生成過程中,生成的數據會反饋到LLM中,以迭代地優化數據集,避免冗余,提高數據集的多樣性。數據集生成過程快速且易于擴展,使用CPU Intel i9-12900KF在不到15分鐘內就可以生成100萬條數據。
實驗
實驗設置
- 模型細節:使用YOLO-11作為對象檢測模型,DeepSeek R1作為任務規劃器和數據生成助手。L2MM是一個基于Transformer的模型,具有256維特征、4層、8個注意力頭、1024維前饋層和一個線性頭層。IOE具有類似的架構,但特征維度較小。
- 訓練設置:收集了100萬樣本的數據集,分為訓練集和測試集,比例為4:1。使用NVIDIA RTX 3080 Ti GPU進行訓練。L2MM模型的訓練參數包括0.1的dropout率、10^-4的學習率、512的批量大小、64的最大序列長度和10的運動損失系數β。使用AdamW優化器訓練25個周期,總訓練時間約為1小時。

- 機器人設置:LOVON可以應用于多種足式機器人。在實驗中,評估了Unitree Go2、B2和H1-2三種模型。計算平臺使用Jetson Orin,視覺平臺包括機器人的內置攝像頭和Realsense D435i攝像頭。
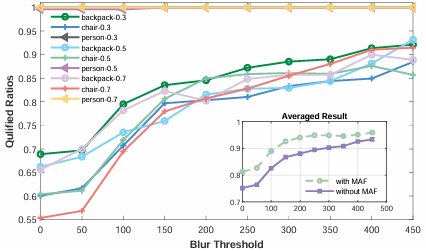
運動模糊幀過濾的性能
研究運動模糊對目標檢測性能的影響,并驗證提出的運動模糊幀過濾方法的有效性。
- 實驗方法:讓機器人以0.3、0.5或0.7 m/s的固定速度接近背包、椅子或人。計算每個幀的拉普拉斯方差,并將其輸入目標檢測模型以獲得預測置信度分數。
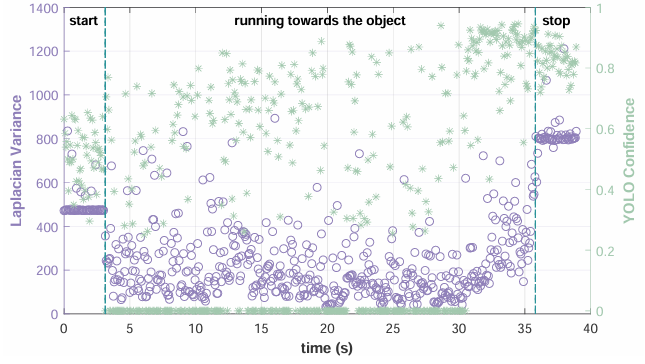
- 實驗結果:發現拉普拉斯方差與YOLO置信度之間存在顯著波動。通過設置模糊閾值,可以過濾掉運動模糊嚴重的幀。實驗結果表明,當閾值設置為Tblur = 150時,所有數據集的合格幀率提高了約15%。將過濾方法整合到目標檢測流程中后,合格幀率總體提高了25%。
在仿真環境中的評估

- 基準和評估指標:在Gym-Unreal基準的四個場景(UrbanCity、SnowVillage、ParkingLot和UrbanRoad)中進行評估。使用兩個指標:集數長度(EL)和成功率(SR)。
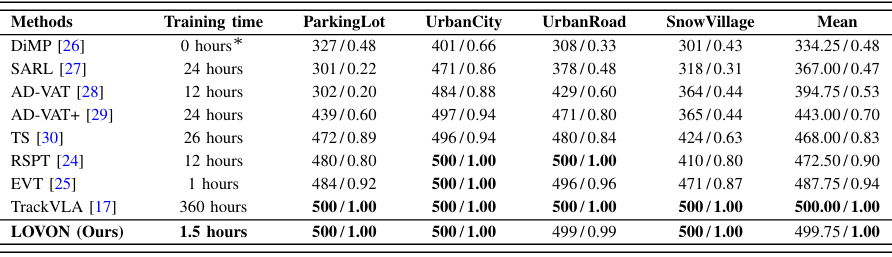
- 性能比較:LOVON在大多數環境中的表現優于基線方法,例如在ParkingLot環境中,LOVON的平均集數長度為500,成功率為1.00,而EVT的平均集數長度為484,成功率為0.92。與TrackVLA相比,LOVON在訓練時間上更高效,僅需1.5小時,而TrackVLA需要360小時。
在現實世界實驗中的評估

- 開放世界適應性:LOVON能夠處理日常生活中常見的各種大小和類型的物體,包括大型物體(如汽車)、中型物體(如人)和小型物品(如包)。
- 多目標跟蹤:通過LLM規劃器實現長時域目標導航,使機器人能夠高效地跟蹤多個目標。
- 動態跟蹤:LOVON能夠在動態環境中成功跟隨移動目標,例如在平坦道路、螺旋樓梯和野草中行走。
- 抗干擾能力:即使目標物體被移動或機器人受到干擾(如被踢),機器人也能快速重新定位并繼續搜索。
消融研究
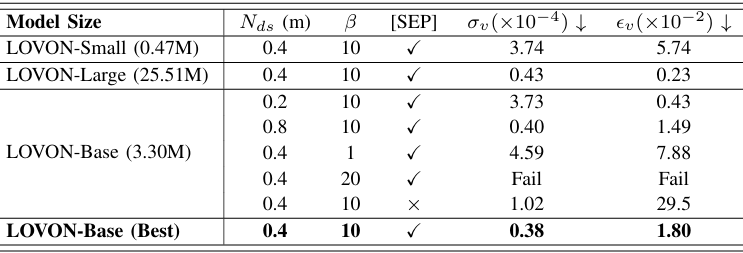
- 模型參數的消融研究:研究了模型大小、數據集大小Nds、運動損失權重β和特殊標記[SEP]的包含與否對模型性能的影響。結果表明,中等大小的模型表現最佳,數據集大小對模型穩定性有影響,運動損失權重β對性能至關重要,特殊標記[SEP]對于區分不同輸入組件(尤其是語言)是必要的。
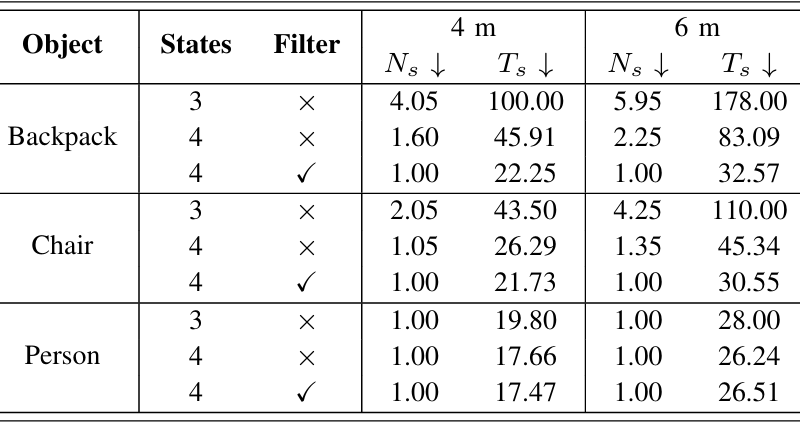
- 過濾方法和狀態數量的消融研究:評估了搜索狀態的數量和幀過濾技術對目標丟失時導航效率的影響。實驗結果表明,使用四個狀態和幀過濾技術的配置(Case 3)在導航效率方面表現最佳。
結論與未來工作
- 結論:
- LOVON通過整合LLMs、開放詞匯視覺檢測和L2MM,有效地解決了足式機器人在開放世界環境中執行長時域任務的挑戰。
- 通過拉普拉斯方差幀過濾和平均置信度平滑濾波器,顯著提高了模型在實際應用中的性能。
- 未來工作:
- 在未來的工作中,論文計劃進一步優化LOVON的架構,增強其與最新視覺語言模型的集成,以進一步提升其在具身智能導航任務中的能力。




















