1 i++/i--引起的線程安全問題
1.1 問題
-
思考:兩個線程對初始值為 0 的靜態變量一個做自增,一個做自減,各做 5000 次,結果是 0 嗎?
public class SyncDemo {private static int counter = 0;public static void increment() {counter++;}public static void decrement() {counter--;}public static void main(String[] args) throws InterruptedException {Thread t1 = new Thread(() -> {for (int i = 0; i < 5000; i++) {increment();}}, "t1");Thread t2 = new Thread(() -> {for (int i = 0; i < 5000; i++) {decrement();}}, "t2");t1.start();t2.start();t1.join();t2.join();// 思考: counter=?log.info("{}", counter);} }- 以上的結果可能是正數、負數或者零。為什么?因為 Java 中對靜態變量的自增和自減并不是原子操作。
1.2 原因
-
我們可以查看
i++和i--(i就是上面代碼中的counter,為靜態變量)的 JVM 字節碼指令; -
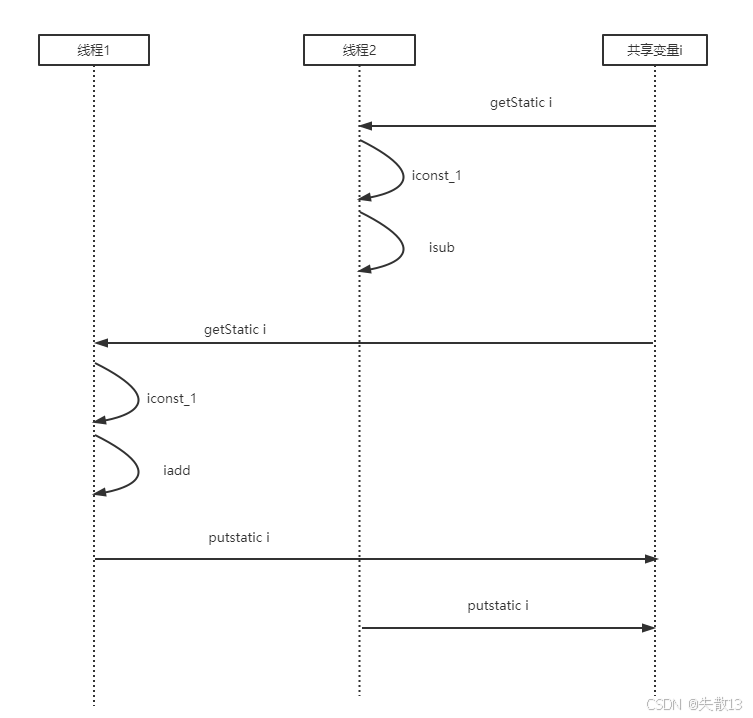
i++的 JVM 字節碼指令getstatic i // 獲取靜態變量i的值,并將其值壓入棧頂 iconst_1 // 將int型常量1壓入棧頂 iadd // 將棧頂兩int型數值相加并將結果壓入棧頂 putstatic i // 將結果賦值給靜態變量i -
i--的 JVM 字節碼指令getstatic i // 獲取靜態變量i的值,并將其值壓入棧頂 iconst_1 // 將int型常量1壓入棧頂 isub // 將棧頂兩int型數值相減并將結果壓入棧頂 putstatic i // 將結果賦值給靜態變量i -
如果是單線程環境,那么上面的這 8 行指令是順序執行(不會交錯)的,最后的運行結果就可能是 0 。但是在多線程環境下,這這 8 行代碼可能是交錯運行,如下圖:
- 問題就出在多個線程訪問共享資源,在多個線程對共享資源進行讀寫操作時會發生指令交錯,就會出現問題;
1.3 解決
-
一段代碼塊內如果存在對共享資源的多線程讀寫操作,就稱這段代碼塊為臨界區,稱其操作的共享資源為臨界資源;
-
多個線程在臨界區內執行,由于代碼的執行序列不同而導致結果無法預測,稱之為發生了競態條件;
//臨界資源 private static int counter = 0;public static void increment() { //臨界區counter++; }public static void decrement() {//臨界區counter--; } -
有多種手段可以避免臨界區的競態條件發生:
- 阻塞式的解決方案:
synchronized,Lock - 非阻塞式的解決方案:原子變量
- 阻塞式的解決方案:
-
雖然 Java 中互斥和同步都可以采用
synchronized關鍵字來完成,但它們還是有區別的:- 互斥是保證臨界區的競態條件發生,同一時刻只能有一個線程執行臨界區代碼;
- 同步是由于線程執行的先后順序不同,需要一個線程等待其它線程運行到某個點后它才能運行。
2 synchronized
2.1 簡介
synchronized同步塊是 Java 提供的一種原子性內置鎖(Java 內置的、使用者看不到的鎖被稱為內置鎖,也叫作監視器鎖),Java 中的每個對象都可以把它當作一個同步鎖來使用。
2.2 加鎖方式
-
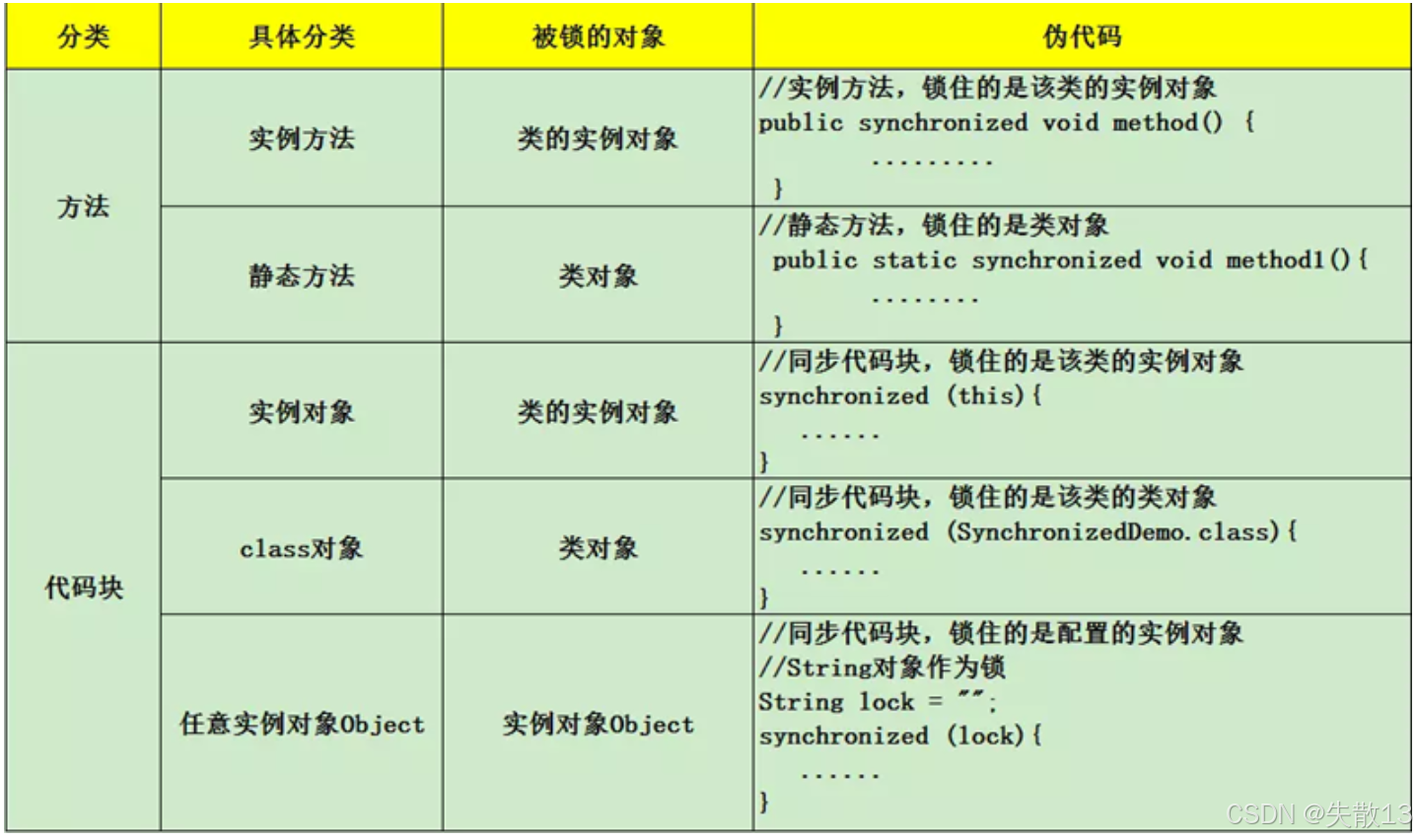
方法分類(直接修飾方法)
-
實例方法加鎖
// 鎖的是當前實例對象,多個線程用同一個實例調用此方法,需競爭這把鎖;不同實例調用,互不影響 public synchronized void method() { // 線程安全的業務邏輯 }-
被鎖對象:類的實例對象(
this指向的對象,每個實例對象鎖獨立); -
比如創建
A a1 = new A(); A a2 = new A();,線程 1 調用a1.method()、線程 2 調用a2.method(),因為鎖的是不同實例,二者可同時執行方法;
-
-
靜態方法加鎖
// 鎖的是當前類的 Class 對象,不管創建多少實例,調用此靜態方法都競爭同一把鎖 public static synchronized void method1() { // 線程安全的業務邏輯 }- 被鎖對象:類的Class 對象(每個類在 JVM 中只有一個
Class對象,全局唯一); - 比如
A a1 = new A(); A a2 = new A();,線程 1 調用a1.method1()、線程 2 調用a2.method1(),由于鎖的是A.class,二者會串行執行方法;
- 被鎖對象:類的Class 對象(每個類在 JVM 中只有一個
-
-
代碼塊分類(手動指定鎖對象,更靈活)
-
實例對象(
this)加鎖public void method() {// 鎖當前實例對象(this),效果和 “實例方法加鎖” 類似,只是鎖范圍更靈活(可縮小到代碼塊)synchronized (this) { // 線程安全的業務邏輯} }- 被鎖對象:類的實例對象(和“實例方法加鎖”鎖的對象一致,都是當前實例);
- 比如方法里有兩段邏輯,只有部分邏輯需要線程安全,就可以用這種方式,只給關鍵代碼加鎖,減少鎖競爭;
-
class 對象加鎖
public void method() {// 鎖當前類的 Class 對象(比如 SynchronizedDemo.class),效果和 “靜態方法加鎖” 類似synchronized (SynchronizedDemo.class) { // 線程安全的業務邏輯} }- 被鎖對象:類的Class 對象(和“靜態方法加鎖”鎖的對象一致,全局唯一);
- 常用于靜態變量修改、靜態工具方法線程安全控制,不管是不是靜態方法,只要鎖
Class對象,就會和靜態方法加鎖競爭同一把鎖;
-
任意實例對象(Object)加鎖
// 定義一個鎖對象(可以是任意類型,只要是同一個實例) String lock = ""; public void method() {// 鎖自定義的 lock 對象,多個線程競爭這同一個對象的鎖synchronized (lock) { // 線程安全的業務邏輯} }- 被鎖對象:自定義的任意實例對象(自己創建的對象,作為鎖標識);
- 這種方式最靈活,比如想讓不同方法、不同類共享同一把鎖,就可以把
lock定義為公共對象;也能精準控制鎖的范圍(比如不同邏輯用不同鎖,減少鎖競爭);
-
-
核心區別總結
分類維度 關鍵差異點 鎖的對象 方法加鎖(實例/靜態)鎖的是 “實例對象” 或 “Class 對象”;代碼塊加鎖可靈活指定任意對象鎖 鎖的粒度 方法加鎖是 “整個方法” ;代碼塊加鎖可縮小到 “部分代碼”,更靈活控制線程安全范圍 使用場景 簡單場景用方法加鎖;復雜場景(需精準控制鎖范圍、自定義鎖對象)用代碼塊加鎖 -
簡單說,
synchronized本質是通過“對象鎖”保證同一時間只有一個線程執行臨界區代碼,不同加鎖方式只是鎖的對象、鎖的范圍不同,實際開發要根據場景選(比如想鎖實例用this或實例方法,想全局鎖用Class對象或靜態方法,想靈活自定義鎖用任意對象代碼塊),避免鎖競爭影響性能,也得保證線程安全。
2.3 使用synchronized解決前面的共享問題
-
方式一:
// 同步靜態方法 increment,當多個線程調用此方法時,會競爭當前類的鎖(Class 對象鎖) // 同一時刻,只有一個線程能進入該方法執行 counter++ 操作,保證線程安全 public static synchronized void increment() {counter++; }public static synchronized void decrement() {counter--; } -
方式二:
// 定義一個私有的、靜態的字符串類型鎖對象 lock,這里用空字符串只是作為一個鎖的標識,實際只要是同一個對象即可 private static String lock = "";// 非同步方法 increment,方法內通過同步代碼塊來實現線程安全 public static void increment() {// 進入同步代碼塊,這里鎖定的是 lock 對象,多個線程要執行此代碼塊,需先獲取 lock 對象的鎖synchronized (lock) {// 執行 counter 自增操作,由于有鎖的保護,同一時刻只有一個線程能執行這行代碼counter++; } }public static void decrement() {synchronized (lock) { counter--; } } -
在上面的兩種修改方式中,
synchronized實際是用對象鎖保證了臨界區內代碼的原子性: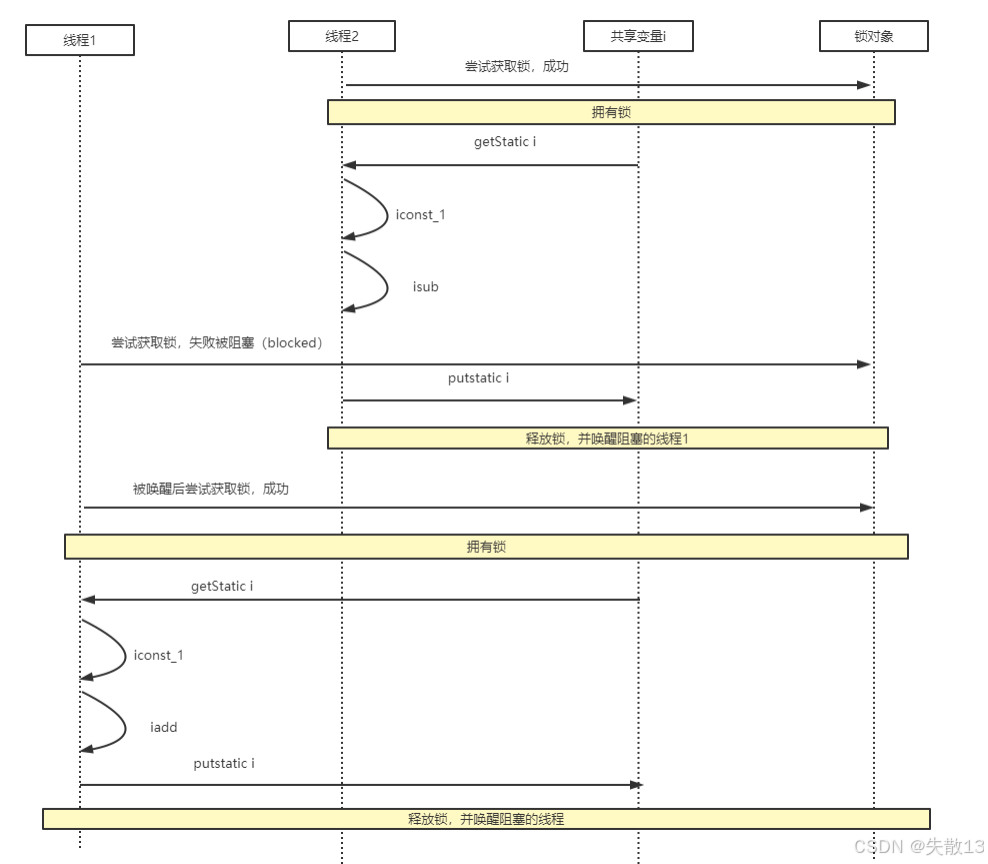
2.4 底層實現原理分析
synchronized是JVM內置鎖,基于Monitor機制實現,依賴底層操作系統的互斥原語Mutex(互斥量),它是一個重量級鎖,性能較低。
2.4.1 查看synchronized的字節碼指令序列
-
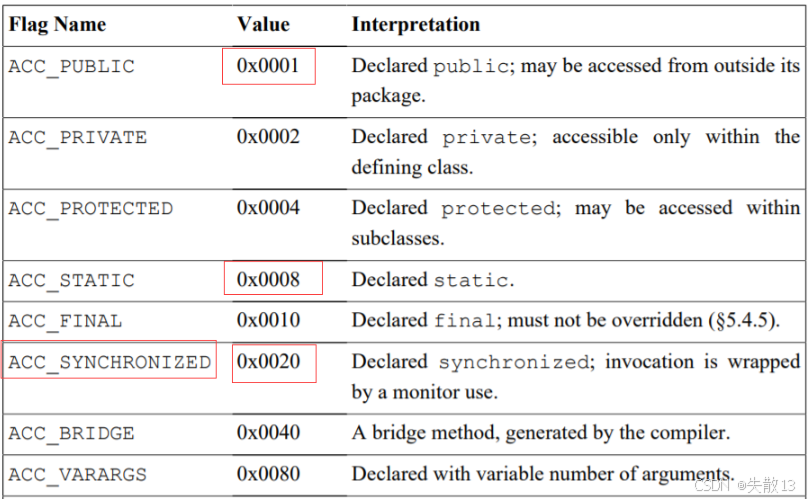
同步方法(
synchronized修飾方法)- 方法的訪問標志(
Access flags)里,會有一個ACC_SYNCHRONIZED標志(值為0x0020); - 原理:JVM 執行方法時,會檢查
ACC_SYNCHRONIZED標志。如果有,會先獲取監視器鎖(monitor),執行完方法后再釋放鎖。同一時間,只有一個線程能持有這把鎖,保證線程安全;
Java 方法的
access_flags(訪問標志),是用 多個標志位 “按位或(|)” 拼接 出來的;比如:
ACC_PUBLIC(0x0001)代表方法是publicACC_STATIC(0x0008)代表方法是staticACC_SYNCHRONIZED(0x0020)代表方法是synchronized
當一個方法同時是
public、static、synchronized時,它的access_flags就是這三個標志的按位或結果:0x0001(ACC_PUBLIC) | 0x0008(ACC_STATIC) | 0x0020(ACC_SYNCHRONIZED) = 0x0029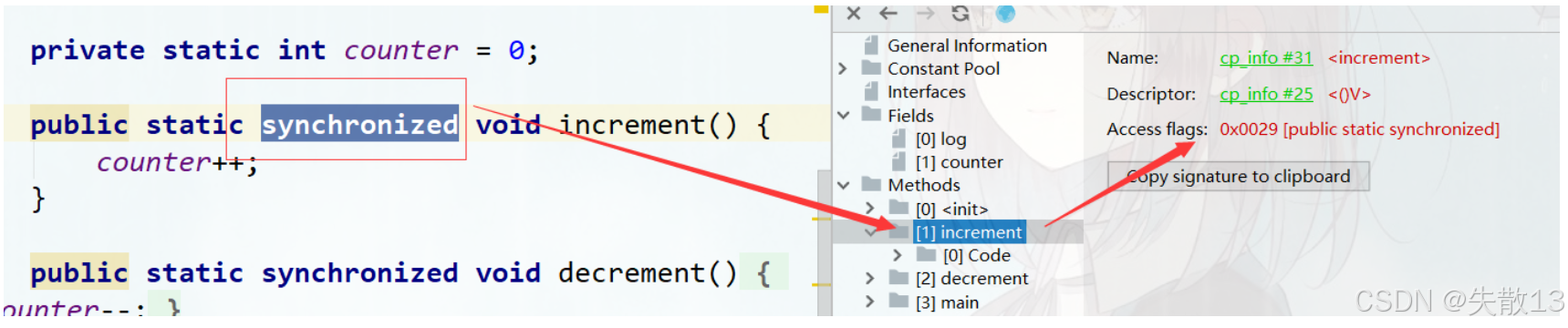
- 方法的訪問標志(
-
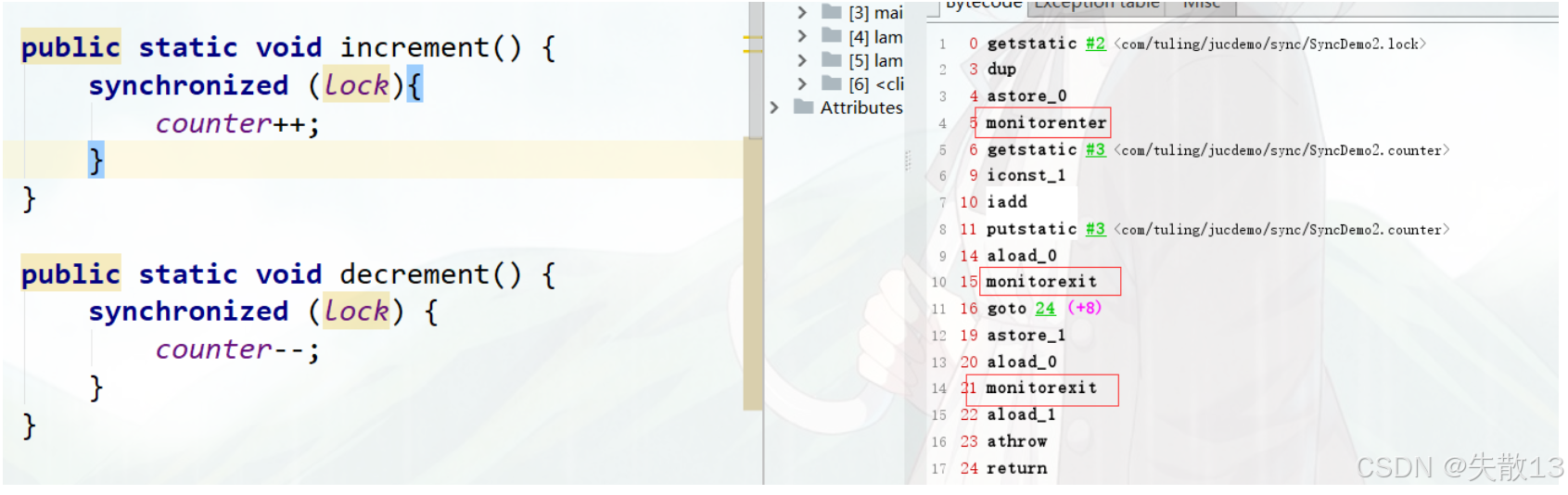
同步代碼塊(
synchronized (lock) { ... })- 字節碼中會出現
monitorenter和monitorexit指令:monitorenter:進入同步代碼塊時,嘗試獲取lock對象的監視器鎖。獲取成功后,鎖的計數器 +1(重入性體現);monitorexit:退出同步代碼塊時,釋放鎖,鎖的計數器 -1。當計數器歸 0,其他線程才能獲取鎖;
- 字節碼中會出現
-
監視器鎖(monitor)是什么?
- 可以理解為**“鎖的底層實現”**,每個對象在 JVM 中都有一個對應的
monitor(可看作一種數據結構); - 當線程獲取鎖時,實際是獲取
monitor的所有權;釋放鎖時,釋放monitor; - 作用:保證同一時間只有一個線程執行臨界區代碼,解決線程安全問題;
- 可以理解為**“鎖的底層實現”**,每個對象在 JVM 中都有一個對應的
-
關鍵區別(同步方法 vs 同步代碼塊)
對比項 同步方法( ACC_SYNCHRONIZED)同步代碼塊( monitorenter/monitorexit)實現方式 靠方法的 ACC_SYNCHRONIZED標志靠顯式的 monitorenter/monitorexit指令鎖的粒度 整個方法都受鎖保護 僅代碼塊范圍受鎖保護(更靈活,可縮小鎖范圍) 重入性支持 支持(JVM 自動處理鎖的重入計數) 支持( monitorenter指令會檢查當前線程是否持有鎖,自動重入)
2.4.2 重量級鎖實現之 Monitor(管程/監視器)機制詳解
2.4.2.1 Monitor 簡介
-
Monitor,直譯為“監視器”,而操作系統領域一般翻譯為管程(管理共享資源的“容器”);
-
管程本質上是一種并發編程的基礎模型,用來管理共享變量,以及對共享變量的操作過程,讓這些操作能安全地支持多線程并發。管程是指管理共享變量以及對共享變量操作的過程,讓它們支持并發;
-
作用:
- 解決多線程并發問題:多線程直接操作共享變量,容易出現線程安全問題(比如數據混亂、結果不一致)。Monitor 的作用就是給共享變量和操作加一層保護,讓同一時間只有一個線程能執行關鍵操作,避免混亂;
- Java 并發的基石:
- Java 1.5 之前,唯一的并發工具就是管程(靠
synchronized+wait/notify實現); - Java 1.5 之后的并發包(
java.util.concurrent),底層也是基于管程思想封裝的(比如ReentrantLock等鎖,本質和管程同源);
- Java 1.5 之前,唯一的并發工具就是管程(靠
-
Monitor 在 Java 里的體現
-
和
synchronized強綁定:-
Java 里,每個對象(
Object)在 JVM 中都對應一個 Monitor 監視器; -
當用
synchronized修飾方法/代碼塊時,本質就是 關聯到對象的 Monitor,獲取 Monitor 的鎖;
-
-
wait/notify/notifyAll是管程的“操作接口”:這三個方法是Object類的方法(每個對象都有),它們的作用就是操作 Monitor 的狀態:wait():釋放當前持有的 Monitor 鎖,進入等待隊列,等待被喚醒;notify()/notifyAll():喚醒等待隊列中的線程,讓它們重新競爭 Monitor 鎖;
-
-
JVM 規范里的 Monitor
-
《Java 語言規范》:

-
每個對象都會關聯一個 Monitor,用來控制多線程對對象狀態(共享變量)的并發訪問;
-
不管是
synchronized方法,還是synchronized代碼塊,最終都依賴 Monitor 實現同步;
-
-
-
《Java 虛擬機規范》:JVM 靠 “Monitor 這一種同步結構”,同時支持兩種同步場景:

- 修飾整個方法(
synchronized方法); - 修飾方法內的一段代碼(
synchronized代碼塊)。
- 修飾整個方法(
2.4.2.2 MESA模型分析
-
管程發展出過 Hasen 模型、Hoare 模型、MESA 模型,目前廣泛使用的是 MESA 模型(Java 的
synchronized就是參考它實現的);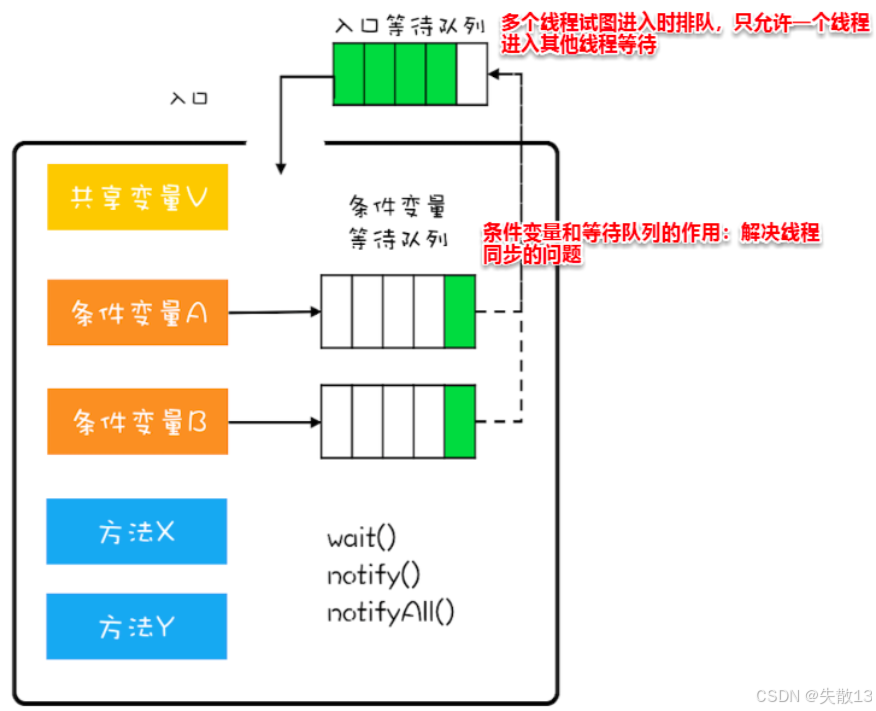
-
共享變量:需要被多線程安全訪問的變量(比如上圖里的“共享變量 V”);
-
入口等待隊列:多線程要進入管程操作共享變量時,先在這里排隊。同一時間,只有一個線程能拿到鎖,進入管程執行;
-
條件變量 + 等待隊列:
- 條件變量(比如“條件變量 A/B”)是管程里的同步工具,用來解決線程之間的復雜同步問題(比如線程需要等待某個條件滿足才能繼續執行);
- 每個條件變量對應一個等待隊列,線程調用
wait()時,會進入對應條件變量的等待隊列,釋放管程鎖,等待被喚醒;
-
-
Java 的
synchronized參考了 MESA 模型,但做了簡化: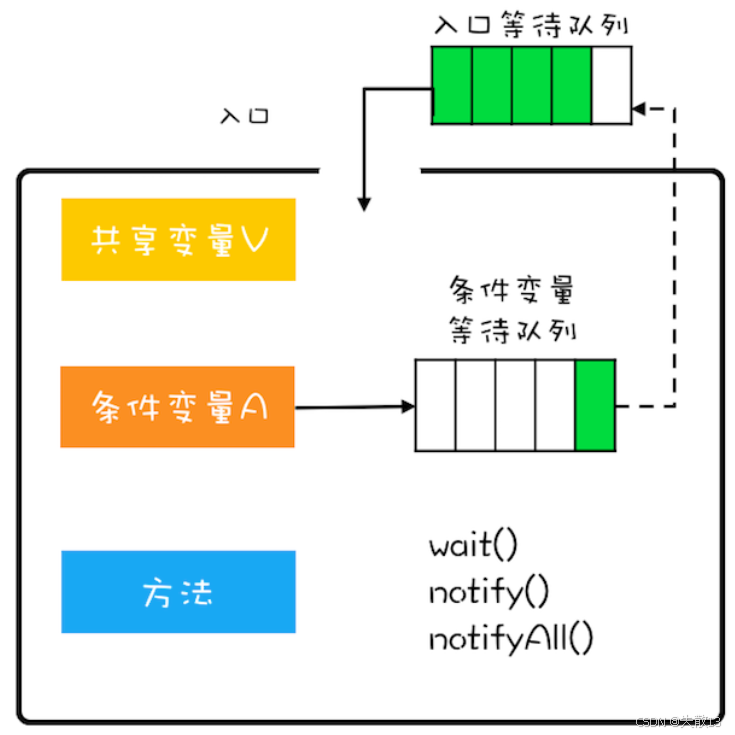
-
條件變量只有 1 個:Java 里,管程(
synchronized)的條件變量是通過Object的wait/notify實現的,整個管程只有一個條件變量隊列(對比 MESA 模型可以有多個條件變量); -
使用更簡單:雖然條件變量少,但足夠解決大部分線程同步問題(如果需要復雜條件,可通過手動邏輯模擬多個條件變量);
-
-
示例代碼:用
synchronized+wait/notifyAll演示了管程的同步邏輯,對應 MESA 模型的執行流程public class WaitDemo {// 管程的“鎖對象”,對應 MESA 模型的“管程鎖”final static Object obj = new Object(); public static void main(String[] args) throws InterruptedException {// 線程 t1:獲取 obj 鎖,執行 wait(),進入條件變量隊列new Thread(() -> {synchronized (obj) {// 操作共享資源try {obj.wait(); // 釋放鎖,進入條件變量隊列} catch (InterruptedException e) { ... }}}).start();// 線程 t2:和 t1 類似,也會執行 wait(),進入條件變量隊列new Thread(() -> {synchronized (obj) {// 操作共享資源try {obj.wait(); } catch (InterruptedException e) { ... }}}).start();// 主線程:等待 2 秒后,調用 notifyAll() 喚醒所有等待線程Thread.sleep(2000);synchronized (obj) {obj.notifyAll(); // 喚醒條件變量隊列里的所有線程}} }-
線程進入“入口等待隊列”:線程
t1、t2執行synchronized (obj)時,會先競爭obj的鎖。如果鎖被占用,就進入**“入口等待隊列”**排隊; -
線程執行
wait(),進入“條件變量隊列”:線程拿到鎖后,執行obj.wait():- 釋放
obj的鎖(讓其他線程可以進入管程); - 進入
obj對應的條件變量等待隊列(對應 MESA 模型里的“條件變量隊列”);
- 釋放
-
主線程調用
notifyAll(),喚醒等待線程:主線程執行obj.notifyAll()時:-
喚醒
obj條件變量隊列里的所有線程(t1、t2都會被喚醒); -
這些線程被喚醒后,會重新進入**“入口等待隊列”**,重新競爭
obj的鎖; -
拿到鎖的線程,繼續執行
wait()之后的邏輯。
-
-
2.4.2.3 ObjectMonitor數據結構分析
-
java.lang.Object類定義了wait()、notify()、notifyAll()方法,這些方法的具體實現,依賴于 JVM 中的ObjectMonitor數據結構; -
核心字段如下(在 Hotspot 源碼
ObjectMonitor.hpp中):ObjectMonitor() {// 1. 對象頭相關_header = NULL; // 對象頭(和 Java 對象的 markOop 關聯,存哈希、分代年齡、偏向鎖標記等)// 2. 鎖的基礎狀態_count = 0; // 記錄 Monitor 的一些統計狀態(比如鎖的競爭次數,JVM 內部調試用)_waiters = 0; // 等待線程的總數(調用 wait() 的線程數,輔助統計)_recursions = 0; // 鎖的重入次數(同一線程多次加鎖時,記錄重入深度)// 3. 關聯 Java 對象_object = NULL; // 指向關聯的 Java 對象(Monitor 和 Java 對象綁定,每個對象對應一個 Monitor)// 4. 持有鎖的線程_owner = NULL; // 當前持有鎖的線程(關鍵!標記誰在占用 Monitor,競爭鎖的核心)// 5. 等待隊列(wait() 相關)_WaitSet = NULL; // 等待隊列的頭節點(調用 wait() 的線程,會被鏈到這個雙向循環鏈表)_WaitSetLock = 0 ; // 保護 _WaitSet 隊列的鎖(操作等待隊列時,防止多線程混亂)// 6. 競爭鎖的輔助隊列_cxq = NULL; // 競爭鎖的臨時隊列(多線程競爭時,先臨時存在這個單向鏈表,FILO 結構)// 7. 阻塞線程隊列(EntryList)_EntryList = NULL; // 競爭鎖失敗的線程隊列(被阻塞的線程,等待重新競爭鎖)// 8. 其他輔助字段(JVM 調試、優化用,實際開發少關注)_Responsible = NULL; // 負責喚醒的線程(JVM 內部用于鎖競爭的優化,標記“該由誰喚醒”)_succ = NULL; // 后繼線程(鎖競爭的輔助標記,記錄下一個該競爭的線程)FreeNext = NULL; // 空閑 Monitor 鏈表(JVM 管理 Monitor 資源的輔助字段)_SpinFreq = 0 ; // 自旋次數統計(自適應自旋鎖的優化,記錄自旋嘗試次數)_SpinClock = 0 ; // 自旋時間統計(自適應自旋鎖的優化,記錄自旋耗時)OwnerIsThread = 0 ; // 標記 _owner 是否是線程(防止其他對象誤判,JVM 內部兼容用)_previous_owner_tid = 0; // 前一個持有鎖的線程 ID(JVM 內部調試、追蹤鎖競爭用) }
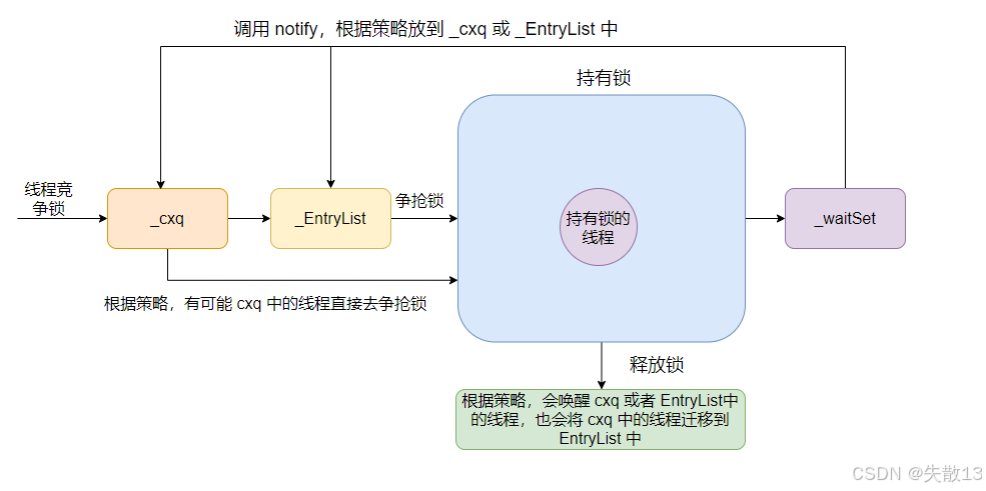
2.4.2.4 synchronized重量級鎖實現原理
-
synchronized底層靠monitor對象 + 隊列(cxq/EntryList/WaitSet) + 操作系統互斥鎖(mutex) 實現。由于線程阻塞/喚醒需要 用戶態 ? 內核態切換,開銷高,因此被稱為“重量級鎖”; -
核心組件:
組件 作用 monitor管理鎖的核心對象,內置隊列( cxq、EntryList、WaitSet),控制線程競爭與同步cxq競爭鎖的臨時單向隊列(基于 CAS 實現,快速暫存競爭失敗的線程) EntryList競爭鎖的阻塞雙向隊列(存放等待重新競爭鎖的線程) WaitSet條件等待隊列(調用 wait()的線程會進入這里,等待被notify喚醒)mutex(互斥鎖)操作系統提供的底層鎖, monitor依賴它實現線程的阻塞/喚醒(涉及內核態切換) -
線程競爭鎖流程(獲取鎖)
- 線程競爭:多個線程同時競爭鎖時,先嘗試 CAS 搶占;
- 進入
cxq:競爭失敗的線程,先進入cxq(單向隊列,基于 CAS 快速暫存); - 遷移到
EntryList:JVM 會“按需”把cxq中的線程遷移到EntryList(雙向隊列,降低尾部競爭); - 再次競爭鎖:
EntryList中的線程,等待鎖釋放后,重新競爭鎖(可能直接從cxq搶鎖,取決于策略);
-
線程釋放鎖流程(釋放鎖)
-
釋放鎖:持有鎖的線程執行完同步代碼,或調用
wait()時,釋放monitor的鎖; -
喚醒策略(默認策略是 Qmode=0):
-
如果
EntryList為空,把cxq的線程按順序遷移到EntryList,喚醒第一個線程(后來的線程可能先獲取鎖,類似“后來者優先”); -
如果
EntryList不為空,直接喚醒EntryList中的線程(先來者優先);假設
cxq里線程的排隊順序(從隊列頭部到尾部,即“入隊先后順序” )是**A → B → C**(A最先進入cxq隊列,C最后進入),此時EntryList為空;那么
cxq的線程會按原順序(保持A → B → C的先后順序)遷移到EntryList,所以遷移后EntryList里的線程順序也是**A → B → C**(A成為EntryList的第一個元素);遷移完成后,會喚醒
EntryList里的第一個線程,也就是**A** 。后續A會去競爭鎖,拿到鎖后執行同步代碼邏輯。
-
-
處理
WaitSet:如果調用notify()/notifyAll(),會從WaitSet喚醒線程,移到EntryList重新競爭;
-
-
wait()/notify()流程-
wait():持有鎖的線程調用wait()→ 釋放鎖 → 進入WaitSet等待 → 被喚醒后移到EntryList重新競爭; -
notify():持有鎖的線程調用notify()→ 從WaitSet選一個線程(或全部,notifyAll())→ 移到EntryList→ 線程重新競爭鎖;
-
-
synchronized被稱為“重量級鎖”的原因:線程的阻塞和喚醒依賴操作系統的mutex鎖,需要從用戶態切換到內核態(內核態負責調度線程阻塞/喚醒);-
用戶態 → 內核態切換:涉及 CPU 權限切換、上下文保存/恢復,開銷非常高;
-
因此,
synchronized重量級鎖的“重”,本質是內核態切換的高成本;
-
-
為什么需要
cxq和EntryList兩個隊列?-
cxq(單向隊列):基于 CAS 實現,支持線程“無鎖競爭”快速入隊,適合高并發搶鎖場景(減少鎖競爭的直接沖突); -
EntryList(雙向隊列):用于存放真正等待喚醒的線程,每次喚醒時遷移cxq的線程到這里,降低cxq的尾部競爭(雙向鏈表更適合批量遷移、喚醒操作); -
協同作用:
cxq負責“快速暫存”競爭失敗的線程,EntryList負責“有序管理”等待喚醒的線程,分工減少鎖競爭的壓力。
-
2.5 重量級鎖的優化策略
- 早期
synchronized是“重量級鎖”,依賴操作系統mutex,涉及用戶態/內核態切換,開銷大。JVM 內置鎖在 JDK 1.5 后引入多種優化(鎖粗化、鎖消除、輕量級鎖、偏向鎖、自適應自旋),讓synchronized性能大幅提升,甚至能和java.util.concurrent.Lock媲美。
2.5.1 鎖粗化(Lock Coarsening)
-
核心思想:將多個連續的小鎖,合并成一個大鎖,減少“加鎖-解鎖”的次數,降低開銷。也就是說,如果 JVM 檢測到有連續的對同一對象的加鎖、解鎖操作,就會把這些加鎖、解鎖操作合并為對這段區域進行一次連續的加鎖和解鎖;
-
例:
-
原始代碼(多個小同步塊):
synchronized (lock) {// 代碼塊 1 } // 無關代碼 synchronized (lock) {// 代碼塊 2 } -
JVM 優化后(合并成一個大同步塊):
synchronized (lock) {// 代碼塊 1// 無關代碼// 代碼塊 2 } -
效果:加鎖/解鎖次數從 2 次 減少到 1 次,降低了開銷;
-
-
為什么需要鎖粗化?每次“加鎖”和“解鎖”都可能涉及線程切換、內核態調用,有性能開銷。如果代碼中有大量連續的小同步塊(對同一個對象加鎖),頻繁加鎖/解鎖會累積成顯著開銷;
-
例:
StringBuffer的append方法是線程安全的(內部用synchronized加鎖)-
原始代碼(多次調用
append,隱含多次加鎖/解鎖):StringBuffer buffer = new StringBuffer(); buffer.append("aaa").append("bbb").append("ccc"); -
JVM 優化:JVM 檢測到“連續對
buffer加鎖”,會合并成一次加鎖、一次解鎖:- 第一次
append時加鎖,最后一次append結束后解鎖; - 中間的
append無需重復加鎖/解鎖,減少開銷;
- 第一次
-
-
鎖粗化的“有效性”原理
-
減少“加鎖-解鎖”的開銷
- 每次加鎖/解鎖可能觸發線程阻塞、內核態切換,成本很高;
- 合并后,次數從
N次 →1次,直接減少這部分開銷;
-
對開發者的啟示
- 不要手動寫“零碎的同步塊”:如果邏輯上可以合并,JVM 會幫你優化,但代碼寫得越簡潔(減少不必要的小同步塊),越容易觸發鎖粗化;
- 例如:避免在循環里反復加鎖同一個對象,盡量把鎖的范圍擴大(只要不影響線程安全)。
-
2.5.2 鎖消除(Lock Elimination)
-
什么是鎖消除?JVM 通過逃逸分析(Escape Analysis)發現:某些加鎖的共享數據實際上不會被多線程訪問(僅在一個線程內使用),于是自動消除這些不必要的鎖,避免加鎖/解鎖的性能開銷;
-
為什么需要鎖消除?
-
加鎖/解鎖本身有開銷(線程切換、內核態調用等);
-
如果數據確定不會被多線程競爭,加鎖就是“多余操作”,反而降低性能;
-
鎖消除能自動識別并移除這些無用鎖,提升程序效率;
-
-
鎖消除的實現基礎:逃逸分析
-
逃逸分析的作用。判斷一個對象的作用范圍:是否會“逃逸”出當前方法/線程,被其他線程訪問;
-
鎖消除的判斷條件。如果 JVM 通過逃逸分析發現:
-
對象是局部變量(作用域僅限當前方法);
-
對象無法被其他線程訪問(沒有逃逸出當前線程);
-
-
那么,對這個對象的加鎖操作(比如
StringBuffer.append的synchronized)會被 自動消除;
-
-
在代碼層面上,我們無法直接控制 JVM 進行鎖消除優化,這是由 JVM 的 JIT 編譯器在運行時動態完成的。但我們可以通過編寫高質量的代碼,使 JIT 編譯器更容易識別出可以進行鎖消除的場景。例如:
public class LockEliminationTest {public void append(String str1, String str2) {// StringBuffer 是局部變量,作用域僅限 append 方法StringBuffer stringBuffer = new StringBuffer(); // append 是同步方法(內部有 synchronized)stringBuffer.append(str1).append(str2); }public static void main(String[] args) {LockEliminationTest demo = new LockEliminationTest();long start = System.currentTimeMillis();// 循環調用 append,觸發 JIT 優化for (int i = 0; i < 10000000; i++) { demo.append("aaa", "bbb");}System.out.println("執行時間: " + (System.currentTimeMillis() - start) + " ms");} }-
StringBuffer是局部變量,作用域僅限append方法 → 不會逃逸到其他線程; -
JVM 通過逃逸分析識別到這一點 → 消除
append內部的synchronized鎖; -
測試結果:
-
關閉鎖消除(
-XX:-EliminateLocks):每次append都要加鎖/解鎖 → 執行時間長(比如 4688 ms); -
開啟鎖消除(
-XX:+EliminateLocks,JDK8+ 默認開啟):JVM 自動移除無用鎖 → 執行時間短(比如 2601 ms);
-
-
-
鎖消除的價值
-
性能提升:避免不必要的加鎖/解鎖開銷,尤其對高頻調用的方法(比如示例中的循環調用),優化效果顯著;
-
開發啟示
-
無需手動控制鎖消除(由 JVM 自動完成);
-
寫代碼時,盡量使用局部變量(減少對象逃逸),讓 JVM 更容易識別可優化的鎖。
-
-
2.5.3 CAS自旋優化(Spinlock Optimization)
-
核心思想:讓線程在競爭鎖失敗時,不直接阻塞,而是自旋等待一段時間(空轉 CPU),期望持有鎖的線程能快速釋放鎖,從而避免線程阻塞的高開銷;
-
為什么需要自旋優化?
-
重量級鎖的痛點:線程競爭鎖失敗時,會進入阻塞狀態 → 觸發用戶態 ? 內核態切換(非常耗時);
-
自旋的價值:如果持有鎖的線程很快釋放鎖(比如同步塊執行時間短),競爭線程通過“自旋等待”拿到鎖,就能避免阻塞的高開銷;
-
-
自旋優化的適用場景
-
多核 CPU 更有效:
-
單核 CPU 自旋會浪費 CPU 時間(沒有其他線程能釋放鎖);
-
多核 CPU 中,其他核的線程可能快速釋放鎖,自旋等待才有意義;
-
-
配合短同步塊:如果同步塊執行時間很短(比如幾納秒),自旋等待的性價比高;如果同步塊執行時間長,自旋會浪費 CPU,不如直接阻塞;
-
-
自旋優化的發展(JVM 版本演進)
-
Java 6 及之前:自適應自旋
-
手動控制:
-
通過參數開啟:
-XX:+UseSpinning(默認開啟); -
設置自旋次數:
-XX:PreBlockSpin(比如設為 10,代表自旋 10 次);
-
-
自適應邏輯:JVM 會根據歷史自旋成功率動態調整自旋次數
- 如果上次自旋成功(拿到鎖),認為這次也容易成功 → 增加自旋次數;
- 如果上次自旋失敗,減少自旋次數甚至不自旋;
-
-
Java 7 及之后:完全自適應
-
自動控制:移除
PreBlockSpin等參數,自旋次數由 JVM 完全自動調整(根據當前線程競爭、鎖釋放的歷史數據動態決策); -
強制自旋:只要觸發鎖競爭,JVM 會先自旋嘗試,不再允許手動關閉(因為 JVM 認為自旋的收益大于成本);
-
-
-
自旋優化的本質目標:減少線程阻塞-喚醒的次數
-
阻塞/喚醒涉及用戶態 ? 內核態切換,是重量級鎖最大的開銷;
-
自旋通過空轉 CPU 等待,讓線程盡量保持在用戶態,避免進入內核態阻塞,從而提升性能。
-
2.5.4 輕量級鎖(Lightweight Locking)
-
思考一個這個場景:當多個線程交替獲取同一把鎖,且競爭不激烈時
-
比如線程 A 用完鎖釋放后,線程 B 才來獲取,不會出現同時爭搶;
-
這種場景下,不需要直接升級到重量級鎖(避免內核態切換的高開銷);
-
-
對于上面這種場景,就可以引入輕量級鎖,輕量級鎖的作用就是:避免直接使用 monitor(重量級鎖),減少系統調用和線程阻塞的開銷
-
重量級鎖依賴
ObjectMonitor,涉及內核態切換(用戶態 ? 內核態),成本高; -
輕量級鎖通過 CAS(Compare-And-Swap) 實現,全程在用戶態完成,開銷低;
-
-
輕量級鎖的核心邏輯(對比重量級鎖講解)
-
加鎖流程
- 輕量級鎖:線程在棧中創建“鎖記錄(Lock Record)”,用 CAS 操作 嘗試將對象頭的“標記”指向自己的鎖記錄;
- 成功:加鎖完成(用戶態操作,無內核調用);
- 失敗:說明有競爭,直接升級為重量級鎖(不再自旋,避免無效等待);
- 輕量級鎖:線程在棧中創建“鎖記錄(Lock Record)”,用 CAS 操作 嘗試將對象頭的“標記”指向自己的鎖記錄;
-
-
重量級鎖:依賴
ObjectMonitor,競爭失敗會進入阻塞隊列(涉及內核態切換);-
與“自旋”的關系
-
錯誤理解:認為“輕量級鎖競爭失敗會自旋,自旋多次后升級為重量級鎖”;
-
正確邏輯:輕量級鎖沒有自旋邏輯!競爭失敗時,直接升級為重量級鎖,避免浪費 CPU。自旋是重量級鎖的優化策略,用于競爭失敗后的最后嘗試;
-
-
-
輕量級鎖的價值
-
針對“交替獲取鎖”優化:適合線程交替使用鎖的場景(比如線程 A 釋放后,線程 B 才來獲取),用 CAS 快速加鎖,避免重量級鎖的內核態開銷;
-
與重量級鎖分工明確,二者配合,覆蓋不同并發強度的需求:
-
輕量級鎖:處理競爭不激烈、交替獲取 的場景;
-
重量級鎖:處理競爭激烈、需要阻塞等待 的場景。
-
-
2.5.5 偏向鎖(Biased Locking)
-
思考一個這個場景:當鎖自始至終(或很長時間)只有一個線程訪問 時
-
比如某個同步方法,從始至終只有線程 A 調用,沒有其他線程競爭;
-
這種場景下,頻繁的 CAS 操作(輕量級鎖的加鎖方式)會帶來不必要的開銷;
-
-
對于上面這種場景,就可以引入偏向鎖,偏向鎖的作用就是:消除無競爭場景下的 CAS 開銷,讓單線程加鎖/解鎖更快
-
輕量級鎖依賴 CAS 操作(雖然在用戶態,但仍有一定開銷);
-
偏向鎖通過“標記鎖的偏向線程”,讓后續加鎖無需 CAS,直接復用;
-
-
偏向鎖的核心邏輯
-
加鎖流程
- 首次加鎖:JVM 檢測到鎖對象未被偏向 → 用 CAS 操作將對象頭的“偏向線程 ID”標記為當前線程。這一步需要 CAS,但只在首次加鎖時執行;
-
-
后續加鎖:線程再次訪問鎖時,無需 CAS。直接檢查對象頭的“偏向線程 ID”是否是自己 → 是則直接獲取鎖,無需任何操作;
-
對比輕量級鎖
鎖類型 適用場景 加鎖核心操作 優勢 偏向鎖 單線程重復加鎖 首次 CAS 標記線程,后續直接復用 消除無競爭下的 CAS 開銷 輕量級鎖 多線程交替加鎖(低競爭) 每次加鎖都要 CAS 避免重量級鎖的內核態切換
-
-
偏向鎖的價值
-
針對單線程加鎖優化。適合長期被一個線程持有、無競爭的鎖,比如工具類的同步方法,只有主線程調用 → 偏向鎖能讓加鎖開銷趨近于 0;
-
消除重入開銷。對于重入鎖(同一線程多次進入同步塊),偏向鎖標記后,無需每次 CAS 或檢查 Monitor → 直接復用,消除重入帶來的 CAS 開銷。
-
2.5.6 鎖升級的過程
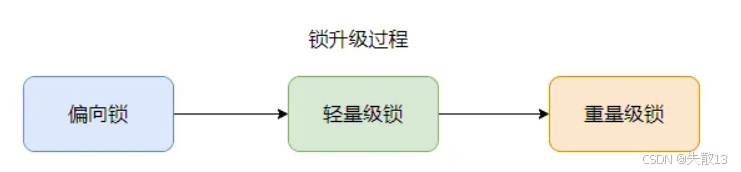
- 注意:
synchronized事實上是先有的重量級鎖的實現,然后根據實際分析優化實現了偏向鎖和輕量級鎖。
2.6 synchronized鎖升級詳解
- 思考:
synchronized加鎖加在對象上,那么對象是如何記錄鎖狀態的(如何判斷是否加鎖成功、鎖狀態記錄在哪兒)?
2.6.1 sychronized多種鎖狀態設計詳解
2.6.1.1 對象的內存布局
-
在 HotSpot 中,對象在內存中的存儲布局可以分為 3 部分:
區域 作用 對象頭(Header) 存儲對象的元數據(如鎖狀態、哈希碼、GC 分代年齡等),是鎖升級的核心 實例數據(Instance Data) 存儲對象的屬性數據(如類的字段值) 對齊填充(Padding) 保證對象起始地址是 8 字節的整數倍(HotSpot 要求),無關業務邏輯 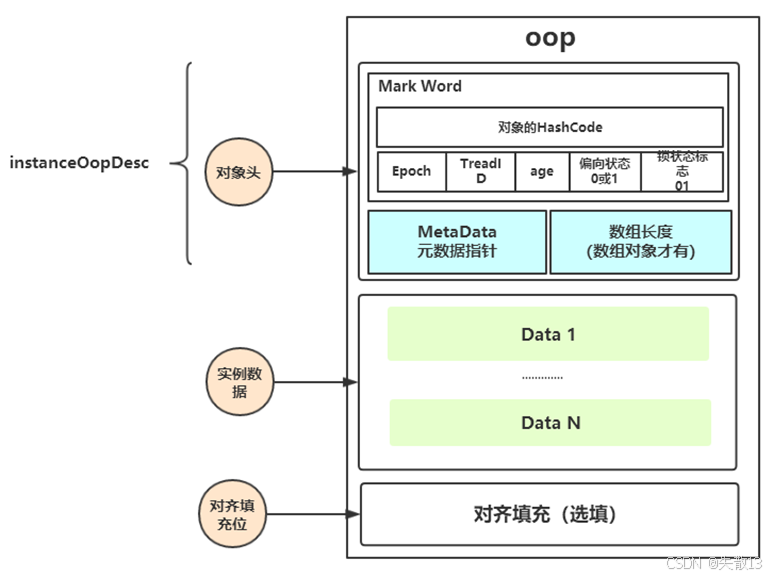
2.6.1.2 對象頭詳解
-
HotSpot 虛擬機中存儲的對象的對象頭的關鍵部分是 Mark Word;
-
它存儲了對象的運行時元數據,包括:
-
哈希碼(HashCode)、GC 分代年齡(用于垃圾回收);
-
鎖狀態標志(偏向鎖、輕量級鎖、重量級鎖的狀態);
-
線程持有的鎖信息(偏向線程 ID、輕量級鎖的指向等);
-
-
Mark Word 的長度:32 位虛擬機中占 32bit,64 位虛擬機中占 64bit(開啟指針壓縮后,實際存儲會更緊湊);
-
-
Klass Pointer(類型指針)
-
指向對象所屬類的元數據(即
Class對象),JVM 通過它確定對象的類型; -
長度:
- 32 位虛擬機中占 4 字節;
- 64 位虛擬機中,默認開啟指針壓縮(
UseCompressedOops),占 4 字節;關閉后占 8 字節;
-
-
數組長度(僅數組對象有):如果對象是數組(如
int[]、Object[]),對象頭中會額外存儲數組長度(4 字節);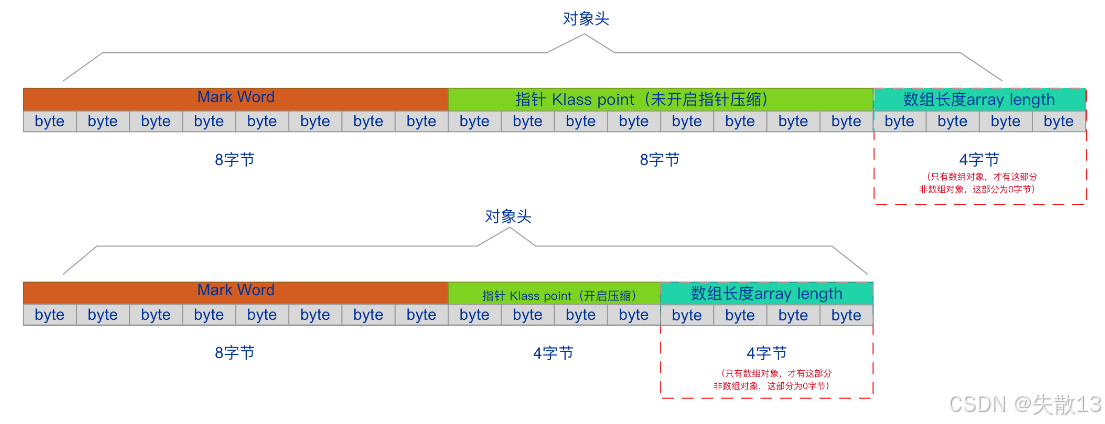
2.6.1.3 使用JOL工具查看內存布局
-
JOL(Java Object Layout)是一個 查看 Java 對象內存布局的工具,作用:
-
分析對象的“對象頭、實例數據、對齊填充”具體占多少字節;
-
驗證“鎖狀態存在對象頭的 Mark Word 中”這一底層邏輯;
-
-
引入依賴(Maven)
<!-- 查看Java對象布局、大小工具 --> <dependency><groupId>org.openjdk.jol</groupId><artifactId>jol-core</artifactId><version>0.18</version> </dependency> -
使用示例:利用 JOL 查看64位系統 Java 對象(空對象)
import org.openjdk.jol.info.ClassLayout;public class JOLTest {public static void main(String[] args) throws InterruptedException {Object obj = new Object();// 打印對象的內存布局System.out.println(ClassLayout.parseInstance(obj).toPrintable());} } -
默認開啟指針壓縮,輸出結果解析(以 64 位系統為例):
-
對象頭占 12 字節(Mark Word 8 字節 + Klass Pointer 4 字節);
-
加上對齊填充,空對象(
new Object())總大小是 16 字節;
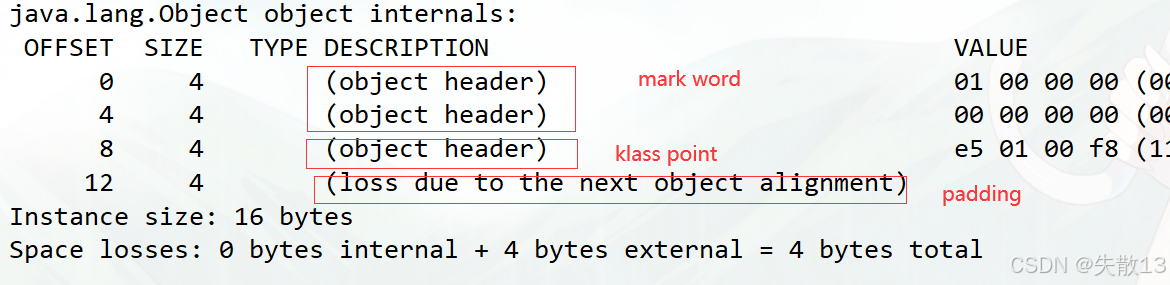
OFFSET:字段的偏移地址(從 0 開始);
SIZE:字段占用的字節數;
TYPE DESCRIPTION:字段類型描述(
object header是對象頭);VALUE:內存中存儲的實際值(對象頭的 Mark Word 內容);
-
-
關閉指針壓縮后,輸出結果解析:
-
對象頭占 16 字節(Mark Word 8 字節 + Klass Pointer 8 字節);
-
空對象總大小仍為 16 字節(無對齊填充);

-
-
練習:下面例子中 obj 對象占多少個字節?12 + 8 + 4 = 24 字節
public class ObjectTest {public static void main(String[] args) {Object obj = new Test();System.out.println(ClassLayout.parseInstance(obj).toPrintable());} }class Test {private long p; // long 占 8 字節 }- 對象頭:12 字節(Mark Word 8 + Klass Pointer 4);
- 實例數據:
long p占 8 字節; - 對齊填充:4 字節(保證總大小是 8 的倍數,24 是 8 的倍數);
-
回到之前的問題:
synchronized加鎖加在對象上,那么對象是如何記錄鎖狀態的?-
通過 JOL 可以驗證:鎖狀態(偏向鎖、輕量級鎖、重量級鎖)記錄在對象頭的 Mark Word 中;
-
Mark Word 存儲哈希碼、GC 分代年齡、鎖狀態標志、偏向線程 ID 等信息;
-
synchronized加鎖時,JVM 會修改 Mark Word 的鎖狀態標志,實現鎖升級。
-
-
2.6.1.4 Mark Word 是如何記錄鎖狀態的?
-
Hotspot 通過
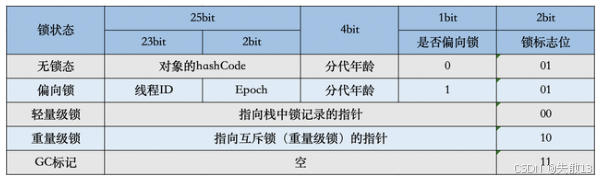
markOop類型實現 Mark Word,具體實現位于markOop.hpp文件中。由于對象需要存儲很多的運行時數據(哈希碼、鎖狀態、分代年齡等),考慮到虛擬機的內存使用,markOop被設計成一個非固定的數據結構,以便在極小的空間存儲盡量多的數據,根據對象的狀態(無鎖、偏向鎖、輕量級鎖等)復用自己的存儲空間; -
Mark Word 的鎖標記結構
// 32 bits: // -------- // hash:25 ------------>| age:4 biased_lock:1 lock:2 (normal object) // JavaThread*:23 epoch:2 age:4 biased_lock:1 lock:2 (biased object) // size:32 ------------------------------------------>| (CMS free block) // PromotedObject*:29 ---------->| promo_bits:3 ----->| (CMS promoted object) // // 64 bits: // -------- // unused:25 hash:31 -->| unused:1 age:4 biased_lock:1 lock:2 (normal object) // JavaThread*:54 epoch:2 unused:1 age:4 biased_lock:1 lock:2 (biased object) // PromotedObject*:61 --------------------->| promo_bits:3 ----->| (CMS promoted object) // size:64 ----------------------------------------------------->| (CMS free block) // // unused:25 hash:31 -->| cms_free:1 age:4 biased_lock:1 lock:2 (COOPs && normal object) // JavaThread*:54 epoch:2 cms_free:1 age:4 biased_lock:1 lock:2 (COOPs && biased object) // narrowOop:32 unused:24 cms_free:1 unused:4 promo_bits:3 ----->| (COOPs && CMS promoted object) // unused:21 size:35 -->| cms_free:1 unused:7 ------------------>| (COOPs && CMS free block)。。。。。。 // [JavaThread* | epoch | age | 1 | 01] lock is biased toward given thread // [0 | epoch | age | 1 | 01] lock is anonymously biased // // - the two lock bits are used to describe three states: locked/unlocked and monitor. // // [ptr | 00] locked ptr points to real header on stack // [header | 0 | 01] unlocked regular object header // [ptr | 10] monitor inflated lock (header is wapped out) // [ptr | 11] marked used by markSweep to mark an object // not valid at any other time -
32 位 JVM 下的對象結構描述
-
64 位 JVM 下的對象結構描述
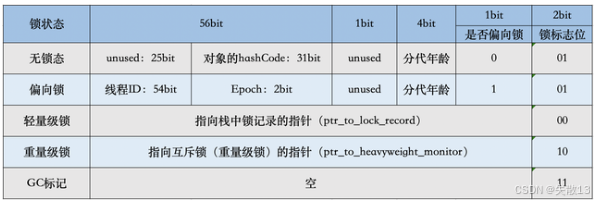
- 哈希碼(hash):對象的唯一標識,延遲計算(調用
System.identityHashCode時才生成);
- 哈希碼(hash):對象的唯一標識,延遲計算(調用
-
分代年齡(age):保存對象的分代年齡。表示對象被GC的次數,當該次數到達閾值的時候,對象就會轉移到老年代;
- 偏向鎖標識位(biased_lock):由于無鎖和偏向鎖的鎖標識都是 01,沒辦法區分,這里引入一位的偏向鎖標識位;
-
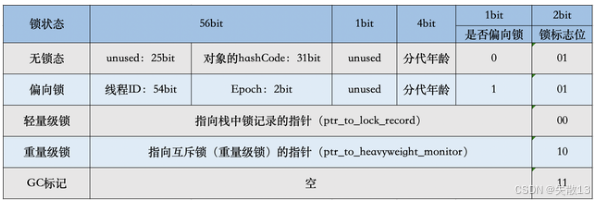
鎖標志位(lock):區分鎖狀態(01=無鎖/偏向鎖,00=輕量級鎖,10=重量級鎖);
- 線程 ID(JavaThread):保存持有偏向鎖的線程ID。當使用偏向鎖且某個線程持有鎖對象的時候,該鎖對象就會被置為該線程的ID。 在后面的操作中,就無需再進行嘗試獲取鎖的動作,避免頻繁 CAS。這個線程ID并不是JVM分配的線程ID號,和 Java Thread 中的ID是兩個概念;
-
Epoch:偏向鎖撤銷的計數器,可用于偏向鎖批量重偏向和批量撤銷的判斷依據;
- ptr_to_lock_record:輕量級鎖狀態下,指向棧中鎖記錄的指針。當鎖獲取是無競爭時,JVM使用原子操作而不是OS互斥,這種技術稱為輕量級鎖定。在輕量級鎖定的情況下,JVM通過CAS操作在對象的Mark Word中設置指向鎖記錄的指針;
-
ptr_to_heavyweight_monitor:重量級鎖狀態下,指向對象監視器 Monitor 的指針。如果兩個不同的線程同時在同一個對象上競爭,則必須將輕量級鎖定升級到 Monitor 以管理等待的線程。在重量級鎖定的情況下,JVM在對象的
ptr_to_heavyweight_monitor設置指向 Monitor 的指針; -
鎖升級流程(偏向鎖 → 輕量級鎖 → 重量級鎖)
-
偏向鎖(Biased Locking)
- 適用場景:單線程重復加鎖,無競爭;
- 加鎖:JVM 檢測到鎖未被偏向 → 用 CAS 將 Mark Word 的“線程 ID”標記為當前線程,鎖標志位為
01(偏向模式); - 解鎖:無需操作(因為無競爭,直接復用);
-
輕量級鎖(Lightweight Locking)
-
觸發條件:出現線程競爭(比如另一個線程嘗試加鎖);
-
加鎖:競爭線程在棧中創建“鎖記錄(Lock Record)”,用 CAS 將 Mark Word 指向自己的鎖記錄,鎖標志位改為
00; -
解鎖:用 CAS 將 Mark Word 恢復為無鎖狀態;若失敗,說明有競爭,升級為重量級鎖;
-
-
重量級鎖(Heavyweight Locking)
-
觸發條件:輕量級鎖 CAS 失敗(競爭激烈),或線程調用
wait()/notify(); -
加鎖:Mark Word 指向
ObjectMonitor(監視器對象),鎖標志位改為10;競爭線程進入ObjectMonitor的阻塞隊列; -
解鎖:喚醒阻塞隊列中的線程,重新競爭鎖;、
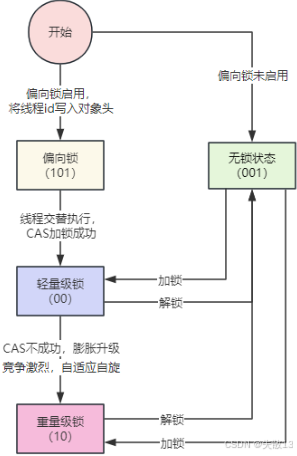
-
-
-
鎖升級的決策邏輯
-
偏向鎖 → 輕量級鎖:當有其他線程競爭鎖時,JVM 嘗試用 CAS 升級為輕量級鎖;若 CAS 失敗(競爭激烈),直接升級為重量級鎖;
-
輕量級鎖 → 重量級鎖:輕量級鎖解鎖時,若發現 Mark Word 已被修改(有其他線程競爭),則升級為重量級鎖,進入阻塞隊列。
-
2.6.1.5 代碼演示鎖升級的過程
import org.openjdk.jol.info.ClassLayout;public class LockUpgrade {public static void main(String[] args) throws InterruptedException {// 創建User對象,初始狀態為無鎖User userTemp = new User();// 打印無鎖狀態的對象布局:Mark Word最后3位為001(無鎖標志)// 此時對象頭存儲哈希碼、GC分代年齡等信息,無線程相關標記System.out.println("無鎖狀態(001):"+ ClassLayout.parseInstance(userTemp).toPrintable());/* * JVM默認延遲4秒開啟偏向鎖機制(避免啟動時的競爭影響偏向鎖效率)* 可通過-XX:BiasedLockingStartupDelay=0參數取消延遲* 若要禁用偏向鎖,使用-XX:-UseBiasedLocking=false*/Thread.sleep(5000); // 等待偏向鎖機制啟用// 新創建對象,此時偏向鎖機制已啟用,對象初始狀態為"可偏向"User user = new User();// 打印可偏向狀態的對象布局:Mark Word最后3位為101(偏向鎖標志,未關聯線程)// 此時對象頭存儲偏向鎖相關標記(如epoch),但未記錄線程IDSystem.out.println("啟用偏向鎖(101):"+ ClassLayout.parseInstance(user).toPrintable());// 主線程兩次獲取并釋放偏向鎖,驗證偏向鎖特性for(int i=0;i<2;i++){// 第一次進入同步塊:主線程獲取偏向鎖// JVM通過CAS將對象頭的線程ID標記為主線程IDsynchronized (user){// 打印偏向鎖狀態:Mark Word最后3位101,且記錄了當前線程ID// 偏向鎖重入時無需CAS,直接復用鎖System.out.println("偏向鎖(101)(帶線程id):"+ ClassLayout.parseInstance(user).toPrintable());}// 偏向鎖釋放后不會清除線程ID標記(這是偏向鎖的特性)// 下次同一線程獲取時無需重新CAS,直接驗證線程ID即可System.out.println("偏向鎖釋放(101)(帶線程id):"+ ClassLayout.parseInstance(user).toPrintable());}// 創建線程1,觸發偏向鎖撤銷與輕量級鎖升級new Thread(new Runnable() {@Overridepublic void run() {// 線程1嘗試獲取已偏向主線程的鎖,觸發偏向鎖撤銷// 撤銷后升級為輕量級鎖:通過CAS將Mark Word指向線程1的鎖記錄synchronized (user){// 打印輕量級鎖狀態:Mark Word最后2位為00(輕量級鎖標志)// 此時對象頭存儲指向線程棧中鎖記錄的指針System.out.println("輕量級鎖(00):"+ ClassLayout.parseInstance(user).toPrintable());try {System.out.println("睡眠3秒========================");Thread.sleep(3000); // 保持鎖3秒,讓線程2有機會競爭} catch (InterruptedException e) {throw new RuntimeException(e);}// 線程2此時已嘗試競爭鎖,輕量級鎖CAS失敗,升級為重量級鎖// 重量級鎖標志為10,對象頭存儲指向ObjectMonitor的指針System.out.println("輕量級鎖--->重量級鎖(10):"+ ClassLayout.parseInstance(user).toPrintable());}}}).start();// 等待1秒,確保線程1已獲取輕量級鎖并進入睡眠Thread.sleep(1000);// 此時線程1持有鎖,主線程觀察到對象已升級為重量級鎖System.out.println("重量級鎖(10):" + ClassLayout.parseInstance(user).toPrintable());// 創建線程2,加劇鎖競爭,鞏固重量級鎖狀態new Thread(new Runnable() {@Overridepublic void run() {// 線程2競爭重量級鎖,進入ObjectMonitor的阻塞隊列synchronized (user) {// 成功獲取重量級鎖后,對象頭仍保持10標志System.out.println("重量級鎖(10):" + ClassLayout.parseInstance(user).toPrintable());}}}).start();// 等待5秒,確保所有線程執行完畢,鎖被釋放Thread.sleep(5000);// 重量級鎖釋放后不會自動降級為輕量級鎖或偏向鎖(鎖升級是單向的)// 此處打印的"無鎖狀態"僅為演示,實際重量級鎖釋放后仍可能保留monitor指針System.out.println("無鎖狀態(001):" + ClassLayout.parseInstance(user).toPrintable());}// 定義簡單的User類作為鎖對象static class User {}
}
- 代碼核心邏輯:
- 無鎖狀態:新創建的對象默認處于無鎖狀態,Mark Word 最后 3 位為
001,存儲對象哈希碼、GC 分代年齡等信息,無任何線程標記; - 偏向鎖啟用:等待 5 秒后(JVM 默認的偏向鎖延遲),新創建的對象進入"可偏向" 狀態(標志位
101),此時對象頭已準備好記錄偏向的線程 ID,但尚未關聯任何線程; - 偏向鎖獲取與釋放:
- 主線程第一次獲取鎖時,JVM 通過 CAS 將對象頭的線程 ID 標記為主線程 ID,標志位保持
101; - 偏向鎖釋放時不會清除線程 ID,下次同一線程獲取時無需重新 CAS,直接復用(體現偏向鎖 “偏向” 特性);
- 主線程第一次獲取鎖時,JVM 通過 CAS 將對象頭的線程 ID 標記為主線程 ID,標志位保持
- 偏向鎖→輕量級鎖升級:線程 1 嘗試獲取已偏向主線程的鎖,觸發偏向鎖撤銷(因為出現競爭),鎖升級為輕量級鎖(標志位
00),此時對象頭存儲指向線程 1 棧中鎖記錄的指針; - 輕量級鎖→重量級鎖升級:線程 1 持有輕量級鎖時,線程 2 嘗試競爭,導致輕量級鎖 CAS 操作失敗。由于競爭激烈,鎖升級為重量級鎖(標志位
10),對象頭轉而存儲指向ObjectMonitor的指針,線程進入阻塞隊列等待; - 鎖升級的單向性:重量級鎖釋放后不會自動降級為輕量級鎖或偏向鎖,這是 JVM 設計的簡化策略(降級成本高于收益)。
- 無鎖狀態:新創建的對象默認處于無鎖狀態,Mark Word 最后 3 位為
2.6.1.4 思考題
-
問:重量級鎖釋放之后變為無鎖,此時有新的線程來調用同步塊,會獲取什么鎖?答:輕量鎖;
-
按照無鎖 -> 偏向鎖 -> 輕量鎖 -> 重量鎖的流程,那不應該加的是偏向鎖嗎?為什么是輕量鎖?
- 原因:因為偏向鎖在大多數現代應用中帶來的收益已經不如其維護成本,自JDK 15起,偏向鎖被默認禁用了;
-
偏向鎖的設計初衷與問題
- 初衷:在“鎖大多情況下不僅不存在競爭,而且總是由同一線程持有”的場景下,為了避免同一線程重復執行CAS操作(輕量級鎖的加鎖解鎖流程),引入了偏向鎖。一旦線程獲得了偏向鎖,后續再進入同步塊只需要簡單檢查一下線程ID即可,開銷極小;
- 問題:
- 維護成本高:偏向鎖的撤銷(Revoke)過程需要進入安全點(SafePoint),這意味著需要暫停所有用戶線程(STW),這個操作是非常昂貴的;
- 收益下降:隨著并發編程的發展和開發者對線程安全意識的提高,很多JDK自身的核心類庫(如
StringBuffer,HashTable等)已經不再作為共享資源被頻繁使用,真正的“無競爭”場景并沒有想象中那么多。在很多高性能應用中,鎖要么是無競爭的輕量級鎖,要么是競爭激烈的重量級鎖,那種“一開始無競爭后來有競爭”的場景,反而觸發了昂貴的偏向鎖撤銷流程,得不償失;
-
由于上述原因,Oracle公司決定逐步棄用并最終默認禁用偏向鎖。
-
JDK 15 開始,偏向鎖被默認禁用。同時,相關的命令行選項(如
-XX:+UseBiasedLocking)被標記為“廢棄”。 -
即使是在JDK 15之前,很多基于大量線程的應用程序(如Web服務器、微服務)也會通過顯式添加JVM參數
-XX:-UseBiasedLocking來主動關閉偏向鎖,以消除撤銷偏向鎖帶來的STW開銷,獲得更穩定的性能表現。
-
-
由于偏向鎖被默認禁用,現在(以JDK 17/21等LTS版本為例)的加鎖流程實際上是:無鎖 -> 輕量級鎖 -> (如果需要) -> 重量級鎖。所以,在思考題的場景中:
- 鎖被釋放后,狀態變為“無鎖”;
- 新的線程來加鎖時,JVM看到偏向鎖是禁用的,因此直接跳過偏向鎖的流程;
- 它嘗試使用CAS操作來獲取輕量級鎖(在自己的棧幀中創建鎖記錄,嘗試替換Mark Word等);
- 如果CAS成功(無競爭),則持有輕量級鎖;
- 如果CAS失敗(有競爭),則立即膨脹為重量級鎖。
2.6.2 輕量級鎖詳解
-
輕量級鎖所適應的場景是線程交替執行同步塊的場合,如果存在同一時間多個線程訪問同一把鎖的場合,就會導致輕量級鎖膨脹為重量級鎖;
-
思考: 輕量級鎖是否可以降級為偏向鎖?答:不能。原因:鎖升級是單向不可逆 的:
-
偏向鎖 → 輕量級鎖 → 重量級鎖(一旦升級,無法自動降級);
-
輕量級鎖的設計目標是“處理低競爭但比偏向鎖稍激烈的場景”,偏向鎖則針對“單線程無競爭”場景;
-
若允許降級,需要額外的狀態回退邏輯,復雜度高且收益低(JVM 選擇簡化設計);
-
-
在介紹輕量級鎖的原理之前,再看看之前 MarkWord 圖:輕量級鎖操作的就是對象頭的 MarkWord
-
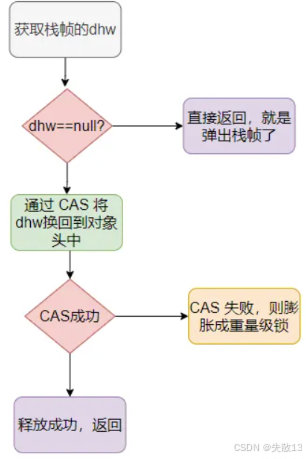
加鎖過程:
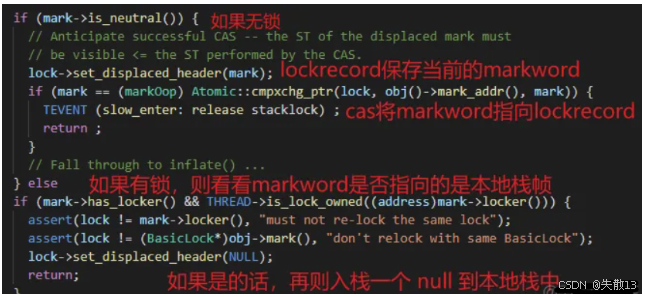
-
如果判斷出當前處于無鎖狀態,線程會在棧中創建一個名叫 **LockRecord(鎖記錄)**的區域,然后把鎖對象的 MarkWord 拷貝一份到 LockRecord 中,該副本稱之為
dhw; -
然后用 CAS 操作,嘗試將鎖對象的 Mark Word 指向當前線程的 LockRecord:
- 成功:加鎖完成(輕量級鎖狀態,Mark Word 標志位為
00); - 失敗:說明有競爭,直接升級為重量級鎖(標志位為
10);
- 成功:加鎖完成(輕量級鎖狀態,Mark Word 標志位為
-
-
解鎖流程
-
用 CAS 操作,將 LockRecord 中存儲的
dhw寫回鎖對象的 Mark Word; -
判斷 CAS 是否成功:
- 成功:解鎖完成(無競爭);
- 失敗:說明解鎖時已有其他線程競爭 → 觸發鎖膨脹(升級為重量級鎖);
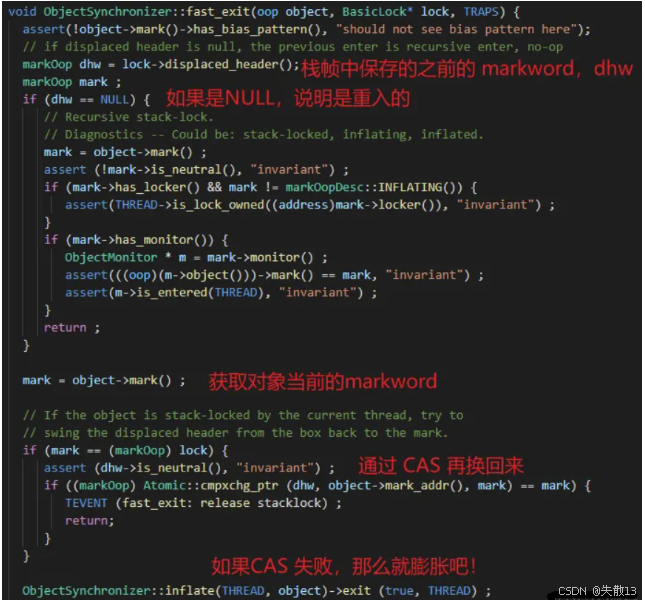
- 如果當前線程已經持有輕量級鎖(重入):
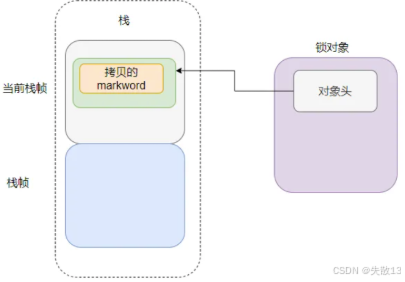
-
加鎖時,將 LockRecord 的
dhw設為null(標記為重入); -
解鎖時,若
dhw為null,直接回退(無需 CAS),避免重復操作;
-
-
2.6.3 偏向鎖詳解
- 偏向鎖是一種針對加鎖操作的優化手段,經過研究發現,在大多數情況下,鎖不僅不存在多線程競爭,而且總是由同一線程多次獲得,因此為了消除數據在無競爭情況下鎖重入(CAS操作)的開銷而引入偏向鎖。對于沒有鎖競爭的場合,偏向鎖有很好的優化效果。
2.6.3.1 偏向鎖匿名偏向狀態
- 當 JVM 啟用了偏向鎖模式(Jdk6 默認開啟),新創建的對象在 4 秒后、未被任何線程獲取時,處于匿名偏向狀態(Anonymously Biased):
- Mark Word 中的
Thread ID為0,偏向鎖標志位為 1(鎖標志位01); - 表示可偏向,但還沒偏向任何線程,一旦有線程獲取鎖,會將
Thread ID標記為當前線程。
- Mark Word 中的
2.6.3.2 偏向鎖的“延遲啟用”機制
-
JVM 啟動時(比如加載類、初始化系統類),會大量使用
synchronized,這些鎖通常不會被競爭(單線程執行)。如果直接啟用偏向鎖,JVM 需要為這些對象做偏向鎖標記,反而增加初始化時間。因此,HotSpot 設計了**“4 秒延遲啟用偏向鎖”**的機制:-
啟動后前 4 秒,新創建的對象不啟用偏向鎖(處于無鎖或輕量級鎖狀態);
-
4 秒后,新創建的對象才會開啟偏向鎖模式(可偏向但未偏向線程,即“匿名偏向狀態”);
-
-
控制延遲的參數
-
關閉延遲:
-XX:BiasedLockingStartupDelay=0(讓偏向鎖立即啟用); -
禁用偏向鎖:
-XX:-UseBiasedLocking(完全關閉偏向鎖優化); -
啟用偏向鎖:
-XX:+UseBiasedLocking(默認開啟);
-
-
代碼實驗:跟蹤偏向鎖狀態變化
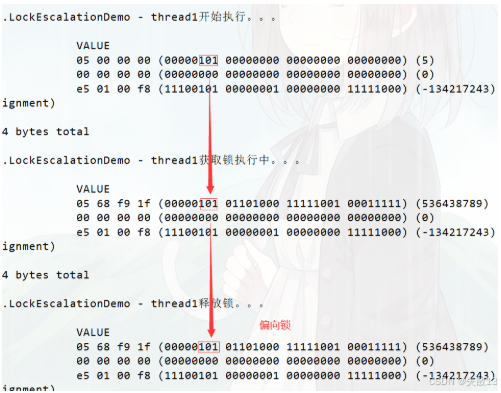
public class LockEscalationDemo {public static void main(String[] args) throws InterruptedException {log.debug(ClassLayout.parseInstance(new Object()).toPrintable());// HotSpot 虛擬機在啟動后有個 4s 的延遲才會對每個新建的對象開啟偏向鎖模式Thread.sleep(4000);// 創建 obj 對象Object obj = new Object();// 創建并啟動thread1來競爭鎖new Thread(new Runnable() {@Overridepublic void run() {log.debug(Thread.currentThread().getName()+"開始執行。。。\n"+ClassLayout.parseInstance(obj).toPrintable());synchronized (obj){log.debug(Thread.currentThread().getName()+"獲取鎖執行中。。。\n"+ClassLayout.parseInstance(obj).toPrintable());}log.debug(Thread.currentThread().getName()+"釋放鎖。。。\n"+ClassLayout.parseInstance(obj).toPrintable());}},"thread1").start();Thread.sleep(5000);log.debug(ClassLayout.parseInstance(obj).toPrintable());} } -
狀態變化流程:
-
線程啟動前(匿名偏向狀態):
obj的 Mark Word 中Thread ID=0,標志位01(匿名偏向); -
線程獲取鎖(偏向鎖生效):
thread1執行synchronized (obj)→ JVM 用 CAS 將Thread ID標記為thread1→ 偏向鎖生效(標志位仍為01,但Thread ID非 0); -
線程釋放鎖(偏向鎖保留):釋放鎖后,
obj的 Mark Word 仍保留thread1的Thread ID(偏向鎖不會自動清除,下次同一線程可直接復用);
-
-
結果解讀:
-
thread1 開始執行:
obj的 Mark Word 中Thread ID=0→ 匿名偏向狀態(4 秒后創建的對象,未被競爭); -
“thread1 獲取鎖執行中”:
Thread ID變為thread1的 ID → 偏向鎖生效(標志位01); -
“thread1 釋放鎖”:
Thread ID仍為thread1的 ID → 偏向鎖保留(下次同一線程可直接獲取,無需 CAS);
-
2.6.3.3 思考題
-
問:如果對象調用了 hashCode,還會開啟偏向鎖模式嗎?
-
答:調用
Object.hashCode()或重寫的hashCode()后,對象的 Mark Word 會存儲哈希碼,這會破壞偏向鎖的狀態,導致偏向鎖無法啟用; -
偏向鎖與哈希碼的沖突:
-
偏向鎖的 Mark Word 存儲:
-
偏向線程 ID、Epoch、分代年齡、鎖標志位(
01); -
沒有預留哈希碼的空間(為了節省內存,復用 Mark Word 區域);
-
-
當對象調用
hashCode()時:-
JVM 會強制計算哈希碼,并將其存儲到 Mark Word(覆蓋原本可能存儲的偏向鎖信息);
-
這會導致偏向鎖的“線程 ID、Epoch”等信息丟失 → 偏向鎖無法啟用(對象不再處于可偏向狀態)。
-
-
2.6.3.4 偏向鎖撤銷場景之調用對象HashCode
-
當鎖對象調用
hashCode()或System.identityHashCode(obj)時,會導致該對象的偏向鎖被撤銷; -
沖突本質:偏向鎖的 Mark Word 沒有預留存儲哈希碼的空間(為了節省內存,復用標記位)
-
當鎖對象調用
hashCode()或System.identityHashCode(obj)時,JVM 必須在 Mark Word 中存儲哈希碼 → 覆蓋偏向鎖的線程 ID、Epoch 等信息; -
這會導致偏向鎖無法維持,觸發鎖撤銷(升級為輕量級鎖或重量級鎖);
-
-
當對象處于可偏向(也就是線程ID為0)和已偏向的狀態下,調用 HashCode 計算將會使對象再也無法偏向:
- 對象處于“可偏向”狀態(線程 ID=0 ):調用
hashCode()→ Mark Word 存儲哈希碼 → 鎖狀態變為無鎖(但存儲了哈希碼),后續無法再進入偏向鎖;
- 對象處于“可偏向”狀態(線程 ID=0 ):調用
-
對象處于“已偏向”狀態(線程 ID≠0 ):調用
hashCode()→ 觸發偏向鎖撤銷 → 升級為輕量級鎖(在棧中創建 LockRecord,存儲哈希碼)。
2.6.3.5 偏向鎖撤銷場景之調用wait/notify
-
偏向鎖狀態執行
obj.notify()會升級為輕量級鎖,調用obj.wait(timeout)會升級為重量級鎖-
wait和notify是 Object 的 native 方法,依賴ObjectMonitor(重量級鎖的實現); -
偏向鎖的 Mark Word 不包含
ObjectMonitor的指針 → 調用wait/notify時,必須升級為重量級鎖(才能關聯ObjectMonitor);
-
-
具體行為
- 調用
notify():偏向鎖狀態下調用obj.notify()→ 觸發偏向鎖撤銷 → 升級為輕量級鎖(因為notify不需要阻塞,但需要關聯ObjectMonitor的等待隊列);
- 調用
-
調用
wait(timeout):偏向鎖狀態下調用obj.wait(100)→ 觸發偏向鎖撤銷 → 直接升級為重量級鎖(因為wait會讓線程進入阻塞隊列,必須依賴ObjectMonitor)。 -
偏向鎖的設計目標是 “單線程無競爭場景”,一旦遇到以下操作,會觸發撤銷(升級為更重的鎖):
- 調用
hashCode()(需要存儲哈希碼,破壞偏向鎖布局); - 調用
wait/notify(需要關聯ObjectMonitor,依賴重量級鎖); - 出現多線程競爭(其他線程嘗試獲取偏向鎖)。
- 調用
2.6.3.6 偏向鎖批量重偏向&批量撤銷
-
偏向鎖的痛點:當多線程競爭偏向鎖時,每次撤銷偏向鎖需要等到
safe point(安全點,JVM 暫停線程的時機),并升級為輕量級鎖或重量級鎖 → 頻繁撤銷會消耗性能,甚至讓偏向鎖從“優化”變成“負優化”,于是就有了了批量重偏向與批量撤銷的機制; -
實現原理
- 以**
Class為單位**,為每個class維護一個偏向鎖撤銷計數器,每一次該class的對象發生偏向撤銷操作時,該計數器+1。統計偏向鎖撤銷次數,當次數達到批量重偏向閾值(默認 20)時:JVM就認為該class的偏向鎖有問題,因此會進行批量重偏向; - 當達到批量重偏向閾值后,假設該
class計數器繼續增長,當其達到批量撤銷閾值(默認 40)后,JVM 就認為該class的使用場景存在多線程競爭,會標記該class為不可偏向,之后,對于該class的鎖,直接走輕量級鎖的邏輯;
- 以**
-
關鍵參數
-
BiasedLockingBulkRebiasThreshold:批量重偏向閾值(默認 20); -
BiasedLockingBulkRevokeThreshold:批量撤銷閾值(默認 40); -
可通過 JVM 參數調整:
-XX:BiasedLockingBulkRebiasThreshold和-XX:BiasedLockingBulkRevokeThreshold;
-
-
應用場景
-
批量重偏向(Bulk Rebias)
-
適用場景:一個線程創建大量對象并執行同步操作(對象偏向該線程),后續另一個線程也競爭這些對象的鎖 → 大量偏向鎖需要撤銷;
-
作用:通過“批量重偏向”,讓新競爭的線程成為對象的偏向線程 → 避免逐個對象撤銷偏向鎖,減少性能開銷;
-
-
批量撤銷(Bulk Revoke)
-
適用場景:多線程競爭激烈,即使重偏向也無法緩解 → 偏向鎖頻繁撤銷,性能下降;
-
作用:標記
Class為“不可偏向”,后續對象直接走輕量級鎖 → 避免偏向鎖的額外開銷;
-
-
-
補充:
-
批量重偏向和批量撤銷是針對類的優化,和對象無關
- 批量重偏向、批量撤銷的觸發與決策,是以
Class(類) 為單位進行的,而非單個對象;- JVM 會為每個類維護偏向鎖撤銷計數器,統計該類所有對象的撤銷行為;
- 當計數器達到閾值(重偏向或批量撤銷閾值),JVM 會對整個類的后續對象調整鎖策略,而不是針對某一個對象單獨處理;
- 批量重偏向、批量撤銷的觸發與決策,是以
-
例:假設
Order.class有 100 個對象,其中 20 個對象因線程競爭觸發偏向鎖撤銷 → JVM 統計到Order類的撤銷次數達閾值,會對所有新創建的Order對象執行批量重偏向或撤銷,影響的是整個類的行為;
-
-
偏向鎖重偏向一次之后不可再次重偏向
-
批量重偏向是一次性的調整:當某個類觸發批量重偏向(撤銷次數達重偏向閾值),JVM 會讓該類新創建的對象偏向當前競爭的線程,但后續不會再次觸發“批量重偏向”;
-
設計意圖:避免無限重偏向導致鎖策略“反復橫跳”,增加復雜度。若后續仍有新線程競爭,直接進入“批量撤銷”流程(若達到撤銷閾值),讓鎖策略向“輕量級鎖”過渡,簡化邏輯;
-
流程示例:
User類觸發批量重偏向 → 新User對象偏向線程 B;
-
若線程 C 又競爭
User對象 → 不會再次重偏向,而是統計撤銷次數,達閾值則觸發批量撤銷;
-
-
當某個類已經觸發批量撤銷機制后,JVM會默認當前類產生了嚴重的問題,剝奪了該類的新實例對象使用偏向鎖的權利
-
觸發后果:批量撤銷是 JVM 應對“持續激烈競爭”的終極手段:一旦某個類觸發批量撤銷(撤銷次數達批量撤銷閾值),JVM 判定該類的使用場景不適合偏向鎖(多線程競爭頻繁);
-
后續行為:該類新創建的對象會直接跳過“偏向鎖”階段,默認使用輕量級鎖(或更高階的鎖策略),避免因偏向鎖的頻繁撤銷帶來額外開銷;
-
實際影響:比如
Product類觸發批量撤銷后,所有新Product對象不再嘗試偏向鎖,同步塊直接以輕量級鎖邏輯執行,犧牲“偏向鎖的輕量優勢”換取“競爭場景下的穩定性”。
-
-
附錄:JVM指令集
指令碼 助記符 說明
0x00 nop 什么都不做
0x01 aconst_null 將null推送至棧頂
0x02 iconst_m1 將int型-1推送至棧頂
0x03 iconst_0 將int型0推送至棧頂
0x04 iconst_1 將int型1推送至棧頂
0x05 iconst_2 將int型2推送至棧頂
0x06 iconst_3 將int型3推送至棧頂
0x07 iconst_4 將int型4推送至棧頂
0x08 iconst_5 將int型5推送至棧頂
0x09 lconst_0 將long型0推送至棧頂
0x0a lconst_1 將long型1推送至棧頂
0x0b fconst_0 將float型0推送至棧頂
0x0c fconst_1 將float型1推送至棧頂
0x0d fconst_2 將float型2推送至棧頂
0x0e dconst_0 將double型0推送至棧頂
0x0f dconst_1 將double型1推送至棧頂
0x10 bipush 將單字節的常量值(-128~127)推送至棧頂
0x11 sipush 將一個短整型常量值(-32768~32767)推送至棧頂
0x12 ldc 將int, float或String型常量值從常量池中推送至棧頂
0x13 ldc_w 將int, float或String型常量值從常量池中推送至棧頂(寬索引)
0x14 ldc2_w 將long或double型常量值從常量池中推送至棧頂(寬索引)
0x15 iload 將指定的int型本地變量推送至棧頂
0x16 lload 將指定的long型本地變量推送至棧頂
0x17 fload 將指定的float型本地變量推送至棧頂
0x18 dload 將指定的double型本地變量推送至棧頂
0x19 aload 將指定的引用類型本地變量推送至棧頂
0x1a iload_0 將第一個int型本地變量推送至棧頂
0x1b iload_1 將第二個int型本地變量推送至棧頂
0x1c iload_2 將第三個int型本地變量推送至棧頂
0x1d iload_3 將第四個int型本地變量推送至棧頂
0x1e lload_0 將第一個long型本地變量推送至棧頂
0x1f lload_1 將第二個long型本地變量推送至棧頂
0x20 lload_2 將第三個long型本地變量推送至棧頂
0x21 lload_3 將第四個long型本地變量推送至棧頂
0x22 fload_0 將第一個float型本地變量推送至棧頂
0x23 fload_1 將第二個float型本地變量推送至棧頂
0x24 fload_2 將第三個float型本地變量推送至棧頂
0x25 fload_3 將第四個float型本地變量推送至棧頂
0x26 dload_0 將第一個double型本地變量推送至棧頂
0x27 dload_1 將第二個double型本地變量推送至棧頂
0x28 dload_2 將第三個double型本地變量推送至棧頂
0x29 dload_3 將第四個double型本地變量推送至棧頂
0x2a aload_0 將第一個引用類型本地變量推送至棧頂
0x2b aload_1 將第二個引用類型本地變量推送至棧頂
0x2c aload_2 將第三個引用類型本地變量推送至棧頂
0x2d aload_3 將第四個引用類型本地變量推送至棧頂
0x2e iaload 將int型數組指定索引的值推送至棧頂
0x2f laload 將long型數組指定索引的值推送至棧頂
0x30 faload 將float型數組指定索引的值推送至棧頂
0x31 daload 將double型數組指定索引的值推送至棧頂
0x32 aaload 將引用型數組指定索引的值推送至棧頂
0x33 baload 將boolean或byte型數組指定索引的值推送至棧頂
0x34 caload 將char型數組指定索引的值推送至棧頂
0x35 saload 將short型數組指定索引的值推送至棧頂
0x36 istore 將棧頂int型數值存入指定本地變量
0x37 lstore 將棧頂long型數值存入指定本地變量
0x38 fstore 將棧頂float型數值存入指定本地變量
0x39 dstore 將棧頂double型數值存入指定本地變量
0x3a astore 將棧頂引用型數值存入指定本地變量
0x3b istore_0 將棧頂int型數值存入第一個本地變量
0x3c istore_1 將棧頂int型數值存入第二個本地變量
0x3d istore_2 將棧頂int型數值存入第三個本地變量
0x3e istore_3 將棧頂int型數值存入第四個本地變量
0x3f lstore_0 將棧頂long型數值存入第一個本地變量
0x40 lstore_1 將棧頂long型數值存入第二個本地變量
0x41 lstore_2 將棧頂long型數值存入第三個本地變量
0x42 lstore_3 將棧頂long型數值存入第四個本地變量
0x43 fstore_0 將棧頂float型數值存入第一個本地變量
0x44 fstore_1 將棧頂float型數值存入第二個本地變量
0x45 fstore_2 將棧頂float型數值存入第三個本地變量
0x46 fstore_3 將棧頂float型數值存入第四個本地變量
0x47 dstore_0 將棧頂double型數值存入第一個本地變量
0x48 dstore_1 將棧頂double型數值存入第二個本地變量
0x49 dstore_2 將棧頂double型數值存入第三個本地變量
0x4a dstore_3 將棧頂double型數值存入第四個本地變量
0x4b astore_0 將棧頂引用型數值存入第一個本地變量
0x4c astore_1 將棧頂引用型數值存入第二個本地變量
0x4d astore_2 將棧頂引用型數值存入第三個本地變量
0x4e astore_3 將棧頂引用型數值存入第四個本地變量
0x4f iastore 將棧頂int型數值存入指定數組的指定索引位置
0x50 lastore 將棧頂long型數值存入指定數組的指定索引位置
0x51 fastore 將棧頂float型數值存入指定數組的指定索引位置
0x52 dastore 將棧頂double型數值存入指定數組的指定索引位置
0x53 aastore 將棧頂引用型數值存入指定數組的指定索引位置
0x54 bastore 將棧頂boolean或byte型數值存入指定數組的指定索引位置
0x55 castore 將棧頂char型數值存入指定數組的指定索引位置
0x56 sastore 將棧頂short型數值存入指定數組的指定索引位置
0x57 pop 將棧頂數值彈出 (數值不能是long或double類型的)
0x58 pop2 將棧頂的一個(long或double類型的)或兩個數值彈出(其它)
0x59 dup 復制棧頂數值并將復制值壓入棧頂
0x5a dup_x1 復制棧頂數值并將兩個復制值壓入棧頂
0x5b dup_x2 復制棧頂數值并將三個(或兩個)復制值壓入棧頂
0x5c dup2 復制棧頂一個(long或double類型的)或兩個(其它)數值并將復制值壓入棧頂
0x5d dup2_x1 <待補充>
0x5e dup2_x2 <待補充>
0x5f swap 將棧最頂端的兩個數值互換(數值不能是long或double類型的)
0x60 iadd 將棧頂兩int型數值相加并將結果壓入棧頂
0x61 ladd 將棧頂兩long型數值相加并將結果壓入棧頂
0x62 fadd 將棧頂兩float型數值相加并將結果壓入棧頂
0x63 dadd 將棧頂兩double型數值相加并將結果壓入棧頂
0x64 isub 將棧頂兩int型數值相減并將結果壓入棧頂
0x65 lsub 將棧頂兩long型數值相減并將結果壓入棧頂
0x66 fsub 將棧頂兩float型數值相減并將結果壓入棧頂
0x67 dsub 將棧頂兩double型數值相減并將結果壓入棧頂
0x68 imul 將棧頂兩int型數值相乘并將結果壓入棧頂
0x69 lmul 將棧頂兩long型數值相乘并將結果壓入棧頂
0x6a fmul 將棧頂兩float型數值相乘并將結果壓入棧頂
0x6b dmul 將棧頂兩double型數值相乘并將結果壓入棧頂
0x6c idiv 將棧頂兩int型數值相除并將結果壓入棧頂
0x6d ldiv 將棧頂兩long型數值相除并將結果壓入棧頂
0x6e fdiv 將棧頂兩float型數值相除并將結果壓入棧頂
0x6f ddiv 將棧頂兩double型數值相除并將結果壓入棧頂
0x70 irem 將棧頂兩int型數值作取模運算并將結果壓入棧頂
0x71 lrem 將棧頂兩long型數值作取模運算并將結果壓入棧頂
0x72 frem 將棧頂兩float型數值作取模運算并將結果壓入棧頂
0x73 drem 將棧頂兩double型數值作取模運算并將結果壓入棧頂
0x74 ineg 將棧頂int型數值取負并將結果壓入棧頂
0x75 lneg 將棧頂long型數值取負并將結果壓入棧頂
0x76 fneg 將棧頂float型數值取負并將結果壓入棧頂
0x77 dneg 將棧頂double型數值取負并將結果壓入棧頂
0x78 ishl 將int型數值左移位指定位數并將結果壓入棧頂
0x79 lshl 將long型數值左移位指定位數并將結果壓入棧頂
0x7a ishr 將int型數值右(符號)移位指定位數并將結果壓入棧頂
0x7b lshr 將long型數值右(符號)移位指定位數并將結果壓入棧頂
0x7c iushr 將int型數值右(無符號)移位指定位數并將結果壓入棧頂
0x7d lushr 將long型數值右(無符號)移位指定位數并將結果壓入棧頂
0x7e iand 將棧頂兩int型數值作“按位與”并將結果壓入棧頂
0x7f land 將棧頂兩long型數值作“按位與”并將結果壓入棧頂
0x80 ior 將棧頂兩int型數值作“按位或”并將結果壓入棧頂
0x81 lor 將棧頂兩long型數值作“按位或”并將結果壓入棧頂
0x82 ixor 將棧頂兩int型數值作“按位異或”并將結果壓入棧頂
0x83 lxor 將棧頂兩long型數值作“按位異或”并將結果壓入棧頂
0x84 iinc 將指定int型變量增加指定值(i++, i--, i+=2)
0x85 i2l 將棧頂int型數值強制轉換成long型數值并將結果壓入棧頂
0x86 i2f 將棧頂int型數值強制轉換成float型數值并將結果壓入棧頂
0x87 i2d 將棧頂int型數值強制轉換成double型數值并將結果壓入棧頂
0x88 l2i 將棧頂long型數值強制轉換成int型數值并將結果壓入棧頂
0x89 l2f 將棧頂long型數值強制轉換成float型數值并將結果壓入棧頂
0x8a l2d 將棧頂long型數值強制轉換成double型數值并將結果壓入棧頂
0x8b f2i 將棧頂float型數值強制轉換成int型數值并將結果壓入棧頂
0x8c f2l 將棧頂float型數值強制轉換成long型數值并將結果壓入棧頂
0x8d f2d 將棧頂float型數值強制轉換成double型數值并將結果壓入棧頂
0x8e d2i 將棧頂double型數值強制轉換成int型數值并將結果壓入棧頂
0x8f d2l 將棧頂double型數值強制轉換成long型數值并將結果壓入棧頂
0x90 d2f 將棧頂double型數值強制轉換成float型數值并將結果壓入棧頂
0x91 i2b 將棧頂int型數值強制轉換成byte型數值并將結果壓入棧頂
0x92 i2c 將棧頂int型數值強制轉換成char型數值并將結果壓入棧頂
0x93 i2s 將棧頂int型數值強制轉換成short型數值并將結果壓入棧頂
0x94 lcmp 比較棧頂兩long型數值大小,并將結果(1,0,-1)壓入棧頂
0x95 fcmpl 比較棧頂兩float型數值大小,并將結果(1,0,-1)壓入棧頂;當其中一個數值為NaN時,將-1壓入棧頂
0x96 fcmpg 比較棧頂兩float型數值大小,并將結果(1,0,-1)壓入棧頂;當其中一個數值為NaN時,將1壓入棧頂
0x97 dcmpl 比較棧頂兩double型數值大小,并將結果(1,0,-1)壓入棧頂;當其中一個數值為NaN時,將-1壓入棧頂
0x98 dcmpg 比較棧頂兩double型數值大小,并將結果(1,0,-1)壓入棧頂;當其中一個數值為NaN時,將1壓入棧頂
0x99 ifeq 當棧頂int型數值等于0時跳轉
0x9a ifne 當棧頂int型數值不等于0時跳轉
0x9b iflt 當棧頂int型數值小于0時跳轉
0x9c ifge 當棧頂int型數值大于等于0時跳轉
0x9d ifgt 當棧頂int型數值大于0時跳轉
0x9e ifle 當棧頂int型數值小于等于0時跳轉
0x9f if_icmpeq 比較棧頂兩int型數值大小,當結果等于0時跳轉
0xa0 if_icmpne 比較棧頂兩int型數值大小,當結果不等于0時跳轉
0xa1 if_icmplt 比較棧頂兩int型數值大小,當結果小于0時跳轉
0xa2 if_icmpge 比較棧頂兩int型數值大小,當結果大于等于0時跳轉
0xa3 if_icmpgt 比較棧頂兩int型數值大小,當結果大于0時跳轉
0xa4 if_icmple 比較棧頂兩int型數值大小,當結果小于等于0時跳轉
0xa5 if_acmpeq 比較棧頂兩引用型數值,當結果相等時跳轉
0xa6 if_acmpne 比較棧頂兩引用型數值,當結果不相等時跳轉
0xa7 goto 無條件跳轉
0xa8 jsr 跳轉至指定16位offset位置,并將jsr下一條指令地址壓入棧頂
0xa9 ret 返回至本地變量指定的index的指令位置(一般與jsr, jsr_w聯合使用)
0xaa tableswitch 用于switch條件跳轉,case值連續(可變長度指令)
0xab lookupswitch 用于switch條件跳轉,case值不連續(可變長度指令)
0xac ireturn 從當前方法返回int
0xad lreturn 從當前方法返回long
0xae freturn 從當前方法返回float
0xaf dreturn 從當前方法返回double
0xb0 areturn 從當前方法返回對象引用
0xb1 return 從當前方法返回void
0xb2 getstatic 獲取指定類的靜態域,并將其值壓入棧頂
0xb3 putstatic 為指定的類的靜態域賦值
0xb4 getfield 獲取指定類的實例域,并將其值壓入棧頂
0xb5 putfield 為指定的類的實例域賦值
0xb6 invokevirtual 調用實例方法
0xb7 invokespecial 調用超類構造方法,實例初始化方法,私有方法
0xb8 invokestatic 調用靜態方法
0xb9 invokeinterface 調用接口方法
0xba --
0xbb new 創建一個對象,并將其引用值壓入棧頂
0xbc newarray 創建一個指定原始類型(如int, float, char…)的數組,并將其引用值壓入棧頂
0xbd anewarray 創建一個引用型(如類,接口,數組)的數組,并將其引用值壓入棧頂
0xbe arraylength 獲得數組的長度值并壓入棧頂
0xbf athrow 將棧頂的異常拋出
0xc0 checkcast 檢驗類型轉換,檢驗未通過將拋出ClassCastException
0xc1 instanceof 檢驗對象是否是指定的類的實例,如果是將1壓入棧頂,否則將0壓入棧頂
0xc2 monitorenter 獲得對象的鎖,用于同步方法或同步塊
0xc3 monitorexit 釋放對象的鎖,用于同步方法或同步塊
0xc4 wide <待補充>
0xc5 multianewarray 創建指定類型和指定維度的多維數組(執行該指令時,操作棧中必須包含各維度的長度值),并將其引用值壓入棧頂
0xc6 ifnull 為null時跳轉
0xc7 ifnonnull 不為null時跳轉
0xc8 goto_w 無條件跳轉(寬索引)
0xc9 jsr_w 跳轉至指定32位offset位置,并將jsr_w下一條指令地址壓入棧頂
(藍橋杯))
![[光學原理與應用-318]:職業 - 光學工程師的技能要求](http://pic.xiahunao.cn/[光學原理與應用-318]:職業 - 光學工程師的技能要求)




中的應用)




)






線程安全和線程不安全 產生的原因 synchronized關鍵字 synchronized可重入特性死鎖 如何避免死鎖 內存可見性)
