目錄
前言
解決思路
需求理解
MCP Server
LangGraph
本教程目標
技術棧
第一部分:構建 MCP Server - 工具服務化的基礎架構
第二部分:Tools 實現
第三部分:基于 LangGraph 構建智能 Agent
第四部分:服務器和前端搭建
前言
差不多今年,"MCP""Agent" 一直都是 AI 領域的熱點,尤其是 manus 的出現,顯得 Agent 好像無所不能,極大的展現了 AI 的思考和執行決策的能力。
AI 不再只是單純地回答問題,而是能夠主動理解任務、規劃步驟、調用工具,并最終完成目標。
但是在控件領域,控件產品基本都有很多 API, 有時候哪怕最熟練的開發者也很難清楚每個 API 的定義.
比如?SpreadJS?:它提供了超過 2000 個 API,功能非常靈活,能夠覆蓋各種復雜場景。但對于開發者來說,光靠人工翻閱文檔或記憶這些 API 顯然效率不高。
如果用 LLM 幫助生成 SpreadJS API 代碼,開發效率肯定會提高,不過,目前市面上常見的 LLM(ChatGPT、DeepSeek、Grok、Gemini ),在 SpreadJS 這種細分領域上能做的事情有限,簡單 API 調用沒什么問題,比如最基礎的 setValue、getValue,但難度一上來它們很容易出現幻覺,生成一些看起來正確實則跑不了的代碼。
比如從數據庫取數據并構建一個儀表盤這種要調用多個 plugin 而且要進行深度使用,考慮 API 聯合工作的結果的復雜需求
如果能通過一些人工投喂的知識,了解 SpreadJS 的一些冷門 API 和準確的使用方式,生成準確的代碼,就可以穩定地提高開發的效率了。
那如何做呢?
解決思路
做類似 "知識庫" 的功能,當 AI 想要知道什么它不懂的東西的時候,就去調用 "知識庫" 來獲取準確的信息,從而降低幻覺,提升代碼準確度.
可以搭建一個?MCP Server?來暴露 SpreadJS 文檔查詢工具,再基于?LangGraph?搭建一個 Agent。該 Agent 能夠自主決定是否查詢文檔,并在生成代碼,執行代碼之后進行結果校驗,確保結果真正滿足用戶需求之后再結束邏輯。
需求理解
我們把 Agent 定義為:
能夠自主理解任務、規劃步驟、使用工具完成目標,并具備多輪對話和記憶能力的 AI 應用。
換句話說,如果一個 AI 能聽懂需求,自行分析步驟,調用工具,并完成多輪消息處理直到完成任務,就可以算作一個 Agent。
在實現上,其實并不復雜,只需要兩條:
- 支持多輪對話的 AI 對話框
- tool call (function call)
就能拼出一個基礎的 Agent 原型。
那么,為什么要額外引入?MCP Server?和?LangGraph?呢?
MCP Server
Model Context Protocol(MCP)是一個 AI 工具調用的標準化協議,最核心的優勢就是打通了不同 tool call 之間的差異,用標準化的協議完成通信,而且跟 Agent 解耦,Agent 只需要通過 getTools 這種接口獲取可用工具列表即可.
因此,我們會把 SpreadJS 文檔查詢封裝成一個獨立的 MCP Server,不與本項目的其他部分耦合。未來即便是別的 AI 項目,也能直接使用這套服務。
當然,MCP 也有其劣勢,例如,提供工具數量太多,AI 會陷入混亂,命名不標準,導致 AI 無法理解等,我們賬號下有文章分析過其中的劣勢,可以自行查找閱讀。整體上來說,MCP 還是一個利大于弊的技術,所以才能被大家廣泛接受。
LangGraph
選擇 LangGraph 的原因在于它是一個 "搭建 Agent 的腳手架",就像我們在前端不會一直用 "原生 JS+HTML+CSS" 寫所有項目,而會選擇 React/Vue 這樣的框架來提升效率一樣,LangGraph 是一個構建 Agent 的框架,可以讓我們用更簡單的方式構建 Agent。
在我們這篇教程中,我們使用的是 Langgraph 的 TypeScript 版本,主要原因是 SpreadJS 主要面向的是前端開發者,對 Typescript 代碼更熟悉,且可以直接在前端運行,如果你對 python 更熟悉,可以用 Langgraph 的 python 包,支持的更好更全面.
本教程目標
構建一個可以理解自然語言并操作 SpreadJS 表格的智能助手,用戶只需輸入類似添加一個表格,范圍為 A1:C4 的需求,AI 即可自主判斷是否需要文檔幫助,是否可以生成代碼,是否已經完成目標,實現用戶的任務。
技術棧
- 后端: TypeScript + LangGraph + MCP Server
- 前端: 原生 HTML/CSS/JavaScript(前端代碼不是我們這次教程的重點,能跑就行)
- 通信: WebSocket(實現實時雙向通信)
- AI: Langchain ChatOpenAI SDK
我們項目設置三個端口:
- 3000 端口:前端服務,網頁
- 3001 端口: Agent 服務,AI
- 3002 端口: MCP Server 服務
第一部分:構建 MCP Server - 工具服務化的基礎架構
MCP Server 實現
首先我們來實現 MCP Server
看看核心代碼:
export class MCPServer {private server: http.Server;constructor() {this.server = this.createHTTPServer();}private createHTTPServer(): http.Server {return http.createServer(async (req, res) => {const parsedUrl = url.parse(req.url!, true);if (req.method === 'GET' && parsedUrl.pathname === '/tools') {res.end(JSON.stringify({success: true,tools: this.getTools()}));} else if (req.method === 'POST' && parsedUrl.pathname === '/execute') {const { toolName, args } = await this.parseBody(req);const result = await this.executeTool(toolName, args);res.end(JSON.stringify({ success: true, result }));}});}
}
這里的設計思路很簡單:getTools 拿工具列表,execute 執行工具,實現了一個 MCP Server 最基礎的功能
核心 API 設計
// 獲取可用工具列表
public getTools() {return Object.entries(toolDefinitions).map(([name, definition]) => ({name,description: definition.description,schemaDescription: definition.schema}));
}// 執行指定的工具
public async executeTool(toolName: string, args: any): Promise<any> {const toolImpl = toolImplementations[toolName];if (!toolImpl) {throw new Error(`Tool ${toolName} not found`);}console.log(`[MCP Server] Executing tool: ${toolName}`);const result = await toolImpl(args);return result;
}
第二部分:Tools 實現
定義與實現分離
我可以在 Agent 里寫工具邏輯,但這樣做有幾個問題,但是我們使用的 MCP 服務不總是自己寫的,所以在教程里,就養成用網絡請求調用 MCP Server 是個好習慣。而且解耦之后,重構成本也更小.
包括工具的定義和實現,也考慮分開,定義用 JSON Schema 就可以了,不需要沾邏輯,在實現上再寫邏輯,這樣不變的定義永遠不用改,邏輯上有 BUG 去改邏輯就行了。
// 工具定義層
export const toolDefinitions: Record<string, ToolDefinition> = {"api-doc-search": {description: "搜索SpreadJS相關的技術文檔和API信息",schema: {type: "object",properties: {keyword: {type: "string",description: "需要搜索SpreadJS如何使用的關鍵詞"}},required: ["keyword"]}}
};// 工具實現層
export const toolImplementations: Record<string, ToolFunction> = {"api-doc-search": async ({ keyword }: { keyword: string }) => {const encodedTopic = encodeURIComponent(keyword);const url = `https://context7.com/api/v1/llmstxt/...`;const res = await fetch(url, { /* 請求配置 */ });const data = await res.json();return processedResults;}
};
我們實現了兩個核心工具:
api-doc-search:基于 Context7 的文檔檢索
"api-doc-search": async ({ keyword }: { keyword: string }) => {const encodedTopic = encodeURIComponent(keyword);const url = `https://context7.com/api/v1/llmstxt/developer_mescius_com-spreadjs-docs-llms.txt?type=json&tokens=100000&topic=${encodedTopic}`;const res = await fetch(url, {method: "GET",headers: {"accept": "*/*","content-type": "application/json",}});const data = await res.json();if (data && data.snippets && Array.isArray(data.snippets)) {return data.snippets.slice(0, 8).map((snippet: any, index: number) => {let content = `**${snippet.codeTitle}**\n\n`;if (snippet.codeDescription) {content += `描述: ${snippet.codeDescription}\n\n`;}if (snippet.codeList && snippet.codeList.length > 0) {content += `代碼示例:\n\`\`\`javascript\n`;content += snippet.codeList[0].code;content += '\n```';}return {id: index + 1,title: snippet.codeTitle,content: content,code: snippet.codeList?.[0]?.code || '',source: snippet.pageTitle};});}
}
這個工具通過 Context7 API 搜索 SpreadJS 文檔,返回結構化的搜索結果。每個結果包含標題、描述、代碼示例等信息,AI 可以基于這些信息生成更準確的代碼。
context7?是一個工具網站,可以通過 llms.txt 構建 RAG 索引,SpreadJS 的 docs 站點提供了 llms.txt, context7 就自動根據 llms.txt 爬取了 SpreadJS 的文檔庫,構建了 RAG 索引,通過 contetx7 搜索就可以拿到文檔中的信息. context7 也提供了一個獨立的 MCP Server, 有興趣可以把它裝到自己的 IDE 里試試.
execute-spreadjs:生成 SpreadJS API 代碼
"execute-spreadjs": async ({ execute_logic, query_logic }: {execute_logic: string;query_logic: string
}) => {console.log(`[Tool Call: execute-SpreadJS] Generating code...`);const responseToFrontend = JSON.stringify({execute: execute_logic,query: query_logic,});return responseToFrontend;
}
這個工具負責生成 SpreadJS 代碼。它接收兩個參數:
- execute_logic:要執行的操作代碼
- query_logic:用于驗證結果的查詢代碼
這個思想其實是很好的,不局限于這個工具,我們寫這種執行邏輯的時候,都可以想到,這種網絡請求式的操作,都可以強制要求返回一個確認操作,即一個 write 操作,一個 read 操作,進行結果校驗,這比單獨寫個 query_spreadjs 的工具再去校驗一次,不就省了很多 token, 請求的時間也省下了嗎.
另外,在 initSpreadJS 的時候,我們把一些變量暴露在了 window 下,這樣 AI 生成的代碼就可以直接 new Function 執行了,但是實際 production 環境,還是要用隔離沙箱去做,不要這樣 hackcode.
工具注冊與對接
在 MCP Server 中,工具的注冊過程很簡單:
public getTools() {return Object.entries(toolDefinitions).map(([name, definition]) => ({name,description: definition.description,schemaDescription: definition.schema}));
}
當 Agent 需要執行工具時:
public async executeTool(toolName: string, args: any): Promise<any> {const toolImpl = toolImplementations[toolName];const result = await toolImpl(args);return result;
}
更好的搜索
如果需要更強的 RAG 檢索效果,可以引入?GC QA RAG, 利用這個 RAG 項目,可以生成 QA 對檢測,可以自己部署,效果很好,可以自己部署一下試試.
只需要替換 api-doc-search 的實現,接口保持不變,Agent 端無需任何修改。
context7 使用的 RAG 技術我不太清楚,但是肯定用的不是 QA 對方案,其實對于查詢來說,用 QA 對 query string 進行向量匹配,效果要比用原文檔對 query string 進行向量匹配肯定要好的多,甚至不需要 reranking 這些步驟.
這些概念對于不了解 RAG 的人可能會稍顯有些費解,如果有興趣可以閱讀一下我們賬號發布的關于 RAG 的一些文章了解.
第三部分:基于 LangGraph 構建智能 Agent
LangGraph 介紹
LangGraph 的核心概念主要有幾個:node、edge 和 state。
可以把它想象成一個狀態機,每個 node 是一個步驟,edge 決定步驟之間怎么流轉,而 state 記錄上下文。這樣一來,就能自然地實現多輪對話和工具調用。?
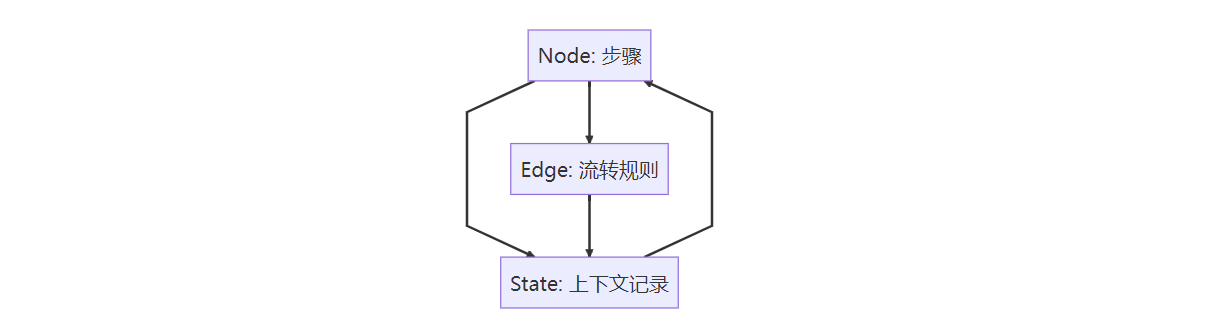
Node、Edge 與 ConditionalEdge
- Node:工作流中的一個步驟,可以是 LLM 調用、工具執行,或者任何異步操作
- Edge:邊 - 固定的流轉路徑,A 節點執行完總是去 B 節點
- ConditionalEdge:條件邊 - 帶條件的流轉路徑,根據運行時狀態決定去哪個節點
Agent 狀態管理
狀態是什么
在 LangGraph 中,state 保存著對話歷史與工具調用結果。對我們來說,messages 是最核心的上下文數據:
type AgentState = {messages: BaseMessage[];
};const workflow = new StateGraph<AgentState>({channels: {messages: {value: (x: BaseMessage[], y: BaseMessage[]) => x.concat(y),default: () => [],}},
});
這里的設計很巧妙:新的 messages 會自動追加到現有 messages 后面,形成完整的對話歷史。這樣 AI 就能記住之前的交互內容。
streamEvents API
streamEvents 是 LangGraph 提供的一個強大功能,讓我們能夠實時監控 Agent 的執行過程。相比只看最終結果,實時過程對用戶體驗來說更重要:
const eventStream = compiledGraph.streamEvents(initialState, {version: "v2" as const,recursionLimit: 10
});for await (const event of eventStream) {switch (event.event) {case 'on_chat_model_stream':// AI 思考的流式輸出if (event.data.chunk?.content) {yield {type: 'agent_message',data: { content: event.data.chunk.content }};}break;case 'on_tool_start':// 工具開始執行yield {type: 'agent_step',data: {step: 'tools',output: { lastToolCall: { name: event.name, args: event.data.input } }}};break;case 'on_tool_end':// 工具執行完成yield {type: 'agent_step',data: {step: 'tools',output: { toolResult: event.data.output }}};break;}
}
LangChain 還推出了一個名為?LangSmith?的工具,它專門用于監控和分析 Agent 的狀態以及工作流執行情況。 雖然我在本教程中沒有使用它,但如果你希望更直觀地觀察 state 變化、事件流和決策路徑,可以把 langsmith 接入項目試試。
Langgraph 工作流設計
我們采用了一個經典的 action-check 模式:
// 節點 1: action - 執行工具調用和LLM推理
workflow.addNode("action", this.actionNode.bind(this));
// 節點 2: check - AI自主決策下一步行動
workflow.addNode("check", this.checkNode.bind(this));// 設置工作流的入口node
workflow.setEntryPoint("action");// action 執行后總是去 check 進行決策
workflow.addEdge("action", "check");// check 節點執行后進行AI自主決策是執行action, 還是結束
workflow.addConditionalEdges("check", async (state: AgentState) => {const decision = await this.aiDecideNextAction(state);if (decision === "__end__") {return "__end__";} else {return "action"; // 繼續執行}
});
在這個 workflow 中,我們設計了 2 個 Node, 2 個 Edge, 并將入口設置為了 action 節點.
我們用一張圖來理解這個 workflow?
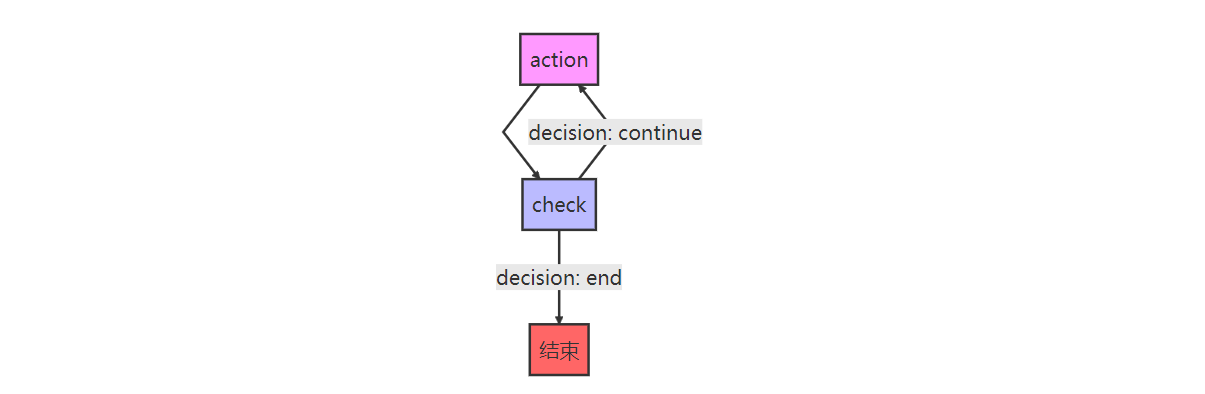
Node 的搭建
action node:這是主要的執行節點,負責 AI 推理和工具調用
private async actionNode(state: AgentState): Promise<{ messages: BaseMessage[] }> {const response = await this.model.invoke(state.messages);// 如果模型決定調用工具if (response.tool_calls && response.tool_calls.length > 0) {const toolMessages: ToolMessage[] = await Promise.all(response.tool_calls.map(async (toolCall) => {const tool = this.tools.find((t) => t.name === toolCall.name);const output = await tool.invoke(toolCall.args);return new ToolMessage({tool_call_id: toolCall.id!,content: typeof output === 'string' ? output : JSON.stringify(output),name: toolCall.name});}));return { messages: [response, ...toolMessages] };}return { messages: [response] };
}
check node:這個節點很簡單,主要作用是觸發 AI 決策,也就是把邏輯放在了條件邊中,可以在這里記一些 log 之類的。
private checkNode(state: AgentState): { messages: [] } {return { messages: [] };
}
為什么使用 action-check 模式
action-check 模式的核心思想是執行與決策解耦:
- action 節點:專注于執行任務,包括調用 AI、執行工具、處理結果等操作。
- check 節點:專注于決策,根據當前狀態分析并決定下一步的行動方向。
邏輯與可維護性優勢
- 邏輯清晰:執行和決策分開,代碼結構直觀,易于維護。
- 可控性高:可以在 check 節點加入復雜決策邏輯,而不干擾執行邏輯。
- 便于調試:每個決策點都有明確日志和狀態記錄,方便排查問題。
發揮 Agent 自主性
這種模式能更好的發揮 AI 自主決策的能力,我們下面討論。
AI 自主決策機制
這是整個系統的核心部分。我們讓 AI 基于完整的對話歷史自主決策下一步行動:
private async aiDecideNextAction(state: AgentState): Promise<string> {const decisionPrompt = `
基于以上完整的對話歷史,決定下一步最合適的行動:1. CONTINUE_SEARCH - 如果需要更多SpreadJS技術信息
2. EXECUTE_CODE - 如果有足夠信息可以生成SpreadJS代碼
3. TASK_COMPLETE - 如果用戶請求已完全滿足請只回復上述選項之一,不需要其他解釋。
`;const decisionModel = new ChatOpenAI({ /* 配置 */ });// 將決策提示添加到現有對話歷史中const decisionMessages = [...state.messages, new HumanMessage(decisionPrompt)];const response = await decisionModel.invoke(decisionMessages);const decision = response.content.trim();// 根據AI決策返回路由switch (decision) {case 'CONTINUE_SEARCH':case 'EXECUTE_CODE':return "action";case 'TASK_COMPLETE':return "__end__";default:return "__end__"; // 安全默認:避免無限循環}
}
這里的關鍵是將決策判斷交給 AI,而不是用硬編碼的規則。AI 能夠理解上下文,做出更智能的判斷。注意要 default 直接結束避免循環.
工具集成
Agent 啟動時會從 MCP Server 獲取工具列表,然后創建本地的工具代理:
private async fetchMCPTools(): Promise<StructuredTool[]> {const response = await this.httpRequest('GET', '/tools');const mcpTools = response.tools;return mcpTools.map((mcpTool: any) => {const schema = this.buildZodSchema(mcpTool.schemaDescription);return new DynamicStructuredTool({name: mcpTool.name,description: mcpTool.description,schema: schema as any,func: async (args: any) => {// 轉發給MCP Server執行return await this.executeMCPTool(mcpTool.name, args);},});});
}
這里做了一個重要的架構決定:Agent 端的工具只是 "代理",真正的執行邏輯在 MCP Server 中。注意接入 tools 之后用 zod 做了個 shcema 綁定,可以規定 AI 返回的格式,做 response_format.
第四部分:服務器和前端搭建
WebSocket 服務架構設計
如前面所說,有兩個服務端口
- Agent Server(3001 端口):處理 AI 請求,管理 WebSocket 連接
- MCP Server(3002 端口):提供工具服務,純 HTTP API
Agent Server 實現
private async fetchMCPTools(): Promise<StructuredTool[]> {const response = await this.httpRequest('GET', '/tools');const mcpTools = response.tools;return mcpTools.map((mcpTool: any) => {const schema = this.buildZodSchema(mcpTool.schemaDescription);return new DynamicStructuredTool({name: mcpTool.name,description: mcpTool.description,schema: schema as any,func: async (args: any) => {// 轉發給MCP Server執行return await this.executeMCPTool(mcpTool.name, args);},});});
}
服務間協作機制
Agent Server 通過 HTTP 請求與 MCP Server 通信:
// Agent 初始化時獲取工具列表
const response = await this.httpRequest('GET', '/tools');// Agent 執行工具時調用 MCP Server
const result = await this.httpRequest('POST', '/execute', {toolName: toolName,args: args
});
這種設計讓兩個服務完全解耦,可以獨立部署和擴容。
前端頁面搭建
主要包含兩個部分:
- 左側:SpreadJS 表格組件
<div class="spreadjs-container"><div id="ss" style="width: 100%; height: 100%;"></div>
</div>
? 2. 我們用 cdn 去拉去 SpreadJS 的 all 包,這個包在 localhost 域名下是可以運行的,不需要 license, 只是會有水印。具體見項目代碼.
? 3.?右側:聊天對話窗口
<div class="chat-messages" id="chatMessages"><!-- 消息展示區域 -->
</div><div class="input-area"><input type="text" id="userInput" placeholder="輸入你的需求..." /><button id="sendButton">發送</button>
</div>
- 這個就是個 chatbox, 怎么實現都可以,拉個三方庫也可以.
WebSocket 客戶端實現
class SpreadJSAgentClient {constructor() {this.ws = new WebSocket('ws://localhost:3001');this.sessionId = this.generateSessionId();this.connectWebSocket();this.setupSpreadJS();}setupSpreadJS() {// 初始化SpreadJSconst spread = new GC.Spread.Sheets.Workbook(document.getElementById('ss'));// 把一些變量暴露在全局, 方便execute_spreadjs調用window.GC = GC;window.workbook = window.spread = spread;window.sheet = window.activeSheet = spread.getActiveSheet();}handleServerMessage(message) {const { type, data } = message;switch (type) {case 'agent_message':// AI 思考內容this.addAgentMessage(data.content);break;case 'agent_step':// 工具調用過程if (data.output.lastToolCall) {this.displayToolCall(data.output.lastToolCall);}if (data.output.toolResult) {this.displayToolResult(data.output.toolResult);}break;}}
}
SpreadJS 代碼執行
當 AI 生成 SpreadJS 代碼時,前端會安全地執行這些代碼:
executeSpreadJSCode(executionPackage) {try {// Execute the generated codeconst func = new Function('workbook', 'GC', executionPackage.executeCode);func(window.workbook, window.GC);// Run query to get resultsconst queryFunc = new Function('workbook', 'GC', 'return ' + executionPackage.queryCode);const result = queryFunc(window.workbook, window.GC);// Send result back to agentthis.sendExecutionResult(executionPackage.id, result);} catch (error) {console.error('Code execution failed:', error);this.sendExecutionResult(executionPackage.id, { error: error.message });}
}
new Function 還是比較危險的,這只是個教程,不要直接使用.
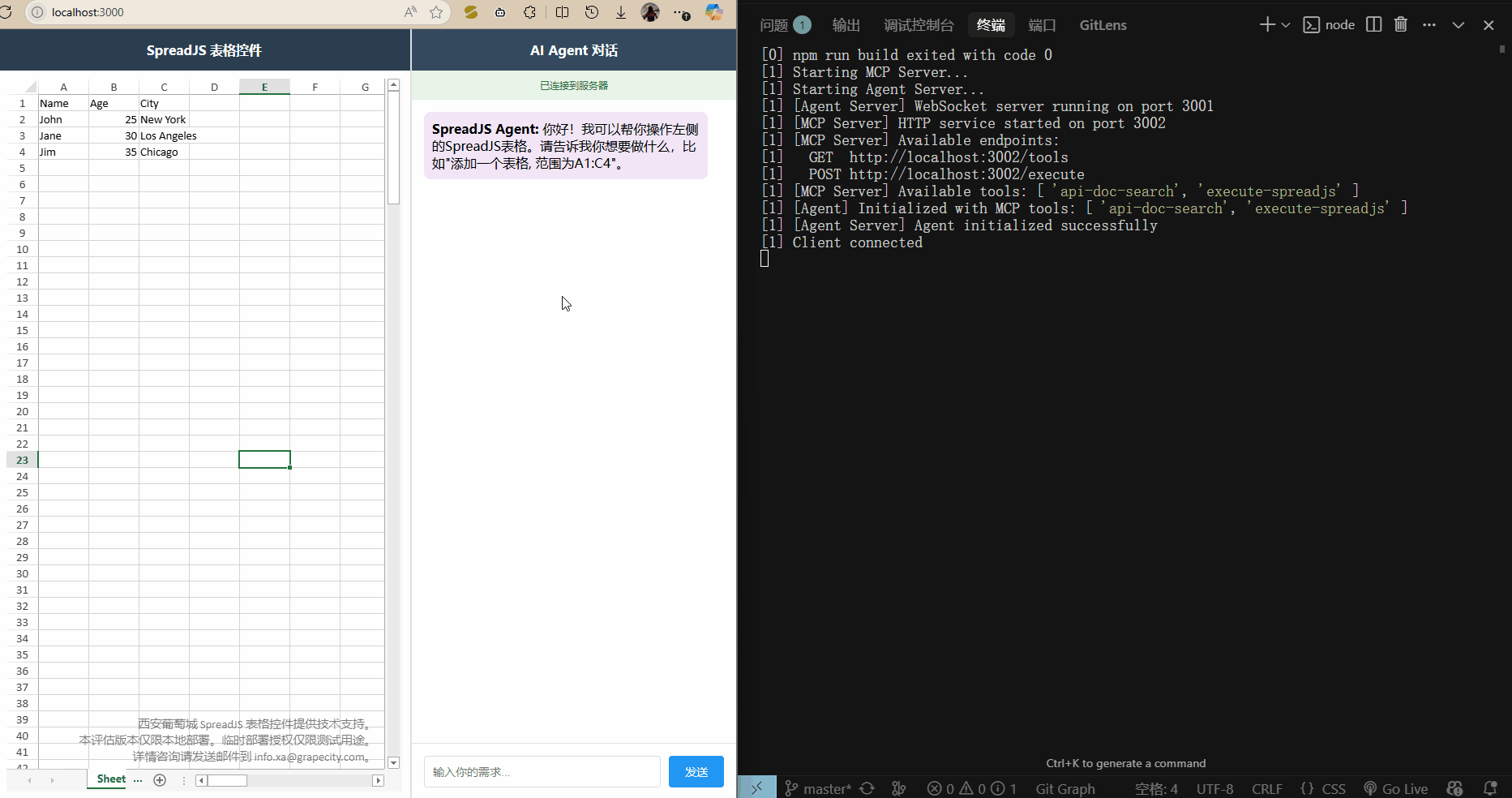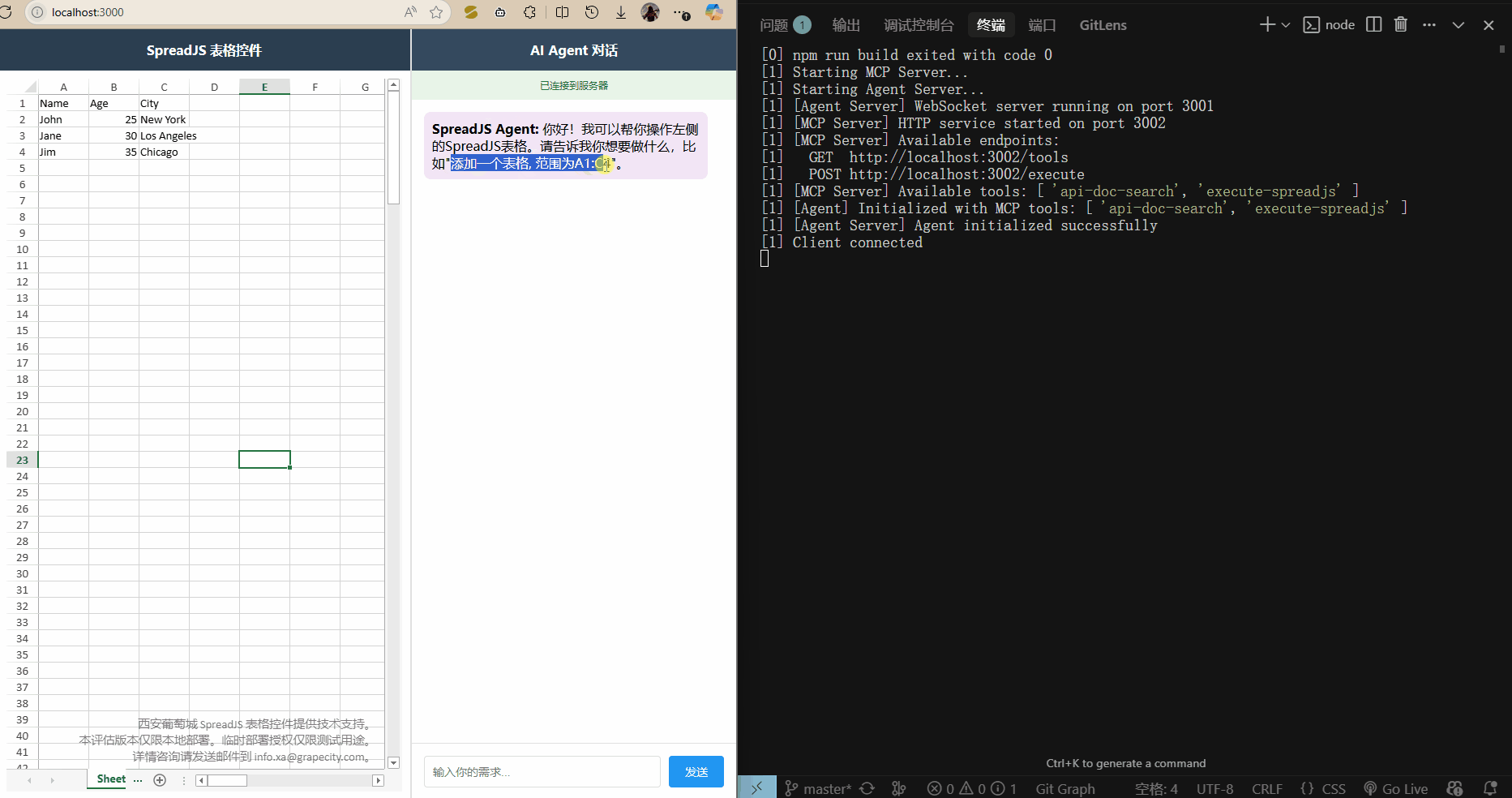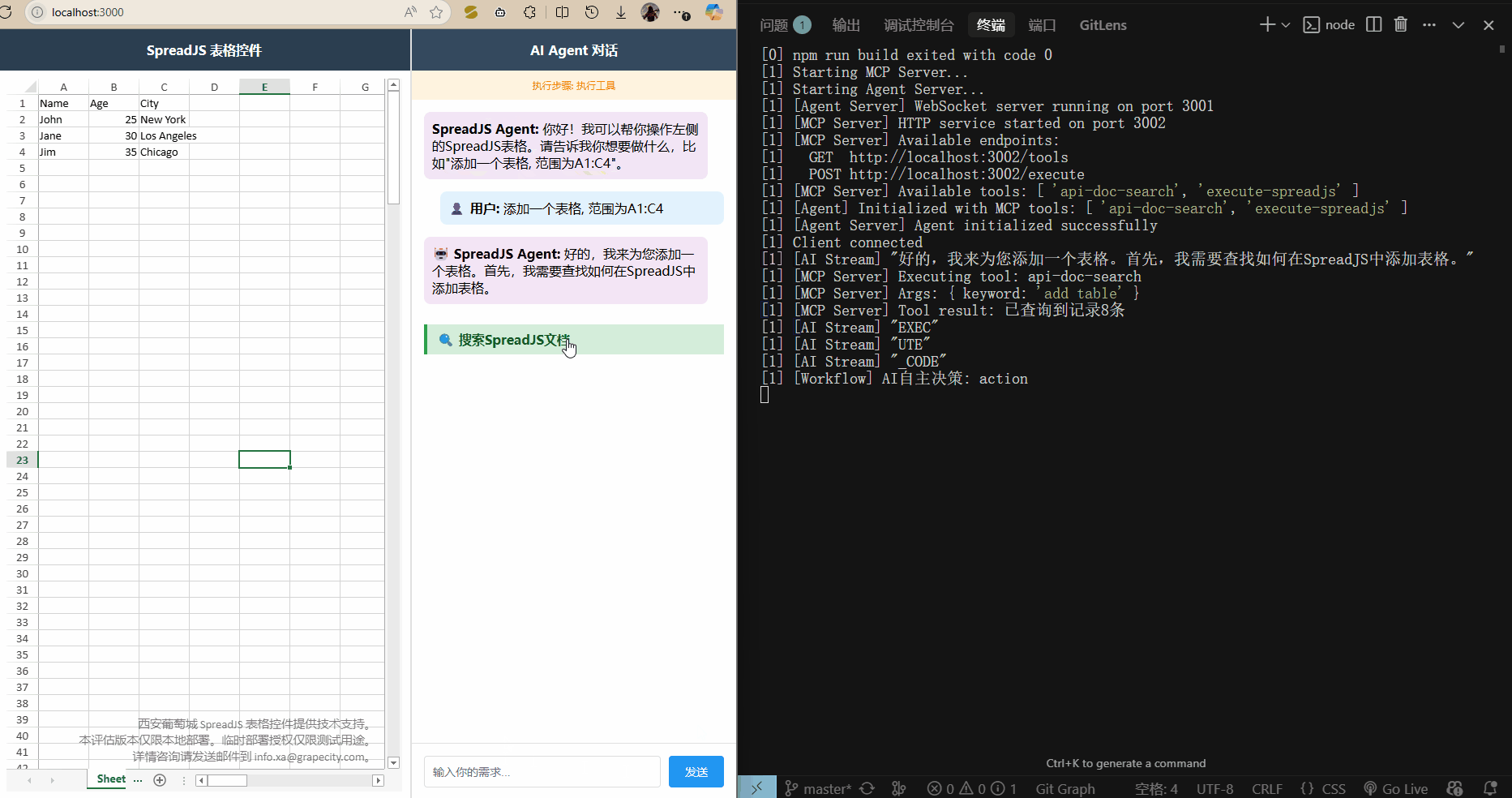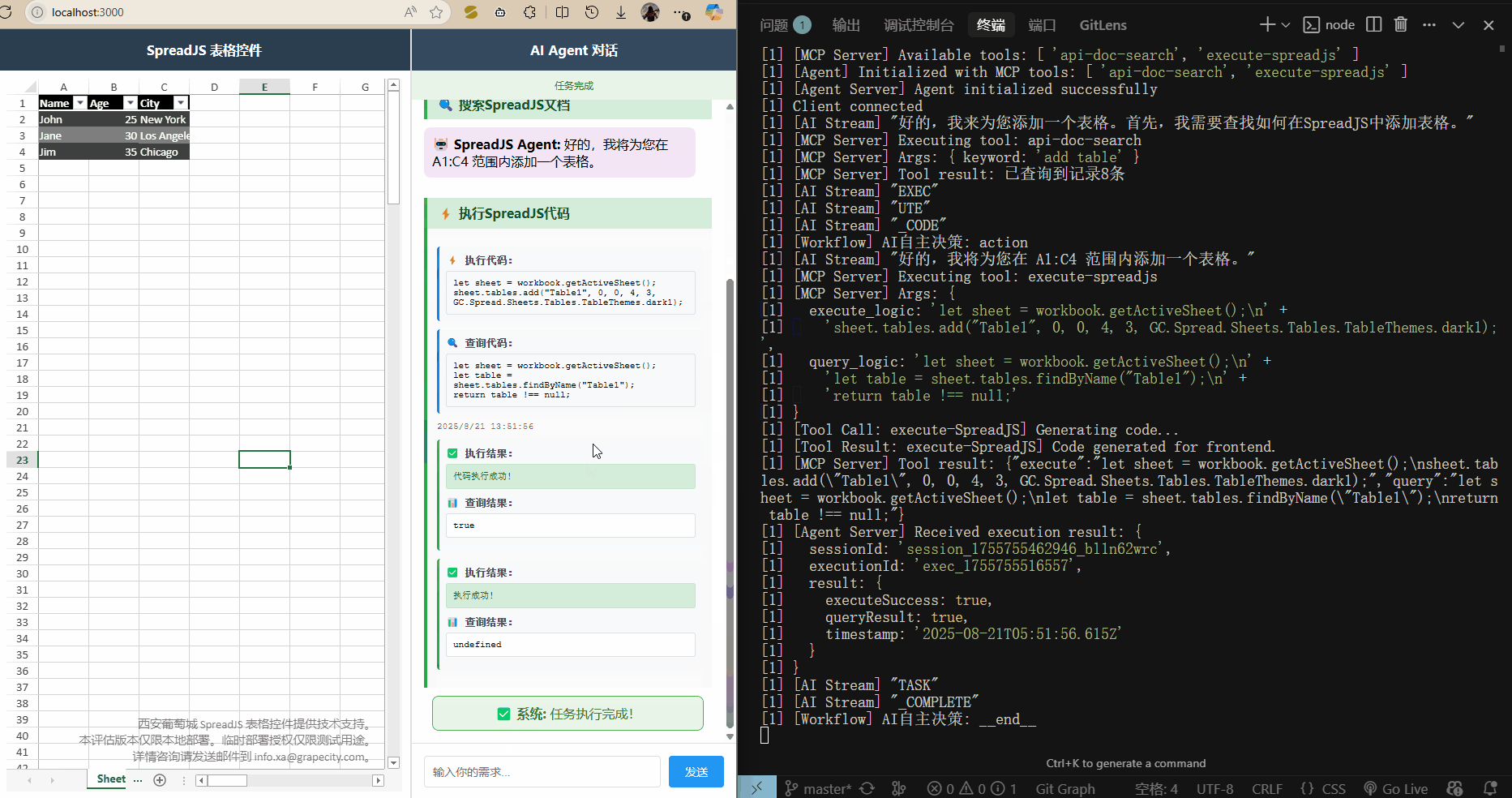
效果展示
運行 npm run dev 啟動三個服務,打開 localhost:3000 訪問前端頁面,就可以輸入需求了.?

)




![[靈動微電子 MM32BIN560CN MM32SPIN0280]讀懂電機MCU之比較器](http://pic.xiahunao.cn/[靈動微電子 MM32BIN560CN MM32SPIN0280]讀懂電機MCU之比較器)




)

![[光學原理與應用-321]:皮秒深紫外激光器產品不同階段使用的工具軟件、對應的輸出文件](http://pic.xiahunao.cn/[光學原理與應用-321]:皮秒深紫外激光器產品不同階段使用的工具軟件、對應的輸出文件)



:深度強化學習的里程碑式突破)

