??一、人工智能三大概念??
-
??人工智能(AI)??
-
定義:使用計算機模擬或代替人類智能的研究領域
-
目標:像人類一樣思考(理性推理)、行動(決策執行)
-
別名:仿智
-
-
??機器學習(ML)??
-
定義:從數據中??自動學習規律??(模型),并用模型預測新數據
-
核心:基于模型自動學習(非人工規則編程)
-
示例:房價預測模型
y = ax + b(a、b為模型參數)
-
-
??深度學習(DL)??
-
定義:模擬人腦神經元的??深度神經網絡??,通過多層結構學習復雜規律
-
特點:從機器學習發展而來,適合圖像、語音等復雜任務
-
-
??三者關系??
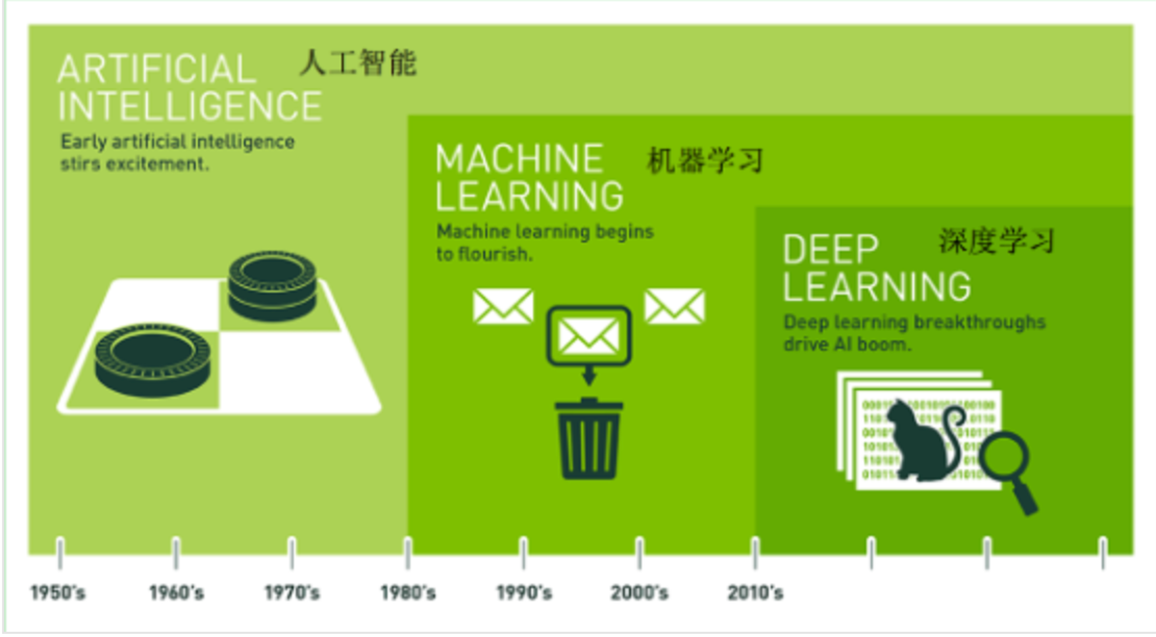
機器學習是實現人工智能的一種途徑,深度學習是機器學習的一種方法
??二、機器學習的應用領域與發展史??
??應用領域??
-
??計算機視覺(CV)??:圖像/視頻理解(如人臉識別)
-
??自然語言處理(NLP)??:文本分析、機器翻譯
-
??數據挖掘??:從大數據中發現隱藏規律
??發展史??
-
??1956年??:AI元年
-
??2012年??:AlexNet引爆深度學習(CV領域)
-
??2017年??:Transformer框架推動NLP發展
-
??2022年??:ChatGPT開啟AIGC時代
??三要素??
-
??數據??:模型訓練的基礎
-
??算法??:解決問題的數學方法
-
??算力??:硬件支持(CPU/GPU/TPU)
-
CPU:適合I/O密集型任務
-
GPU:適合計算密集型任務(如神經網絡訓練)
-
??三、機器學習常用術語??
| 術語 | 說明 | 示例 |
|---|---|---|
| ??樣本?? | 數據集中的一行數據(一條記錄) | 西瓜數據集中的一條 |
| ??特征?? | 描述樣本的屬性(一列數據) | 西瓜的色澤、根蒂 |
| ??標簽?? | 待預測的目標值 | 西瓜是否是好瓜(0/1) |
| ??訓練集?? | 用于訓練模型的數據(70-80%) |
|
| ??測試集?? | 用于評估模型的數據(20-30%) |
|
??四、機器學習算法分類??
1. ??監督學習??(數據含標簽)
-
??回歸??:預測連續值(如房價)
-
??分類??:預測離散類別(如是否垃圾郵件)
2. ??無監督學習??(數據無標簽)
-
??聚類??:按樣本相似性分組(如用戶分群)
3. ??半監督學習??
-
少量標注數據 + 大量未標注數據,降低標注成本
4. ??強化學習??
-
智能體通過??環境交互??獲取獎勵(如AlphaGo、自動駕駛)
-
四要素:Agent, Environment, Action, Reward
??五、機器學習建模流程?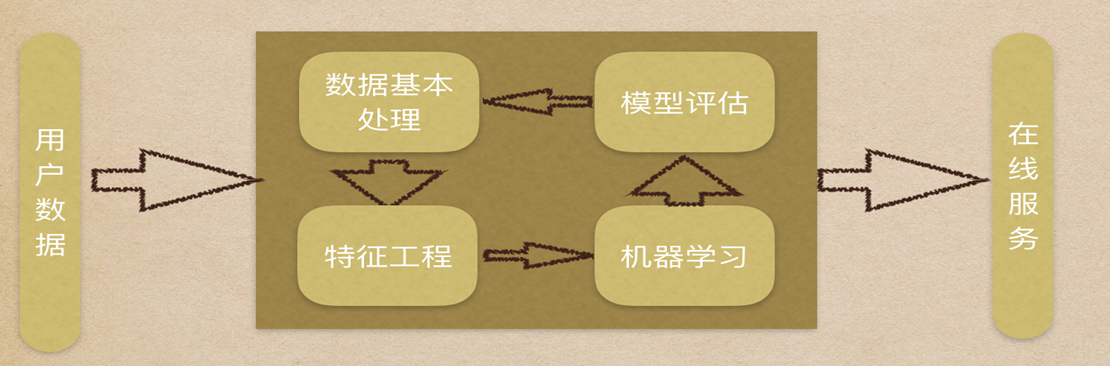
-
??數據預處理??:處理缺失值、異常值
-
??特征工程??(核心耗時步驟):
-
特征提取 → 特征預處理 → 特征降維 → 特征選擇 → 特征組合
-
-
??模型訓練??:選擇算法(如線性回歸、決策樹)
-
??模型評估??:
-
回歸:均方誤差(MSE)
-
分類:準確率、召回率
-
??六、特征工程詳解??
??目標??:提升模型效果,是影響模型上限的關鍵
??原則??:數據和特征 > 模型算法
| 步驟 | 作用 |
|---|---|
| ??特征提取?? | 從原始數據構造特征向量(如文本轉詞向量) |
| ??特征預處理?? | 標準化/歸一化,消除特征量綱影響(如MinMax縮放) |
| ??特征降維?? | 降低特征維度,保留主要信息(如PCA) |
| ??特征選擇?? | 篩選與任務相關的特征子集(不修改原始數據) |
| ??特征組合?? | 合并特征(如乘法/加法),增強表達能力(如組合“面積×位置”預測房價) |
??七、模型擬合問題??
| 問題 | 表現 | 原因 | 解決方案 |
|---|---|---|---|
| ??欠擬合?? | 訓練集和測試集效果均差 | 模型過于簡單 | 增加特征、增強模型復雜度 |
| ??過擬合?? | 訓練集效果好,測試集效果差 | 模型復雜/數據噪聲多 | 簡化模型、正則化、增加數據量 |
??核心概念??
-
??泛化能力??:模型在??新數據??上的表現(最終目標)
-
??奧卡姆剃刀原則??:相同效果下,選擇更簡單的模型
??八、開發環境??
-
??工具??:
scikit-learn(Python庫)-
特點:
-
基于NumPy/SciPy/matplotlib
-
開源,支持分類/回歸/聚類等算法
-
-
安裝:
pip install scikit-learn -
官網:https://scikit-learn.org
-
??關鍵總結??
-
??學習方式??:
-
規則編程(人工定義邏輯) → 機器學習(自動學習模型)
-
-
??核心鏈路??:
數據 → 特征工程 → 模型訓練 → 評估優化 -
??避坑指南??:
-
優先解決特征工程,再優化模型
-
模型選擇:簡單模型優先,避免過擬合
-

線程安全和線程不安全 產生的原因 synchronized關鍵字 synchronized可重入特性死鎖 如何避免死鎖 內存可見性)











)





