文章目錄
- 自動語音識別(ASR)簡介
- 簡要介紹Transformer
- Transformer 在 ASR 中的應用
- 基于“語音識別模型整體框架圖”的模塊介紹
- 1. 音頻采集模塊(Audio Acquisition Module)
- 2. 音頻預處理模塊(Audio Preprocessing Module)
- 3. 特征提取模塊(Feature Extraction Module)
- 4. Transformer 編碼模塊(Transformer Encoding Module)
- 5. Tokenization 模塊(Tokenization Module)
- 6. Word Embedding 模塊(Word Embedding Module)
- 7. Transformer 解碼模塊(Transformer Decoding Module)
自動語音識別(ASR)簡介

自動語音識別(Automatic Speech Recognition,ASR),簡單來說,就是讓計算機能夠聽懂人類的語音,并將其轉換為文本的技術。在我們的日常生活中,ASR 有著極為廣泛的應用。比如大家常用的語音助手,像蘋果的 Siri、小米的小愛同學等,當我們對著它們說話,它們能夠快速識別我們的語音指令,進而幫我們查詢信息、設置提醒、撥打電話等;在智能車載系統中,司機通過語音就能控制導航、播放音樂,無需手動操作,大大提高了駕駛的安全性;還有在會議記錄、語音轉寫等工作場景中,ASR 技術也能極大地提高工作效率,減少人工轉錄的工作量。
簡要介紹Transformer
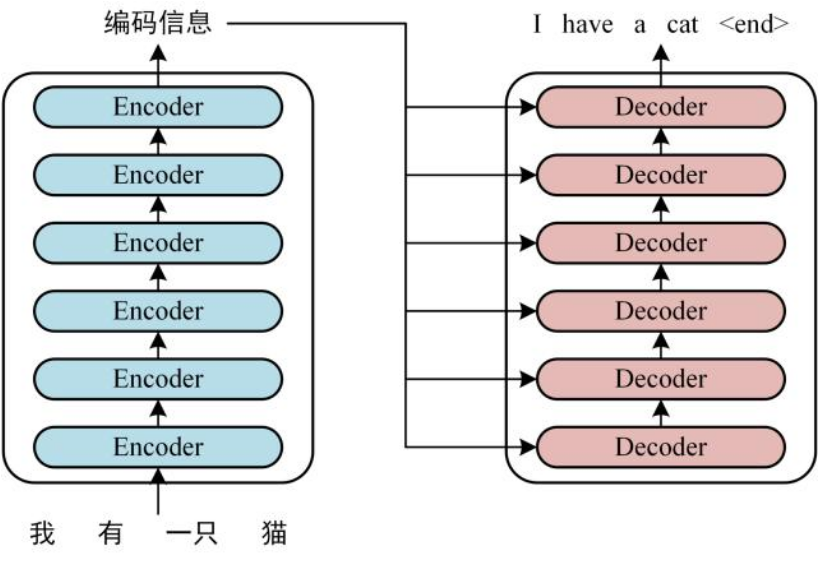
從上述圖片中可直觀看到,Transformer 模型的核心是注意力機制與“編碼器-解碼器”雙結構。圖片中左側堆疊的模塊為編碼器,主要通過自注意力組件捕捉輸入序列中各元素的關聯;右側堆疊的模塊為解碼器,在自注意力基礎上增加了與編碼器的交互組件;底部還可看到位置編碼模塊,用于補充序列的順序信息,整體結構簡潔且聚焦于“全局信息交互”這一核心優勢,為后續適配ASR任務奠定基礎。
Transformer 在 ASR 中的應用
在傳統的 ASR 系統中,多依賴循環神經網絡(RNN),然而 RNN 結構存在難以并行化訓練、訓練效率低、長距離依賴建模效果差等問題。相比之下,Transformer 憑借圖片中展示的自注意力機制,能高效捕捉音頻序列的全局關聯,在 ASR 任務中展現出顯著優勢。
在基于 Transformer 的 ASR 系統中,輸入不再是文本序列,而是音頻信號:首先對音頻進行預處理,將其轉換為梅爾頻譜圖等特征;隨后這些特征輸入 Transformer 編碼器,經圖片中所示的注意力組件處理后,轉化為蘊含音頻關鍵信息的向量;最后解碼器結合與編碼器的交互機制,逐步生成對應的文本序列,實現“音頻-文本”的端到端映射,簡化了傳統ASR的復雜流程。
基于“語音識別模型整體框架圖”的模塊介紹
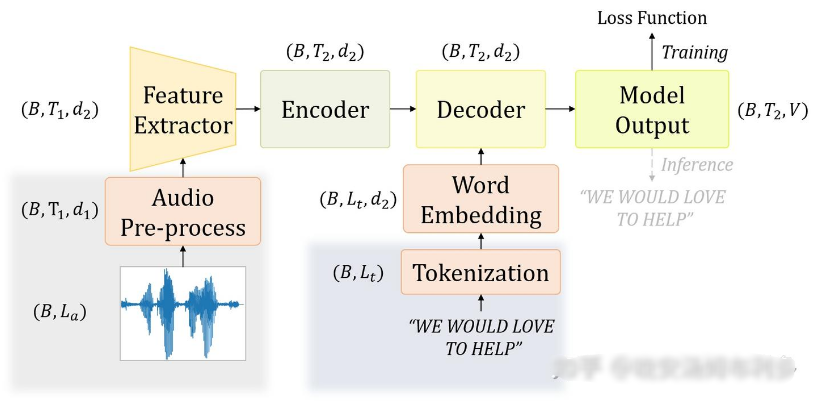
結合上述框架圖,一個完整的Transformer-based ASR系統可拆解為以下核心模塊,各模塊功能如下:
1. 音頻采集模塊(Audio Acquisition Module)
框架圖最左側的模塊為音頻采集模塊,主要功能是獲取原始語音信號。其輸入來源包括實時場景(如麥克風采集的人聲)和離線場景(如本地存儲的MP3、WAV格式音頻文件),輸出為未經處理的模擬/數字音頻流,是整個ASR系統的“數據入口”,需保證信號無明顯噪聲、采樣率穩定。
2. 音頻預處理模塊(Audio Preprocessing Module)
緊鄰采集模塊的是音頻預處理模塊,作用是優化原始音頻質量。主要操作包括:去除背景噪聲(如通過降噪算法過濾環境音)、消除回聲(針對實時通話場景)、統一音頻采樣率(如轉為16kHz標準采樣率),最終輸出干凈、規整的音頻信號,為后續特征提取掃清干擾。
3. 特征提取模塊(Feature Extraction Module)
預處理后的音頻進入特征提取模塊,這是“將音頻轉化為模型可理解語言”的關鍵步驟。框架圖中該模塊通常與梅爾濾波組件關聯,核心是將音頻信號轉換為梅爾頻譜圖:通過模擬人類聽覺系統的濾波特性,將音頻的頻率、幅度信息映射為二維頻譜特征,既保留語音的關鍵辨識度信息,又降低數據維度,輸出的特征圖直接作為Transformer編碼器的輸入。
4. Transformer 編碼模塊(Transformer Encoding Module)
框架圖中間偏左、與特征提取模塊連接的是Transformer編碼模塊,對應前文圖片中展示的編碼器結構。其功能是深度挖掘音頻特征的語義關聯:通過自注意力組件捕捉不同時間點音頻特征的全局依賴(如“你好”一詞中“你”和“好”的頻譜關聯),再經前饋網絡進一步提取高層特征,最終輸出蘊含完整語音語義的向量表示,為解碼提供“音頻語義底座”。
5. Tokenization 模塊(Tokenization Module)
框架圖中與Transformer解碼模塊關聯的是Tokenization模塊,這是“文本生成前的基礎處理環節”。其核心功能是將目標語言的文本拆分為最小語義單元(即Token):對于中文,Token可以是單個漢字(如“你”“好”);對于英文,Token可以是單詞或子詞(如“apple”拆分為“app”和“le”,或直接保留“apple”)。通過該模塊處理,文本被轉化為離散的Token序列,為后續詞嵌入和解碼生成提供標準化輸入格式,避免因文本格式不統一導致的解碼誤差。
6. Word Embedding 模塊(Word Embedding Module)
緊鄰Tokenization模塊的是Word Embedding模塊,作用是“將離散Token轉化為連續向量”。由于Transformer模型無法直接處理離散的文字符號,該模塊會通過預訓練或模型訓練過程,為每個Token分配一個固定維度的實數向量(如256維、512維)。這些向量會蘊含Token的語義信息(如“貓”和“狗”的向量距離較近,“貓”和“汽車”的向量距離較遠),最終輸出的Token向量序列,會作為Transformer解碼器的輸入之一,幫助解碼器理解文本語義,提升生成文本的準確性。
7. Transformer 解碼模塊(Transformer Decoding Module)
位于框架圖中間偏右的是Transformer解碼模塊,對應前文圖片中的解碼器結構。其核心功能是將編碼器輸出的音頻語義向量,結合Word Embedding模塊輸出的Token向量,轉化為完整文本:首先通過遮蔽自注意力確保“只能根據已生成Token預測下一個Token”(避免提前看到未來信息),再通過與編碼器的交互組件,從編碼向量中提取對應音頻語義;最后通過輸出層預測每個位置的Token,逐步生成完整的Token序列,再經簡單轉換得到最終文本(如將“n”“i”“h”“a”對應的Token向量拼出“你好”)。
Transformer 模型通過其簡潔高效的結構,成為ASR系統的核心引擎;而“語音識別模型整體框架圖”中的各模塊則像一條完整的“流水線”,從音頻采集到文本生成層層遞進,尤其是Tokenization和Word Embedding模塊的加入,為解碼器搭建了“語義理解橋梁”,共同實現“讓計算機聽懂語音”的核心目標。
參考資源:
- https://github.com/owenliang/transformer-asr/tree/main
- https://zhuanlan.zhihu.com/p/648133707




)






線程安全和線程不安全 產生的原因 synchronized關鍵字 synchronized可重入特性死鎖 如何避免死鎖 內存可見性)







