Google DeepMind 近期發布了關于遞歸混合(Mixture of Recursion)架構的研究論文,這一新型 Transformers 架構變體在學術界和工業界引起了廣泛關注。該架構通過創新的設計理念,能夠在保持模型性能的前提下顯著降低推理延遲和模型規模。

本文將深入分析遞歸混合(MoR)與專家混合(MoE)兩種架構在大語言模型中的技術特性差異,探討各自的適用場景和實現機制,并從架構設計、參數效率、推理性能等多個維度進行全面對比。
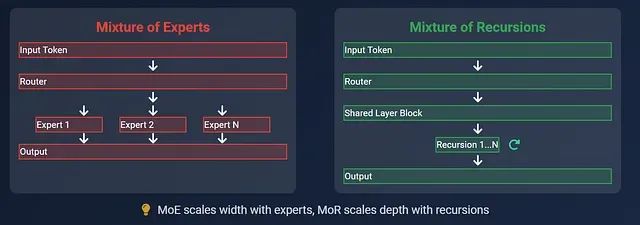
專家混合(Mixture of Experts)架構原理
專家混合架構將神經網絡模型分解為共享基礎層和多個專門化的專家模塊,其中每個專家模塊都是經過特定訓練的小型前饋神經網絡,負責處理特定類型的輸入模式。
在推理過程中,當輸入令牌通過模型時,路由機制會從眾多專家中選擇性激活少數幾個(通常為2-4個,總專家數可能達64個或更多)來處理該令牌。這種設計使得不同令牌在模型中遵循不同的計算路徑,從而實現了在不增加實際計算量的情況下擴大模型容量的目標。這一機制類似于在復雜任務中僅調用相關專業人員而非整個團隊的協作模式。
遞歸混合(Mixture of Recursion)架構原理
遞歸混合架構采用了截然不同的設計思路,它使用一個相對較小的共享計算塊(通常由幾個 Transformer 層組成),通過多次迭代處理來實現深度計算。每個輸入令牌根據其復雜程度自主決定所需的處理輪數。
在這種架構中,語義簡單的令牌會在較少的迭代后提前退出處理流程,而復雜令牌則需要經過更多輪次的遞歸處理。與 MoE 通過增加模型寬度來提升容量不同,MoR 通過動態調整計算深度來優化性能。此外,該架構通過智能緩存機制僅保留迭代過程中的必要信息,顯著降低了內存占用。整個系統中不存在多個專家模塊,而是通過單一計算塊的智能重用來實現高效計算。
基于以上架構原理,我們將從多個技術維度深入分析兩種架構的具體差異:
架構設計對比分析
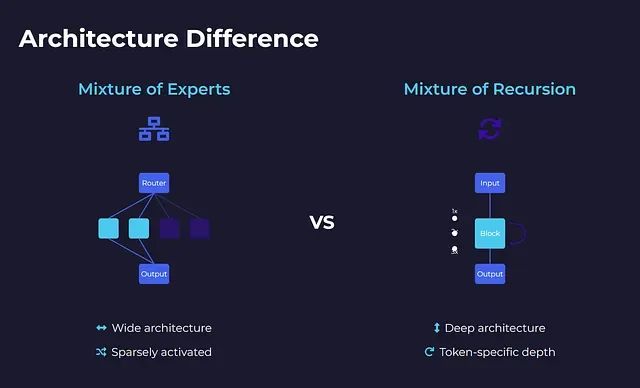
專家混合架構采用分布式專家系統的設計理念,整個模型可以視為一個大型智能交換網絡。模型內部包含大量小型多層感知機專家模塊,但在處理任何單一令牌時,僅有少數專家(通常2-4個)處于激活狀態。路由器負責決策激活哪些專家,而其余專家保持空閑狀態。每個令牌在網絡中沿著獨特的路徑傳播,激活不同的專家組合。這種設計實現了大規模稀疏激活模型——雖然總體規模龐大,但實際計算量保持高效。
遞歸混合架構則采用了相反的設計策略,整個模型僅包含一個小型 Transformer 計算塊,所有令牌共享同一計算資源。令牌不是在不同專家間分流,而是在同一計算塊中進行多輪迭代處理。迭代次數完全由令牌特性決定:簡單令牌快速退出,復雜令牌進行深度處理。因此,模型呈現窄而深的特征,具備令牌特定的動態深度調整能力。
從系統架構角度來看,MoE 類似于配備多個專科醫生的大型綜合醫院,患者根據病情被路由到相應的專科部門;而 MoR 則像一位經驗豐富的全科醫生,根據患者病情復雜程度進行相應次數的深入診查——簡單感冒一次診斷即可,復雜心臟疾病則需要多輪深度檢查。
模型規模與參數效率分析
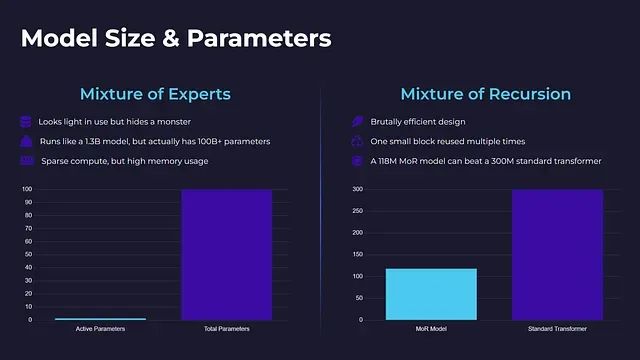
專家混合架構在運行時表現出輕量化特征,但其背后隱藏著巨大的參數規模。一個在推理時表現如同1.3B參數模型的MoE系統,實際上可能在所有專家模塊中總計包含超過100B個參數。雖然單次推理僅激活其中一小部分,但所有專家模塊都需要完整的存儲、加載和訓練支持。
這種設計帶來了計算稀疏性與內存密集性并存的特點。在訓練過程中,所有專家模塊都需要接收梯度更新,包括那些很少被激活的專家。如何在眾多專家間實現負載均衡成為了比預期更加復雜的工程挑戰。
相比之下,遞歸混合架構展現出極高的參數效率。通過在多個處理步驟中重復使用單一計算塊,該架構避免了參數數量的爆炸性增長,也無需管理復雜的專家模塊集合。實驗數據表明,一個118M參數的MoR模型在少樣本學習任務中的性能可以超越300M參數的標準Transformer模型,這種優勢并非來自更大的模型規模,而是源于更智能的計算資源利用策略。
當內存容量、存儲空間或部署成本成為關鍵考慮因素時,MoR架構相比MoE具有顯著優勢。
推理延遲性能評估
在實際部署環境中,推理延遲性能成為衡量架構實用性的關鍵指標。
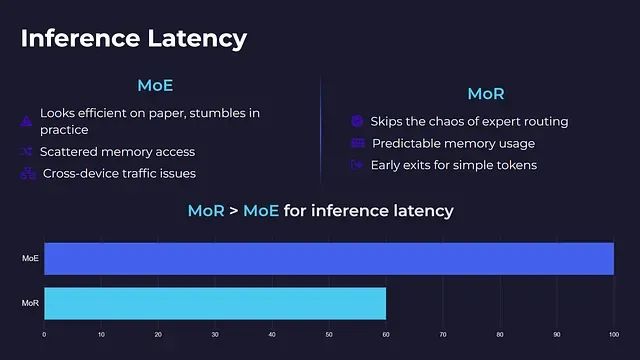
專家混合架構雖然在理論分析中表現出良好的計算效率,但在實際實現中往往面臨性能瓶頸。每個令牌僅激活少數專家的策略雖然減少了計算量,但同時引入了內存訪問模式分散、計算負載不均衡以及跨設備通信開銷等問題。
對于基礎設施水平未達到Google或Microsoft等科技巨頭標準的部署環境,延遲、網絡擁塞和系統復雜性往往會抵消稀疏計算帶來的性能收益。MoE架構并非即插即用的解決方案,需要針對特定硬件環境進行深度優化。
遞歸混合架構有效避免了上述復雜性問題。由于不存在專家路由機制和跨設備通信需求,每個令牌在同一小型計算塊中進行迭代處理,并自主決定退出時機。這種設計確保了內存訪問的可預測性、支持早期退出機制,并在各種硬件環境下保持穩定的運行時性能,即使在中等性能的GPU上也能良好運行。部署MoR架構無需超算集群支持。
從推理延遲角度分析,MoR架構明顯優于MoE架構。
訓練穩定性與收斂特性
專家混合架構在訓練過程中容易出現專家崩潰現象,這是該架構面臨的主要技術挑戰之一。在訓練進程中,模型可能過度依賴少數幾個專家模塊,而忽視其他專家的能力發展。部分專家模塊可能無法接收到足夠的梯度信號,導致學習停滯,最終拖累整體模型性能。
解決專家崩潰問題需要引入額外的損失函數項、熵正則化機制以及精心設計的負載均衡策略。雖然這些技術手段可以緩解問題,但增加了訓練流程的復雜性和脆弱性。
遞歸混合架構從根本上避免了專家不均衡問題。由于不存在多個專家模塊,所有令牌共享相同的權重參數,通過干凈的重用機制實現高效訓練,顯著提升了訓練過程的穩定性。
然而,MoR架構也有其特定的調優挑戰:如何確定每個令牌的最優迭代次數。迭代次數過少會導致處理深度不足,過多則造成計算資源浪費。MoR通過專家選擇路由和令牌選擇路由兩種策略來平衡這一問題,且無需額外的損失函數技巧。
路由機制技術實現
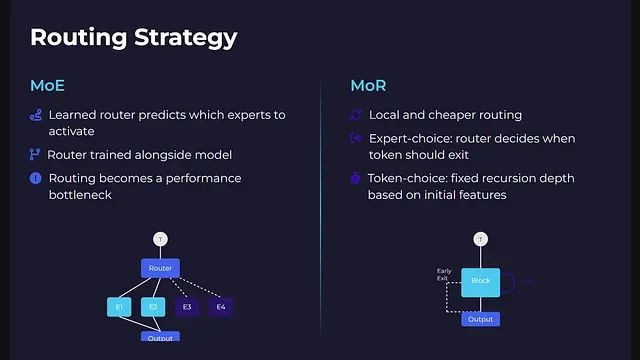
專家混合架構采用基于學習的路由機制,路由器通過分析令牌嵌入向量來預測應該激活哪些專家模塊。這種路由決策與整個模型一同進行端到端訓練。系統需要確保沒有專家模塊被過度使用,同時防止路由器陷入固定的激活模式。
在大規模MoE模型中,特別是涉及跨設備路由時,路由機制往往成為系統性能的瓶頸。
遞歸混合架構的路由機制更加本地化且計算開銷更低。該架構支持兩種路由模式:專家選擇路由模式下,路由在每個遞歸步驟中決定令牌是否繼續處理或退出流程;令牌選擇路由模式下,每個令牌在處理開始時根據其初始特征被分配固定的遞歸深度。
MoR中的路由重點不在于選擇處理單元,而在于確定在同一計算塊中的停留時間。由于無需令牌間或設備間的通信協調,整個計算圖保持了更好的簡潔性和優化空間。
硬件適配與部署考量
專家混合架構主要面向大規模計算環境設計。要充分發揮其效率優勢,需要GPU間高速互連、跨加速器智能分片以及硬件級稀疏張量運算支持。該架構并非即插即用解決方案,大多數開源深度學習框架無法提供開箱即用的大規模MoE支持。對于擁有頂級基礎設施的科技公司,MoE架構展現出良好的性能表現。
然而,對于在個人工作站或邊緣設備上進行推理的場景,MoE架構的部署難度極高。
遞歸混合架構在部署方面表現出更好的靈活性。該架構基于標準Transformer結構,僅在核心計算塊外增加迭代控制邏輯。開發者可以使用標準的PyTorch或JAX原語進行實現。由于采用共享權重和簡單的令牌級控制流,MoR架構能夠以最小的修改集成到現有的模型服務管道中。
應用場景與技術選型
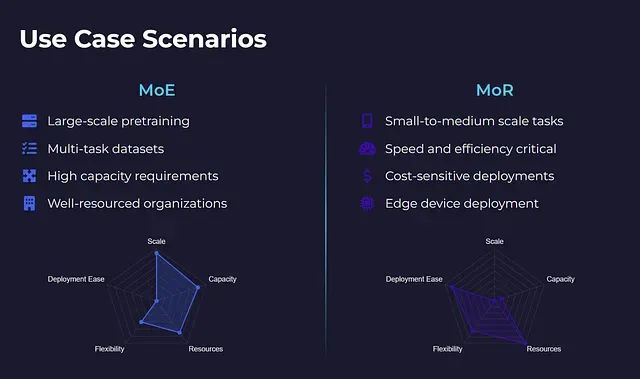
專家混合架構適用于從零開始訓練大規模模型、處理多任務數據集,以及在不進行全密集計算的前提下追求高模型容量的場景。該架構在大規模預訓練任務中表現出色,但除非具備充足的計算和工程資源,否則將在系統復雜性、內存需求和延遲優化方面面臨顯著挑戰。
遞歸混合架構更適合對推理速度、計算效率和部署成本敏感的中小規模應用場景。該架構在模型微調、少樣本學習以及邊緣計算或消費級硬件部署方面具有明顯優勢。此外,MoR架構具備良好的縮放特性,這是MoE架構的薄弱環節。
總結
從技術發展趨勢來看,專家混合架構通過部署大量專家模塊來解決復雜問題,但在每次推理中僅激活其中一小部分;而遞歸混合架構則通過單一計算單元的反復迭代,在每次處理中都變得更加智能。
對于致力于構建大規模商業化語言模型平臺的組織,專家混合架構的復雜性投入可能是值得的。而對于需要在實際設備上快速部署高效模型的應用場景,遞歸混合架構能夠以更低的技術債務實現目標。
兩種架構代表了大語言模型發展的不同技術路徑,各自在特定場景下展現出獨特的技術優勢。選擇哪種架構應基于具體的應用需求、資源約束和技術能力進行綜合考量。
https://avoid.overfit.cn/post/c95f03d8ad3049ada1c41e71094e2fd5
作者:Mehul Gupta

)














如何進行MySQL的全局變量設置?)


