DL入門指南
資料課程
- 李沐老師 《動手學深度學習》
https://tangshusen.me/Dive-into-DL-PyTorch/ - 李宏毅老師課程
https://speech.ee.ntu.edu.tw/~hylee/ml/2021-spring.php
DL入門必掌握知識點
- 數據處理 : numpy、torch
- 地址處理 : os、pathlib
- 文件處理 : json、yaml
- 命令行參數解析 :args
- 獲取時間 : time
- 圖片讀取與可視化: PIL、cv2、matplotlib
- 數據預處理與數據增強 :torchvision.transforms、cv2
- 獲取常用數據/處理數據 :torchvision.datasets、自定義dataset
- 迭代batch數據 : torch.utils.data.DataLoader、自定義collate_fn
- 模型搭建 : torch.nn、torch.nn.functional
- 獲取(預訓練)模型 :torchvision.models
- 保存日志 :tensorboard、logging
- 優化器 :torch.optim
- 學習率調度器 :torch.optim.lr_scheduler
- 模型參數/checkpoint 保存與加載
- 遷移學習:模型修改、參數凍結
- 各任務常用損失函數
- 各任務評價指標
- 項目環境配置
入門算法
包括但不限于以下算法:
第一階段 :LeNet、AlexNet、GoogleNet、VGG
第二階段 :Resnet、DenseNet、Unet、FCN
第三階段 :Faster RCNN、SSD、YOLO v3、self-attention、Vision Transformer(encoder-decoder模塊)
第四階段 : YOLO 系列 、 DETR 系列、(有興趣的可以看 Mamba 系列)
入門評估
怎樣才算入門?
1、掌握模型訓練代碼框架
2、熟悉各種常用數據集
3、無障礙預處理數據
4、玩轉以 resnet 為 backbone 的各種遷移學習算法
5、熟悉圖像分類任務、目標檢測任務、語義分割任務的常用損失函數與評價指標
6、完全理解 Fater RCNN、SSD、YOLO v3、Attention 的理論,看懂并理解每一行代碼
如何快速入門
1、入門有哪些東西需要學習
2、建議的學習步驟
3、相關的學習資料從哪獲取
深度學習 想要快速入門,需從2個方面進行提升:
- 理論知識 :多看 csdn、b站 等平臺的 經典算法理論講解
- 代碼能力 :動手臨摹一些經典算法,這些算法基本都是開源的
- Step 1 :動手臨摹一些 簡單的、經典的開源算法,(比如 LeNet、AlexNet、GoogleNet、VGG) ,務必搞懂每一行代碼的作用與原理、整理自己的訓練代碼框架 訓練代碼框架
- Step 2 :入門后,在代碼能力提升階段,多看別人的代碼,碰到經常見到的、不熟悉的模塊的使用,再進行資料查找并學習,整理自己的學習筆記 (功能模塊代碼)!一定要整理自己的學習筆記!
Step 1 : LeNet、AlexNet、GoogleNet、VGG 一定是你入門必學必臨摹的算法
這個階段的目標:
- 熟悉整體的訓練代碼框架 訓練代碼框架、理解每一行代碼的作用與原理
- 掌握
torchvision中的3個重要模塊:torchvision.models、torchvision.datasets、torchvision.transforms - 掌握如下知識點的理論與代碼使用:
- 簡單的基礎模型搭建
- 模型查看
- 如何直接從
torchvision.datasets獲取常用數據 - 簡單的使用
torchvision.transforms進行圖像預處理 - DataLoader 的基礎使用,參數功能掌握
- 幾種優化器的理論知,
torch.optim的模塊使用 - 學習率、梯度、反向傳播的關系
- 分類任務、目標檢測任務、分割任務 常用的損失函數 理論與 相關pytorch類的使用
Step 2 :玩轉常用數據集
熟悉常用數據集:MNIST、Flowers、CIFAR、MSCOCO、PascalVOC
根據每個數據集,整理你自己的 數據處理通用代碼 :
- 一方面,幫助你學習數據處理
- 另一方面,方便之后復用
通過這個階段,你的目標:
- 熟悉各個數據集的:數據結構、支持的任務、圖片大小、類別數
- 數據讀取庫:PIL、cv2
- 自定義 DataSet :3個必要的函數的使用:
init()、getitem()、len() - 數據處理,數據增強 : 進一步 了解
torchvision.transforms的使用 - Dataloader 的使用,各個參數的含義
- 數據可視化庫:cv2、matplotlib
Step 3 : 玩轉 Resnet
通過這個階段的目標:
- 完全理解 Resnet,以及 Resnet 的網絡特點,知道怎么將它作為 backbone 提取 feature map
- 遷移學習的各種技巧:修改網絡,網絡加載參數、凍結參數
- 了解一些基礎的 目標檢測、語義分割的理論知識
- 圖像預處理/圖像增強的技巧:針對不同任務,圖像預處理/圖像增強需要注意的點
Resnet 是最常用的 backbone,玩轉它很有必要,學習內容:
- 學習 Resnet 理論知識、臨摹 Resnet 網絡搭建
- 在 Resnet 的基礎上做遷移學習,再去學習一個以 Resnet 為 backbone 的網絡
- 圖像分類:直接在 Resnet 網絡上做修改,去訓練一些 常用數據集(圖像尺寸不易太小)
- 目標檢測:以 ResNet 為 backbone 的 YOLO v3
- 語義分割:以 ResNet 為 backbone 的 FCN
- 有時間再去學習一下 U-net 網絡,對你網絡搭建技巧有很大的幫助
Step 4 : 學習你研究方向相關的經典網絡
比如 :Faster-RCNN、SSD、YOLO系列、self-attention
- 學習你研究方向的 理論知識
- 比如,什么是 one-stage,什么是 two-stage
- 比如,end-to-end 的方法需要我們輸出包括哪些內容
- 比如,目標檢測任務的目標是什么,圖像分割任務的目標是什么
- 比如,目標檢測任務的評價指標 mAP 怎么計算,圖像分割任務的評價指標是那幾個
- 比如,什么是 self- attention,什么是 cross-attention;
- 提升代碼能力,復現代碼的時候,看到不了解的代碼行,代碼塊,記錄下來,去查資料學習,整理為自己的學習筆記。
算法學習流程
(1)先找1~2個 點贊多的視頻 或者 博客看,了解一下算法的背景,做了啥,重點思想是什么
(2)然后去看論文,根據 abstract 部分,了解作者提出了哪些創新點;算法部分會仔細的看(一般是第3節、第4節),以及論文中貼出來的每張圖 也會仔細的看
(3)再回頭多找幾個 博客或者視頻看,看大家的理解是什么
(4)需要了解算法細節的,就翻代碼,一邊看一邊隨手畫畫數據處理流程圖,幫助理清思路
(5)了解數據處理過程之后,再回頭自己思考背后的思想,這么做的用意是什么,
(6)有覺得以后能用得上的代碼,就整理到自己的代碼庫中,方便以后 control c + control v
(7)有需要就再多翻一翻論文,論文中總有 別人博客中沒有提及到的細節
(8)看代碼可以和看書一樣,多看幾遍,第一遍不需要多細,大概看個結構,一遍比一遍往細了看
想復現 卻找不到源碼
完美復現是一件非常非常困難的事情
1、github
- 通過算法關鍵詞搜索
- 去各個作者的倉庫中查看
- 去 issue 中提問
2、paper with code 里面可能會有相關代碼
3、kaggle 找相關數據集,看與這個數據集 相關的代碼中是否有可參考代碼。
4、其他方式 :
- 在 stackoverflow 或其他平臺進行提問
- 如果是系列代碼,去查看同系列其他代碼
- 給作者發郵件,去要代碼
- 問師兄師姐
- 找相關方向的群組,群組內提問
如何僅下載GitHub項目的部分文件
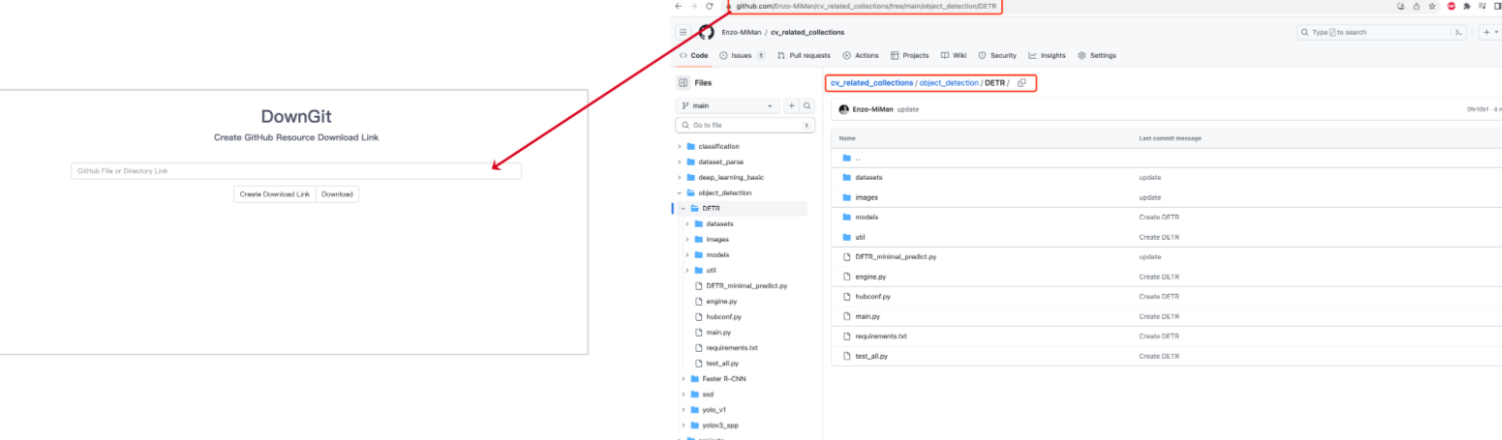
1、Downgit
Downgit 地址 : https://minhaskamal.github.io/DownGit/#/home
將倉庫中,需要下載的那一部分的根目錄地址,粘貼到 DownGit,然后 download 即可
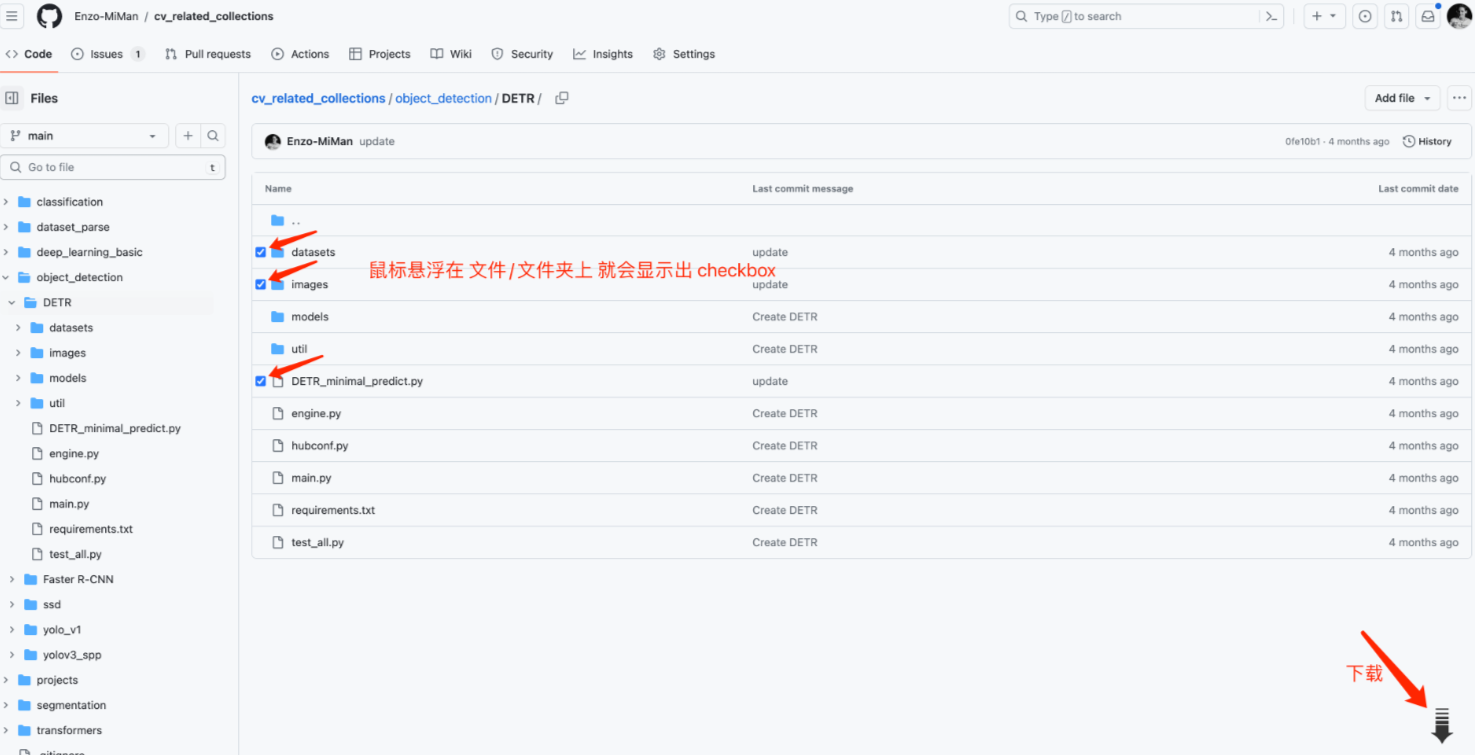
2、GitZip for github
GitZip for github 是 Chrom瀏覽器中的插件, 安裝地址: https://chrome.google.com/webstore/detail/gitzip-for-github/ffabmkklhbepgcgfonabamgnfafbdlkn/related

用 Chrom 瀏覽器打開 Github 中的某目標倉庫,倉庫中的 文件/文件夾前面,就會顯示出一個 checkbox,選中要下載的 文件/文件夾, 在右下角點擊加載即可。
)

)



)








棧和隊列)

隨機數與隨機顏色)

