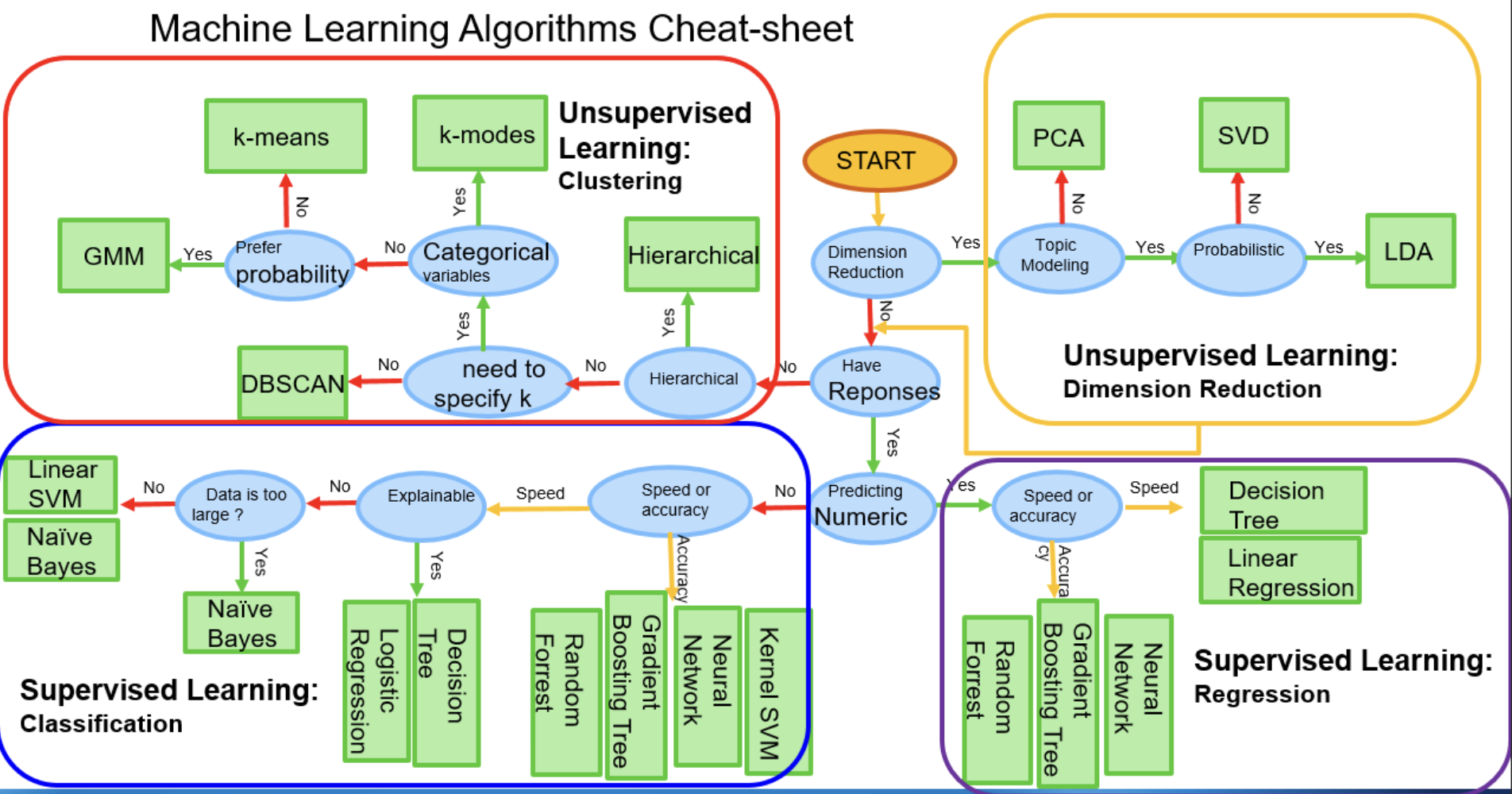
機器學習領域存在"沒有免費午餐"定理,沒有任何一種模型在所有問題上都表現最優。不同模型有各自的優勢和適用場景。同一數據集上,不同模型的預測性能可能有巨大差異。例如,線性關系明顯的數據上線性模型可能表現優異,而復雜非線性關系則可能需要樹模型或神經網絡。
這里寫目錄標題
- 模型選擇依據
- 根據問題類型選擇合適的模型
- 根據模型特點選擇合適的模型
- 根據數據特征選擇合適的模型
- 用于回歸任務的多種模型
- 用于分類任務的常見模型
- 分類模型選擇建議
- 常見分類模型
- 1. **邏輯回歸(Logistic Regression)**
- 2. **支持向量機(SVM / SVC)**
- 3. **決策樹(Decision Tree)**
- 4. **隨機森林(Random Forest)**
- 5. **梯度提升樹(Gradient Boosting)**
- 6. **K近鄰(K-Nearest Neighbors, KNN)**
- 7. **樸素貝葉斯(Naive Bayes)**
- 8. **多層感知機(MLP / 神經網絡)**
- 9. **LightGBM / XGBoost / CatBoost(進階推薦)**
模型選擇依據
根據問題類型選擇合適的模型
| 問題類型 | 模型方向 |
|---|---|
| 回歸任務(預測連續值):房價、銷量、溫度 | 使用 RandomForestRegressor, XGBoost, LinearRegression 等 |
| 分類任務(預測類別):是否違約、圖像分類 | 使用 RandomForestClassifier, LogisticRegression, SVC 等 |
| 聚類任務 | 。。。 |
根據模型特點選擇合適的模型
| 模型 | 假設/特點 | 不適用場景 |
|---|---|---|
| 線性回歸 | 特征與目標呈線性關系 | 數據高度非線性 |
| 決策樹 | 分段常數預測,適合規則型數據 | 對噪聲敏感,易過擬合 |
| KNN | 局部相似性有效 | 高維稀疏數據(維度災難) |
| SVR | 小樣本、非線性核有效 | 大數據集(訓練慢) |
| XGBoost/LightGBM | 結構化數據王者 | 圖像、文本等非結構化數據 |
根據數據特征選擇合適的模型
| 數據特點 | 推薦模型 |
|---|---|
| 樣本少(<1k) | SVR、KNN、線性模型 |
| 樣本多(>10k) | 樹模型(XGBoost、LightGBM)、神經網絡 |
| 特征少且線性關系明顯 | 線性回歸、嶺/套索回歸 |
| 特征多、非線性、交互多 | 隨機森林、梯度提升、MLP |
| 高維稀疏(如文本) | 線性模型 + L1 正則化、SVM |
| 存在多重共線性 | Ridge、Lasso、ElasticNet |
| 需要特征選擇 | Lasso、Tree-based 模型 |
| 數據未標準化 | 樹模型(不需要標準化)、避免 KNN/SVR/MLP |
| 類別特征多 | LightGBM(原生支持)、CatBoost |
用于回歸任務的多種模型
-
LinearRegression(線性回歸)
- 最基礎的回歸模型,通過尋找特征與目標變量之間的線性關系進行預測
- 公式:y = w?x? + w?x? + … + w?x? + b
-
Ridge(嶺回歸)
- 線性回歸的正則化版本,使用L2正則化
- 通過添加系數平方和的懲罰項防止過擬合
- alpha參數控制正則化強度
-
Lasso(套索回歸)
- 線性回歸的另一種正則化版本,使用L1正則化
- 可以將某些特征的系數縮減到零,實現特征選擇
- 適用于高維數據集
-
Elastic Net(彈性網絡)
- 結合了Ridge和Lasso的特點,同時使用L1和L2正則化
- l1_ratio參數控制兩種正則化的比例
- 在處理多重共線性數據時表現良好
-
Random Forest(隨機森林)
- 集成學習方法,構建多棵決策樹并取平均預測結果
- 通過隨機選擇特征和樣本增加模型多樣性
- 通常具有較高的準確性和魯棒性
-
Extra Trees(極端隨機樹)
- 與隨機森林類似,但在選擇分割點時增加了更多隨機性
- 不僅隨機選擇特征,還隨機選擇分割閾值
- 計算效率通常比隨機森林高
-
Gradient Boosting(梯度提升)
- 另一種集成方法,通過順序構建決策樹來改進模型
- 每棵新樹都試圖修正前面樹的預測錯誤
- 通常有很高的預測精度,但需要仔細調參
-
SVR(支持向量回歸)
- 基于支持向量機(SVM)的回歸方法
- 使用核函數(這里是rbf核)處理非線性關系
- 通過尋找一個函數使大部分樣本點與函數的偏差不超過ε
-
KNN(K近鄰回歸)
- 基于實例的學習方法,不需要顯式訓練
- 對新樣本,找到最近的k個鄰居,用它們的目標值平均作為預測
- 簡單直觀,但對數據尺度和維度敏感
-
MLP(多層感知器)
- 一種前饋神經網絡,包含輸入層、隱藏層和輸出層
- 這里配置有兩個隱藏層,分別有100和50個神經元
- 能夠學習復雜的非線性關系,但需要較多數據和計算資源
用于分類任務的常見模型
在機器學習中,分類任務(Classification)是指預測樣本所屬的類別(離散標簽),例如:
- 垃圾郵件檢測(是/否)
- 醫療診斷(患病/健康)
- 圖像識別(貓/狗/車)
- 客戶流失預測(會流失/不會流失)
下面是一些最常用、性能穩定且廣泛應用的分類模型,適用于結構化數據(如表格 CSV)和中小規模數據集。
| 模型 | 是否適合小數據 | 是否需標準化 | 是否可解釋 | 推薦指數 |
|---|---|---|---|---|
| 邏輯回歸 | ? | ? | ? | ????? |
| 決策樹 | ? | ? | ?? | ????☆ |
| 隨機森林 | ?? | ? | ? | ????? |
| XGBoost / LightGBM | ?(中等以上) | ? | ??(需 SHAP) | ????? |
| SVM | ? | ? | ? | ???☆ |
| KNN | ? | ? | ? | ??☆ |
| 樸素貝葉斯 | ? | ? | ?? | ???? |
| MLP(神經網絡) | ??(慎用) | ? | ? | ??☆ |
分類模型選擇建議
| 場景 | 推薦模型 |
|---|---|
| 小數據(<500)+ 可解釋性要求高 | 邏輯回歸、決策樹 |
| 中等數據 + 高精度需求 | 隨機森林、XGBoost、LightGBM |
| 文本分類 | 樸素貝葉斯、邏輯回歸 + TF-IDF |
| 實時預測 | 邏輯回歸、KNN、決策樹 |
| 特征很多但樣本少 | SVM、Ridge 分類器 |
| 需要概率輸出 | 邏輯回歸、隨機森林、SVM(開啟 probability) |
| 類別特征多(如性別、地區) | CatBoost、LightGBM |
常見分類模型
1. 邏輯回歸(Logistic Regression)
- 適用場景:二分類問題,特征與結果呈線性關系
- 優點:
- 簡單、速度快
- 輸出具有概率意義
- 可解釋性強(系數表示特征影響方向)
- 缺點:無法處理復雜的非線性關系
- 代碼:
from sklearn.linear_model import LogisticRegression model = LogisticRegression()
2. 支持向量機(SVM / SVC)
- 適用場景:小樣本、高維數據、非線性邊界(用核函數)
- 優點:
- 在小數據上表現好
- 使用 RBF 核可擬合復雜邊界
- 缺點:
- 訓練慢,不適合大數據
- 對特征縮放敏感(必須標準化)
- 代碼:
from sklearn.svm import SVC model = SVC(kernel='rbf', probability=True) # 開啟概率輸出
3. 決策樹(Decision Tree)
- 適用場景:規則清晰、需要可解釋性的任務
- 優點:
- 易于理解和可視化
- 不需要標準化
- 能自動處理特征交互
- 缺點:容易過擬合,泛化能力差
- 代碼:
from sklearn.tree import DecisionTreeClassifier model = DecisionTreeClassifier(max_depth=5) # 控制深度防過擬合
4. 隨機森林(Random Forest)
- 原理:多個決策樹投票決定最終類別
- 適用場景:大多數結構化數據分類任務的“默認首選”
- 優點:
- 抗過擬合能力強
- 能處理非線性關系
- 支持特征重要性分析
- 缺點:比單棵樹慢,但通常可接受
- 代碼:
from sklearn.ensemble import RandomForestClassifier model = RandomForestClassifier(n_estimators=100, random_state=47)
5. 梯度提升樹(Gradient Boosting)
- 代表模型:
GradientBoostingClassifier、XGBoost、LightGBM、CatBoost - 原理:逐個訓練樹來修正前一個模型的錯誤
- 優點:
- 高精度,常用于競賽
- 對缺失值和類別特征有一定魯棒性
- 缺點:訓練較慢,需調參
- 代碼示例:
或使用第三方庫:from sklearn.ensemble import GradientBoostingClassifier model = GradientBoostingClassifier(n_estimators=100, learning_rate=0.1)import xgboost as xgb model = xgb.XGBClassifier(n_estimators=100, random_state=47)
6. K近鄰(K-Nearest Neighbors, KNN)
- 原理:根據最近的 K 個鄰居的類別投票
- 適用場景:數據分布局部相似性強
- 優點:無需訓練,直觀
- 缺點:
- 預測慢(要計算距離)
- 對高維數據效果差(維度災難)
- 必須標準化
- 代碼:
from sklearn.neighbors import KNeighborsClassifier model = KNeighborsClassifier(n_neighbors=5)
7. 樸素貝葉斯(Naive Bayes)
- 適用場景:文本分類(如垃圾郵件識別)、高維稀疏數據
- 優點:
- 極快,適合實時預測
- 在文本任務中表現意外地好
- 缺點:假設特征相互獨立(現實中常不成立)
- 常見變體:
GaussianNB:連續特征(假設正態分布)MultinomialNB:文本計數數據(如詞頻)BernoulliNB:二值特征
- 代碼:
from sklearn.naive_bayes import GaussianNB model = GaussianNB()
8. 多層感知機(MLP / 神經網絡)
- 適用場景:有一定數據量(>1000)、特征復雜、非線性強
- 注意:小樣本(如 <500)容易過擬合
- 優點:能擬合任意復雜函數
- 缺點:需要調參多、必須標準化、訓練不穩定
- 代碼:
from sklearn.neural_network import MLPClassifier model = MLPClassifier(hidden_layer_sizes=(50, 25), max_iter=500, alpha=1.0)
9. LightGBM / XGBoost / CatBoost(進階推薦)
這些是當前結構化數據分類任務中的“王者級”模型:
| 模型 | 特點 ||------|------|
| LightGBM | 快、省內存,適合大數據 |
| XGBoost | 精度高,廣泛使用 |
| CatBoost | 原生支持類別特征,無需獨熱編碼 |
import lightgbm as lgb
model = lgb.LGBMClassifier(n_estimators=100, verbose=-1)














如何進行MySQL的全局變量設置?)




