本文代碼詳解參考:
模型訓練基礎流程-CSDN博客
目錄
為什么要用GPU訓練模型
什么是CUDA
利用GPU訓練—方式一(.cuda())
利用GPU訓練—方式二 (.to())
Google Colaboratory
為什么要用GPU訓練模型
用 GPU 訓練模型的核心原因是GPU 的硬件架構和計算特性,能完美適配深度學習模型的計算需求,大幅提升訓練效率
一、GPU 的核心優勢:并行計算能力極強
深度學習模型的訓練過程(如神經網絡的前向傳播、反向傳播)本質上是大量重復的矩陣運算和向量運算(例如卷積層的卷積操作、全連接層的矩陣乘法)。
-
CPU 的設計側重 “低延遲、串行計算”,核心數量少(通常 4-32 核),適合處理邏輯復雜、步驟連貫的任務(如系統調度、單線程指令),但面對成百上千萬次的并行重復計算時效率極低。
-
GPU 的設計則側重 “高吞吐、并行計算”,核心數量極多(主流 GPU 有數千個計算核心,如 RTX 4090 有 16384 個 CUDA 核心),這些核心可以同時處理大量相似的簡單計算(比如同時對矩陣中不同位置的元素做乘法)。
例如:一個 1000×1000 的矩陣乘法,CPU 可能需要逐個元素循環計算,而 GPU 可以同時啟動上萬次運算,將計算時間從 “小時級” 壓縮到 “分鐘級” 甚至 “秒級”。
二、適配深度學習的 “計算密集型” 需求
深度學習訓練的兩大核心特點,恰好被 GPU 針對性解決:
-
計算量極大:模型參數量從百萬級(簡單 CNN)到千億級(大語言模型),每次迭代需要對所有參數計算梯度,涉及的運算次數按 “億” 甚至 “萬億” 計。GPU 的并行核心能同時分攤這些計算,避免 CPU “逐個處理” 的低效。
-
數據吞吐量高:訓練時需要頻繁讀取批量數據(如圖像、文本特征),并在模型各層間傳遞。GPU 自帶大容量高帶寬顯存(如 16GB-80GB GDDR6/HOF),配合專門的存儲控制器,能快速讀寫數據,避免 “數據等待計算” 的瓶頸(而 CPU 的內存帶寬通常僅為 GPU 的 1/10 左右)。
三、實際效果:訓練效率提升數十倍甚至上百倍
-
對于簡單模型(如小型 CNN):GPU 訓練速度通常是 CPU 的 10-30 倍。
-
對于大型模型(如 Transformer、大語言模型):CPU 可能需要數周甚至數月才能完成訓練,而 GPU(尤其是多 GPU 集群)可壓縮到幾天甚至幾小時,且能支持更大的批量和更復雜的模型結構(否則 CPU 會因內存或速度限制無法運行)。
用后述代碼展示速度差異:
利用GPU訓練的時間:
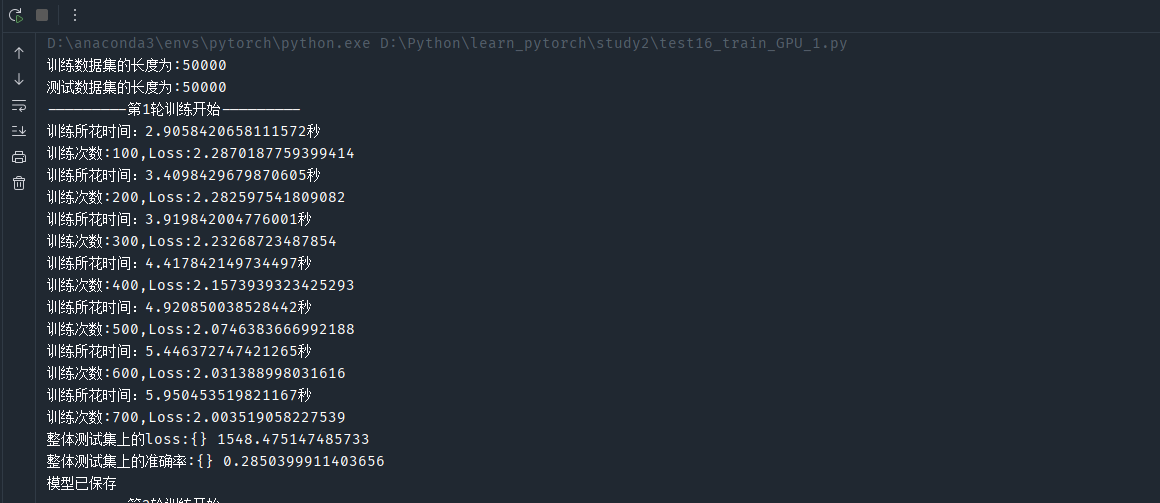
?利用CPU訓練的時間:
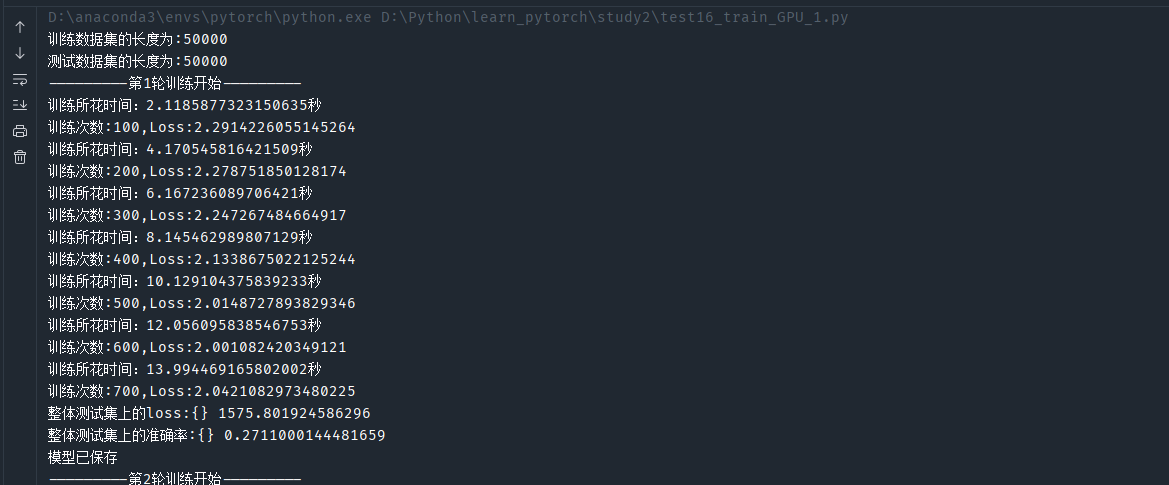
CPU訓練百次需要2s左右 而GPU只要0.5s ! ! !?
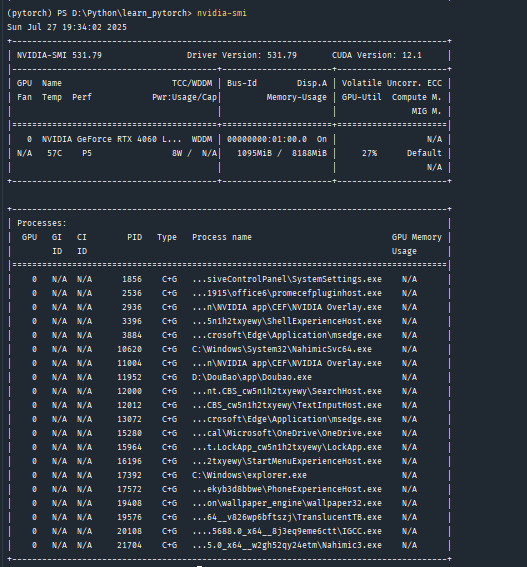
可以使用如圖命令查看自己設備的GPU信息
若報錯則是驅動沒有正確安裝,需要去英偉達官網下載?
什么是CUDA
CUDA(Compute Unified Device Architecture)是英偉達(NVIDIA)推出的一種并行計算平臺和編程模型,旨在利用 NVIDIA GPU 的并行計算能力,加速計算密集型任務。
核心概念
-
并行計算平臺:CUDA 為開發者提供了一個環境,使得 GPU 可以作為一個高度并行的計算設備,和 CPU 協同工作。在傳統計算中,CPU 處理任務是串行的,而 CUDA 允許將大量可以并行執行的計算任務分配到 GPU 上,極大地提高計算效率。
-
編程模型:CUDA 定義了一套編程接口和語法規則,允許開發者使用類 C 語言(CUDA C/C++)編寫并行計算程序,來充分發揮 GPU 的大規模并行計算能力。此外,像 PyTorch、TensorFlow 等深度學習框架也對 CUDA 進行了封裝,使得深度學習開發者無需深入了解底層編程細節,就能輕松利用 GPU 加速模型訓練。
工作原理
-
任務拆分:在 CUDA 編程中,開發者需要將計算任務分解成大量可以并行執行的小任務。例如,在深度學習的矩陣乘法中,矩陣的不同元素運算可以并行執行,CUDA 可以將這些運算分配到 GPU 的眾多計算核心上。
-
線程管理:CUDA 將 GPU 的計算資源組織成線程層次結構,包括線程塊(block)和線程網格(grid)。每個線程執行相同的內核函數(kernel function),但處理不同的數據,通過線程 ID 來區分和操作不同的數據。
-
協同計算:CPU 負責處理邏輯性強、計算量小的任務,如程序的流程控制、數據的預處理和后處理等;GPU 則專注于執行高度并行的計算任務,兩者相互協作,共同完成復雜的計算任務。
應用場景
-
深度學習:是 CUDA 最廣泛的應用領域之一。在訓練神經網絡模型(如卷積神經網絡 CNN、循環神經網絡 RNN 及其變體 LSTM、GRU,還有 Transformer 等)時,大量的矩陣運算(如前向傳播、反向傳播)可以利用 CUDA 在 GPU 上并行加速,大幅縮短訓練時間。
-
科學計算:在物理模擬、流體動力學計算、分子動力學模擬等科學領域,存在大量的數值計算,CUDA 能夠顯著提升這些計算的效率,加速科研進程。
-
圖形渲染:雖然 GPU 最初是為圖形渲染設計的,但 CUDA 進一步拓展了其應用。在實時渲染、光線追蹤等圖形處理任務中,CUDA 可以加速圖形算法的執行,提升渲染質量和速度。
利用GPU訓練—方式一(.cuda())
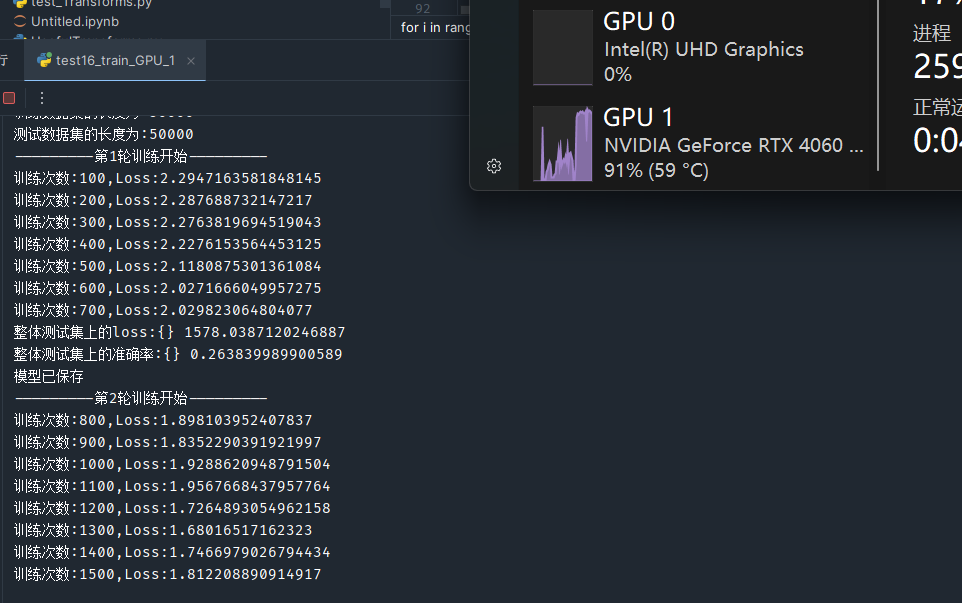
把如圖所示的三個 加上cuda方法即可

運行后GPU確實跑起來了:
代碼:
import torchimport torchvision
from torch import nn
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
import timetrain_data = torchvision.datasets.CIFAR10(root="D:\\Python\\learn_pytorch\\torchvision_dataset", train=True,transform=torchvision.transforms.ToTensor(),download=True)test_data = torchvision.datasets.CIFAR10(root="D:\\Python\\learn_pytorch\\torchvision_dataset", train=True,transform=torchvision.transforms.ToTensor(),download=False)# 數據集長度
train_data_size = len(train_data)
test_data_size = len(test_data)
print("訓練數據集的長度為:{}".format(train_data_size))
print("測試數據集的長度為:{}".format(test_data_size))# 利用DataLoader來加載數據集
train_dataloader = DataLoader(train_data, batch_size=64)
test_dataloader = DataLoader(test_data, batch_size=64)# 創建網絡模型
class MyModule(nn.Module):def __init__(self):super().__init__()self.module = nn.Sequential(nn.Conv2d(3, 32, 5, 1, 2),nn.MaxPool2d(2),nn.Conv2d(32, 32, 5, 1, 2),nn.MaxPool2d(2),nn.Conv2d(32, 64, 5, 1, 2),nn.MaxPool2d(2),nn.Flatten(),nn.Linear(64 * 4 * 4, 64),nn.Linear(64, 10))def forward(self, x):x = self.module(x)return xmodel = MyModule()
# 網絡模型轉移到GPU
if torch.cuda.is_available():model = model.cuda()# 損失函數
loss_fn = nn.CrossEntropyLoss()
# 損失函數轉移到GPU
if torch.cuda.is_available():loss_fn = loss_fn.cuda()
# 優化器
learning_rate = 1e-2
optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate)# 設置訓練網絡的一些參數
# 訓練次數
total_train_step = 0
# 測試次數
total_test_step = 0
# 訓練輪數
epoch = 10# 添加tensorboard
writer = SummaryWriter("logs_test16")# 計時比較CPU和GPU的訓練速度差異
# 開始時間
start_time=time.time()
for i in range(epoch):print("---------第{}輪訓練開始---------".format(i + 1))# 訓練model.train()for data in train_dataloader:imgs, targets = data# 訓練數據轉移到GPUif torch.cuda.is_available():imgs = imgs.cuda()targets = targets.cuda()outputs = model(imgs)loss = loss_fn(outputs, targets)# 優化器優化模型optimizer.zero_grad()loss.backward()optimizer.step()total_train_step = total_train_step + 1if total_train_step % 100 == 0:# 到當前的訓練總時間end_time=time.time()print("訓練所花時間:{}秒".format(end_time-start_time))print("訓練次數:{},Loss:{}".format(total_train_step, loss.item()))writer.add_scalar("train_loss", loss.item(), total_train_step)# 評估模型訓練效果 - 跑一個測試數據查看正確率# 測試過程中,參數不需要調整了,臨時把梯度去除model.eval()total_test_loss = 0total_accuracy = 0with torch.no_grad():for data in test_dataloader:imgs, targets = data# 測試數據轉移到GPUif torch.cuda.is_available():imgs = imgs.cuda()targets = targets.cuda()outputs = model(imgs)loss = loss_fn(outputs, targets)total_test_loss = total_test_loss + loss.item()accuracy = (outputs.argmax(1) == targets).sum()total_accuracy = total_accuracy + accuracy # 預測對的總數量print("整體測試集上的loss:{}", format(total_test_loss))print("整體測試集上的準確率:{}", format(total_accuracy / test_data_size)) # 準確率writer.add_scalar("test_sum_loss", total_test_loss, total_test_step)writer.add_scalar("test_accuracy", total_accuracy / test_data_size, total_test_step)total_test_step = total_test_step + 1# 保存每一次訓練的結果torch.save(model, "model_{}.pth".format(i))print("模型已保存")writer.close()
import torch
import torchvision
from torch import nn
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
import timetrain_data = torchvision.datasets.CIFAR10(root="D:\\Python\\learn_pytorch\\torchvision_dataset", train=True,
????????????????????????????????????????? transform=torchvision.transforms.ToTensor(),
????????????????????????????????????????? download=True)test_data = torchvision.datasets.CIFAR10(root="D:\\Python\\learn_pytorch\\torchvision_dataset", train=True,
???????????????????????????????????????? transform=torchvision.transforms.ToTensor(),
???????????????????????????????????????? download=False)# 數據集長度
train_data_size = len(train_data)
test_data_size = len(test_data)
print("訓練數據集的長度為:{}".format(train_data_size))
print("測試數據集的長度為:{}".format(test_data_size))# 利用DataLoader來加載數據集
train_dataloader = DataLoader(train_data, batch_size=64)
test_dataloader = DataLoader(test_data, batch_size=64)# 創建網絡模型
class MyModule(nn.Module):
??? def __init__(self):
??????? super().__init__()
??????? self.module = nn.Sequential(
??????????? nn.Conv2d(3, 32, 5, 1, 2),
??????????? nn.MaxPool2d(2),
??????????? nn.Conv2d(32, 32, 5, 1, 2),
??????????? nn.MaxPool2d(2),
??????????? nn.Conv2d(32, 64, 5, 1, 2),
??????????? nn.MaxPool2d(2),
??????????? nn.Flatten(),
??????????? nn.Linear(64 * 4 * 4, 64),
??????????? nn.Linear(64, 10)
??????? )??? def forward(self, x):
??????? x = self.module(x)
??????? return xmodel = MyModule()
# 網絡模型轉移到GPU
if torch.cuda.is_available():
??? model = model.cuda()# 損失函數
loss_fn = nn.CrossEntropyLoss()
# 損失函數轉移到GPU
if torch.cuda.is_available():
??? loss_fn = loss_fn.cuda()
# 優化器
learning_rate = 1e-2
optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate)# 設置訓練網絡的一些參數
# 訓練次數
total_train_step = 0
# 測試次數
total_test_step = 0
# 訓練輪數
epoch = 10# 添加tensorboard
writer = SummaryWriter("logs_test16")# 計時比較CPU和GPU的訓練速度差異
# 開始時間
start_time=time.time()
for i in range(epoch):
??? print("---------第{}輪訓練開始---------".format(i + 1))??? # 訓練
??? model.train()
??? for data in train_dataloader:
??????? imgs, targets = data??????? # 訓練數據轉移到GPU
??????? if torch.cuda.is_available():
??????????? imgs = imgs.cuda()
??????????? targets = targets.cuda()
??????? outputs = model(imgs)
??????? loss = loss_fn(outputs, targets)??????? # 優化器優化模型
??????? optimizer.zero_grad()
??????? loss.backward()
??????? optimizer.step()
??????? total_train_step = total_train_step + 1
??????? if total_train_step % 100 == 0:
??????????? # 到當前的訓練總時間
??????????? end_time=time.time()
??????????? print("訓練所花時間:{}秒".format(end_time-start_time))
??????????? print("訓練次數:{},Loss:{}".format(total_train_step, loss.item()))
??????????? writer.add_scalar("train_loss", loss.item(), total_train_step)
??? # 評估模型訓練效果 - 跑一個測試數據查看正確率??? # 測試過程中,參數不需要調整了,臨時把梯度去除
??? model.eval()
??? total_test_loss = 0
??? total_accuracy = 0
??? with torch.no_grad():
??????? for data in test_dataloader:
??????????? imgs, targets = data?????????? # 測試數據轉移到GPU
??????????? if torch.cuda.is_available():
??????????????? imgs = imgs.cuda()
??????????????? targets = targets.cuda()??????????? outputs = model(imgs)
??????????? loss = loss_fn(outputs, targets)
??????????? total_test_loss = total_test_loss + loss.item()
??????????? accuracy = (outputs.argmax(1) == targets).sum()
??????????? total_accuracy = total_accuracy + accuracy? # 預測對的總數量??? print("整體測試集上的loss:{}", format(total_test_loss))
??? print("整體測試集上的準確率:{}", format(total_accuracy / test_data_size))? # 準確率
??? writer.add_scalar("test_sum_loss", total_test_loss, total_test_step)
??? writer.add_scalar("test_accuracy", total_accuracy / test_data_size, total_test_step)
??? total_test_step = total_test_step + 1??? # 保存每一次訓練的結果
??? torch.save(model, "model_{}.pth".format(i))
??? print("模型已保存")writer.close()
?利用GPU訓練—方式二 (.to())

更常用和推薦
import torchimport torchvision
from torch import nn
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
import time# 定義訓練的設備
device1 = torch.device("cpu")
device2 = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# device2 = torch.device("cuda") 在確保有GPU的情況下也可以train_data = torchvision.datasets.CIFAR10(root="D:\\Python\\learn_pytorch\\torchvision_dataset", train=True,transform=torchvision.transforms.ToTensor(),download=True)test_data = torchvision.datasets.CIFAR10(root="D:\\Python\\learn_pytorch\\torchvision_dataset", train=True,transform=torchvision.transforms.ToTensor(),download=False)# 數據集長度
train_data_size = len(train_data)
test_data_size = len(test_data)
print("訓練數據集的長度為:{}".format(train_data_size))
print("測試數據集的長度為:{}".format(test_data_size))# 利用DataLoader來加載數據集
train_dataloader = DataLoader(train_data, batch_size=64)
test_dataloader = DataLoader(test_data, batch_size=64)# 創建網絡模型
class MyModule(nn.Module):def __init__(self):super().__init__()self.module = nn.Sequential(nn.Conv2d(3, 32, 5, 1, 2),nn.MaxPool2d(2),nn.Conv2d(32, 32, 5, 1, 2),nn.MaxPool2d(2),nn.Conv2d(32, 64, 5, 1, 2),nn.MaxPool2d(2),nn.Flatten(),nn.Linear(64 * 4 * 4, 64),nn.Linear(64, 10))def forward(self, x):x = self.module(x)return xmodel = MyModule()
# 網絡模型轉移到GPU
model = model.to(device2)# 損失函數
loss_fn = nn.CrossEntropyLoss()
# 損失函數轉移到GPU
loss_fn = loss_fn.to(device2)
# 優化器
learning_rate = 1e-2
optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate)# 設置訓練網絡的一些參數
# 訓練次數
total_train_step = 0
# 測試次數
total_test_step = 0
# 訓練輪數
epoch = 10# 添加tensorboard
writer = SummaryWriter("logs_test17")# 計時比較CPU和GPU的訓練速度差異
# 開始時間
start_time = time.time()
for i in range(epoch):print("---------第{}輪訓練開始---------".format(i + 1))# 訓練model.train()for data in train_dataloader:imgs, targets = data# 訓練數據轉移到GPUimgs = imgs.to(device2)targets = targets.to(device2)outputs = model(imgs)loss = loss_fn(outputs, targets)# 優化器優化模型optimizer.zero_grad()loss.backward()optimizer.step()total_train_step = total_train_step + 1if total_train_step % 100 == 0:# 到當前的訓練總時間end_time = time.time()print("訓練所花時間:{}秒".format(end_time - start_time))print("訓練次數:{},Loss:{}".format(total_train_step, loss.item()))writer.add_scalar("train_loss", loss.item(), total_train_step)# 評估模型訓練效果 - 跑一個測試數據查看正確率# 測試過程中,參數不需要調整了,臨時把梯度去除model.eval()total_test_loss = 0total_accuracy = 0with torch.no_grad():for data in test_dataloader:imgs, targets = data# 測試數據轉移到GPUimgs = imgs.to(device2)targets = targets.to(device2)outputs = model(imgs)loss = loss_fn(outputs, targets)total_test_loss = total_test_loss + loss.item()accuracy = (outputs.argmax(1) == targets).sum()total_accuracy = total_accuracy + accuracy # 預測對的總數量print("整體測試集上的loss:{}", format(total_test_loss))print("整體測試集上的準確率:{}", format(total_accuracy / test_data_size)) # 準確率writer.add_scalar("test_sum_loss", total_test_loss, total_test_step)writer.add_scalar("test_accuracy", total_accuracy / test_data_size, total_test_step)total_test_step = total_test_step + 1# 保存每一次訓練的結果torch.save(model, "model_{}.pth".format(i))print("模型已保存")writer.close()
import torchimport torchvision from torch import nn from torch.utils.data import DataLoader from torch.utils.tensorboard import SummaryWriter import time# 定義訓練的設備 device1 = torch.device("cpu") device2 = torch.device("cuda" if torch.cuda.is_available() else "cpu")train_data = torchvision.datasets.CIFAR10(root="D:\\Python\\learn_pytorch\\torchvision_dataset", train=True,transform=torchvision.transforms.ToTensor(),download=True)test_data = torchvision.datasets.CIFAR10(root="D:\\Python\\learn_pytorch\\torchvision_dataset", train=True,transform=torchvision.transforms.ToTensor(),download=False)# 數據集長度 train_data_size = len(train_data) test_data_size = len(test_data) print("訓練數據集的長度為:{}".format(train_data_size)) print("測試數據集的長度為:{}".format(test_data_size))# 利用DataLoader來加載數據集 train_dataloader = DataLoader(train_data, batch_size=64) test_dataloader = DataLoader(test_data, batch_size=64)# 創建網絡模型 class MyModule(nn.Module):def __init__(self):super().__init__()self.module = nn.Sequential(nn.Conv2d(3, 32, 5, 1, 2),nn.MaxPool2d(2),nn.Conv2d(32, 32, 5, 1, 2),nn.MaxPool2d(2),nn.Conv2d(32, 64, 5, 1, 2),nn.MaxPool2d(2),nn.Flatten(),nn.Linear(64 * 4 * 4, 64),nn.Linear(64, 10))def forward(self, x):x = self.module(x)return xmodel = MyModule() # 網絡模型轉移到GPU model = model.to(device2)# 損失函數 loss_fn = nn.CrossEntropyLoss() # 損失函數轉移到GPU loss_fn = loss_fn.to(device2) # 優化器 learning_rate = 1e-2 optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate)# 設置訓練網絡的一些參數 # 訓練次數 total_train_step = 0 # 測試次數 total_test_step = 0 # 訓練輪數 epoch = 10# 添加tensorboard writer = SummaryWriter("logs_test17")# 計時比較CPU和GPU的訓練速度差異 # 開始時間 start_time = time.time() for i in range(epoch):print("---------第{}輪訓練開始---------".format(i + 1))# 訓練model.train()for data in train_dataloader:imgs, targets = data# 訓練數據轉移到GPUimgs = imgs.to(device2)targets = targets.to(device2)outputs = model(imgs)loss = loss_fn(outputs, targets)# 優化器優化模型optimizer.zero_grad()loss.backward()optimizer.step()total_train_step = total_train_step + 1if total_train_step % 100 == 0:# 到當前的訓練總時間end_time = time.time()print("訓練所花時間:{}秒".format(end_time - start_time))print("訓練次數:{},Loss:{}".format(total_train_step, loss.item()))writer.add_scalar("train_loss", loss.item(), total_train_step)# 評估模型訓練效果 - 跑一個測試數據查看正確率# 測試過程中,參數不需要調整了,臨時把梯度去除model.eval()total_test_loss = 0total_accuracy = 0with torch.no_grad():for data in test_dataloader:imgs, targets = data # 測試數據轉移到GPUimgs = imgs.to(device2)targets = targets.to(device2)outputs = model(imgs)loss = loss_fn(outputs, targets)total_test_loss = total_test_loss + loss.item()accuracy = (outputs.argmax(1) == targets).sum()total_accuracy = total_accuracy + accuracy # 預測對的總數量print("整體測試集上的loss:{}", format(total_test_loss))print("整體測試集上的準確率:{}", format(total_accuracy / test_data_size)) # 準確率writer.add_scalar("test_sum_loss", total_test_loss, total_test_step)writer.add_scalar("test_accuracy", total_accuracy / test_data_size, total_test_step)total_test_step = total_test_step + 1# 保存每一次訓練的結果torch.save(model, "model_{}.pth".format(i))print("模型已保存")writer.close()
Google Colaboratory
Google Colab(Colaboratory)是谷歌開發的基于云端的交互式筆記本環境。
- 核心功能:無需本地配置環境,可直接在瀏覽器中編寫和運行 Python 代碼,支持深度學習、數據分析等任務。
- 硬件支持:免費提供 CPU、GPU(如 Tesla K80、T4)甚至 TPU(張量處理單元)資源,方便運行大型模型(如訓練神經網絡)。
- 優勢:
- 與 Google Drive 無縫集成,可直接讀取 / 保存云端文件;
- 支持實時協作(多人共同編輯同一筆記本);
- 預裝了 PyTorch、TensorFlow、NumPy 等主流庫,開箱即用。
- 適用場景:快速原型開發、學習深度學習、資源有限時的模型訓練等。
簡單說,它是一個 “云端免費 GPU 編程工具”,對初學者和需要臨時算力的開發者非常友好。?
前提:能使用谷歌? (-_-)
?
?在上方導航欄? ?修改-筆記本設置 里可以啟用GPU/TPU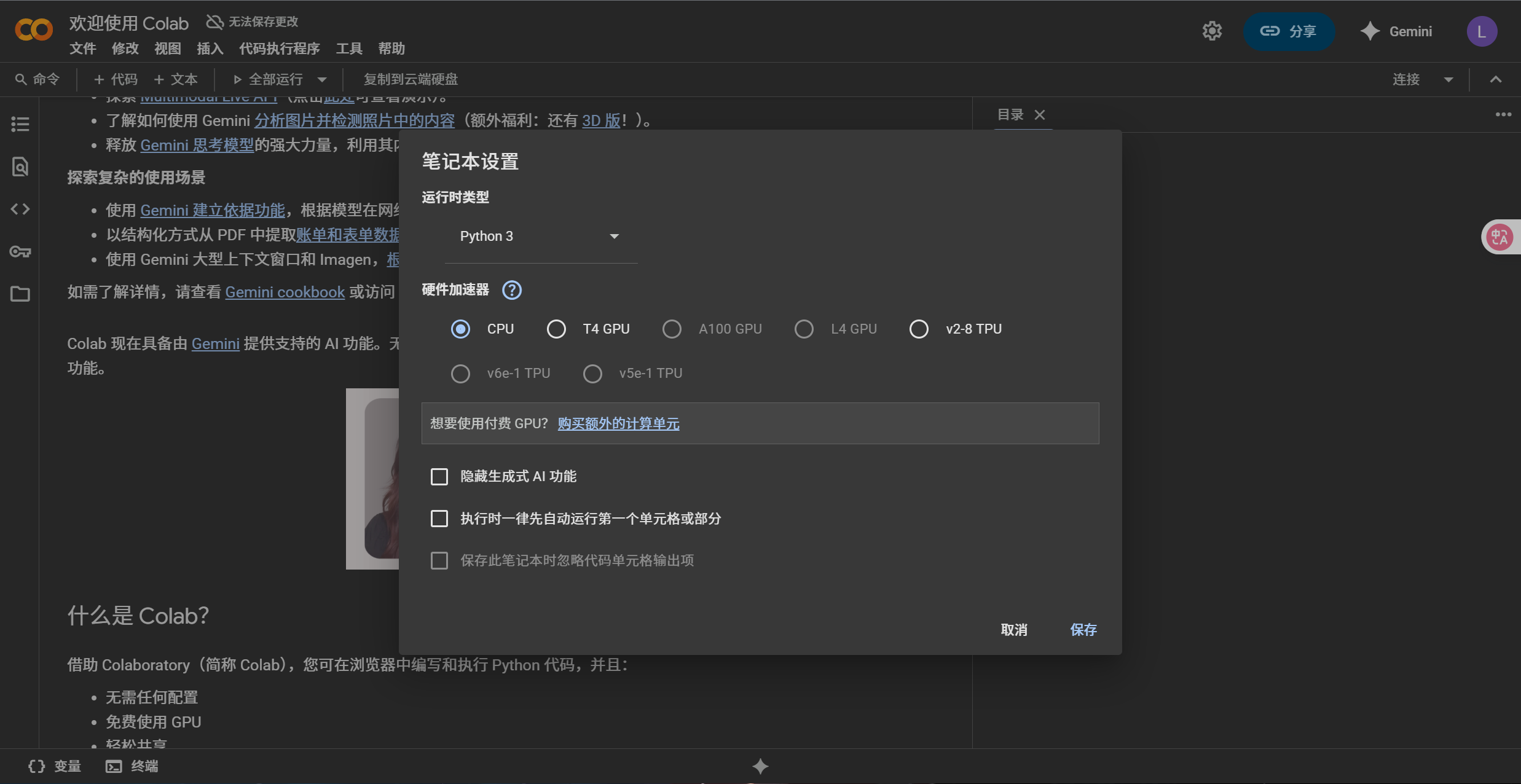
查看硬件參數?
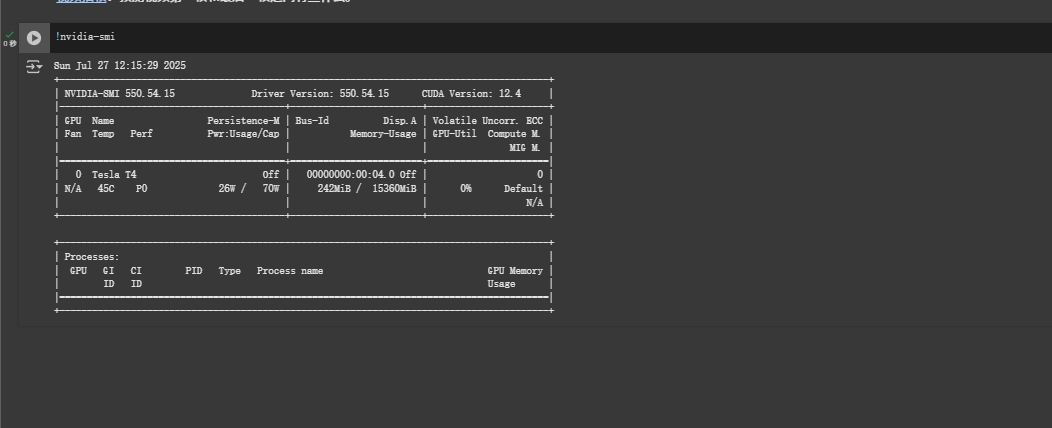
Tesla T4 是一款面向數據中心的推理加速 GPU,基于 Turing 架構,具備不錯的計算能力,支持多種計算精度,在深度學習推理任務中有出色表現。
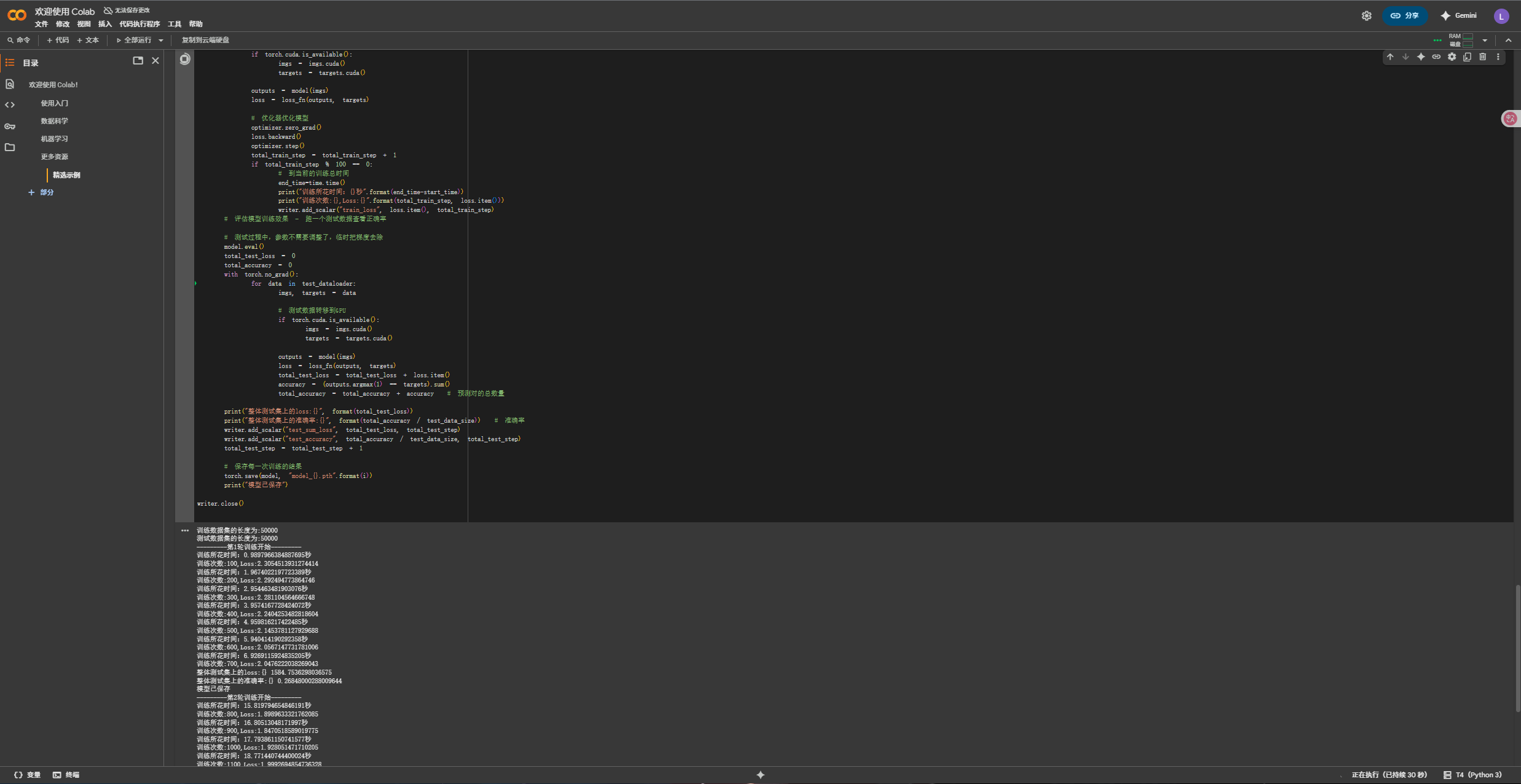
用?Colaboratory 跑上述代碼


 與 HTTP API:大模型時代的通信新范式)



![0-1BFS(雙端隊列,洛谷P4667 [BalticOI 2011] Switch the Lamp On 電路維修 (Day1)題解)](http://pic.xiahunao.cn/0-1BFS(雙端隊列,洛谷P4667 [BalticOI 2011] Switch the Lamp On 電路維修 (Day1)題解))


)

的完整流程)


![[2025CVPR-圖象超分辨方向]DORNet:面向退化的正則化網絡,用于盲深度超分辨率](http://pic.xiahunao.cn/[2025CVPR-圖象超分辨方向]DORNet:面向退化的正則化網絡,用于盲深度超分辨率)




