享元模式是一種結構型設計模式,它通過共享對象來最小化內存使用或計算開銷。這種模式適用于大量相似對象的情況,通過共享這些對象的公共部分來減少資源消耗。
基本概念
享元模式的核心思想是將對象的內在狀態(不變的部分)和外在狀態(變化的部分)分離:
內在狀態(Intrinsic State):存儲在享元內部,可以被多個對象共享,獨立于具體場景
外在狀態(Extrinsic State):取決于具體場景,通常由客戶端保存或計算
實現示例
下面是一個簡單的享元模式實現示例,模擬文本編輯器中的字符處理:
#include <iostream>
#include <string>
#include <unordered_map>// 享元類 - 表示字符及其內在狀態(字體、大小等)
class Character {
public:Character(char symbol, const std::string& font, int size): symbol_(symbol), font_(font), size_(size) {}void display(int position) const {std::cout << "Character: " << symbol_ << ", Font: " << font_<< ", Size: " << size_<< ", Position: " << position << std::endl;}private:char symbol_;std::string font_;int size_;
};// 享元工廠 - 創建和管理享元對象
class CharacterFactory {
public:Character* getCharacter(char key, const std::string& font, int size) {// 使用組合鍵來唯一標識享元對象std::string compositeKey = std::string(1, key) + "_" + font + "_" + std::to_string(size);if (characters_.find(compositeKey) == characters_.end()) {characters_[compositeKey] = new Character(key, font, size);}return characters_[compositeKey];}~CharacterFactory() {for (auto& pair : characters_) {delete pair.second;}}private:std::unordered_map<std::string, Character*> characters_;
};// 客戶端代碼
int main() {CharacterFactory factory;// 文檔中的字符及其位置std::string text = "Hello, World!";for (size_t i = 0; i < text.size(); ++i) {char c = text[i];// 假設所有字符使用相同的字體和大小Character* character = factory.getCharacter(c, "Arial", 12);character->display(i); // 位置是外在狀態,由客戶端提供}return 0;
}UML結構?
?
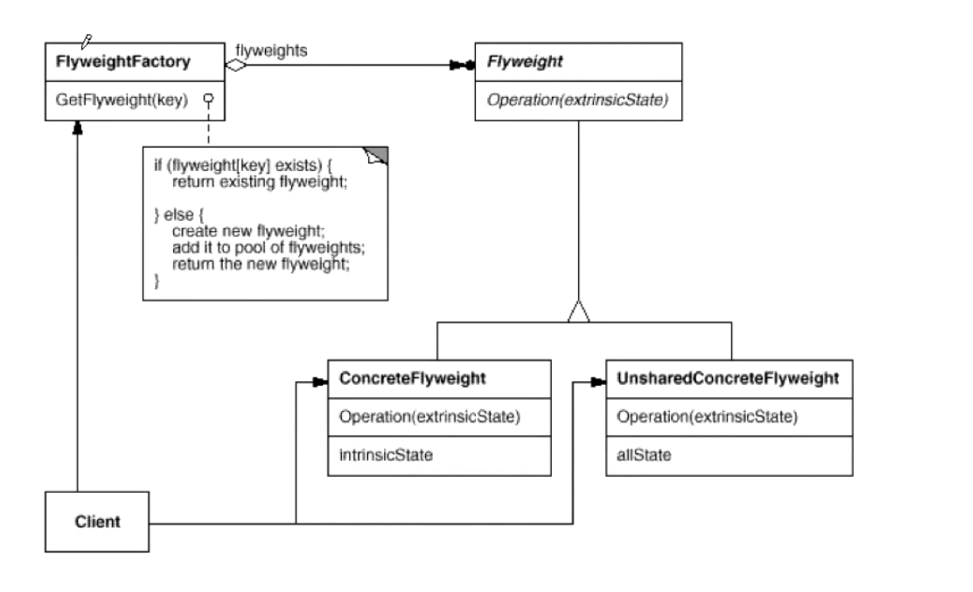
享元模式的組成
Flyweight(享元接口):定義享元對象的接口
ConcreteFlyweight(具體享元):實現享元接口,存儲內在狀態
UnsharedConcreteFlyweight(非共享具體享元):不需要共享的享元實現
FlyweightFactory(享元工廠):創建和管理享元對象,確保合理共享
Client(客戶端):維護對享元的引用,計算或存儲外在狀態
適用場景
一個應用程序使用了大量相似對象
由于大量對象造成很大的存儲開銷
對象的大多數狀態可以變為外部狀態
移除了外部狀態后,可以用較少的共享對象替代大量對象
優點
減少內存使用,因為共享了相似對象
減少了對象的創建數量,提高了性能
將狀態外部化,使得對象更輕量
缺點
增加了系統復雜性,需要分離內在和外在狀態
可能需要線程安全考慮,因為享元對象是共享的
外在狀態需要由客戶端維護和管理
實際應用
文本編輯器中的字符處理
游戲開發中的粒子系統
圖形編輯器中的圖形對象
數據庫連接池
任何需要大量細粒度對象的場景
在C++標準庫中,std::string的寫時復制(COW)實現某種程度上也使用了享元模式的思想。

的完整流程)


![[2025CVPR-圖象超分辨方向]DORNet:面向退化的正則化網絡,用于盲深度超分辨率](http://pic.xiahunao.cn/[2025CVPR-圖象超分辨方向]DORNet:面向退化的正則化網絡,用于盲深度超分辨率)







2025年7月底測試好用:從理論到實踐的完整技術方案)
)


![[10月考試] F](http://pic.xiahunao.cn/[10月考試] F)


